

Глава 11. Маркетинговые исследования с использованием статистических методов
11.1. Прогнозирование объема продаж с использованием корреляционно-регрессионного анализа в системе statistica
В современных условиях практически все розничные торговые предприятия сталкиваются с необходимостью прогнозировать объемы продаж и оптимизировать существующий товарный ассортимент. Для достижения этих целей можно использовать значительное количество различных математико-статистических методов, одним из которых является корреляционно-регрессионный анализ.
Цель исследования – выявить и изучить зависимость между показателями продаж нескольких групп товаров розничного торгового предприятия с помощью пакета STATISTICA.
Особенности проведения корреляционно-регрессионного анализа в системе STATISTICA
Корреляционно-регрессионный анализ позволяет не только установить и оценить зависимость изучаемой случайной величины (y) от одной или нескольких других факторных величин (x), но и прогнозировать значения y.
Корреляционно-регрессионный анализ включает в себя следующие этапы.
Измерение тесноты связи между выбранными показателями.
Отбор главных существенных факторов, оказывающих влияние на зависимую переменную, и определение уравнения регрессии.
Проверка адекватности модели (определение числовых значений параметров уравнения регрессии).
Экономическая интерпретация результатов анализа.
Измерение тесноты связи между выбранными показателями в системе STATISTICA проводится в модуле Basic Statistics and Tables: Correlation matrices (основные статистики и таблицы: корреляционный анализ) путем расчета парных коэффициентов корреляции.
Степень линейной зависимости можно определить с помощью коэффициента корреляции Пирсона (линейного коэффициента корреляции), который рассчитывается по следующей формуле:
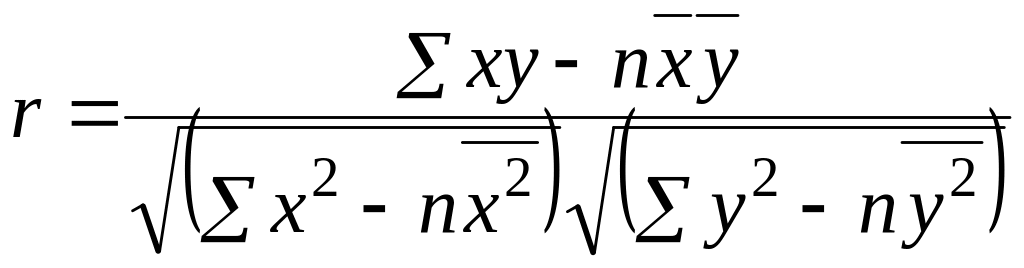 .
.
Значение линейного коэффициента корреляции находится между −1 и +1. Значения, близкие к +1, свидетельствуют о хорошей зависимости между параметрами, причем прямой зависимости. Значения, близкие к −1, также указывают на хорошую зависимость между переменными, но обратную зависимость. Значение «0» говорит об отсутствии линейной зависимости между данными.
Кроме того, в процессе исследования может возникнуть ситуация, когда одна величина коррелирует с другой, но эта связь означает, что обе величины коррелированны с некой третьей величиной или набором величин, которые не вошли в исследование корреляционной зависимости. В этом случае рассматривается условная корреляция между двумя величинами при фиксированных значениях остальных величин. Эту корреляцию называют частной. Коэффициент частной корреляции определяется по особой формуле: например, для переменных X, Y, Z коэффициент частной корреляции rXY*Z между переменными X и Y при фиксированном значении переменной Z можно вычислить так:
![]() .
.
Аналогично рассчитывают коэффициенты частной корреляции rXZ*Y и rYZ*X:
![]() ;
;
![]() .
.
Следует заметить, что представленные выше формулы симметричны, знаком «*» отделяются друг от друга переменные, значения которых фиксированы.
В процессе осуществления корреляционно-регрессионного анализа возникает необходимость расчета множественного коэффициента корреляции. Уравнение регрессии имеет вид:
y=a + bx1 + cx2.
Коэффициенты a, b, c – неизвестные параметры. В широких предположениях оптимальными оценками неизвестных параметров a, b, c являются оценки метода наименьших квадратов. Обозначим оценки метода наименьших квадратов через A, B, C. Эти оценки хороши тем, что сумма квадратов расстояний между наблюдениями y и плоскостью, задаваемой уравнением регрессии, минимальна. Затем, используя оценки метода наименьших квадратов, получаем значения Y. Теперь коэффициент множественной корреляции между y, x1 и x2 можно определить как обычный коэффициент корреляции Пирсона между y и Y.
Для расчета частного и множественного коэффициентов корреляции используют модуль Multiple Regression (множественная регрессия) в системе STATISTICA.
Кроме того, модуль Multiple Regression системы STATISTICA позволяет реализовать метод пошаговой регрессии, гребневой регрессии, осуществить анализ остатков и прогноз зависимой переменной при изменении значений независимых переменных.
Методы пошаговой регрессии позволяют из множества независимых переменных отобрать только те, которые наиболее значимы для адекватного описания модели множественной регрессии. В модуле Multiple Regression реализованы две процедуры отбора переменных, каждая из которых может давать различный конечный набор переменных – в частности, последовательное включение (Forward stepwise) и последовательное исключение (Backward stepwise). В процедуре пошаговой регрессии с последовательным включением система начинает построение модели с одной независимой переменной; затем, используя F-критерий, в модель включают еще одну переменную и т. д. Если предполагается, что в модели должно присутствовать небольшое количество независимых переменных, то лучше использовать метод пошаговой регрессии с включением. При другой ситуации, когда предполагается, что в модели должно присутствовать большое количество независимых переменных, то рекомендуют использовать метод с исключением.
Гребневая регрессия используется для получения более устойчивых оценок параметров регрессионной модели в условиях мультиколлинеарности переменных.
Установление зависимости между объемами продаж некоторых групп товаров розничного торгового предприятия
Для выявления и изучения зависимости между показателями продаж нескольких групп товаров одного из розничных торговых предприятий города Зеленограда был проведен корреляционно-регрессионный анализ с использованием программного пакета STATISTICA. Анализировали совокупность данных по объему продаж девяти групп продовольственных товаров и двенадцати групп непродовольственных товаров за период с 01.01.2006 г. по 31.12.2006 г. (помесячно).
Продовольственные товары:
бакалея;
вино;
гастрономия;
кондитерские изделия;
крепкие напитки и ликеры;
кулинария;
овощи-фрукты;
сыры;
чипсы-сухарики.
Непродовольственные товары
-
бытовая косметика;
бытовая химия;
гигиенические товары;
декоративная косметика;
зонты;
канцтовары;
нижнее белье;
одноразовая посуда;
парфюмерия;
подарки, кожгалантерея;
посуда;
товары для дома.
Затраты на получение таких данных для предприятия минимальны, поскольку ими располагает практически каждая организация.
Цель исследования – выявить связь между покупкой посетителями магазина товаров различных групп.
В программный пакет STATISTICA занесли данные объема продаж по 21 товарной группе и с помощью модуля Basic Statistics and Tables: Correlation matrices рассчитали парные коэффициенты корреляции.
Результаты корреляционного анализа представлены в корреляционных матрицах (таблицы 11.1 и 11.2).
Таблица 11.1
Корреляционная матрица объема продаж 9 групп продовольственных товаров
|
|
Бакалея |
Вино |
Гастрономия |
Кондитерские изделия |
Крепкие напитки и ликеры |
Кулинария |
Овощи-фрукты |
Сыры |
Чипсы-сухарики |
|
Бакалея |
1,00 |
0,57 |
0,21 |
0,12 |
0,34 |
0,03 |
0,54 |
0,26 |
−0,10 |
|
Вино |
0,57 |
1,00 |
0,75 |
0,50 |
0,90 |
0,49 |
0,52 |
0,84 |
0,33 |
|
Гастрономия |
0,21 |
0,75 |
1,00 |
0,62 |
0,88 |
0,87 |
−0,07 |
0,94 |
0,31 |
229 |
Кондитерские изделия |
0,12 |
0,50 |
0,62 |
1,00 |
0,64 |
0,67 |
0,13 |
0,71 |
0,27 |
|
Крепкие напитки и ликеры |
0,34 |
0,90 |
0,88 |
0,64 |
1,00 |
0,73 |
0,21 |
0,98 |
0,19 |
|
Кулинария |
0,03 |
0,49 |
0,87 |
0,67 |
0,73 |
1,00 |
−0,28 |
0,83 |
0,06 |
|
Овощи-фрукты |
0,54 |
0,52 |
−0,07 |
0,13 |
0,21 |
−0,28 |
1,00 |
0,08 |
0,29 |
|
Сыры |
0,26 |
0,84 |
0,94 |
0,71 |
0,98 |
0,83 |
0,08 |
1,00 |
0,20 |
|
Чипсы-сухарики |
−0,10 |
0,33 |
0,31 |
0,27 |
0,19 |
0,06 |
0,29 |
0,20 |
1,00 |
Таблица 11.2
Корреляционная матрица объема продаж 12 групп промышленных товаров
230 |
|
Бытовая косметика |
Бытовая химия |
Гигиенические товары |
Декоративная косметика |
Зонты |
Канцтовары |
Нижнее белье |
Одноразовая посуда |
Парфюмерия |
Подарки, кожгалантерея |
Посуда |
Товары для дома |
Бытовая косметика |
1,00 |
0,70 |
0,73 |
0,52 |
0,19 |
0,24 |
0,85 |
0,35 |
0,82 |
0,96 |
0,83 |
0,95 |
|
Бытовая химия |
0,70 |
1,00 |
0,85 |
0,15 |
0,30 |
0,14 |
0,59 |
0,17 |
0,46 |
0,69 |
0,65 |
0,70 |
|
Гигиенические товары |
0,73 |
0,85 |
1,00 |
0,30 |
0,31 |
0,21 |
0,65 |
0,55 |
0,45 |
0,67 |
0,64 |
0,82 |
|
Декоративная косметика |
0,52 |
0,15 |
0,30 |
1,00 |
−0,21 |
0,29 |
0,60 |
0,07 |
0,71 |
0,56 |
0,68 |
0,55 |
|
Зонты |
0,19 |
0,30 |
0,31 |
−0,21 |
1,00 |
0,33 |
0,13 |
0,09 |
−0,03 |
0,15 |
0,12 |
0,16 |
|
Канцтовары |
0,24 |
0,14 |
0,21 |
0,29 |
0,33 |
1,00 |
0,25 |
−0,24 |
0,36 |
0,43 |
0,56 |
0,30 |
|
Нижнее белье |
0,85 |
0,59 |
0,65 |
0,60 |
0,13 |
0,25 |
1,00 |
0,40 |
0,75 |
0,84 |
0,69 |
0,92 |
|
Одноразовая посуда |
0,35 |
0,17 |
0,55 |
0,07 |
0,09 |
−0,24 |
0,40 |
1,00 |
0,01 |
0,13 |
−0,01 |
0,49 |
|
Парфюмерия |
0,82 |
0,46 |
0,45 |
0,71 |
−0,03 |
0,36 |
0,75 |
0,01 |
1,00 |
0,90 |
0,86 |
0,77 |
|
Подарки, кожгалантерея |
0,96 |
0,69 |
0,67 |
0,56 |
0,15 |
0,43 |
0,84 |
0,13 |
0,90 |
1,00 |
0,91 |
0,91 |
|
Посуда |
0,83 |
0,65 |
0,64 |
0,68 |
0,12 |
0,56 |
0,69 |
−0,01 |
0,86 |
0,91 |
1,00 |
0,80 |
|
Товары для дома |
0,95 |
0,70 |
0,82 |
0,55 |
0,16 |
0,30 |
0,92 |
0,49 |
0,77 |
0,91 |
0,80 |
1,00 |
Данные матрицы содержат значения парных коэффициентов корреляции, которые показывают силу и направление связи между исследуемыми переменными (объемами продаж 21 группы товаров). Сильной считается связь, если коэффициент корреляции между переменными по модулю равен 0,7 и выше.
В качестве примера рассмотрим товарную группу «Вино» (из таблицы 11.1) и товарную группу «Гигиенические товары» (из таблицы 11.2). По данным корреляционных матриц, группа «Вино» наиболее тесно связана с 3 группами: «Гастрономия», «Крепкие напитки и ликеры» и «Сыры» (коэффициенты корреляции равны 0,75, 0,90 и 0,84 соответственно). Группа «Гигиенические товары» коррелирует с товарными группами: «Бытовая косметика», «Бытовая химия» и «Товары для дома» (коэффициенты корреляции равны 0,73, 0,85 и 0,82 соответственно).
На практике предприятия розничной торговли могут использовать полученные результаты корреляционного анализа, чтобы: пополнять товарные запасы путем в процессе совместной закупки товаров, объемы продаж которых коррелируют между собой; выкладывать эти товары по соседству в торговом зале; экономить денежные средства на продвижение нескольких товаров (стимулировать покупку одного товара можно за счет стимулирования покупки другого).
Построение прогнозной модели изменения объема продаж группы товаров «Кондитерские изделия»
В
Multiple
Regression Results
Dependent:
КОНДИТЕРСКИЕ
ИЗДЕЛИЯ
Multiple R = ,71100039 F = 10,22333
R?=
,50552155 df = 1,10 No.
of cases: 12 adjusted R?= ,45607371 p = ,009534
Standard
error of estimate:7401,8413531
Intercept:
150628,26435 Std.Error: 19064,41 t( 10) = 7,9010 p = ,0000
СЫРЫ
beta=,711
(significant
betas are highlighted)
Рис. 11.1. Результаты регрессионного анализа
Dependent – имя зависимой переменной;
No. of cases – объем выборки, n = 12;
Multiple R – оценка коэффициента множественной корреляции; характеризует тесноту линейной связи между зависимой и всеми независимыми переменными. Может принимать значения от 0 до 1.
R2 – оценка коэффициента детерминации; численно выражает долю вариации зависимой переменной, объясненную с помощью регрессионного уравнения. Чем больше R2, тем большую долю вариации объясняют переменные, включенные в модель.
adjusted R2 – скорректированный коэффициент детерминации; скорректированный R2 можно с большим успехом (по сравнению с R2) применять для выбора наилучшего подмножества независимых переменных в регрессионном уравнении.
F – значение F-критерия расчетный.
df – число степеней свободы F-критерия.
p – уровень значимости.
Standard error of estimate – стандартная ошибка оценки, оценивает меру рассеяния наблюдаемых значений относительно регрессионной прямой.
Intercept – оценка свободного члена, значения коэффициента b0 в уравнении регрессии.
Std.Error – стандартная ошибка коэффициента b0 в уравнении регрессии.
t(df) и p-value – значение t-критерия и уровня p.
beta – β-коэффициенты уравнения: это стандартизированные регрессионные коэффициенты, рассчитанные по стандартизированным значениям переменных. По их величине можно сравнить и оценить значимость независимых переменных в регрессионной модели, так как β-коэффициент показывает, на сколько единиц стандартного отклонения изменится зависимая переменная при изменении на одно стандартное отклонение независимой переменной при условии постоянства остальных независимых переменных.
Теперь рассмотрим основные результаты регрессионного анализа более подробно.
R egression
Summary for Dependent Variable: Кондитерские
изделия
egression
Summary for Dependent Variable: Кондитерские
изделия
(табл продажи кор-регр ан итог)
R= ,71100039 R?= ,50552155 Adjusted R?= ,45607371
F(1,10)=10,223 p<,00953 Std.Error of estimate: 7401,8
N=12
|
Beta |
Std.Err. |
B |
Std.Err. |
t(10) |
p-level |
Intercept |
|
|
150628,26 |
19064,41 |
7,901017 |
0,000013 |
Сыры |
0,711000 |
0,222369 |
0,24 |
0,08 |
3,197394 |
0,009534 |
Рис. 11.2. Результаты работы модуля «Multiple Regression»
Beta – стандартизованные β-коэффициенты уравнения регрессии.
Std.Err. of Beta – стандартные ошибки β-коэффициентов.
B – коэффициенты уравнения регрессии.
Std.Err. of B – стандартные ошибки коэффициентов уравнения регрессии.
t(3) – t-критерии для коэффициентов уравнения регрессии.
p-level – уровень значимости.
Для проверки адекватности полученной модели используют табличные значения F-критерия Фишера для уровня значимости p = 0,05. В рассматриваемой нами модели Fфакт.>F(3,8) – следовательно, модель адекватно отражает зависимость между факторами и нет оснований отказываться от ее применения на практике.
Таким образом, в результате проведенного регрессионного анализа получено следующее уравнение взаимосвязи между объемом продаж товарной группы «Кондитерские изделия» (Y, тыс. руб.) и объемом продаж товарной группы «Сыры» (X, тыс. руб.):
Y = 150628,26 + 0,24X.
Кнопка Predict dependent variable в модуле «Multiple Regression» позволяет рассчитать по полученному регрессионному уравнению значение зависимой переменной по значению независимой переменной. Зададим для этого следующее конкретное значение фактора – например, X = 350 000 (тыс. руб.).
Прогнозируемые значения переменной «Кондитерские изделия»
P redicting
Values for (табл
продажи
кор-регр
ан
итог)
redicting
Values for (табл
продажи
кор-регр
ан
итог)
variable: Кондитерские изделия
|
B-Weight |
Value |
B-Weight |
Сыры |
0,243515 |
350 000,0 |
85230,2 |
Intercept |
|
|
150 628,3 |
Predicted |
|
|
235 858,5 |
-95,0%CL |
|
|
218 028,0 |
+95,0%CL |
|
|
253 689,0 |
Рис. 11.3
Как видно из рисунка 11.3, прогнозируемое значение Y (Predicted) составит 235 858,51 тыс. руб.
В заключение следует отметить, что цель данного исследования – не только построить модель прогноза изменения объемов продаж по товарным группам, но и продемонстрировать применение программы STATISTICA для этих целей. В нашем примере для построения модели с целью иллюстрации использовался только один фактор, на практике в модель, как правило, включают больше факторных переменных, оказывающих существенное влияние на результативный показатель. При помощи корреляционно-регрессионного анализа предприятие розничной торговли может не только планировать предполагаемый объем продаж и ожидаемую прибыль, но и использовать полученные зависимости, чтобы сокращать издержки на поддержание товарных запасов и экономить денежные средства на стимулирование продаж.