

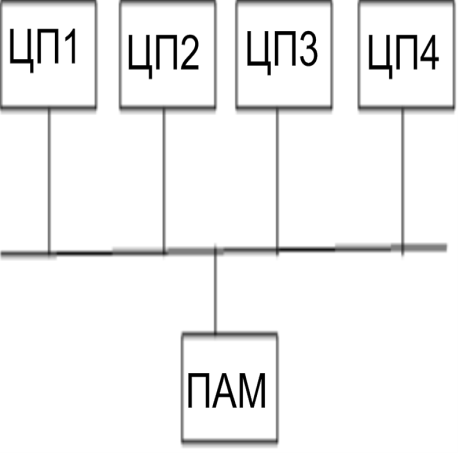
56. Проблемы когерентности кэш памяти в многопроцессорных системах. Протокол mesi. Системы с массовым параллелизмом.
Протокол mesi для поддержания когерентности. Единица данных – строка КЭШа, минимальная порция данных. С каждой строкой связано 4 бита, описывающих состояние:
М - строка модифицирована (доступна по чтению и записи только в этом ВМ, потому что модифицирована командой записи по сравнению со строкой основной памяти);
Е - строка монопольно копированная (доступна по чтению и записи в этом ВМ и в основной памяти);
S - строка множественно копированная или разделяемая (доступна по чтению и записи в этом ВМ, в основной памяти и в кэш-памятях других ВМ, в которых содержится ее копия);
I - строка, невозможная к использованию (строка не доступна ни по чтению, ни по записи).
Состояние строки используется, во-первых, для определения процессором ВМ возможности локального, без выхода на шину, доступа к данным в кэш-памяти, а, во-вторых, - для управления механизмом когерентности.
Для управления режимом работы механизма поддержки когерентности используется бит WT, состояние 1 которого задает режим сквозной (write-through) записи, а состояние 0 - режим обратной (write-back) записи в кэш-память.
в начальный момент времени все строки памяти помечаются как I ЦП1 прочитал одно значение. Оно помечается как Е. Если данные помечены как Е, то он с ними все, что хочет. Они в основную память не переписываются, ни какие сигналы не передаются. ЦП2 прочитал туже самую величину, эта строка переводиться в состояние S. Доступ по чтению они организуют одним и тем же образом. Пусть ЦП2 изменил строку. Тогда строка переходит в состояние М. ЦП3 пытается обратиться к этой же самой строке. ЦП2 отслеживает это обращение, блокирует его, производит запись в память и после этого разрешает запись для ЦП3. Теперь ЦП1 тоже изменил данные и записывает их в память. ЦП2 и ЦП3 отслеживают шины и определяют что их данные кто-то меняет. При этом данные в ЦП2 и ЦП3 переходят в состояние I. Данные переписываются в память, а состояние записывается как Е.
Микропроцессоры семейства Pentium Pro.
Проц состоит из 3-х независимых блоков. 1 блок декодирование команд 2 – планирование 3- выполнение. Т.к блоки независимы, то команды могут выполняться не в том порядке, в каком они были описаны в программе. Конвейер имеет длину в 14 этапов.
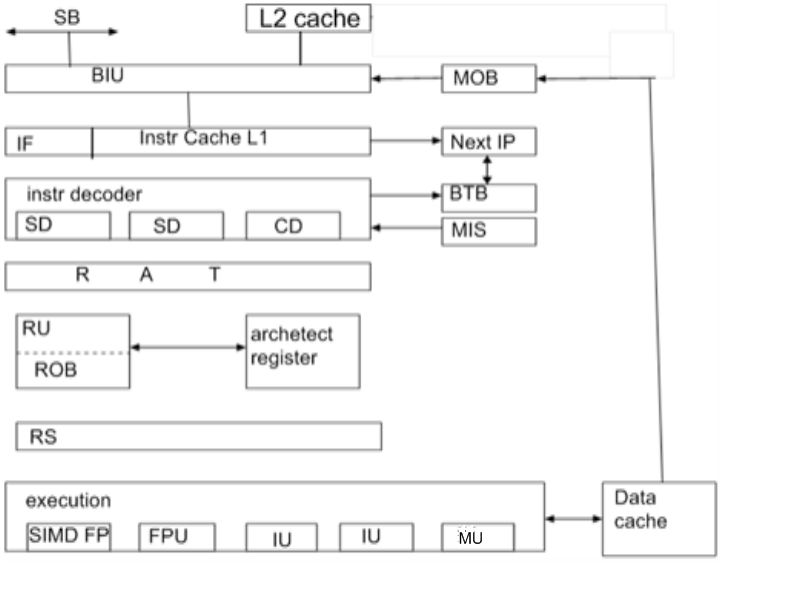
ROB + MOB – in order back-end
BIU – bus Interface unit
IF – устройство выборки команд. Оно выбирает из памяти выравненые блоки.
NEXT Ip – устройство предсказания переходов. Точность предсказаний >90%. Декодеры содержат 3 параллельных команды : 2 простых (simple decoder) и одну сложную (complex decoder). В среднем 3 декодера выдают 3 команды за 1 такт. Если СD не может обработать команду однозначно. То MIS обрабатывает их микропрограммно
RAT – таблица отображения регистров на него опираются Ru и ROB. RS – станция резервирования. Она отслеживает команд, снабженные всеми ресурсами. И пересылает одно в другое. Всего имеется 5 исполнительных устройств
SIMDFP – MMX
FP – с плавающей точкой
IU – целочисленные операции
MU – пересылка в память
Одновременно может выполняться 4 команды.
RU – устройство удаления. Удаляет выполненные команды из RS.
MOB – устройство упорядочивания обращения к памяти. Отслеживает команды, которые выводят результат в память. Результаты должны записываться в том же порядке, что и поступила. У Р6 есть недостаток. L2 Cache находится в одном корпусе что и процессор -> в 2 раза дороже и в 2 раза больше браке –> выпускался не долго.
Архитектура Pentium IV, технология Hyper Threading.
В Пентиум 4 был разработан мегаконвейер. Частота увеличилась с 1Гц до 1,5 Гц.
f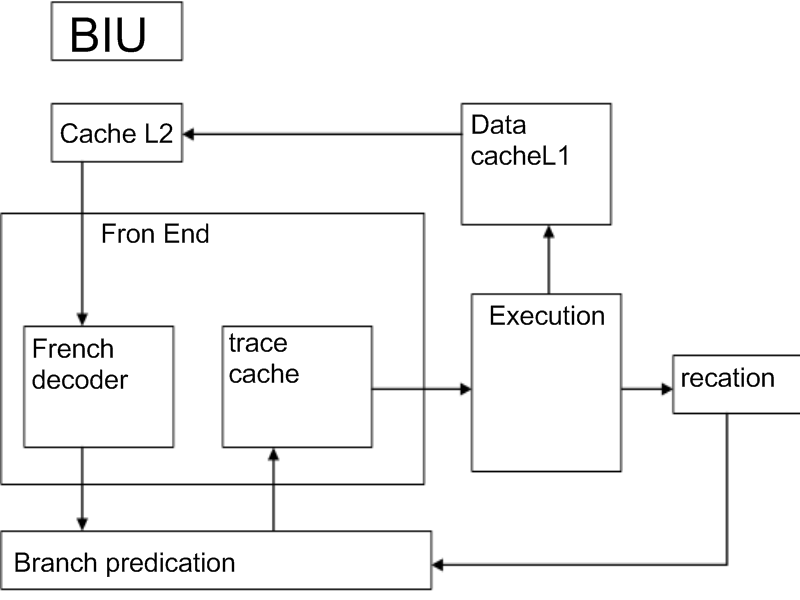 ront
end
– декодирование команд.
ront
end
– декодирование команд.
Execution устройство не упорядоченного выполнения
Reticount упорядоченное завершение, удаление команд из процессора.
Cache L2 – перемещен во внутрь. Есть тяжелый и неповоротливый блок декодирования команд. В процессоре сложные команды декодируются и превращаются в микрокоманды.
в место
того, чтобы перезапускать декодер при
каждой ошибки ветвления, результаты
сохраняются вtrace
cache.
Это кэш команд, но не исходных, а
микрокоманд + микрокоманды упорядочиваются
в соответствии с текущем алгоритмом.
Объявлено 20 этапов конвейера, но не
включен декодер. Устройство предсказания
переходов имеет 4000 ячеек предсказания
команд. Более сложный линейный алгоритм
предсказания -> точность 93-94%.
место
того, чтобы перезапускать декодер при
каждой ошибки ветвления, результаты
сохраняются вtrace
cache.
Это кэш команд, но не исходных, а
микрокоманд + микрокоманды упорядочиваются
в соответствии с текущем алгоритмом.
Объявлено 20 этапов конвейера, но не
включен декодер. Устройство предсказания
переходов имеет 4000 ячеек предсказания
команд. Более сложный линейный алгоритм
предсказания -> точность 93-94%.
Планировщик рассматривает одновременно 128 команд, каждая команда дожидается момента, когда будут готовы ресурсы.
4 ALU-целочисленные опр
2 AGN – адресное устройство
2 устройства с плавающей точкой.
Блок выполнения работает на частоте в 2 раза больше тактовой
Технология Hyper Threading. Есть задача, которая состоит из независимых потоков. Идея состоит в том, чтобы смешивать несколько нитей в один поток, один физически, представляется как два логически, каждый со своими регистрами, таблицами прерываний и т.п.
Пусть у нас есть
ALU * [__] [__]
ALU * [__] [__]
FP [__] * [__]
MEM [__] [__] *
Вместо 12 команд выполняются 4. Устройства, которые свободны, занимаются другой веткой. Такая технология позволяет увеличить нагрузку с 25-30% до 40-50%
Архитектура IA- 64. Предикатное исполнение команд.
Архитектура IA- 64.
В середине 90-х годов специалистами hp и Intel была предложена так называемая архитектура явно параллельного исполнения команд, которая позволяет исполнять до 8 команд за один такт.
В основу этой архитектуры были положены:
Явный параллелизм - поиск зависимостей и предсказание были возложены на компилятор. Компилятор получил возможность перед генерацией исходного кода осмотреть весь исходный файл и проанализировать его на возможный запуск параллельных процессов.
Предикация - команды из разных ветвей условного ветвления снабжаются предикатными полями (предикатами) и запускаются параллельно. Это дало возможность получить результаты исполнения обоих или одного из условий к моменту проверки следующего.
Загрузка по предположению - данные из медленной основной памяти помещаются в сверх быстрый кэш заранее, таким образом, они доступны к началу исполнения следующей команды. Все операнды собраны и доступны для обработки.
Ключевыми стимулирующими особенностями являются:
открытая архитектура: основывается на открытости и повсеместном принятии отраслевых стандартов, которые делают её доступной для независимых компаний, занимающихся разработкой аппаратного и программного обеспечения;
конкуренция и сотрудничество: огромное сообщество разработчиков с одной стороны ускоряет развитие платформы, с другой стороны конкуренция работает на понижение стоимости этих продуктов;
новаторство: тесное сотрудничество и здоровая конкуренция порождает высокий уровень новых технологий, которые разработчики процессора стараются привнести в новые поколения;
практическая ценность: открытая архитектура, конкуренция, тесное сотрудничество и новаторство повышают практическую ценность платформы, что позволяет предлагать системы с лучшими возможностями по более низкой цене
Процессоры AMD, архитектура RISC86: процессоры семейств К6, К7
Основная идея процессора 5Nx 86. Есть risc процессор с простыми командами и большими возможностями для разгона. Есть интел с большими неповоротливыми командами. Поэтому ЦП состоит из 2-х частей. I-32 заменяется на риск подобные команды.
К7
о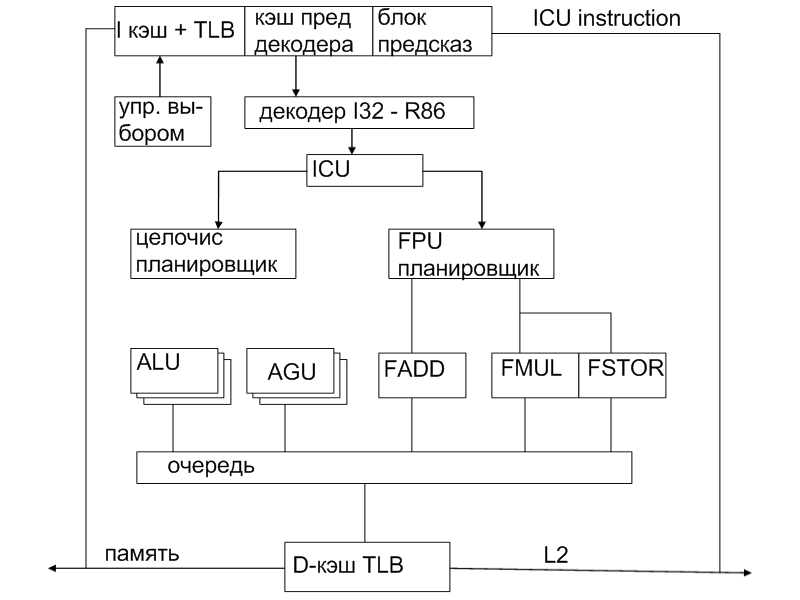 снова
– декодер.
снова
– декодер.
I кэш-кэш команд использующий TBL –буфер целевых адресов. Он ответственен за вычисление адреса виртуальной памяти. Устройство подобно кэшу. Длина TBL -256 строк. КЭШ преддекодера - блок преддекодирования. Вынимает выравненые команды с учетом предсказаний. Блок предсказаний – содежит таблицу с 2048 элементами и двух битовым счетчиком. Точность 90-92%.
ICU – блок управления командами. 2 очереди, целочисленная и вещественная. Команды дожидаются пока они дойдут до состояния выполнения. Всего в очереди 72 команды. А дальше они распределяются по устройствам. Дальше данные попадают в очередь. Длина конвейера
12- целых
7 – вещ.
D-кэш – кэш данных с TBL.