

6.4. Методы решения проблемы условного перехода
Несмотря на важность аспекта вычисления исполнительного адреса точки перехода, основные усилия проектировщиков ВМ направлены на решение проблемы условных переходов, поскольку именно последние приводят к наибольшим издержкам в работе конвейера. Для устранения или частичного сокращения этих издержек были предложены различные способы, которые условно можно разделить на четыре группы:
буферы предвыборки;
множественные потоки;
задержанный переход;
предсказание перехода.
Равномерность поступления команд на вход конвейера часто нарушается, например из-за занятости памяти или при выборке команд, состоящих из нескольких слов. Чтобы добиться ритмичности подачи команд на вход конвейера, между ступенью выборки команды и остальной частью конвейера часто размещают буферную память, организованную по принципу очереди (FIFO) и называемую буфером предвыборки. Буфер предвыборки можно рассматривать как несколько дополнительных ступеней конвейера. Подобное удлинение конвейера не сказывается на его производительности (при заданной тактовой частоте); оно лишь приводит к увеличению времени прохождения команды через конвейер. Типичные буферы предвыборки в известных процессорах рассчитаны на 2-8 команд.
Чтобы одновременно с обеспечением ритмичной работы конвейера решить и проблему условных переходов, в конвейер включают два таких буфера (рис. 52).
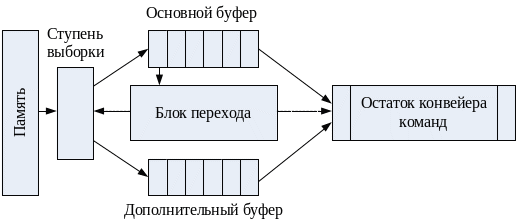
Рис. 52. Конвейер с буферами предвыборки команд.
Каждая извлеченная из памяти и помещенная в основной буфер команда анализируется блоком перехода. При обнаружении команды условного перехода (УП) блок перехода вычисляет исполнительный адрес точки перехода и параллельно с продолжением последовательной выборки в основной буфер организует выборку в дополнительный буфер команд, начиная с точки УП. Далее блок перехода определяет исход команды УП, в зависимости от которого подключает к остатку конвейера нужный буфер, при этом содержимое другого буфера сбрасывается. Упрощенный вариант подобного подхода применен в IBM 360/91, где дополнительный буфер рассчитан на одну команду, то есть выигрыш достигается за счет исключения времени на выборку команды из точки перехода.
Помимо необходимости дублирования части оборудования, у метода имеется еще один недостаток. Так, если в потоке команд несколько команд УП следуют одна за другой или находятся достаточно близко, количество возможных ветвлений увеличивается и, соответственно, должно быть увеличено и число буферов предвыборки.
Другим решением проблемы переходов служит дублирование начальных ступеней конвейера и создание тем самым двух параллельных потоков команд (рис. 53).

Рис. 53. Конвейер с множественными потоками.
В одной из ветвей такого «раздвоенного» конвейера последовательность выборки и выполнения команд соответствует случаю, когда условие перехода не выполнилось, во второй ветви – случаю выполнения этого условия. Для ранее рассмотренного примера (см. рис. 53) в одном из потоков может обрабатываться последовательность команд 4-6, а в другом – 15-17. Оба потока сходятся в точке, где итог проверки условия перехода становится очевидным. Дальнейшее продвижение по конвейеру продолжает только «правильный» поток. Основной недостаток метода состоит в том, что на конвейер или в поток может поступить новая команда УП до того, как будет принято окончательное решение по текущей команде перехода. Каждая такая команда требует дополнительного потока. Несмотря на это, стратегия позволяет улучшить производительность конвейера. Примерами ВМ, где используются два или более конвейерных потоков, служат IBM 370/168 и IBM 3033.
Стратегия задержанного перехода предполагает продолжение выполнения команд, следующих за командой УП, вне зависимости от ее исхода. Естественно, что это имеет смысл, лишь когда последующие команды являются «полезными», то есть такими, которые все равно должны быть когда-то выполнены, независимо от того, происходит переход или нет, и если команда перехода никак не влияет на результат их выполнения.
Для реализации этой идеи на этапе компиляции программы после каждой команды перехода вставляется команда «Нет операции». Затем на стадии оптимизации программы производятся попытки «перемешать» команды таким образом, чтобы по возможности большее количество команд «Нет операции» заменить «полезными» командами программы. Разумеется, замещать команду «Нет операции» можно лишь на такую, которая не влияет на условие выполняемого перехода, иначе полученная последовательность команд не будет функционально эквивалентной исходной. В оптимизированной программе удается заменить более 20% команд «Нет операции».