

Прямые измерения
Обозначим
истинное значение некоторой физической
величины через x.
Результаты n
отдельных измерений – х![]() ,
х
,
х![]() ,…,
х
,…,
х![]() (случайные
величины). Тогда абсолютной ошибкой
хi
i-го
измерения называется разность: х
(случайные
величины). Тогда абсолютной ошибкой
хi
i-го
измерения называется разность: х![]() =
х
– х
=
х
– х![]() .
Абсолютные ошибки также являются
случайными величинами. Огромное
количество опытных фактов, накопленных
в экспериментальной физике, позволяет
установить два основополагающих
предположения относительно абсолютных
ошибок измерения:
.
Абсолютные ошибки также являются
случайными величинами. Огромное
количество опытных фактов, накопленных
в экспериментальной физике, позволяет
установить два основополагающих
предположения относительно абсолютных
ошибок измерения:
1. При большом числе измерений случайные абсолютные ошибки одинаковой величины, но разного знака встречаются одинаково часто.
2. Большие (по абсолютной величине) погрешности встречаются реже, чем малые, т.е. вероятность появления погрешности уменьшается с ростом величины погрешности.
Эти два предположения лежат в основе теории ошибок.
Найдем наиболее точную оценку величины х. С этой целью проведем ряд преобразований. Величины отдельных измерений можно выразить так:
х![]() =
х
- х1;
=
х
- х1;
х![]() =
х -
х2;
=
х -
х2;
……………
хn = х - хn .
Почленное
сложение всех равенств дает:
![]() .
.
Отсюда для х получим
![]() ,
,
где
![]() – среднее арифметическое из n
измерений.
– среднее арифметическое из n
измерений.
Из
предположения 1 при n
следует:
![]() .
.
Поэтому при бесконечно большом числе измерений x = <x>. Однако в реальном эксперименте число измерений всегда ограничено, т.е. x < x >. При обработке результатов измерений в качестве наиболее точного значения величины х принимается среднее арифметическое из n измерений.
Для оценки отклонения истинного значения х от среднего арифметического рассмотрим некоторые понятия теории вероятности.
Случайная величина может быть дискретной (выпадение герба монеты или какой-либо грани кубика при подбрасывании), т.е. принимать ряд дискретных значений, или непрерывной (температура в помещении).
Для дискретной величины: если в N опытах случайная величина появляется Ni раз, то вероятность Р появления этой величины равна
![]() .
.
П ример.
Если подбросить монету 10 раз, то пусть
герб выпадет 3 раза и vi
= 0,3 (vi=
Ni
/
N
– относительная частота появления
герба в опыте). Но если подбросить монету
105
раз, то vi
будет очень близко к 0,5. Если подбросить
1010
раз, то vi
будет еще ближе к 0,5. Таким образом,
величина 0,5 –
вероятность появления герба в опыте.
Понятие вероятности справедливо для
случайных процессов. Мы не знаем, появится
ли данное событие (выпадение герба) в
опыте, но мы характеризуем появление
этого события понятием вероятности и
численным значением вероятности.
ример.
Если подбросить монету 10 раз, то пусть
герб выпадет 3 раза и vi
= 0,3 (vi=
Ni
/
N
– относительная частота появления
герба в опыте). Но если подбросить монету
105
раз, то vi
будет очень близко к 0,5. Если подбросить
1010
раз, то vi
будет еще ближе к 0,5. Таким образом,
величина 0,5 –
вероятность появления герба в опыте.
Понятие вероятности справедливо для
случайных процессов. Мы не знаем, появится
ли данное событие (выпадение герба) в
опыте, но мы характеризуем появление
этого события понятием вероятности и
численным значением вероятности.
Если случайная величина х – непрерывная, то ставится вопрос: какова вероятность того, что случайная величина окажется в опыте в определенном бесконечно малом интервале dx около некоторого значения хi .
Эта вероятность пропорциональна ширине интервала dx и зависит от значения xi , т.е. dP(x) = y(x)dx. За вероятность появления случайной величины х в интервале dx около значения xi dP(xi) = y(xi) dx принимают относительную частоту появлений этой величины в интервале dx около значения xi, когда число измерений стремится к бесконечности.
Главную роль в описании случайной величины, распределенной непрерывно, играет функция y(x), которая называется функцией распределения вероятностей.
В
математической статистике показано,
что при выполнении предположений 1 и 2
функция распределения имеет вид (на
рис.1 представлен график этой функции):
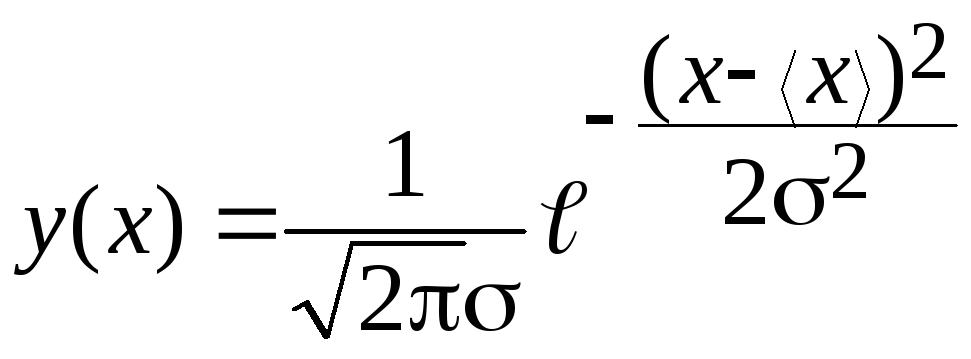 ,
где 2
– дисперсия распределения.
,
где 2
– дисперсия распределения.
Распределение случайной величины такого типа называется нормальным распределением, или распределением Гаусса.
Как видно из рис. 1, дисперсия показывает, насколько широко разбросаны значения случайной величины относительно среднего значения.
Из теории математической статистики следует, что при n измерениях наиболее точную оценку дисперсии дает выражение
 .
.
Величина Sx называется среднеквадратичной погрешностью отдельного измерения.
С реднеквадратичная
погрешность отдельного измерения
характеризует разброс результатов
единичных измерений около среднего
значения. Но главная цель – оценить,
насколько среднее значение близко к
истинному. Если для этого рассмотреть
серии измерений изn1
опытов, n2
и т.д., то в каждой серии можно определить
<x1>,
<x2>,
<x3>
и т.д. Эти средние значения будут
отличаться друг от друга, и, более того,
совокупность этих средних значений
представляет собой набор случайных
величин. Эти случайные величины также
распределены по нормальному закону,
который и будет характеризовать отличие
<x>
от истинного, но с другой дисперсией
<2>.
В теории математической статистики
показано, что наилучшей оценкой <>
распределения средних значений является
величина
реднеквадратичная
погрешность отдельного измерения
характеризует разброс результатов
единичных измерений около среднего
значения. Но главная цель – оценить,
насколько среднее значение близко к
истинному. Если для этого рассмотреть
серии измерений изn1
опытов, n2
и т.д., то в каждой серии можно определить
<x1>,
<x2>,
<x3>
и т.д. Эти средние значения будут
отличаться друг от друга, и, более того,
совокупность этих средних значений
представляет собой набор случайных
величин. Эти случайные величины также
распределены по нормальному закону,
который и будет характеризовать отличие
<x>
от истинного, но с другой дисперсией
<2>.
В теории математической статистики
показано, что наилучшей оценкой <>
распределения средних значений является
величина
 .
.
Величина
![]() называется среднеквадратичной
погрешностью среднего. Величины
и <>
связаны соотношением
называется среднеквадратичной
погрешностью среднего. Величины
и <>
связаны соотношением
![]() ,
причем
– величина постоянная, так как
характеризует разброс результатов
отдельных измерений. Поэтому, чем больше
число измерений, тем меньше среднеквадратичная
погрешность среднего <>
и тем меньше различие между <х>
и истинным значением х.
При выполнении лабораторных работ число
измерений обычно равно 5
10.
,
причем
– величина постоянная, так как
характеризует разброс результатов
отдельных измерений. Поэтому, чем больше
число измерений, тем меньше среднеквадратичная
погрешность среднего <>
и тем меньше различие между <х>
и истинным значением х.
При выполнении лабораторных работ число
измерений обычно равно 5
10.
Характеристикой того, как сильно среднее арифметическое значение отличается от истинного, служит доверительный интервал, для которого известно, с какой вероятностью истинное значение может находиться внутри этого интервала. Величина этой вероятности выбирается экспериментатором и называется надежностью. При выполнении лабораторных работ рекомендуется надежность , равная 0,95. Величина доверительного интервала х с заданной надежностью равна
![]() ,
,
где t(n) – коэффициент Стьюдента, который можно найти в таблице для n измерений и надежности . Окончательный результат записывается в форме х = <х> + х с надежностью . При заметной величине систематической погрешности ошибки объединяют по формуле
 ,
,
где
![]() ;
–
систематическая погрешность прибора.
;
–
систематическая погрешность прибора.
Часто
для оценки погрешности используют
относительную ошибку Е,
которая определяется выражением
 или в процентах:
или в процентах:
 .
.