

15. Виртуальные olap системы - структурная схема, функционал.
Виртуальным хранилищем данных называется система, которая работает с разрозненными источниками данных и эмулирует работу обычного хранилища данных, извлекая, преобразуя и интегрируя данные непосредственно в процессе выполнения запроса.
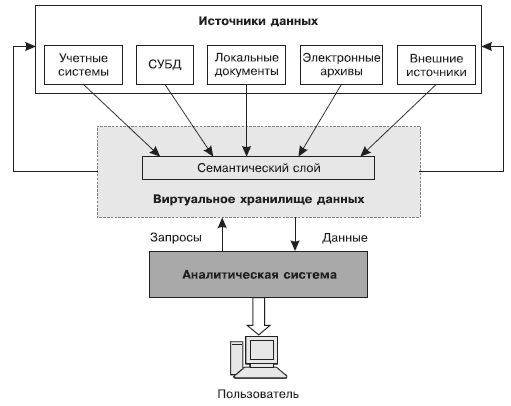
Рис. Виртуальное ХД
16. Многомерная модель данных ОLАР-кубов.
Основное назначение:
поддержка систем ориентиров на поддержку данных на аналитическую обработку данных.
Поскольку хранилище лучше справляется с сложным не регламентирующим запросом.
Многомерная модель данных лежит на основе многомерных кубов. Она представляют собой упорядоченное многомерное хранилище данных.
Технология OLAP представляет собой методику извлечения нужной информации из большого массива данных и формирование отчетов.
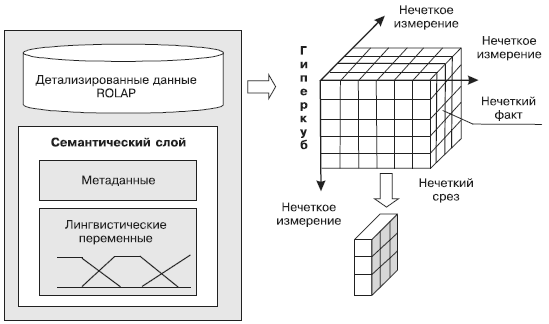
17. Семантический слой в виртуальных OLAP систем- структурная схема, функционал.
VOLAP не реализовано физически, а собирает непосредственно процесс запросов. В таких системах работа ведется отдельными источниками данных, но при этом ведется эмуляция обычного хранилища данных.
Данные не консолидируются физически, а собираются непосредственно в процессе выполнения запроса.
18. Декомпозиция ОLАР-кубов в виде двухмерных таблиц.
19. Базовые понятия многомерной модели данных - измерения и факты.
В основе многомерного представления данных лежит их разделение на две группы — измерения и факты.
Измерения — это категориальные атрибуты, наименования и свойства объектов, участвующих в некотором бизнес-процессе. Значениями измерений являются наименования товаров, названия фирм-поставщиков и покупателей, ФИО людей, названия городов и т.д. Измерения могут быть и числовыми, если какой-либо категории (например, наименованию товара) соответствует числовой код, но в любом случае это данные дискретные, то есть принимающие значения из ограниченного набора. Измерения качественно описывают исследуемый бизнес-процесс.
Факты — это данные, количественно описывающие бизнес-процесс, непрерывные по своему характеру, то есть они могут принимать бесконечное множество значений. Примеры фактов — цена товара или изделия, их количество, сумма продаж или закупок, зарплата сотрудников, сумма кредита, страховое вознаграждение и т.д.
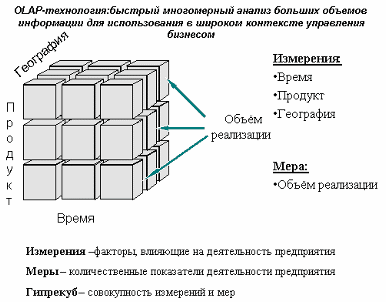
20. Структура многомерного куба, привести пример.
Информация хранящаяся в многомерных хранилищах данных является логической ценностью, которая может быть получена из различных таблиц.
Плюсы:
Наглядность, проще, чем пользоваться таблицами реляционных моделей.
Время выполнения запросов. Возможно построение широких запросов; в ячейках хранятся агрегированные данные (время выполнения поиска уменьшается).
Процесс поиска:
Для извлечения из куба нужной информации над его данными проводят преобразования: сечение, транспортирование, свертка, детализация.

21. Принцип организации многомерного куба, привести пример.
См.20
22. Потери при декомпозиции ОLАР-кубов в виде двухмерных таблиц.
23. Компенсация потерь при декомпозиции ОLАР-кубов в виде двухмерных таблиц.
Чтобы компенсировать потерянную информацию от одного или нескольких измерений, придётся усложнить структуру таблиц.
24. Преимущества многомерного OLAP-подхода.
Преимущества многомерного подхода очевидны. Представление данных в виде многомерных кубов более наглядно, чем совокупность нормализованных таблиц реляционной модели, структуру которой представляет только администратор БД.
Возможности построения аналитических запросов к системе, использующей МХД, более широки.
В некоторых случаях использование многомерной модели позволяет значительно уменьшить продолжительность поиска в МХД, обеспечивая выполнение аналитических запросов практически в режиме реального времени. Это связано с тем, что агрегированные данные вычисляются предварительно и хранятся в многомерных кубах вместе с детализированными, поэтому тратить время на вычисление агрегатов при выполнении запроса уже не нужно.