

Случайная балансировка бинарных поисковых деревьев. [3 п.13.1]
При вставке новой вершины в дерево, состоящее из n вершин, вероятность появления новой вершины в корне должна быть равна 1/(n+1), это следует из рассуждений обоснования оценки времени в среднем для операций с бинарным поисковым деревом. Поэтому вместо стандартной вставки мы просто принимаем рандомизованное решение с этой вероятностью, использовать вставку в корень.
В случаях рандомизованных и стандартных бинарных поисковых деревьев усредненные затраты одинаковы (хотя для рандомизованных деревьев коэффициент пропорциональности несколько выше), однако для случая стандартных деревьев результат зависит от допущения о вставке в случайном (равновероятном) порядке их ключей. Это допущение не всегда справедливо в практических приложениях, а рандомизованный алгоритм примечателен тем, что позволяет избавиться от такого допущения и вместо этого исходить из законов распределения вероятностей в генераторе случайных чисел. При вставке элементов в порядке следования их ключей, в обратном порядке или любом другом порядке, поисковое дерево все равно будет рандомизованным.
Списки пропусков (Skip Lists). [13 п.8.6; 3 п.13.5]
Список пропусков - это многоуровневый связный список, в котором элементы одной последовательности связываются в односвязные списки на каждом уровне, но на i-м уровне связываются не все элементы, а с пропуском - только некоторые из связанных на предыдущем уровне. Образование нового уровня и пропуск элементов основаны на рандомизации.
Пусть skip-список S для словаря D состоит из серии списков {S0, S1, S2, … Sh}. Каждый список Si хранит набор объектов словаря D по ключам в неубывающей последовательности (плюс объекты с двумя специальными ключами, записываемыми в виде «-» и «+», где «-» обозначает меньше, а «+» - больше любого возможного ключа, который может быть в D). Кроме того, списки в S отвечают следующим требованиям:
список S0 содержит каждый объект словаря D (плюс специальные объекты с ключами «-» и «+»);
для i = 1, … h-1 список Si содержит (в дополнение к «-» и «+») случайно сгенерированный набор объектов из списка Si-1;
список Sh содержит только «-» и «+».
Образец такого skip-списка приведен ниже:
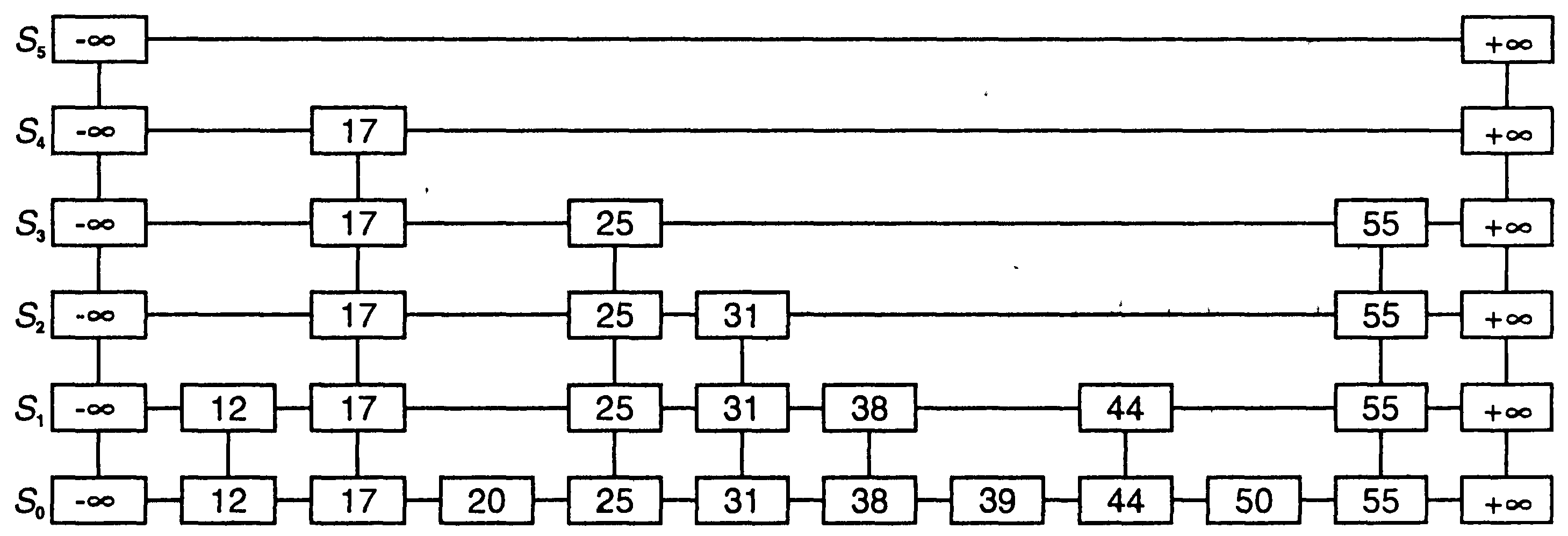
Фактически такой skip-список является аналогом упорядоченного дерева, в котором на каждом уровне примерно в два раза (в среднем) меньше вершин, чем на предыдущем. Каждой вершине p текущего уровня (с предшествующей вершиной p) в качестве сыновей соответствуют вершины предыдущего уровня с ключами в интервале от ключа вершины p (исключительно) до ключа вершины p.
Позиции skip-списка можно проходить с помощью следующих операций:
after(p): возвращает позицию, следующую за p на том же уровне;
before(p): возвращает позицию, предшествующую p на том же уровне;
below(p): возвращает позицию, расположенную под p на предыдущем уровне;
above(p): возвращает позицию, расположенную над p на предыдущем уровне (если такая есть).
Эти операции реализуемы с временем O(1) в среднем, а операции АТД «Словарь» (Вставить, Удалить, Найти элемент) реализуемы с временем O(log(n)) в среднем.