

Пирамиды (heap), другое название – сортирующее (или частично упорядоченное) дерево. [4 гл.6,19-20]
Неубывающая пирамида – это почти полное дерево (только уровень листьев может быть неполным), удовлетворяющее требованию – ключ каждой вершины не больше ключа родителя. Аналогично определяются невозрастающие пирамиды.
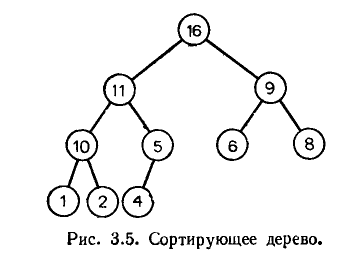
На
рисунке приведен пример двоичной
невозрастающей пирамиды. Несложно
заметить, что ключи в каждой вершине не
меньше максимального из ключей левого
и правого поддеревьев. Дерево является
сбалансированным, высота этого дерева
равна
![]() ,
где
,
где![]() -
число вершин дерева. Заметим, что
последовательность элементов, лежащих
на пути от листа к корню, всегда линейно
упорядочена, а наибольший элемент дерева
приписан его корню. Как видно в этой
структуре легко находится максимальный
элемент, а перестройка дерева в пирамиду
после удаления максимального элемента
занимаетO(log(n)).
-
число вершин дерева. Заметим, что
последовательность элементов, лежащих
на пути от листа к корню, всегда линейно
упорядочена, а наибольший элемент дерева
приписан его корню. Как видно в этой
структуре легко находится максимальный
элемент, а перестройка дерева в пирамиду
после удаления максимального элемента
занимаетO(log(n)).
Для пирамид представление с помощью массива, основанное на нумерации вершин (см. выше преамбулу п.3.2), эффективно и по памяти, и по времени в худшем, O(log(n)) – для операций АТД «Очередь с приоритетом» (с n элементами). Алгоритм (внутренней) пирамидальной сортировки можно описать как алгоритм, который сначала строит очередь с приоритетом для сортируемой последовательности, а потом выводит её в отсортированном виде, удаляя из очереди выводимый элемент. Он имеет наилучшие характеристики, по времени в худшем - O(nlog(n)), и при этом не требует дополнительной памя ти (как например алгоритм сортировки слиянием).
Отметим, что на пирамидах не удается реализовать операторы общего вида Найти и Удалить (произвольно заданный) элемент с временем выполнения O(log(n)).
Разработаны и исследованы расширения пирамидальных структур данных, которые используются в практике программирования в задачах, требующих большей функциональности, чем базовый АТД очередей с приоритетом.
Один из видов таких расширений известен под названием сливаемые пирамиды (mergeable heaps) - биномиальные и фибоначчиевы пирамиды. Главное функциональное отличие этих структур данных – операция слияния двух пирамид, которая создает новую пирамиду (без сохранения исходных). Сливаемые пирамиды позволяют реализовать эту операцию за время (log(n)) в худшем случае или даже (1) в среднем (точнее, это амортизированное время). В то время как бинарная пирамида позволяет реализовать эту операцию только за время в худшем (n).
Основные структурные отличия этих структур данных:
Сливаемая пирамида – это не дерево, а лес (связанных) деревьев.
Деревья этого леса не почти полные, а имеют более сложную структуру.
Но эта структура деревьев (с учетом леса) позволяет организовать приемлемую балансировку, в итоге она дает для операций базового АТД очередей с приоритетом такие же оценки по времени, как и классическая бинарная пирамида.
Список основных операций для (неубывающих) сливаемых пирамид:
Make_Heap(): создает и возвращает новую пустую пирамиду.
Insert(H, х): вставляет вершину х (с заполненным полем key) в пирамиду Н.
Minimum(H): возвращает указатель на вершину в пирамиде Н, обладающую минимальным ключом.
Extract_Min(H): удаляет из пирамиды Н вершину, ключ которой минимален, возвращая при этом указатель на эту вершину.
Union(H1, H2): создает (и возвращает) новую пирамиду, которая содержит все вершины пирамид H1 и H2. Исходные пирамиды должны не иметь общих ключей, и при выполнении этой операции они уничтожаются.
Кроме того, эти структуры данных поддерживают следующие две операции.
Decrease_Key(H, х, k): присваивает вершине х в пирамиде Н новое значение ключа k (предполагается, что новое значение ключа не превосходит текущего).
Delete(H, х): удаляет вершину х из пирамиды Н.
Время выполнения операций у разных реализаций сливаемых пирамид:
|
Операция |
Бинарная пирамида (наихудший случай) |
Биномиальная пирамида (наихудший случай) |
Пирамида Фибоначчи (амортизированное время) |
|
Make_Heap |
(1) |
(1) |
(1) |
|
Insert |
(log(n)) |
O(log(n)) |
(1) |
|
Minimum |
(1) |
O(log(n)) |
(1) |
|
Extract_Min |
(log(n)) |
(log(n)) |
O(log(n)) |
|
Union |
(n) |
(log(n)) |
(1) |
|
Decrease_Key |
(log(n)) |
(log(n)) |
(1) |
|
Delete (см. уточнение ниже) |
(log(n)) |
(log(n)) |
O(log(n)) |
|
Найти (элемент по ключу), Принадлежать |
O(n) |
O(n) |
O(n) |
Все три указанных вида пирамид не могут обеспечить эффективную реализацию поиска элемента с заданным ключом (операции Найти и Принадлежать АТД «Множество» и «Словарь»), поэтому операции Decrease_Key и Delete в качестве параметра получают указатель на вершину, а не значение её ключа.
Замечание. Но дополнительно используя подходящую структуру данных для работы со словарем вершин можно устранить это ограничение.
Фибоначчиевы пирамиды особенно полезны в случае, когда количество операций Extract_Min и Delete относительно мало по сравнению с количеством других операций. Такая ситуация возникает во многих приложениях. Однако с практической точки зрения программная сложность реализации и высокие значения постоянных множителей в формулах времени работы существенно снижают эффективность применения фибоначчиевых пирамид, делая их для многих приложений менее привлекательными, чем обычные бинарные (или к-арные) пирамиды, если не нужна операция Union.