

2.5.10. Страничная адресация
Страничная адресация (СТА) предполагает разбиение адресного пространства на страницы. Страница определяется своим начальным адресом, выступающим в качестве базы. Старшая часть этого адреса хранится в специальном регистре —регистре адреса страницы (РАС). В адресном коде команды указывается смещение внутри страницы, рассматриваемое как младшая часть исполнительного адреса. Исполнительный адрес образуется конкатенацией (присоединением) Ас к содержимому РАС, как показано на рис. 32.
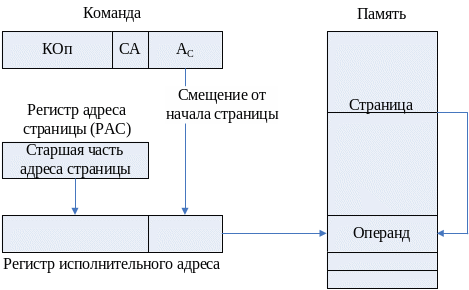
Рис. 32. Страничная адресация.
Показатели эффективности страничной адресации имеют вид:
ССТА = int(log2 Ni. - log2M),
TСТА = TРОН + TЗУ,
где М — количество страниц в памяти.
2.6. Цикл команды
Программа в фон-неймановской ЭВМ реализуется центральным процессором (ЦП) посредством последовательного исполнения образующих эту программу команд. Действия, требуемые для выборки (извлечения из основной памяти) и выполнения команды, называют циклом команды. В общем случае цикл команды включает в себя несколько составляющих (этапов):
выборку команды;
формирование адреса следующей команды;
декодирование команды;
вычисление адресов операндов;
выборку операндов;
исполнение операции;
запись результата.
Перечисленные этапы выполнения команды в дальнейшем будем называть стандартным циклом команды. Отметим, что не все из этапов присутствуют при выполнении любой команды (зависит от типа команды), тем не менее этапы выборки, декодирования, формирования адреса следующей команды и исполнения имеют место всегда.
В определенных ситуациях возможны еще два этапа:
косвенная адресация;
реакция на прерывание.
2.7. Основные показатели вычислительных машин
Использование конкретной вычислительной машины имеет смысл, если ее показатели соответствуют показателям, определяемым требованиями к реализации заданных алгоритмов. В качестве основных показателей ВМ обычно рассматривают: емкость памяти, быстродействие и производительность, стоимость и надежность. Остановимся только на показателях быстродействия и производительности, обычно представляющих основной интерес для пользователей.
Целесообразно рассматривать два вида быстродействия: номинальное и среднее. Номинальное быстродействие характеризует возможности ВМ при выполнении стандартной операции. В качестве стандартной обычно выбирают короткую операцию сложения. Если обозначить через τсл время сложения, то номинальное быстродействие определится из выражения
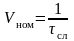 оп/с.
оп/с.
Среднее быстродействие характеризует скорость вычислений при выполнении эталонного алгоритма или некоторого класса алгоритмов. Величина среднего быстродействия зависит как от параметров ВМ, так и от параметров алгоритма и определяется соотношением
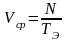 ,
,
где Тэ — время выполнения эталонного алгоритма; N — количество операций, содержащихся в эталонном алгоритме.
Обозначим через пi число операций г-го типа; l — количество типов операций в алгоритме (n = 1, 2,..., l); τi, — время выполнения операции i-ro типа.
Время выполнения эталонного алгоритма рассчитывается по формуле:
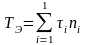
Подставив в выражение для Vcp, получим:
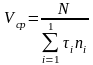 .
.
Разделим числитель и знаменатель на N:
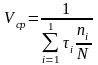 .
.
Обозначив частоту появления операции i-го типа через qi =ni/N , запишем окончательную формулу для расчета среднего быстродействия:
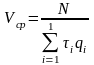
В выражении вектор {τ} характеризует систему команд ВМ, а вектор {q}, называемый частотным вектором операций, характеризует алгоритм.
Очевидно, что для эффективной реализации алгоритма необходимо стремиться к увеличению Vcp. Если VHOM главным образом отталкивается от быстродействия элементной базы, то Vср очень сильно зависит от оптимальности выбора команд ВМ.
Формула позволяет определить среднее быстродействие машины при реализации одного алгоритма.
Производительность ВМ оценивается количеством эталонных алгоритмов выполняемых в единицу времени:
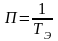 задач/с.
задач/с.
Производительность при выполнении полного алгоритма оценивается по формуле
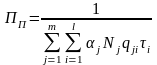 .
.
Производительность является более универсальным показателем, чем среднее быстродействие, поскольку в явном виде зависит от порядка прохождения задач через ВМ.