

38. Централизованное хд с витринами данных - структурная схема, функционал.
Использование витрин данных вместе с централизованными ХД позволяет повысить достоверность данных, получаемых пользователями витрин, поскольку витрины «питаются» данными из хранилищ, где автоматически поддерживается целостность и непротиворечивость данных и производится их очистка. Кроме того, корпоративная информационная система может эффективно наращиваться за счет добавления новых витрин данных. И наконец, использование витрин данных позволяет снизить нагрузку на централизованное ХД.
Примером организации централизованного ХД с витринами данных для предприятия с большим количеством подразделений может служить схема, представленная на рис.
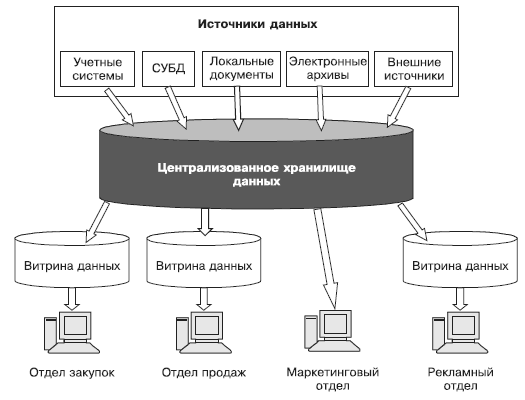
Рис. Централизованное ХД с витринами данных
39. Аналитические платформы - структурная схема, функционал.
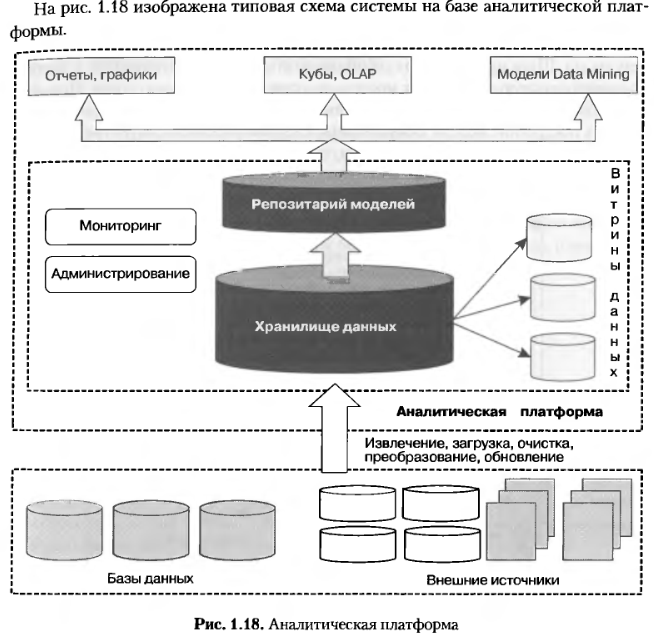
Аналитическая платформа - специализированное программное решение (или набор решений), которое содержит в себе все инструменты для извлечения закономерностей из сырых данных: средства консолидации информации в едином источнике (хранилище данных), извлечения, преобразования, трансформации данных, алгоритмы Data Мiпiпg, средства визуализации и распространения результатов среди пользователей, а также возможности конвейерной обработки новых данных.
В аналитической платформе, как правило, всегда присутствуют гибкие и развитые средства консолидации, включающие богатые механизмы итерации с промышленными источниками данных, инструменты очистки и преобразования структурированных данных и их последующее хранение в едином источнике в многомерном виде в хранилище данных. Модели, описывающие выявленные закономерности,правила и прогнозы, также хранятся в специальном источнике данных репозитории моделей.
40. Data Mining - предназначение, полный цикл функционирования.
Data Mining (рус. добыча данных, интеллектуальный анализ данных, глубинный анализ данных) — собирательное название, используемое для обозначения совокупности методов обнаружения в данных ранее неизвестных, нетривиальных, практически полезных и доступных интерпретации знаний, необходимых для принятия решений в различных сферах человеческой деятельности.
Одно из важнейших назначений методов Data Mining состоит в наглядном представлении результатов вычислений (визуализация), что позволяет использовать инструментарий Data Mining людьми, не имеющими специальной математической подготовки. В то же время, применение статистических методов анализа данных требует хорошего владения теорией вероятностей и математической статистикой.
На лекции был отличный от данного алгоритм.
Ряд этапов решения задач методами Data Mining:
Постановка задачи анализа;
Сбор данных;
Подготовка данных (фильтрация, дополнение, кодирование);
Выбор модели (алгоритма анализа данных);
Подбор параметров модели и алгоритма обучения;
Обучение модели (автоматический поиск остальных параметров модели);
Анализ качества обучения, если неудовлетворительный переход на п. 5 или п. 4;
Анализ выявленных закономерностей, если неудовлетворительный переход на п. 1, 4 или 5.
41. Data Мining - классификация, задачи, привести пример.
Приведем несколько определений.
Классификация - системное распределение изучаемых предметов, явлений, процессов по родам, видам, типам, по каким-либо существенным признакам для удобства их исследования; группировка исходных понятий и расположение их в определенном порядке, отражающем степень этого сходства.
Классификация - упорядоченное по некоторому принципу множество объектов, которые имеют сходные классификационные признаки (одно или несколько свойств), выбранных для определения сходства или различия между этими объектами.
Задачей классификации часто называют предсказание категориальной зависимой переменной (т.е. зависимой переменной, являющейся категорией) на основе выборки непрерывных и/или категориальных переменных.
Пример. Определить, к какому классу принадлежит новый клиент и какой из двух видов рекламных материалов ему стоит отсылать.
Для наглядности представим нашу базу данных в двухмерном измерении (возраст и доход), в виде множества объектов, принадлежащих классам 1 (оранжевая метка) и 2 (серая метка). На рис. 5.1 приведены объекты из двух классов.
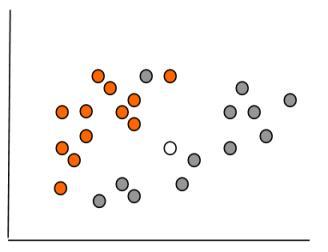
Рис. 5.1. Множество объектов базы данных в двухмерном измерении
Решение нашей задачи будет состоять в том, чтобы определить, к какому классу относится новый клиент, на рисунке обозначенный белой меткой.