

52. Кодирование источников без памяти: код шеннона-фано
Все кодируемые символы исх. алфавита перечисляются в порядке уменьшения их вероятностей. Все символы делятся на М примерно равновероятных групп. Верхней группе ставится в соответствие 0, нижней – 1. Затем обе группы снова разбиваются на М подгрупп, верхней группе ставится в соответствие 0, нижней – 1. Такое разбиение продолжается до тех пор, пока в таблице не исчезнут префиксно зависимые кодовые слова.
53. КОДИРОВАНИЕ ИСТОЧНИКОВ БЕЗ ПАМЯТИ: КОД ХАФФМАНА
Таблица кодирования строится как процесс формирования дерева (дерево кодирования Хаффмана). Исх. символы изображаются
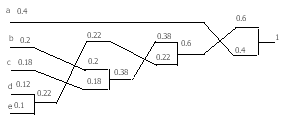
Этим символам ставятся в соответствие листья сформир.дерева. К листу направляется ветвь, возле кот. записываются вероятности листа. 2 самые нижние ветви формируют вершину ветвления, к кот. направл. ветвь с суммарной вероятностью. Далее формируется след. уровень дерева, в кот. нижележащие вершины упорядочены по вероятности. После построения дерева ветви, исходящие из каждой вершины ветвления, снабжаются двоичным решением. Верхняя ветвь – 1, нижняя – 0(или наоборот). Такой алгоритм формирования дерева наз. методом пузырька, т.к. после каждого «объединения» двух вершин полученная вершина-родитель поднимается до уровня, соответсв. суммарной вероятности. Для построения кода осущ-ся переход (спуск по дереву) от корня к каждому листу. При переходе в код заносятся попавшиеся двоич.решения.
54. Кодирование источников с памятью: методы подавления нулей и групповое кодирование
Кодирование Хаффмана в чистом виде не применяется, т.к. у него есть недостатки. Во-первых, нужно знать вероятности, приписываемые отд. символам источника. Во-вторых, если алфавит очень велик, то велико и дерево кодирования, которое передается файлам кода в виде заголовка. В-третьих, в коде обычно часто встречаются повторяющиеся комбинации символов кода. Например, графич. файл может иметь коды миллиона пикселей, расположенных рядом. При этом части кодов таких пикселей совпадают.
В методе подавления нулей последовательность часто повторяющихся символов заменяется лексемой, кот. может состоять из 2 частей: самого повтор. символа и числа его повторений. Обычно в качестве такого символа выбирается 0. Если в двоич. коде сообщения появляется 37 нулей, то они заменяются лексемой <37>.
Групповое кодирование – это расширенное подавление нулей, при котором заменяются числом повторений группы смежных символов. Если лексема формируется из числа повторения нулей и единиц, то код 111111000000111 имеет вид 663.
55. Кодирование источников с памятью: методы подстановки образцов и дифференциальное сжатие
В методе подстановки
образцов часто повторяющиеся комбинации
кода заменяются метасимволами. Например,
нач.кодовые комбинации посылаются
пользователю и формируют так называемый
словарь образцов. При поступлении
очередной кодовой комбинации для нее
ищется в словаре образцов элемент. В
случае его нахождения вместо посылаемой
комбинации посылается метасимвол,
состоящий из 3 компонентов: адрес
(порядковый номер образца в словаре),
кол-во выбираемых из образца символов
(совпадающим с нач.кода), добавляется
новый символ. Он не только пересылается,
но и добавляется в словарь образцов.
Дифференциальное сжатие используется
при передаче аналоговых сигналов. До
передачи выборки анал.сигналы квантуются.
Само квантование уже является сжатием.
При обычной передаче квантуются выборки
Xs(n).
При диффер.сжатии квантованию подвергаются
разность текущего и предыдущего отсчетов
: d(n)=xs(n)-xs(n-1).
Таким обр. посылаются квантованные
значения dq(n).
Т.к. амплитуды остатков d(n)
значительно меньше амплитуд исх.сигнала
xs(n),
то для их передачи (dq(n))
требуется значительно меньшая полоса
частот: ![]() =
dq(n)+
=
dq(n)+
![]() . Такое
сжатие наз-ся дифференциально-импульсно-кодвой
модуляцией (ДИКМ или DPCM).
. Такое
сжатие наз-ся дифференциально-импульсно-кодвой
модуляцией (ДИКМ или DPCM).