

6.5.2. Динамическое предсказание переходов
В динамических стратегиях решение о наиболее вероятном исходе команды УП принимается в ходе вычислений, исходя из информации о предшествующих переходах (истории переходов), собираемой в процессе выполнения программы. В целом, динамические стратегии по сравнению со статическими обеспечивают более высокую точность предсказания. Прежде чем приступить к рассмотрению конкретных динамических механизмов предсказания переходов, остановимся на некоторых положениях, общих для всех динамических подходов.
Идея динамического предсказания переходов предполагает накопление информации об исходе предшествующих команд УП. История переходов фиксируется в форме таблицы, каждый элемент которой состоит из m битов. Нужный элемент таблицы указывается с помощью k-разрядной двоичной комбинации – шаблона (pattern). Этим объясняется общепринятое название таблицы предыстории переходов – таблица истории для шаблонов (РНТ, Pattern History Table).
При описании динамических схем предсказания переходов их часто расценивают как один из видов автоматов Мура, при этом содержимое элементов РНТ трактуется как информация, отображающая текущее состояние автомата.
6.6. Суперконвейерные процессоры
Эффективность конвейера находится в прямой зависимости от того, с какой частотой на его вход подаются объекты обработки. Добиться n-кратного увеличения темпа работы конвейера можно двумя путями:
разбиением каждой ступени конвейера на п «подступеней» при одновременном повышении тактовой частоты внутри конвейера также в п раз;
включением в состав процессора п конвейеров, работающих с перекрытием.
В данном разделе рассматривается первый из этих подходов, известный как суперконвейеризация (термин впервые был применен в 1988 году). Иллюстрацией эффекта суперконвейеризации может служить диаграмма, приведенная на рис. 54, где рассмотрен ранее обсуждавшийся пример (см. рис. 50). Каждая из шести ступеней стандартного конвейера разбита на две более простые подступени, обозначенные индексами 1 и 2. Выполнение операции в подступенях занимает половину тактового периода. Тактирование операций внутри конвейера производится с частотой, вдвое превышающей частоту «внешнего» тактирования конвейера, благодаря чему на каждой ступени конвейера можно в пределах одного «внешнего» тактового периода выполнить две команды.
В сущности, суперконвейеризация сводится к увеличению количества ступеней конвейера как за счет добавления новых ступеней, так и путем дробления имеющихся ступеней на несколько простых подступеней. Главное требование — возможность реализации операции в каждой подступени наиболее простыми техническими средствами, а значит, с минимальными затратами времени. Вторым, не менее важным, условием является одинаковость задержки во всех подступенях.
Критерием для причисления процессора к суперконвейерным служит число ступеней в конвейере команд. К суперконвейерным относят процессоры, где таких ступеней больше шести. Первым серийным суперконвейерным процессором считается MIPS R4000, конвейер команд которого включает в себя восемь ступе ней. Суперконвейеризация здесь стала следствием разбиения этапов выборки команды и выборки операнда, а также введения в конвейер дополнительного этапа проверки тега, появление которой обусловлено архитектурой системы команд машины.
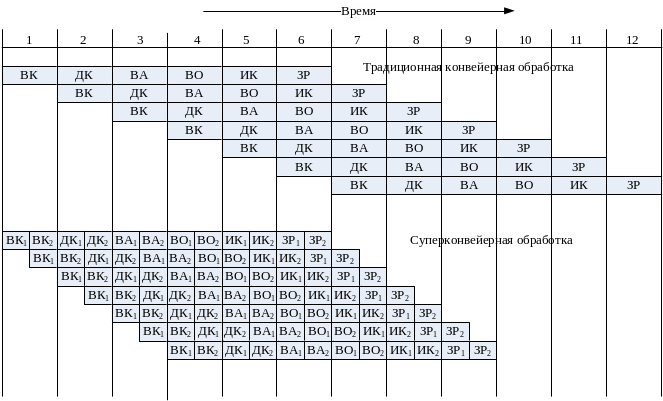
Рис. 54. Традиционная и суперконвейерная обработка команд.
К сожалению, выигрыш, достигаемый за счет суперконвейеризации, на практике может оказаться лишь умозрительным. Удлинение конвейера ведет не только к усугублению проблем, характерных для любого конвейера, но и возникновению дополнительных сложностей. В длинном конвейере возрастает вероятность конфликтов. Дороже встает ошибка предсказания перехода — приходится очищать большее число ступеней конвейера, на что требуется больше времени. Усложняется логика взаимодействия ступеней конвейера. Тем не менее, создателям ВМ удается успешно справляться с большинством из перечисленных проблем, свидетельством чего служит неуклонное возрастание числа ступеней в конвейерах команд современных процессоров.