

Глава 6. Основные направления в архитектуре процессоров
Ранее уже были рассмотрены основные составляющие центрального процессора. В данной главе основное внимание уделено вопросам общей архитектуры процессоров как единого устройства и способам повышения их производительности.
6.1. Конвейеризация вычислений
Совершенствование элементной базы уже не приводит к кардинальному росту производительности ВМ. Более перспективными в этом плане представляются архитектурные приемы, среди которых один из наиболее значимых — конвейеризация.
Для пояснения идеи конвейера сначала обратимся к рис. 48, а, где показан отдельный функциональный блок (ФБ). Исходные данные помещаются во входной регистр Ргвх, обрабатываются в функциональном блоке, а результат обработки фиксируется в выходном регистре Ргвых. Если максимальное время обработки в ФБ равно Tmax, то новые данные могут быть занесены во входной регистр Рвх не ранее, чем спустя Tmах.
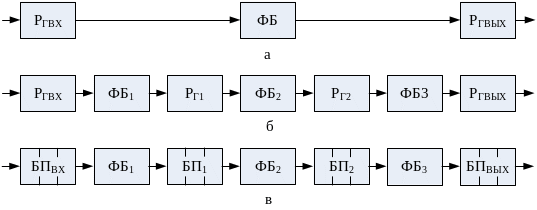
Рис. 48. Обработка информации. а – в одиночном блоке, б – в конвейере с регистрами, в – в конвейере с буферной памятью.
Теперь распределим функции, выполняемые в функциональном блоке ФБ (см. рис. 48, а), между тремя последовательными независимыми блоками: ФБ1, ФБ2 и ФБ3, причем так, чтобы максимальное время обработки в каждом ФБ, было одинаковым и равнялось Tmах/3. Между блоками разместим буферные регистры Рг (рис. 48, б), предназначенные для хранения результата обработки в ФБ(, на случай, если следующий за ним функциональный блок еще не готов использовать этот результат. В рассмотренной схеме данные на вход конвейера могут подаваться с интервалом Tmах /3 (втрое чаще), и хотя задержка от момента поступления первой единицы данных в Ргвх до момента появления результата ее обработки на выходе Ргвых по-прежнему составляет Tmах, последующие результаты появляются на выходе Ргвых уже с интервалом Tmах /3.
На практике редко удается добиться того, чтобы задержки в каждом ФБi были одинаковыми. Как следствие, производительность конвейера снижается, поскольку период поступления входных данных определяется максимальным временем их обработки в каждом функциональном блоке. Для устранения этого недостатка или, по крайней мере, частичной его компенсации каждый буферный регистр Рг, следует заменить буферной памятью БП„ способной хранить множество данных и организованной по принципу FIFO — «первым вошел — первым вышел» (рис. 48, в). Обработав элемент данных, ФБi заносит результат в БПi, извлекает из БПi-1 новый элемент данных и приступает к очередному циклу обработки, причем эта последовательность осуществляется каждым функциональным блоком независимо от других блоков. Обработка в каждом блоке может продолжаться до тех пор, пока не ликвидируется предыдущая очередь или пока не переполнится следующая очередь. Если емкость буферной памяти достаточно велика, различия во времени обработки не сказываются на производительности, тем не менее желательно, чтобы средняя длительность обработки во всех ФБ, была одинаковой.
В архитектуре вычислительных машин можно найти множество объектов, где конвейеризация обеспечивает ощутимый прирост производительности ВМ. Ранее уже рассматривались два таких объекта — операционные устройства и память, однако наиболее ощутимый эффект достигается при конвейеризации этапов машинного цикла.
По способу синхронизации работы ступеней конвейеры могут быть синхронными и асинхронными. Для традиционных ВМ характерны синхронные конвейеры. Связано это, прежде всего, с синхронным характером работы процессоров. Ступени конвейеров в процессоре обычно располагаются близко друг от друга, благодаря чему тракты распространения сигналов синхронизации получаются достаточно короткими и фактор «перекоса» сигналов становится не столь существенным. Асинхронные конвейеры оказываются полезными, если связь между ступенями не столь сильна, а длина сигнальных трактов между разными ступенями сильно рознится. Примером асинхронных конвейеров могут служить систолические массивы (систолическая обработка будет рассмотрена в последующих разделах).