

01 КАСЮК С. Т. ПЕРВИЧНЫЙ, КЛАСТЕРНЫЙ, РЕГРЕССИОННЫЙ И ДИСКРИМИНАНТНЫЙ АНАЛИЗ ДАННЫХ СПОРТИВНОЙ МЕДИЦИНЫ НА КОМПЬЮТЕРЕ
.pdfединение, осталось два кластера, один из которых держал 9 объектов, а другой – 5. На 25 шаге кластеризация закончилась. Образовался один кластер [3].
Рисунок 2.11 – Кластеризация агломеративным методом. Построение дендрограммы
На древовидных диаграммах второго типа горизонтальные (или вербальные) оси представляют расстояние объединения. Для каждого узла в графе, где формируется новый кластер, можно видеть величину расстояния, для которого соответствующие элементы связываются в новый единственный кластер. Когда данные имеют ясную структуру объектов, сходных между собой, тогда эта структура скорее всего должна быть отражена в иерархическом дереве различными ветвями. В результате успешного анализа методом объединения появляется возможность обнаружить кластеры (ветви) и интерпретировать их [3].
Правила объединения. Па первом шаге, когда каждый объект представляет отдельный кластер, расстояния между объектами определяются выбранной мерой. Однако когда по мере образования кластеров связываются вместе несколько объектов, следует определить расстояния между кластерами, то есть необходимо выбрать правило объединения или связи для двух кластеров. Здесь имеются следующие возможности [3]:
1 Метод «ближних соседей» или одиночной связи (Single Linkage). С его помощью можно связать два кластера вместе, когда любые два объекта в двух кластерах ближе друг к другу, чем соответствующее расстояние связи. Это правило строит «волокнистые» кластеры, «сцепленные вместе» только отдельными эле-
51

ментами, случайно оказавшимися ближе остальных друг к другу. Это правило нанизывает объекты вместе для формирования кластеров, и результирующие кластеры представляются длинными «цепочками».
2 Метод «дальних соседей» или метод полной связи (Complete Linkage).
Как альтернативу первому способу можно использовать «соседей» в кластерах, которые находятся дальше всех остальных пар объектов друг от друга. Этот метод называется методом полной связи. Он обычно работает очень хорошо, когда объекты происходят на самом деле из реально различных «рощ». Если же кластеры имеют удлиненную форму или их естественный тип «цепочечный», то этот метод непригоден.
3 Невзвешенное попарное среднее (Unweighted pair-group average). В
этом методе расстояние между двумя различными кластерами вычисляют как среднее расстояние между всеми парами объектов в них. Метод эффективен, когда объекты в действительности формируют различные «рощи», однако он работает одинаково хорошо и в случаях протяженных «цепочного» вида кластеров.
4 Взвешенное попарное среднее (Weighted pair-group average). Метод идентичен методу невзвешенного попарного среднего, за исключением того, что при вычислениях в качестве весового коэффициента используют размер соответствующих кластеров (число объектов, содержащихся в них). Данный метод следует использовать, когда предполагают неравные размеры кластеров.
5 Невзвешенный попарный центроидный метод (Unweighted pair-group centroid). В этом методе расстояние между двумя кластерами определяется как расстояние между их центрами тяжести.
6 Взвешенный центроидный метод или медиана (Weighted pair-group centroid). Этот метод идентичен предыдущему, за исключением того, что для учета разницы между размерами кластеров (то есть числами объектов в них) при вычислениях используют веса. Поэтому, если имеются (или подозреваются) значительные отличия в размерах кластеров, этот метод оказывается предпочтительнее предыдущего.
7 Метод Варда (Ward's method). Этот метод отличается от всех других методов, поскольку он использует методы дисперсионного анализа для оценки расстояний между кластерами. Метод минимизирует сумму квадратов для любых двух (гипотетических) кластеров, которые могут быть сформированы на каждом шаге. Метод очень эффективен, однако он стремится создавать кластеры малого размера.
2.7 Пример проведения кластерного анализа алгоритмом древовидной кластеризации в пакетe STATISTICA 10
Проведем кластерный анализ данных предыдущего примера о профессиональном отборе врачей-лаборантов (таблица 2.1) [6]. Вопрос остается тем же:
52

можно ли разделить претендентов на группы, и сколько таких групп может получиться исходя из результатов профотбора?
Алгоритм решения [6]:
1 Таблица с исходными данными у нас уже имеется. Поэтому, как и в предыдущем примере стандартизируем данные, чтобы привести их к одному порядку по шкале от –1 до 1: из значений переменных вычтем их среднее, и эти значения поделим на стандартное отклонение. Во вкладке Data (Данные) в группе Transformations (Трансформация) выберем команду Standardize (Стандартизация), и
в окне Standardization of Values (Стандартизация значений) зададим значения параметров (рисунок 2.2):
–Variables (Переменные) – Var 1–3;
–Cases (Наблюдения) – All (Все);
–Weight (Вес) – Off (Не задавать). Нажав ОК, выполним стандартизацию.
2 На вкладке Statistics (Анализ) в группе Advanced/Multivariate (Углуб-
ленная статистика) выберем команду Mult/Exploratory (Многомерный анализ) – Cluster (Кластерный анализ).
3 В появившемся окне Clustering Method (Методы кластеризации) (рису-
нок 2.1) выберем метод Joining (tree clustering) (Иерархическая классифика-
ция) и нажмем ОК.
4 В диалоговом окне этого метода Cluster Analysis: Joining (Tree Clustering) (Кластерный анализ: иерархическая классификация) во вкладке
Advanced (Дополнительно) (рисунок 2.12) заполним:
–Variables (Переменные) – Var 1, 2, 3;
–в поле Input file (Файл данных) выберем Raw data (Исходные данные),
поскольку данные у нас уже имеются (можно открывать и ранее сохраненный файл);
–в поле Cluster (Объекты) зададим направление классификации – Cases (Rows) (Наблюдения (строки));
–в поле Amalgamation (linkage) rule (Правило объединения) зададим ус-
тановку для выбора различных мер сходства – Ward's method (Метод Варда);
–в поле Distance measure (Мера близости) зададим метрику – Euclidean distances (Евклидово расстояние);
–в группе MD deletaion (Удаление пропущенных данных)) можно вы-
брать два способа некомплектных наблюдений, содержащих пропуски хотя бы одной переменной: Casewise (Построчное) – некомплектные наблюдения полностью исключаются их дальнейшего анализа; Mean substitution (Замена средним) – пропущенные данные заменяют срежними значениями показателя, полученным по комплектным (полным) данным – в данном примере выберем построчное удаление Casewise.
53
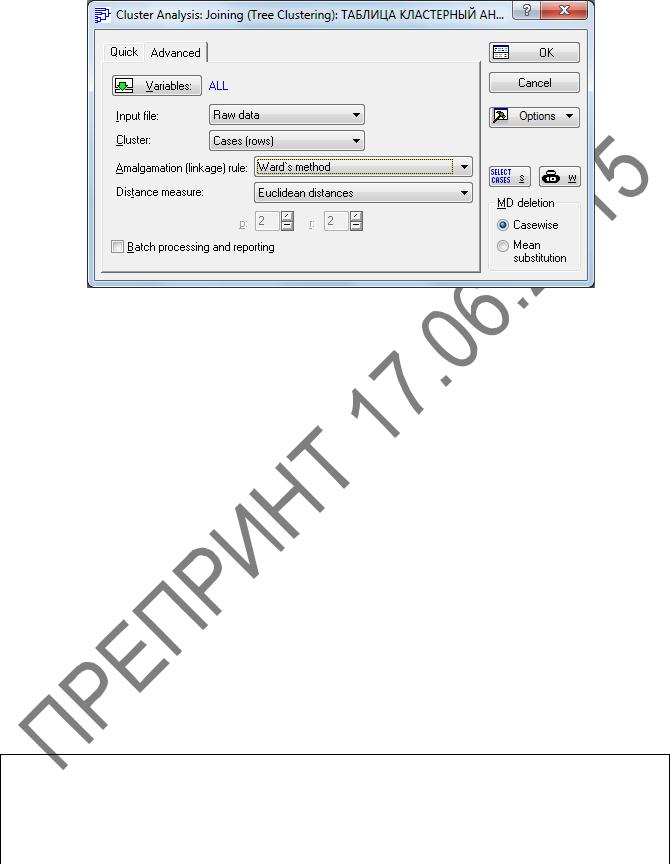
Рисунок 2.12 – Окно Cluster Analysis: Joining (Tree Clustering)
(Кластерный анализ: иерархическая классификация)
5 Нажав OK, выполним кластеризацию. В окне Joining Results (Результаты иерархической классификации) (рисунок 2.13) переходим на вкладку Advanced (Дополнительно) и нажимаем кнопку Vertical icicle plot (Вертикальная дендро-
грамма). На появившейся дендрограмме (рисунок 2.14) горизонтальная ось представляет наблюдения, вертикальная – расстояние объединения. Дендрограмма показывает процесс объединения. На расстоянии, равном 4, существуют 4 кластера; на расстоянии, равном 7, существуют три кластера; при увеличении расстояния до 13 количество кластеров становится равным двум; на расстоянии, равном 23, остался один кластер.
Сравним результаты кластеризации по алгоритмам k-средних и древовидной кластеризации для количества кластеров, равного 4 (таблицы 2.4 и 2.5). Содержимое первых и четвертых кластеров здесь совпадает, а в содержимом вторых и третьих кластеров наблюдаются небольшие отличия.
Закроим окно.
Таблица 2.5 – Результаты кластерного анализа по алгоритму иерархической классификации
Разбиение выборки на 4 кластера
Кластер 1 |
Кластер 2 |
|
Кластер 3 |
Кластер 4 |
11, 4, 6, 10, 12, 22, |
5, 7, 9, 11, 14, 17, |
|
2, 3, 8, 25, 27, 30 |
13, 15, 16, 31 |
26 |
18, 19, 20, 21, 23, |
|
|
|
|
24, 28, 29, 32 |
|
|
|
|
|
54 |
|
|
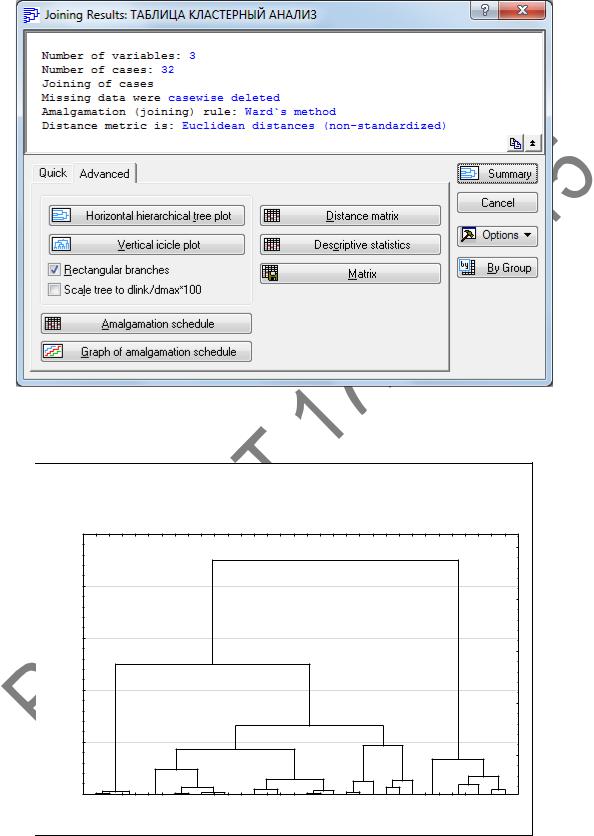
Рисунок 2.13 – Окно Joining Results
(Результаты иерархической классификации)
 Расстояние объединения
Расстояние объединения
Дендрограмма для 32 наблюдений Метод Варда
Евклидово расстояние
25
20
15
10
5
0
C_16 C_15 C_31 C_13 C_24 C_14 C_28 C_20 C_32 C_23 C_17 C_7 C_11 C_21 C_19 C_9 C_29 C_18 C_5 C_30 C_27 C_25 C_8 C_3 C_2 C_26 C_22 C_12 C_6 C_4 C_10 C_1
Рисунок 2.14 – Дендрограмма иерархической классификации
55
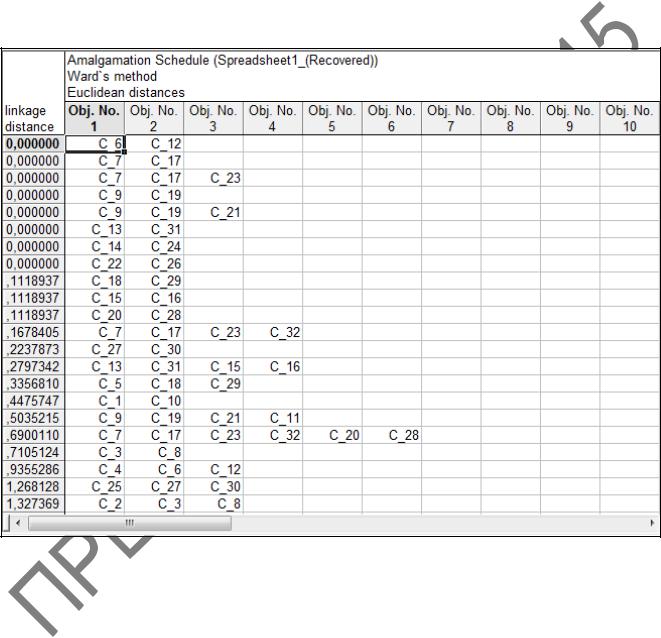
6 В окне Joining Results (Результаты иерархической классификации)
(рисунок 2.13) нажмем на кнопку Amalgamation schedule (Схема объединения) и выведем на экран таблицу результатов со схемой объединения (рисунок 2.15). Первый столбец таблицы содержит расстояния до соответствующих кластеров. Каждая строка показывает состав кластера на данном шаге классификации. Например, на первом шаге (1 строка) объединяются наблюдения 6 и 12, на втором (2 строка) – 7 и 17, на третьем (3 строка) – 7, 17 и 23 и так далее. Закончилось объединение на расстоянии 22,4. Закроим таблицу.
Рисунок 2.15 – Схема объединения
7 В окне Joining Results (Результаты иерархической классификации)
(рисунок 2.13) нажмем на кнопку Graph of amalgamation schedule (График схе-
мы объединения) и просмотрим результаты древовидной кластеризации (рисунок 2.16). По горизонтальной оси на диаграмме отложены шаги, по вертикальной – расстояния. Всего алгоритму потребовалось 31 шаг для объединения всех объектов в один кластер. Закроим график.
8 В окне Joining Results (Результаты иерархической классификации)
(рисунок 2.13) нажмем на кнопку Distance matrix (Матрица расстояний) и про-
56
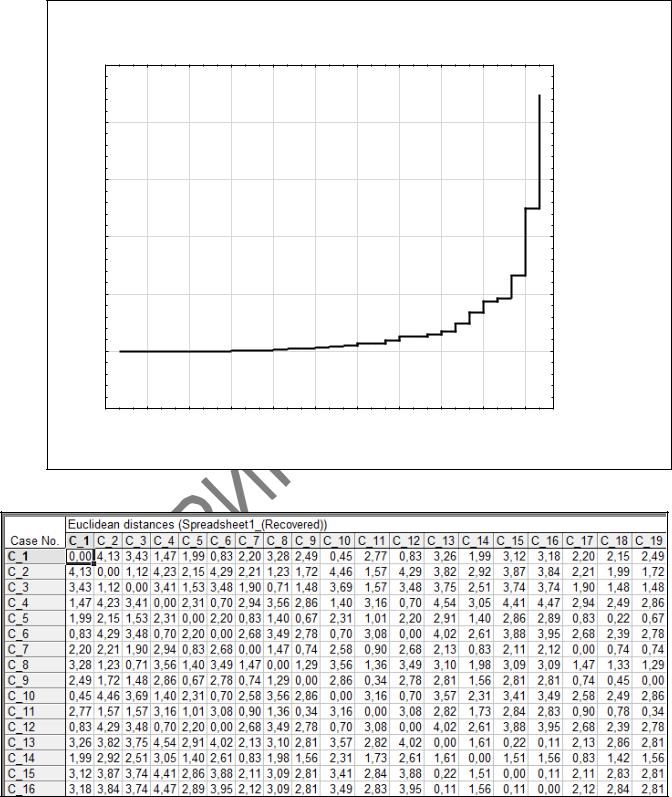
смотрим матрицу Евклидовых расстояний между различными наблюдениями (ри-
сунок 2.17).
Расстояние объединения
Диаграмма расстояний объединения по шагам Евклидово расстояние
25
20
15
10
5
0
-5
0 |
3 |
6 |
9 12 15 18 21 24 27 30 |
|
Расст. |
|
|||||
|
|
|
Шаг |
|
объедин. |
Рисунок 2.16 – График схемы объединения
Рисунок 2.17 – Матрица Евклидовых расстояний между различными наблюдениями
57

2.8 Проблемы алгоритмов кластеризации
Одно и то же множество наблюдений можно разбить на несколько кластеров по-разному. Это приводит к изобилию алгоритмов кластеризации.
При решении задач кластеризации популярны алгоритмы, которые ищут оптимальное разбиение множества данных на группы. Критерий оптимальности определяется видом целевой функции, от которой зависит результат кластеризации.
Например, семейство алгоритмов k-
средних показывает хорошие результаты, когда данные в пространстве образуют компактные сгустки, четко отличимые друг от друга. Поэтому и критерий качества основан
на вычислении расстояний точек до центров кластера [8].
На рисунке 2.18 приведен пример неуспеха алгоритма k-средних. При использовании Евклидовой метрики кластеры в k- средних имеют сферическую форму, поэтому такой алгоритм никогда не разделит на кластеры вложенные друг в друга множества объектов.
Выбор числа кластеров. Хоть и редко, но встречаются случаи, когда точно известно, сколько кластеров нужно выделить. Однако чаще всего перед процедурой кластеризации этот вопрос остается открытым. Если алгоритм не поддерживает автоматическое определение оптимального количества кластеров, существует несколько эмпирических правил, которые можно применять при условии, что каждый кластер будет в дальнейшем подвергаться содержательной интерпретации аналитиком [8].
1 Двух или трех кластеров, как правило, недостаточно: кластеризация будет слишком грубой, приводящей к потере информации об индивидуальных свойствах объектов.
2 Больше десяти кластеров не укладываются в «число Миллера 7 ± 2»: аналитику трудно держать в кратковременной памяти столько кластеров. Поэтому в подавляющем большинстве случаев число кластеров варьируется от 4 до 9.
Любая кластеризация всегда носит субъективный характер субъективна, потому что выполняется на основе конечного подмножества свойств объектов, а выбор этого подмножества всегда субъективен [8].
Чтобы применять кластеризацию корректно и снизить риск получения результатов, не имеющих отношения к действительности, необходимо придерживаться следующих правил:
58

1 Перед кластеризацией четко обозначьте цели еѐ проведения: облегчение дальнейшего анализа, сжатие данных и тому подобно. Кластеризация сама по себе не представляет особой ценности.
2 Выбирая алгоритм, убедитесь, что он корректно работает с теми данными, которыми вы располагаете для кластеризации. В частности, если присутствуют категориальные признаки, удостоверьтесь, что та реализация алгоритма, которую вы используете, умеет правильно обрабатывать их. Это особенно актуально для алгоритма k-средних, применяющего Евклидову меру расстояния. Если алгоритм не умеет работать со смешанными наборами данных, постарайтесь сделать набор данных однородным, то есть отказаться от категориальных или числовых признаков.
3 Обязательно проведите содержательную интерпретацию каждого полученного кластера: постарайтесь понять, почему объекты были сгруппированы в определенный кластер, что их объединяет. Полезно каждому кластеру дать емкое название, состоящее из нескольких слов. Встречаются ситуации, когда алгоритм кластеризации не выделил никаких особых групп. Возможно, набор данных и до кластеризации был однороден, не расслаивался на изолированные подмножества, а кластеризация подтвердила эту гипотезу.
Таким образом, не существует единого универсального алгоритма кластеризации. При использовании любого алгоритма важно понимать его достоинства, недостатки и ограничения. Только тогда кластеризация будет эффективным инструментом в руках аналитика.
2.9 Варианты заданий по кластерному анализу в пакете STATISTICA 10
Для всех вариантов заданий произвести следующий анализ: 1 Стандартизировать исходные данные.
2 Произвести кластерный анализ таблицы алгоритмом k-средних для числа кластеров 3, 4 и 5. Получить описательные статистики для каждого кластера. Определить центроиды для каждого кластера и Евклидово расстояние между кластерами. Построить графики средних для каждого кластера. Выбрать оптимальное количество кластеров по величинам межгрупповой и внутригрупповой дисперсий.
3 Произвести кластерный анализ алгоритмом древовидной классификации, используя различные правила объединения (метод «ближайших соседей», метод «дальних соседей», невзвешенное попарное среднее, взвешенное попарное среднее, невзвешенный попарный центроидный метод, взвешенный центороидный метод, метод Варда) и метрики пространства (Евклидово расстояние, расстояние Манхеттена, расстояние Чебышева, степенное расстояние). Построить дендрограммы иерархической классификации, схемы объединения, графики схем объединения и матрицы расстояний между наблюдениями. Сравнить результаты кластеризации, полученные с помощью различных правил объединения и метрик пространства.
59

4 Сравнить результаты кластеризации алгоритмами k-средних и древовидной классификации. Сделать выводы.
Вариант 1. Имеются результаты измерения спортивных показателей X1, X2, X3, X4, X5 женщин-спортсменок в количестве 40 человек (таблица 2.6).
|
Таблица 2.6 – Вариант 1 |
|
|
|
|
|
|
|
|||
№ X1 X2 |
X3 |
X4 |
X5 |
№ X1 X2 |
X3 |
X4 |
X5 |
||||
1 |
5,0 |
12,6 |
474 |
5851 |
33328 |
21 |
2,3 |
42,3 |
206 |
3494 |
14262 |
2 |
2,1 |
54,7 |
218 |
3417 |
18457 |
22 |
2,4 |
52,6 |
133 |
3384 |
12315 |
3 |
2,6 |
67,9 |
249 |
3265 |
16588 |
23 |
2,8 |
55,6 |
186 |
3378 |
11276 |
4 |
1,3 |
59,1 |
283 |
3662 |
17797 |
24 |
2,4 |
49,4 |
329 |
3861 |
14284 |
5 |
3,0 |
44,6 |
215 |
3106 |
11722 |
25 |
5,0 |
33,1 |
358 |
5277 |
50404 |
6 |
8,5 |
92,6 |
578 |
8899 |
78120 |
26 |
5,0 |
20,6 |
328 |
4341 |
47877 |
7 |
5,4 |
11,0 |
357 |
5546 |
38914 |
27 |
2,7 |
56,1 |
255 |
3300 |
13421 |
8 |
5,5 |
18,5 |
414 |
5029 |
52018 |
28 |
4,1 |
37,7 |
387 |
5332 |
45651 |
9 |
7,3 |
95,2 |
685 |
8530 |
71412 |
29 |
5,7 |
22,7 |
386 |
5462 |
45910 |
10 |
5,1 |
37,6 |
409 |
5826 |
49624 |
30 |
2,8 |
69,9 |
150 |
3745 |
17355 |
11 |
8,1 |
86,6 |
635 |
7913 |
69504 |
31 |
7,4 |
88,3 |
585 |
8637 |
78570 |
12 |
1,9 |
56,2 |
194 |
3514 |
20003 |
32 |
7,6 |
91,5 |
594 |
9205 |
80795 |
13 |
5,6 |
35,5 |
454 |
5434 |
47120 |
33 |
2,0 |
57,0 |
196 |
4019 |
15137 |
14 |
4,8 |
18,7 |
470 |
4993 |
41686 |
34 |
9,0 |
84,4 |
558 |
7876 |
72703 |
15 |
6,4 |
27,6 |
379 |
6125 |
42080 |
35 |
2,3 |
65,3 |
179 |
3508 |
26314 |
16 |
1,9 |
64,3 |
221 |
3731 |
14928 |
36 |
2,4 |
57,1 |
273 |
3631 |
13396 |
17 |
6,0 |
25,3 |
356 |
6597 |
33815 |
37 |
8,2 |
80,8 |
619 |
9006 |
79554 |
18 |
6,9 |
85,0 |
599 |
8506 |
73321 |
38 |
8,1 |
100,7 |
552 |
8737 |
72201 |
19 |
4,9 |
5,6 |
430 |
5570 |
43341 |
39 |
5,3 |
22,3 |
544 |
5826 |
40405 |
20 |
7,5 |
82,2 |
612 |
8758 |
68433 |
40 |
6,2 |
17,7 |
510 |
4840 |
42532 |
|
|
|
|
|
|
60 |
|
|
|
|
|