


www.basegroup.ru
Как и для нейросети, общее количество правильно классифицированных примеров можно посмотреть в таблице сопряженности.
Карты Кохонена
Самоорганизующиеся карты (карты Кохонена) могут использоваться для решения таких задач, как моделирование, прогнозирование, поиск закономерностей в больших массивах данных, выявление наборов независимых признаков и сжатие информации.
Алгоритм функционирования самоорганизующихся карт (Self Organizing Maps – SOM) представляет собой один из вариантов кластеризации многомерных векторов – алгоритм проецирования с сохранением топологического подобия.
Примером таких алгоритмов может служить алгоритм k-ближайших средних (k-means). Важным отличием алгоритма SOM является то, что в нем все нейроны (узлы, центры классов) упорядочены в некоторую структуру (обычно двумерную сетку). При этом в ходе обучения модифицируется не только нейрон-победитель (нейрон карты, который в наибольшей степени соответствует вектору входов и определяет, к какому классу относится пример), но и его соседи, хотя и в меньшей степени. За счет этого SOM можно считать одним из методов проецирования многомерного пространства в пространство с более низкой размерностью. При использовании этого алгоритма вектора, близкие в исходном пространстве, оказываются рядом и на полученной карте.
SOM подразумевает использование упорядоченной структуры нейронов. Обычно используются одно- и двумерные сетки. При этом каждый нейрон представляет собой n-мерный векторстолбец, где n определяется размерностью исходного пространства (размерностью входных векторов). Применение одно- и двумерных сеток связано с тем, что возникают проблемы при отображении пространственных структур большей размерности (при этом опять возникают проблемы с понижением размерности до двумерной, представимой на мониторе).
Обычно нейроны располагаются в узлах двумерной сетки с прямоугольными или шестиугольными ячейками. При этом, как было сказано выше, нейроны также взаимодействуют друг с другом. Величина этого взаимодействия определяется расстоянием между нейронами на карте.
При реализации алгоритма SOM заранее задается конфигурация сетки (прямоугольная или шестиугольная), а также количество нейронов в сети. Некоторые источники рекомендуют использовать максимально возможное количество нейронов в карте. При этом начальный радиус обучения (neighbourhood в англоязычной литературе) в значительной степени влияет на способность обобщения при помощи полученной карты. В случае, когда количество узлов карты превышает количество примеров в обучающей выборке, успех использования алгоритма в большой степени зависит от подходящего выбора начального радиуса обучения. Однако, в случае, когда размер карты составляет десятки тысяч нейронов, время, требуемое на обучение карты, обычно бывает слишком велико для решения практических задач. Таким образом, необходимо достигать допустимый компромисс при выборе количества узлов.
Подготовка обучающей выборки
Отличием в подготовке обучающей выборки в этом алгоритме заключается в том, что выходные поля в такой выборке могут отсутствовать совсем. Даже если в обучающей выборке будут присутствовать выходные поля, они не будут участвовать при обучении нейросети, однако они будут участвовать при отображении карт.
Нормализация значений полей
Нормализация полей здесь такая же, как для нейросетей.
Настройка обучающей выборки
стр. 119 из 192

www.basegroup.ru
Обучающая выборка настраивается также, как и для нейросети и дерева решений.
Обучение
Перед началом обучения карты необходимо проинициализировать весовые коэффициенты нейронов. Удачно выбранный способ инициализации может существенно ускорить обучение и привести к получению более качественных результатов.
Существуют три способа инициирования начальных весов.
§Случайными значениями, когда всем весам даются малые случайные величины.
§Из обучающего множества, когда в качестве начальных значений задаются значения случайно выбранных примеров из обучающей выборки;
§Из собственных векторов. В этом случае веса инициируются значениями векторов, линейно упорядоченных вдоль линейного подпространства, проходящего между двумя главными собственными векторами исходного набора данных.
Визуализация
Полученную в результате обучения карту можно представить в виде слоеного пирога, каждый слой которого представляет собой раскраску, порожденную одной из компонент исходных данных. Полученный набор раскрасок может использоваться для анализа закономерностей, имеющихся между компонентами набора данных. После формирования карты получается набор узлов, который можно отобразить в виде двумерной картинки. При этом каждому узлу карты можно поставить в соответствие участок на рисунке (четырех или шестиугольный), координаты которого определяются координатами соответствующего узла в решетке. Теперь для визуализации остается только определить цвет ячеек этой картинки. Для этого и используются значения компонент. Самый простой вариант – использование градаций серого. В этом случае ячейки, соответствующие узлам карты, в которые попали элементы с минимальными значениями компонента или не попало вообще ни одной записи, будут изображены черным цветом, а ячейки, в которые попали записи с максимальными значениями такого компонента, будут соответствовать ячейке белого цвета. Более удобной является использование для раскраски цветной палитры. В принципе можно использовать любую градиентную палитру для раскраски.
Полученные раскраски в совокупности образуют атлас, отображающий расположение компонент, связи между ними, а также относительное расположение различных значений компонент.
Пример
Продолжим пример с кредитованием физических лиц. С помощью самоорганизующихся карт Кохонена можно посмотреть зависимости между различными характеристиками заемщиков и выделить сегменты заемщиков, объединив их по схожим признакам.
Обучающей выборкой будет та же, что и для нейросетей и деревьев решений. Но поле «Автомобиль» использовать не будем. Это нецелесообразно, так как данные, подаваемые на вход карт Кохонена, должны быть такими, чтобы между ними можно было вычислить расстояние или, по крайней мере, была возможность расположить их в порядке возрастания или убывания. Значения же «отечественная», «импортная» и «нет автомобиля» сравнивать между собой не совсем корректно.
Нормализация полей будет такая же, как для деревьев решений. Разбиение обучающей выборки на два множества оставим по умолчанию, как и остальные настройки.
Результаты работы алгоритма отображаются на картах. Каждому входному полю соответствует своя карта.
стр. 120 из 192
www.basegroup.ru
К примеру, в один и тот же кластер были сгруппированы молодые заемщики с маленьким сроком проживания в данной местности, специальным или средним образованием, средней жилплощадью, берущие высокие суммы кредита. В результате кластеризации заемщики со схожими характеристиками попадут в один кластер, и поэтому для них можно применять одинаковые правила выдачи кредита, т.е. для каждого кластера определить, стоит ли выдавать кредит его представителям.
Для поиска зависимостей удобно использовать выходные поля в картах Кохонена. Вообще, самообучающиеся карты – это алгоритм обучения без учителя, поэтому выходных полей в том виде, какие они бывают при решении задач регрессии и классификации здесь нет. В данном случае выходным называется, которое не используется при обучении модели, но может отображаться на построенной карте. Например, в случае банковским кредитованием таким полем может быть признак возврата/невозврата кредита. Это поле не будет использоваться при построении модели, но можно будет просмотреть как сгруппированы на построенной карте хорошие и плохие заемщики и на при наличии закономерностей в их размещении, делать выводы относительно наличия зависимостей.
Общий принцип подобного способа анализа заключается в том, что новый объект «прогоняется» сквозь построенную карту и попадает в некоторый кластер, далее определяется какого соотношение хороших и плохих заемщиков в данном кластере и на основании этого делается вывод о вероятности возврата кредита.
Результаты кластеризации алгоритмом Кохонена можно увидеть не только на карте, но и специальном визуализаторе «Профили кластеров». Принцип его работы поясняется при описании обработчика «Кластеризация».
Кластеризация (k-means и g-means)
Кластеризация семействами алгоритмов k-means и g-means используется в тех же задачах, что сети Кохонена, но ее результаты уже не просмотреть в виде двумерной раскрашенной карты.
В основе работы алгоритма k-means лежит принцип оптимального в определенном смысле разбиения множества данных на k кластеров. Алгоритм пытается сгруппировать данные в кластеры таким образом, чтобы целевая функция алгоритма разбиения достигала экстремума.
стр. 121 из 192

www.basegroup.ru
Выбор числа k может базироваться на теоретических соображениях или интуиции. Введем понятие центра кластера – средние значения переменных объектов, входящих в кластер.
Алгоритм состоит из двух этапов.
1Первоначальное распределение объектов по кластерам.
Задается число k, и на первом шаге эти точки считаются «центрами» кластеров. Каждому кластеру соответствует один центр. Выбор начальных центров осуществляется случайным образом. В результате каждый объект назначен определенному кластеру.
2Итерационный процесс.
Вычисляются новые центры кластеров и объекты перераспределяются.
Процесс вычисления центров и перераспределения объектов продолжается до тех пор, пока не стабилизируются центры кластеров, т.е. все объекты будут принадлежать кластеру, которому они принадлежали до текущей итерации.
Иллюстрация работы алгоритма k-means приведена на рисунке.
Если число кластеров назначить затруднительно, то можно использовать алгоритм g-means. Он определяет число кластеров в модели на основании последовательного выполнения статистического теста на то, что данные внутри каждого кластера подчиняются определенному гауссовскому (Gaussian, отсюда и название алгоритма) закону распределения. Если тест дает отрицательный результат, кластер разбивается на два новых кластера (алгоритмом k-means) с центрами, расположенными на оси главных компонент.
Важно помнить, что алгоритмы k-means и g-means ориентированы на гипотезу о компактности, которая предполагает, что данные обучающей выборки в виде многомерных векторов образуют в пространстве компактные сгустки сферической формы. В противном случае (например, вложенные друг в друга шары) кластеры, найденные этими алгоритмами, будут малоинформативными.
Вкачестве функции расстояния k-means в Deductor использует:
§для непрерывных числовых полей, а также упорядоченных категориальных признаков – евклидово расстояние;
§для неупорядоченных категориальных признаков – функцию отличия.
стр. 122 из 192
www.basegroup.ru
Пример
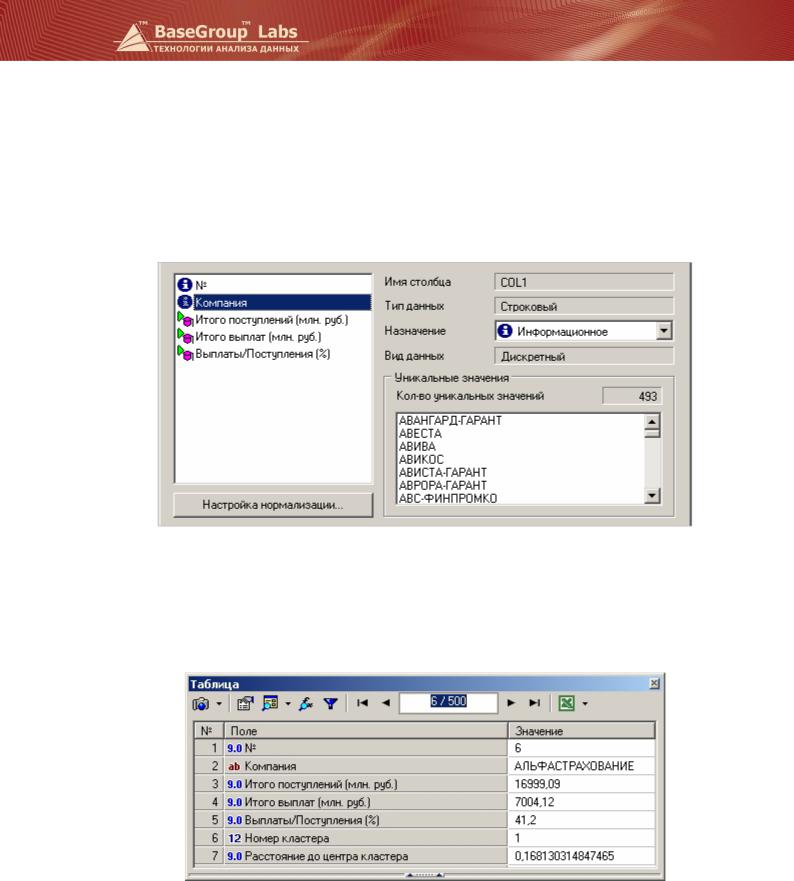
Возьмем открытые данные о 500 страховых компаниях РФ за 2008 год. Для каждой компании, кроме названия и позиции в рейтинге, известны три характеристики: Итого поступлений (млн.
руб.), Итого выплат (млн. руб.), Выплаты/Поступления (%). Очевидно, что страховые компании можно разбить на сегменты по этим показателям. Воспользуемся кластеризацией и назначим входные поля. Поля № и Компания сделаем информационными.
На вкладке разбиения исходного множества данных на обучающее и тестовое все записи отнесем к обучающим. Зададим число кластеров вручную равным 7. В качестве визуализаторов выберем «Таблица» и «Профили кластеров». В таблице появятся два новых поля – Номер кластера и Расстояние до центра кластера.
Теперь обратимся к «Профилям кластеров». Это кросс-таблица с двумя измерениями – Кластеры и Поля. На их пересечении отображаются следующие показатели.
стр. 123 из 192
www.basegroup.ru
Показатель |
|
Пример |
|
Описание |
|
|
|
|
|
|
|
Значимость |
|
|
|
1 минус вероятность нулевой гипотезы. Значимость |
|
|
|
|
|
выражается в процентах. Для непрерывных полей |
|
|
|
|
|
используется t-критерий Стьюдента, а для дискретных |
|
|
|
|
|
полей – критерий хи-квадрат. Общая значимость поля |
|
|
|
|
|
определяется по F-критерию Фишера. |
|
|
|
|
|
|
|
Доверительный |
|
|
|
Графическое изображение 95% доверительного |
|
|
|
|
интервала для среднего значения кластера (темно-серая |
||
интервал |
|
|
|
||
|
|
|
область). Кроме этого, показываются: |
||
|
|
|
|
||
|
|
|
|
§ среднее значение по кластеру – красной линией; |
|
|
|
|
|
§ среднее значение по всей выборке – синей |
|
|
|
|
|
штрихпунктирной линией. |
|
|
|
|
|
|
|
Среднее |
|
– |
|
Среднее значение по полю, рассчитанное для объектов, |
|
|
|
|
|
попавших в кластер. |
|
|
|
|
|
|
|
Стандартное |
|
– |
|
Стандартное отклонение по полю, рассчитанное для |
|
отклонение |
|
|
|
объектов, попавших в кластер. |
|
|
|
|
|
|
|
Стандартная |
|
– |
|
Стандартная ошибка по полю, рассчитанная для |
|
ошибка |
|
|
|
объектов, попавших в кластер. |
|
|
|
|
|
|
|
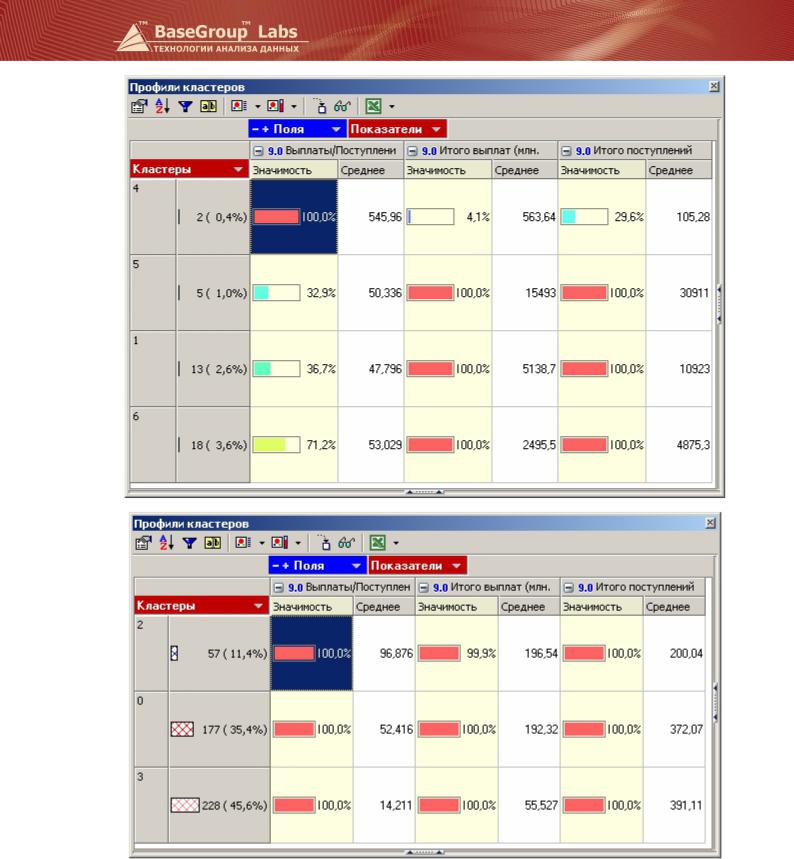
Настроим сортировку в порядке убывания поддержки (или мощности кластеров), в показателях оставим только значимость и среднее (см. рисунок). Проинтерпретируем кластеры.
стр. 124 из 192
www.basegroup.ru
В кластер № 4 попали 2 компании.
стр. 125 из 192