

01 КАСЮК С. Т. ПЕРВИЧНЫЙ, КЛАСТЕРНЫЙ, РЕГРЕССИОННЫЙ И ДИСКРИМИНАНТНЫЙ АНАЛИЗ ДАННЫХ СПОРТИВНОЙ МЕДИЦИНЫ НА КОМПЬЮТЕРЕ
.pdfстоит в построении зависимости между несколькими независимыми переменными и зависимой переменной. В этом модуле доступны пошаговые процедуры включения и исключения, стандартная регрессия. Можно строить модели со свободным членом и без него. Пакет STATISTICA 10 вычисляет все стандартные статистики регрессии, позволяет провести всесторонний анализ остатков и оценить адекватность моделей [1].
Модуль Discriminant (Дискриминантный анализ) содержит классические процедуры дискриминантного анализа. Пакет STATISTICA 10 предоставляет широкий набор опций и статистик для классификации наблюдений. Результаты включают статистики лямбды Уилкса, частные лямбды Уилкса, р-уровни, уровни толерантности, R-квадрат и др. Этот модуль вычисляет стандартные функции классификации для каждой группы. Классификацию наблюдений можно рассматривать в терминах расстояний Махаланобиса, апостериорных вероятностей и действительных классификаций [1].
1.3 Создание файла данных в пакете STATISTICA 10
Рассмотрим процесс создания файла данных в пакете STATISTICA 10. Представим, что у нас есть записи результатов олимпийских чемпионов в
беге на 100 м с 1896 г. по 2012 г. Введем эти данные в STATISTICA 10 и проанализируем их.
Шаг 1. Во вкладке Home (Главная) в группе |
|
|
|
||
File (Файл) выберем команду New (Создать) (ри- |
|
|
сунок 1.2). Эта команда доступна также по комби- |
|
|
нации клавиш CTRL+N. На экране появится окно |
|
|
Create New Document (Создать Новый Доку- |
|
|
мент) (рисунок 1.3). Пакет предложит выбрать |
|
|
один из вариантов документа STATISTICA 10. Вы- |
|
|
берем вкладку Spreadsheet (Таблица) и нажмем |
Рисунок 1.2 – Вкладка |
|
кнопку ОК. |
||
Home (Главная) – группа |
||
STATISTICA 10 автоматически откроет пус- |
||
|
||
тую электронную таблицу, которая и появится на |
File (Файл) |
экране. Сохраним создаваемый файл под именем olimpic.sta. Для этого необходимо выбрать команду Save (Сохранить)  на панели быстрого доступа (рисунок 1.1) или нажать сочетание клавиш CTRL + S.
на панели быстрого доступа (рисунок 1.1) или нажать сочетание клавиш CTRL + S.
Созданная таблица olimpic.sta появится на экране. Пока эта таблица пуста (рисунок 1.4). В таблице имеется 10 переменных – столбцов и 10 наблюдений – строк. В заголовке окна электронной таблицы автоматически отображается имя файла и его размер (olimpic.sta 10v*10c) [1].
11

Рисунок 1.3 – Окно Create New Document (Создать Новый Документ)
Рисунок 1.4 – Таблица olimpic.sta
12
Шаг 2. Настройка таблицы. Проведем настройку таблицы. Создадим столько переменных и наблюдений, сколько необходимо.
Для наших данных требуется только четыре переменные: год проведения Олимпиады; имя чемпиона; страна, которую он представлял; время, показанное на дистанции. Поэтому часть переменных из таблицы необходимо удалить.
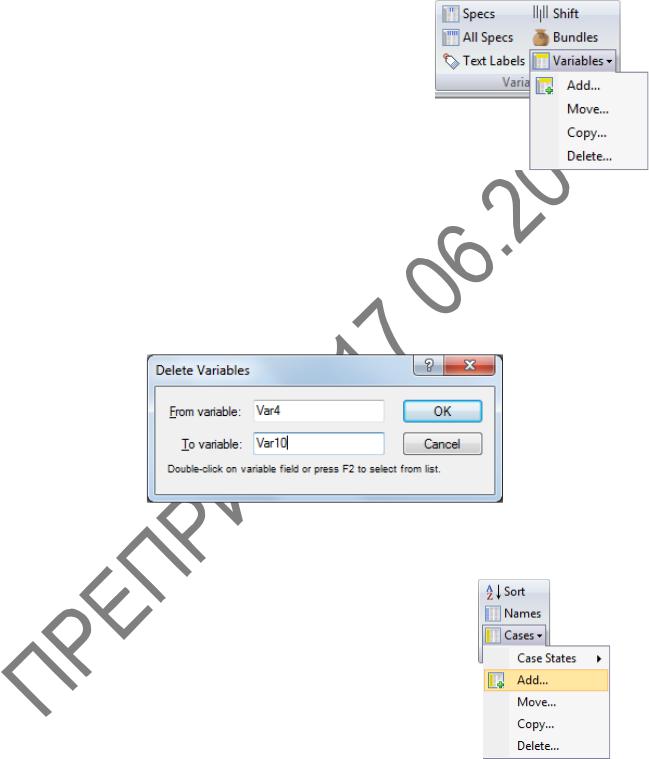
Во вкладке Data (Данные) в группе Variables (Переменные) нажмем кнопку Variables
(Переменные) (рисунок 1.5) и в выпадающем списке выберем команду Delete (Удалить). Эта команда также доступна при вызове контекстного меню нажатием правой клавиши мыши, если указатель мыши при этом установлен на заголовоке
столбца.
В диалоговом окне Delete Variables (Удалить переменные) укажем диапазон удаляемых переменных, как показано на рисунке 1.6. Нажмем кнопку ОК. Переменные с номерами 4, 5, 6, ..., 10 будут удалены. 
Рисунок 1.6 – Окно Delete Variables (Удалить переменные)
Число наблюдений сделаем равным 27. В созданной таблице принято по умолчанию число наблюдений, равное 10. Следовательно, семнадцать наблюдений нужно добавить в таблицу. Чтобы сделать это, во вкладке Data (Данные) в группе Cases (Наблюдения) (рисунок 1.7) воспользуемся кнопкой Cases (Наблюдения), и в выпадающем списке выберем команду Add (Добавить). Эта команда также доступна при вызове контекстного меню нажатием правой клавиши мыши, если указатель мыши при этом установлен на заголовок строки.
13
Рисунок 1.7 – Вкладка Data
(Данные) – группа Cases
(Наблюдения)

Зададим диапазон новых наблюдений |
|
в диалоговом окне Add Cases (Добавить |
|
наблюдения), как показано на рисунке 1.8. |
|
Нажмем кнопку ОК. Теперь наша таблица |
|
имеет нужное число строк и столбцов. |
|
Шаг 3. Подготовка таблицы к вво- |
|
ду данных, заголовок таблицы. Введем |
|
заголовок файла. Дважды щелкаем мышью |
Рисунок 1.8 – Окно Add Cases |
в верхней строке файла. В этой строке |
(Добавить наблюдения) |
можно ввести заголовок таблицы и допол- |
|
нительную информацию о данных. Введем заголовок таблицы, используя клавиатуру, наберем строку «Олимпийские чемпионы в беге на 100 м» [1].
Шаг 4. Задание имен переменных. Введем имена переменных в таблице. Дважды щелкнем на имени переменной Var1 в электронной таблице. На экране появится окно, показанное на рисунке 1.9. 
Рисунок 1.9 – Окно Variable (Переменная)
14

Вэтом окне можно задать имя переменной, тип переменной, формат отображения и некоторые другие свойства, например, текстовые метки.
Вверхней части доступны несколько средств форматирования, которые можно применять к имени переменной.
Вполе Name (Имя) вводится имя переменной, которое будет отображаться
вверхней части столбца в таблице данных. В нашем случае это имя Год (год проведения Олимпиады, когда был показан соответствующий результат).
Вполе Type (Тип) указывается тип данных выбранной переменной, например, число, дата, время и др.
Вполе MD Code (Код ПД) отображается код пропущенных данных, который будет использоваться в качестве значения, если ячейки пусты. Код пропущенных данных для текстовых значений всегда является пустой строкой.
Вполе Length (Ширина) вводится максимальное число символов для выбранной переменной. Это поле доступно только, если выбран текстовый тип данных.
По умолчанию переменные отображаются в формате целого числа, то есть отсутствуют десятичные разряды после запятой. Для данных об олимпийских чемпионах разряды после запятой не нужны. Но если, например, необходимо отображать количество разрядов, равное 3, то эта установка производится в группе опций Display Format (Формат отображения), путем задания параметра Decimal Places (Дес. разряды) равным трем [1].
Вполе Long Name (Длинное имя) можно ввести длинное имя или формулу
вкачестве параметра переменной.
Чтобы определить формулу в поле Long Name (Длинное имя) необходимо ввести перед выражением знак равенства и далее записать формулу, используя для переменных обозначения vl, v2... Наблюдения обозначаются символом v0. С помощью формул можно вычислить значения одних переменных, используя значения других переменных, например, определить новую переменную, как сумму vl
и v2 [1].
Можно использовать разнообразные встроенные функции, например, sin, cos и так далее.
Кнопка Functions (Функциями) вызывает диалог Function Browser (Дис-
петчер функций), который можно использовать для ввода необходимых функций в формулу.
Опция Function guide (Просмотр функций) обеспечивает использование справки при вводе формулы в поле Long Name (Длинное имя). Если ввести в поле Long Name (Длинное имя) знак равенства (который обозначает формулу), то при вводе следующих букв будет отображаться соответствующий список доступных функций STATISTICA 10. Можно выбрать любую функцию из этого списка, вставив ее в поле Long Name (Длинное имя) [1].
Кнопки со стрелками (<< и >>) используются для перехода между переменными в активной таблице данных.
15

Кнопка All Specs (Все спецификации) вызывает диалог Variable Specifications Editor (Редактор спецификаций переменных). Этот диалог можно использовать для изменения свойств переменных в активной таблице данных [1].
Кнопка Text Labels (Текстовые метки) вызывает диалог Text Labels Editor (Редактор текстовых меток). Этот диалог используется для создания или изменения текстовых меток, соответствующих выбранным переменным.
Все значения в пакете STATISTICA 10 могут иметь два представления: текстовое и числовое. Например, при вводе текстовых значений можно использовать кодировку: мужчины – 1, женщины – 2; ввести численные значения, а затем перейти к текстовому отображению.
Кнопка Values/Stats (Значения/статистики) вызывает диалог Values/Stats (Значения/статистики), в котором отображается дополнительная информация о
выбранной переменной, |
|
||||
включая |
список |
всех |
|
||
значений |
и |
описатель- |
|
||
ных статистик. |
|
|
|||
|
Введем имя пере- |
|
|||
менной Var1 – Чемпи- |
|
||||
он. |
Переменной |
Var2 |
|
||
присвоим имя Страна. |
|
||||
Переменной Var3 – имя |
|
||||
Время [1]. |
|
|
|
||
|
Далее |
определим |
|
||
имена наблюдений. Для |
|
||||
этого |
осуществим |
|
|||
двойной |
щелчок |
левой |
|
||
кнопкой мыши по но- |
|
||||
меру |
наблюдения и |
|
|||
введем |
название |
на- |
|
||
блюдения – год уста- |
|
||||
новления рекорда. |
|
|
|||
|
Шаг 5. |
|
Ввод |
|
|
данных |
в |
электрон- |
|
||
ную |
таблицу. Введем |
|
|||
данные |
с клавиатуры. |
|
|||
Полностью |
заполнен- |
|
|||
ная |
таблица |
результа- |
|
||
тов олимпийский |
чем- |
|
|||
пионов в беге на 100 м |
|
||||
появится на экране (ри- |
Рисунок 1.10 – Электронная таблица |
||||
сунок 1.10). |
|
|
с исходными данными |
||
|
|
|
|
|
16 |

Из таблицы видно, что чемпион Олимпиады 2012 г., Усен Болт, показал результат 9,63 с.
Шаг 6. Сохранение файла данных. Для сохранения файла необходимо щелкнуть мышью на кнопку Save (Сохранить)  на панели быстрого доступа (рисунок 1.1) или нажать сочетание клавиш CTRL + S.
на панели быстрого доступа (рисунок 1.1) или нажать сочетание клавиш CTRL + S.
Шаг 7. Визуальное представление. Прежде всего, визуализируем данные. Нажмем правой кнопкой мыши на любое наблюдение переменной Время. Из выпадающего меню выберем линейный график, как показано на рисунке 1.11.
Рисунок 1.11 – Выбор линейного графика (Line Plot) из выпадающего списка
Пакет STATISTICA 10 построит линейный график, у которого по оси абсцисс отложены год проведения Олимпиады, по оси ординат – время, показанное чемпионом в соответствующем году (рисунок 1.12). Из графика видно, что у олимпийских чемпионов имеется устойчивая тенденция улучшать результаты: наихудшее время показано в 1896 г., наилучшее – в 2012 г. Однако эта тенденция
17

не абсолютна, в ней имеются колебания – за улучшением результатов может последовать ухудшение [1].
Рисунок 1.12 – Линейный график для переменной Время олимпийских чемпионов в беге на 100 м
1.4 Вычисление описательных статистик данных в пакете STATISTICA 10
Рассмотрим вычисление описательных статистик на примере таблицы с результатами олимпийских чемпионов в беге на 100 м, созданной ранее.
Выделим переменную Время щелчком мыши по ее имени в таблице и щелкнем правой кнопкой мыши по выделенному столбцу, из выпадающего списка вы-
берем Statistics of Block Data (Блоковые статистики) – Block Columns (По столбцам) – All (Все) (рисунок 1.11).
Можно поступить и другим образом: на вкладке Statistics (Анализ) в группе
Base (Базовая статистика) выберать Basic Statistics (Основные статистики и таблицы). На экране появится окно Basic Statistics and Tables (Основные стати-
стики и таблицы) (рисунок 1.13), в котором необходимо выбрать пункт Descriptive statistics (Описательные статистики) и нажать ОК.
18

Рисунок 1.13 – Окно Basic Statistics and Tables
(Основные статистики и таблицы)
В открывшемся окне Descriptive statistics (Описательные статистики) (ри-
сунок 1.14) выберем переменную Время, нажав кнопку Variables (Переменные). Выберем на вкладке Advanced (Дополнительно) опции, как показано на рисунке 1.14, и нажмем на Summary (ОК).
Электронная таблица с основными описательными статистиками для переменной Время появится на экране (рисунок 1.15).
Основные статистические показатели, присутствующие в окне Descriptive statistics (Описательные статистики) (рисунок 1.14) следующие:
–Valid N (N набл.) – истинное число наблюдений переменной (число наблюдений без пропусков);
–% valid obsvn. (% набл.) – доля наблюдений, пригодных для проведения анализа;
–Mean (Среднее) – выборочное среднее;
–Sum (Сумма) – сумма значений переменной;
–Median (Медиана) – медиана;
–Mode (Мода) – мода;
–Minimum & maximum (Минимум и максимум) – минимальное и максимальное значения переменной;
–Range (Размах) – разность между максимумом и минимумом;
19

–Standard Deviation (Стандартное отклонение) – выборочное стандартное отклонение;
–Variance (Дисперсия) – выборочная дисперсия;
–Conf. limits for means (Доверит. интервал среднего) – доверительный интервал среднего для заданного в процентах уровня нижней и верхней границы;
–Skewness (Асимметрия) – выборочный коэффициент асимметрии;
–Kurtosis (Эксцесс) – выборочный коэффициент эксцесса;
–Std. err. of mean (Стандартн. ошибка среднего) – стандартная ошибка
среднего.
Рисунок 1.14 – Окно Descriptive statistics (Описательные статистики)
Рисунок 1.15 – Электронная таблица с описательными статистиками результатов олимпийских чемпионов в беге на 100 м
20