

2.2 Тест Дарбина-Уотсона для серийной корреляции
Один
из подходов, часто используемых для
выявления наличия серийной корреляции,
состоит в применении критерия
Дарбина-Уотсона. Этот критерий определяет,
можно ли считать равным нулю параметр
![]() ,
присутствующий в уравнении:
,
присутствующий в уравнении:
![]()
Необходимо выбрать одну из двух гипотез:
![]()
![]()
Если регрессионная модель не свободна от автокорреляции, остатки будут автокоррелирующими. Поэтому в критерии Дарбина-Уотсона выводы строятся на основании величин остатков, полученных при регрессионном анализе.
Статистика Дарбина-Уотсона определяется следующим равенством:
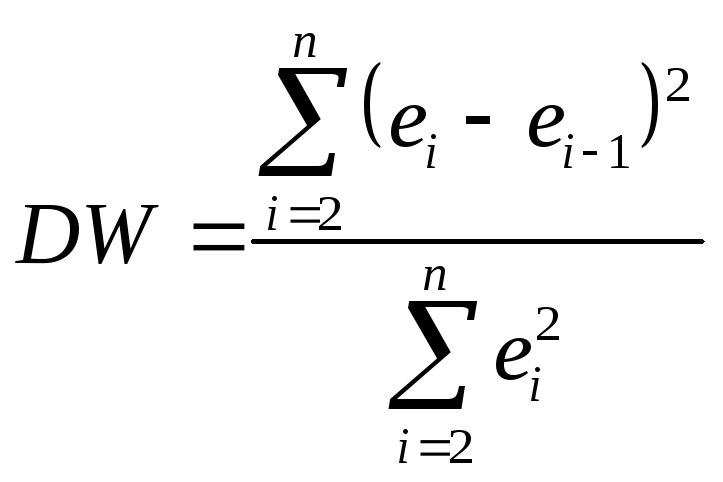
где
![]() - остаток для периода времени t;
- остаток для периода времени t;
![]() -
остаток для периода времени t-1.
-
остаток для периода времени t-1.
При положительной серийной автокорреляции последовательные серийные остатки имеют тенденцию быть близкими по величине и сумма квадратов разностей в числителе статистики Дарбина-Уотсона будет сравнительно мала. Наличие малых значений у статистики Дарбина-Уотсона указывает на положительную серийную корреляцию.
Коэффициент
автокорреляции
![]() можно также оценить с помощью величины
автокорреляции остатков с запаздыванием,
равным 1 – r1(e).
С помощью несложных преобразований
можно показать, что значение статистики
Дарбина-Уотсона связано с величиной
r1(e).
Для средних и больших выборок
можно также оценить с помощью величины
автокорреляции остатков с запаздыванием,
равным 1 – r1(e).
С помощью несложных преобразований
можно показать, что значение статистики
Дарбина-Уотсона связано с величиной
r1(e).
Для средних и больших выборок
DW= 2(1 – r1(e))
Поскольку -1 < r1(e) < 1, то 0 < DW< 4. Для r1(e), близкого к нулю, статистика DW будет близка к 2. Положительная автокорреляция с запаздыванием 1 связана со значениями DW, меньшими 2, а отрицательная автокорреляция с запаздыванием 1 связана со значениями DW, большими 2.
Полезный (но не всегда определяющий) критерий серийной корреляции основан на сравнении вычисленного значения статистики Дарбина-Уотсона с нижней (L) и верхней (U) границами. Выводы делаются на основании следующих правил.
1
Если значение статистики Дарбина-Уотсона
больше верхней границы (U),
коэффициент автокорреляции
![]() равен нулю (нет положительной
автокорреляции).
равен нулю (нет положительной
автокорреляции).
2
Если значение статистики Дарбина-Уотсона
меньше нижней границы (L),
коэффициент автокорреляции
![]() больше нуля (есть положительная
автокорреляция).
больше нуля (есть положительная
автокорреляция).
3 Если значение статистики Дарбина-Уотсона находится между нижней и верхней границами, критерий не дает ответа (неизвестно, имеет ли место положительная автокорреляция).
Значения границ L и U приведены в специальных таблицах. Чтобы найти необходимые значения L и U, требуется знать размер выборки, уровень значимости и количество независимых переменных.
Как
следует из уравнения, можно делать
выводы о знаке и величине коэффициента
автокорреляции остатков с запаздыванием
1 по значению статистики Дарбина-Уотсона
и наоборот. Так, для ситуации, в которой
критерий DW не дает ответа, значимость
серийной корреляции может быть исследована
через сравнение r1(e)
с величиной
![]() .
Если r1(e)
попадает в интервал
.
Если r1(e)
попадает в интервал
![]() ,
правомочно сделать вывод о том, что
автокорреляция мала и может не учитываться.
,
правомочно сделать вывод о том, что
автокорреляция мала и может не учитываться.
2.3 Решение проблемы автокорреляции
Если в данных временных рядов обнаружена автокорреляция, ее необходимо нейтрализовать или как-то учесть, прежде чем полученную функцию регрессии можно будет использовать для прогноза. Выбор подходящего метода обработки данных при наличии серийной корреляции зависит от того, что является ее первопричиной. Автокорреляция может появиться из-за некоторой систематической ошибки - например, пропущенной переменной. В других случаях коррелируют слагаемые ошибок в корректно определенной во всех остальных отношениях модели.
Решение проблемы серийной автокорреляции начинается с оценки модели регрессии. Подходит ли ее функциональная форма? Не пропущена ли важная независимая переменная? Имеются ли какие-то повторяющиеся явления, которые накладывают свой отпечаток на значения данных во времени и вызывают эффект автокорреляции ошибок?
Поскольку основной причиной автокорреляции ошибок в регрессионной модели является пропуск одной или нескольких важных переменных, наилучший подход к решению проблемы - найти их. В некоторых случаях подобные действия называют процедурой улучшения спецификации модели. Спецификация модели включает не только выбор необходимых независимых переменных, но и введение этих переменных в функцию регрессии должным образом. К сожалению, модель может быть улучшена не всегда - пропущенные переменные могут не поддаваться количественному определению или же данные по ним могут быть просто недоступны. Тем не менее, когда это возможно, спецификация модели обязательно должна быть согласована с теоретическим смыслом и интуитивным пониманием величин данных.
Один из методов устранения влияния автокорреляции - добавление в функцию регрессии пропущенной переменной, объясняющей связь значений зависимой переменной в разные периоды времени.
При другом методе устранения этого влияния используется общее понятие дифференциации. В данном случае регрессионная модель определяется в терминах изменений величин. Например, использование в регрессии выраженного в процентах изменения зависимой переменной вместе с выраженными в процентах изменениями независимых переменных. Наконец, вместо простых или первых разностей для устранения влияния автокорреляции в модели регрессии может потребоваться использовать обобщенные разности.
Для того чтобы устранить серийную корреляцию для сильно автокоррелирующих данных, можно использовать разности их значений. Так, вместо записи уравнения регрессии относительно переменных Y и Х данное уравнение может быть записано для разностей. Разности следует использовать, когда значение статистики Дарбина-Уотсона, вычисленное для начальных переменных, близко к нулю.
Тогда используется следующая модель
![]()
где штрих обозначает обобщенные разности:
![]()
![]()
Преобразованное
уравнение включает ошибки
![]() ,
которые представляют собой независимые
случайные величины с нулевым математическим
ожиданием и постоянной дисперсией.
Следовательно, к данной регрессионной
модели можно применять обычные методы
регрессии.
,
которые представляют собой независимые
случайные величины с нулевым математическим
ожиданием и постоянной дисперсией.
Следовательно, к данной регрессионной
модели можно применять обычные методы
регрессии.
Если
корреляция между последовательными
ошибками велика (![]() близко к 1), то обобщенные разности, по
существу, равны простым или первым
разностям:
близко к 1), то обобщенные разности, по
существу, равны простым или первым
разностям:
![]()
![]()
и свободный член в модели близок к нулю (пропадает).
Использование регрессионных моделей, построенных для обобщенных разностей, часто позволяет устранить серийную корреляцию. Если серийная корреляция особенно велика, целесообразно использовать обычные разности.