

Неправильные и неполные представления
На рис. 2-3 приведено несколько типичных примеров неправильного или неполного представления статистических данных. Такие искажения могут обусловливаться преднамеренной интерпретацией фактов в пропагандистских целях или недостаточными познаниями в области соответствующих способов представления статистических данных. Первое допустимо в некоторых ситуациях, когда смысл представления данных состоит в том, чтобы подчеркнуть особенности исследуемого явления, или в том, чтобы обратить внимание руководителя на особенности проекта, имеющие важное значение, однако начинающему читателю рекомендуется лишь со всей осмотрительностью пользоваться критериями, соответствующими формуле «цель оправдывает средства».
1
Существует много полезных книг по
графическому представлению статистических
данных. В
качестве
примера
можно
назвать
книгу:
L. Е.
Smart
and S. Arnold,
Practical
Rules for Graphic Presentation of Business Statistics, Bureau of
Business Research, College of Commerce and Administration, Ohio
State University Columbus, Ohio, 1947.


а —масштаб по вертикали меньше масштаба по горизонтали.
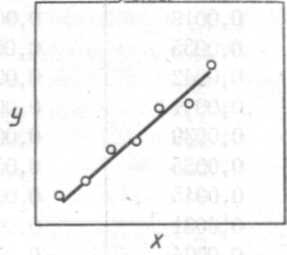
с — переменная величина у находится в тесной корреляционной связи с переменной величиной х. Вывод, сделанный на основании этого о зависимости у от х, может оказаться ошибочным. Причиной изменения каждой из этих величин может служить какая-либо другая третья величина.
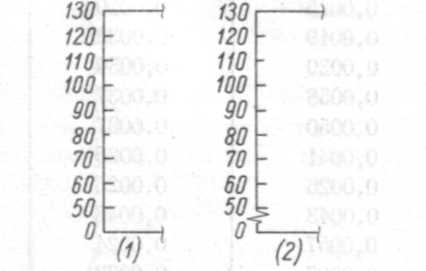
d — ошибочный (1) и правильный (2) методы изображения шкалы, в случае несоответствия ее делений отмеченным на ней величинам.

Сравнение объемов реали
зованной продукции
Сравнение ежегодных приростов реализованной продукции

 е
— (1)
— неполное представление статистических
данных. Положение компании С
выглядит
намного прочнее положения других
компаний. (3) — представление статистических
данных, соответствующее действительному
положению. В этом случае положение
компании С
выглядит
уже не так прочно, как в (1).
е
— (1)
— неполное представление статистических
данных. Положение компании С
выглядит
намного прочнее положения других
компаний. (3) — представление статистических
данных, соответствующее действительному
положению. В этом случае положение
компании С
выглядит
уже не так прочно, как в (1).
f — картина, обратная е. Кривая X на левом графике показывает более быстрый абсолютный рост, чем кривая У. На правом графике видно, что кривая У показывает больший относительный рост, чем кривая X. Заимствовано из «Стандартов представления статистических данных» Военного ведомства США, март 1955 г.
Рис. 2-3. Примеры неправильного и неполного представления статистических данных.
ПРЕДСТАВЛЕНИЕ ДАННЫХ, ХАРАКТЕРИЗУЮЩИХ ЧАСТОТЫ, И ИХ АНАЛИЗ
 Для
характеристики остальных этапов
применения элементарных статистических
методов будет использован пример,
типичный для данных, относящихся к
контролю качества. На рис. 2-4 приведена
таблица, содержащая
Для
характеристики остальных этапов
применения элементарных статистических
методов будет использован пример,
типичный для данных, относящихся к
контролю качества. На рис. 2-4 приведена
таблица, содержащая
несистематизированные данные, полученные в результате замера наружного диаметра в выборочной партии, состоящей из 100 деталей, обработанных на станке. В качестве примера выбраны именно такого рода детали, чтобы анализ этих данных легче воспринимался начинающими. С самого начала должно быть ясно, что ко всем производимым товарам будут применяться одни и те же методы анализа независимо от особенностей производимого товара, т. е. независимо от того, измеряются ли его свойства в дюймах, микродюймах, футофунтах, фунтах на квадратный дюйм, миллиметрах ртутного столба или каких-либо других единицах измерения. Определяющий фактор (безотносительно к тому, поддается он измерению или нет) представляет собой переменную.
В том виде, в каком статистические данные представлены в таблице на рис. 2-4, они, конечно, мало приспособлены для оценки качества изделий. Гораздо больших результатов можно достичь при распределении частот наблюдаемого признака в порядке уменьшения их численных значений (от высшего к низшему). На рис. 2-5 показаны результаты упорядочения данных по величине измеряемого признака (от высшего к низшему), при котором распределение частот каждого измерения осуществляется простым подсчетом числа черточек, соответствующих каждому значению наблюдаемого признака и расположенных с правой стороны столбцов цифр.
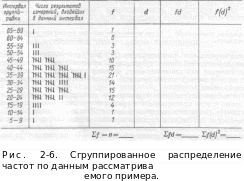
Упорядоченные таким образом данные измерений, несомненно, представляют собой уже более репрезентативный материал. Однако полученная картина остается все еще недостаточно наглядной и компактной для эффективного визуального анализа. Компактность может быть достигнута соответствующей группировкой данных измерений. Такая группировка может быть осуществлена в следующей последовательности:
 Подготавливается
макет таблицы сгруппированного
распределения частот результатов
измерений (см. рис. 2-6), в подлежащем
которой проставляется интервал
группировки, а в сказуемом — число
результатов измерений, входящих в
данный интервал, частоты / и числовые
характеристики
Подготавливается
макет таблицы сгруппированного
распределения частот результатов
измерений (см. рис. 2-6), в подлежащем
которой проставляется интервал
группировки, а в сказуемом — число
результатов измерений, входящих в
данный интервал, частоты / и числовые
характеристики
 и
/(сО2,
смысл
которых будет разъяснен нами дальше.
и
/(сО2,
смысл
которых будет разъяснен нами дальше.
Определяется размах изменения результатов измерений. Для нашего примера он равен 66—7 = 59.
Размах изменения, исчисленный на стадии 2, делится на такое число, чтобы полученное частное было бы не меньше 10 и не больше 20. (Следует подчеркнуть, что эта стадия является решающей. Иногда можно допустить,
чтобы количество групп было не более 7 или не менее 30.) Например, в данном случае количество групп равно 59 : 5 ^ 12.
После этого производится подбор числа, ближайшего к принятому. Подобранное таким образом число будет представлять величину интервала группировки, которая должна быть использована для группировки данных, полученных в результате измерений. Предпочтительные размеры интервалов — 1, 2, 3, 5, 7, 10, 15 или более высокого порядка, кратного 5. В данном примере принят интервал, равный 5.
Числовые интервалы обозначаются своими границами и записываются в нисходящем порядке в графе таблицы «Интервал группировки». Эта стадия обработки данных, как и последующие, также показана на рис. 2-6. Границы интервала соответствуют высшему и низшему значениям признаков, входящих в данный интервал. Эти интервалы, начиная от высшего и кончая низшим, охватывают все полученные данные.
Подсчитывается число данных, полученных в результате измерений, соответствующих по своему значению каждому из интервалов. На рис. 2-5 такой подсчет приведен в чисто иллюстративных целях только для того, чтобы показать, как это достигается даже при наличии необработанных данных.
Подсчитывается найденное таким путем число «черточек» для каждого интервала и результаты записываются в графу /.