

www.basegroup.ru
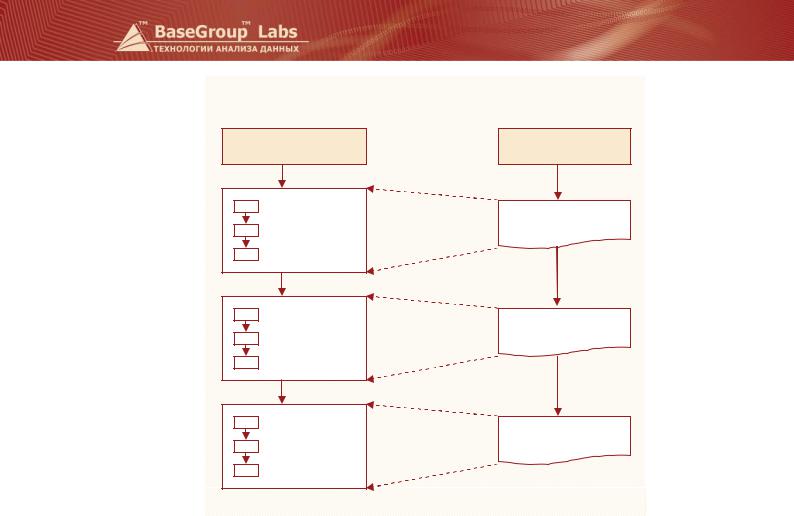
Ветка 1
Импорт данных
Ветка 2
Импорт данных
Предобработка |
Скрипт |
предобработки |
Скрипт анализа
Анализ
Постобработка |
Скрипт |
постобработки |
Любой из этих скриптов может отсутствовать, а между двумя скриптами могут находиться произвольные узлы обработки.
Дополнительное преимущество, даваемое применением скриптов в проектах, состоит в возможности избежать ошибок и легкости модернизации сразу всех моделей обработки данных. При обнаружении ошибки достаточно исправить ее в одном месте, в ветке-оригинале, и она автоматически исправляется во всех остальных ветвях, где используется скрипт. Аналогично изменение исходной модели синхронно скажется на всех ветвях обработки, построенных на скриптах.
Использование переменных
В Deductor Studio имеется возможность использовать в формулах, например, в «Калькуляторе» переменные. Эти переменные задаются в специальном окне настройки Сервис ► Переменные.
Данный механизм удобно использовать для случаев, когда необходимо выполнить одни и те же сценарии, но с различными параметрами. Можно настроить сценарий таким образом, чтобы в нем использовалась определяемая переменная, потом задать эту переменную и «прогнать» сценарий, ввести новое значение переменной, закрыть узлы ветки и еще раз провести обработку, но уже с новым параметром.
Переменные можно передавать программе в командной строке. Эту возможность удобно использовать при написании пакетных (*.bat) файлов. Можно несколько раз вызвать один и тот же сценарий с различными переменными.
Обработка сценариев при помощи Deductor Server
Имеется возможность оптимизировать скорость работы при помощи Deductor Server. Deductor Server – служба Windows, способная выполнить обработку сценариев и переобучение моделей.
стр. 175 из 192

www.basegroup.ru
Делается это следующим образом.
Сначала строится сценарий при помощи Deductor Studio. Для того чтобы можно было выполнить на сервере обработку, сценарий должен содержать узлы экспорта данных. Deductor Server не интерактивное приложение, в нем отсутствует визуальная часть, поэтому получить результаты при его применении можно единственным способом – экспортировав их в какой-нибудь приемник данных. Если будет проводится серверное переобучение, то необходимо, чтобы в сценарии присутствовали обработчики допускающие переобучение, например, деревья решений или самоорганизующиеся карты.
После этого построенный файл проекта переносится на оборудование, где установлен Deductor Server. Теперь можно его использовать. Для управления и работы с сервером предназначен специальная библиотека – Deductor Client. Его применение требует написания кода программистами. Информация по этому поводу описана в SDK, поставляемый с Deductor Enterprise. Работа аналитика заключается только в написании сценариев, остальные операции должны выполнять сотрудники IT служб.
Оптимизация производительности при применении Deductor Server происходит по следующим причинам:
§Используется более производительное серверное оборудование.
§Поддерживается многопоточная обработка данных.
§Применяется специальное кэширование данных для уменьшения времени на загрузку проектов в память и повторный импорт.
§Отсутствует визуализация, обычно отнимающая значительную часть вычислительных ресурсов.
стр. 176 из 192