

52. Классификация параллельных проектов. Системы класса simd; матричная и векторная обработка данных.
Компьютеры делятся на 4 класса
Sisd (single instruction single data)
Simd (single instruction multiple data)
Mimd
misd
1 вид – конвейерные и суперскалярные
2 вид – системы векторной и матричной обработки
В этих системах предполагается, что есть несколько однотипных процессорных элементов, которые управляются одним общим устройством управления, но каждый обрабатывает свой собственный элемент данных. Термен векторный и матричный часто употребляются как синонимы. Векторный компьютер основан на конвейерной обработке на целенной на обработку массива векторов с помощью одной операции. В матричном компе предполагается, что каждый процессорный элемент представляет собой процесс общего назначения, его программа может содержать цикл, условия. Каждый элемент имеет свою память все они управляются одним общим устройством управления, при этом каждый выполняет либо одну и ту же команду, либо простаивает. Если комп имеет несколько матр или вект процессоров, то он MSIMD.
53. Системы класса mimd; Классификация. Модели связи и архитектуры памяти; способы реализации и основные особенности.
Самые распространенные мультипроцессорные системы это mimd. Вызвано это 2-мы причинами:
Модель вычислений достаточно простая, интуитивно просто и легко масштабируема.
Особенность развития микропроцессорной техники.
Из соображения минимилизации стоимости абсолютно все процы делаются на базе одних и тех же микропроцессорах. С другой стороны практически все процы имеют встроенные блоки обработки мультимедия данных, а эти блоки основаны на simd. Системы класса mimd можно разделить на несколько подклассов (по доступу к памяти).
1. Система содержит несколько процессоров и несколько модулей памяти. И они соединены между собой просторной шиной. Среднее время доступа для любого цп к любому блоку памяти одинаков. Каждый ЦП имеет свой кэш. узкое место – подсистема доступа к памяти. Несколько ЦП вынуждены конкурировать при доступе к памяти -> возникаю задержки –> число ЦП в системе с однородной памятью ограничено
Матричный коммуникатор
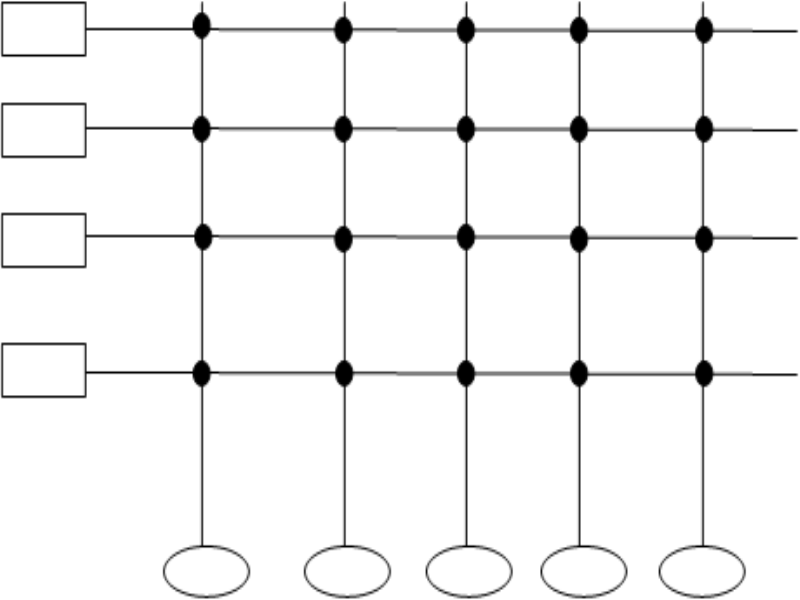
Используется вместо шины. В узлах стоят коммуникаторы
2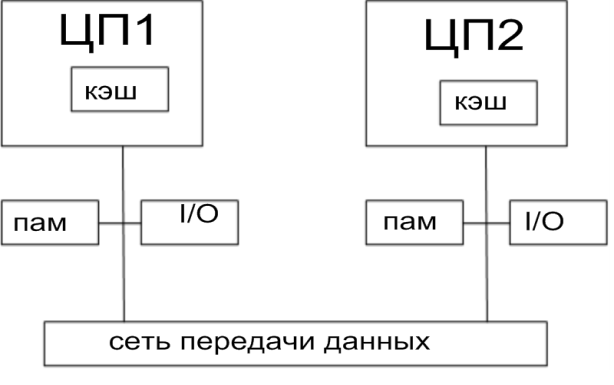 .
система с неоднородным доступом к памяти
.
система с неоднородным доступом к памяти
время доступа к своей памяти выше, чем к чужой. Возможен вариант когда несколько ЦП объединены в кластер с общим модулем памяти. В 1 случае данные с чужой памяти доступны по чтению (система распределенной разделяемой памятью).
2-ой подход доступа к чужой памяти нет, чтобы обменивать данными реализуется метод обмена сообщениями между ЦП.
Проблемы когерентности кэш памяти в многопроцессорных системах. Виды протоколов поддержания когерентности.
Предполагаем, что система выполняет некую общую задачу. Данные в такой системе могут быть частные, могут быть общими. Данные могут храниться в общедоступной памяти, так и в КЭШе => возникает проблема поддержания когерентного состояния КЭШа. Когерентность состоит в выполнении двух правил:
После записи проца А числа в некую ячейку памяти. Процессор В должен получить новые измененные данные.
При последовательном неоднократном изменение одной и той же ячейки проц В должен видеть изменения в том же порядке, что они и были совершенны процессором А.
Существуют несколько подходов нацеленных на обеспечение когерентности:
Подход основанный на наблюдении. Каждый из процессоров просматривает обращения по шине и определяет моменты обращения к своим переменным.
Подход основанных на справочнике. В памяти есть каталог, описывающий состояние общих переменных
Реализация когерентности возможна 2-мя способами
Подход с аннулированием. Если есть несколько копий одной переменной в разных местах, при изменений одной копий все остальные аннулируются
Измененное значение рассылается всем узлам, в которых содержится ее копия, подход основан на ретрансляции. Разница в производительности между протоколами записи с обновлением и с аннулированием определяется тремя характеристиками: Несколько последовательных операций записи в одно и то же слово, не перемежающихся операциями чтения, требуют нескольких операций трансляции при использовании протокола записи с обновлением, но только одной начальной операции аннулирования при использовании протокола записи с аннулированием. При наличии многословных блоков в кэш-памяти каждое слово, записываемое в блок кэша, требует трансляции при использовании протокола записи с обновлением, в то время как только первая запись в любое слово блока нуждается в генерации операции аннулирования при использовании протокола записи с аннулированием. Протокол записи с аннулированием работает на уровне блоков кэш-памяти, в то время как протокол записи с обновлением должен работать на уровне отдельных слов (или байтов, если выполняется запись байта). Задержка между записью слова в одном процессоре и чтением записанного значения другим процессором обычно меньше при использовании схемы записи с обновлением, поскольку записанные данные немедленно транслируются в процессор, выполняющий чтение (предполагается, что этот процессор имеет копию данных). Для сравнения, при использовании протокола записи с аннулированием в процессоре, выполняющим чтение, сначала произойдет аннулирование его копии, затем будет производиться чтение данных и его приостановка до тех пор, пока обновленная копия блока не станет доступной и не вернется в процессор.