

2.1.5 Регрессия против проблем классификации.
Переменные могут быть характеризованы либо как количественные, либо как качественные переменные. Количественные переменные принимают числовые значения. Примерами могут быть – возраст, рост, вес и т.д. В отличии от этого, качественные переменные принимают значения в одном из К различных классов или категорий. Примеры такие как пол, бренд купленной продукции, существовании долга, диагноз болезни. Мы склонны обращаться к проблемам с количественным ответом, таким как проблемы регресса, в то время как те, которые включают качественный ответ, упоминается как проблемы регрессии. Тем не менее, это различие не всегда четкое.
Мы склонны выбирать статистические методы обучения на основе того, ответ количественный или качественный, т.е. мы можем использовать линейную регрессию, когда ответ количественный и логическую регрессию, когда качественный. Однако, предсказатели являются качественными или количественными считается менее важным.
2.2 Оценка точности модели.
В статистике нет «бесплатного сыра»: ни один метод не доминирует над другим по всем возможным наборам данных. Выбор лучшего метода, может быть самой сложной частью выполнения статистического обучения.
2.2.1 Измерение качества прогонки.
Для того, чтобы оценить производительность статистического метода обучения на данном наборе данных, нам нужен некоторый способ измерения того, насколько хорошо его предсказания фактически совпадают с наблюдаемыми данными.
В настройках регрессии, наиболее часто используема мера – средне-квадратическая ошибка (MSE),
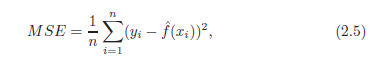
F(xi) – предсказание f для i ого наблюдения. MSE будет малым, если прогнозируемые ответы очень близки к истинным ответам, и будет большим, если для некоторых из наблюдений, предсказанные и истинные ответы существенно отличаются.
MSE вычисляется с использованием данных обучения, который был использован, чтобы соответствовать модели, и как его правильнее называют учебным MSE. В целом, нам все равно, как хорошо работает метод обучающих данных. Скорее, мы заинтересованы в точности предсказаний, которые мы получаем, когда мы применяем наш метод к ранее тестированным данным. Предположим, что мы заинтересованы в развитии алгоритма для прогнозирования цены акции, основанной на предыдущих доходностях акции. Мы можем обучить метод, используя доходности акций из предыдущих 6 месяцев. Но нас не интересует, как хорошо метод предсказывает цену акции за прошлую неделю, нам необходимо предсказывать завтрашнюю цену или цену в следующем месяце.
Математически, представим, что мы соответствуем нашему статистическому методу обучения на наших учебных наблюдениях {(x1,y1),…, (xn,yn)}, и получаем оценку f. Затем мы можем вычислить f(xi). Если они приблизительно равны yi, то MSE мала. Тем не менее, мы не заинтересованы на сколько приблизительно они равны, нам необходимо знать, является ли f(x0) примерно равна y0, где (x0, y0) ранее невидимое испытательное наблюдение, не используемое, чтобы обучить статистический метод. Мы хотим выбрать способ, который дает самую низкую тестируемую MSE, в отличии от самой низкой учебной MSE. Если бы мы имели большое количество текстовых наблюдений, мы могли бы вычислить:
![]()
MSE предсказания для этих испытательных наблюдений (х0,у0). Для выбора метода, сводящего тест MSE к минимуму, нужно оценить 2.6 на тестовых наблюдениях и выбрать метод обучения с наименьшим тестом MSE. Если никакие испытательные наблюдения не доступны, можно было бы предположить статистический метод обучения, который сводит к минимуму учебный MSE. Основная проблема такой стратегии: нет никакой гарантии что метод с низкой учебной MSE также имеет свою самую низкую тестовую MSE. Проблема в том, что многие статистические методы специально оценивают коэффициенты так, чтобы минимизировать MSE набора обучения. Для этих методов, набор MSE может быть достаточно небольшим, но тестовые MSE часто намного больше.
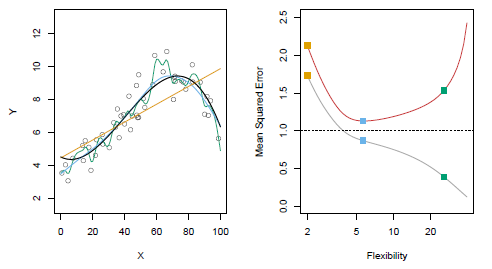
рис 2.9
Данный рисунок иллюстрирует это заявление на простом примере. В левой части мы видим наблюдения из 2.1 с истинным f (черная кривая). Оранжевые, синие, зеленые кривые иллюстрируют три возможных оценки f, полученные с использованием методов, увеличивающие уровни гибкости. Оранжевая линия – это подгонка линейной регрессии, которая является относительно гибкой. Синие и зеленые кривые были получены с помощью сглаживания сплайнов, с разным уровнем гладкости. Зеленая кривая является наиболее гибкой и соответствует данным очень хорошо. Однако, заметим, что она соответствует истинной кривой f (черное) плохо, потому что она слишком волнистая. Регулируя уровень гибкости прогонки сплайна сглаживания, мы можем произвести много различных прогонок к этим данным. На правой части рисунка, серая кривая отображает среднее учебной MSE как функция гибкости, или более формально степени свободы, для многих сплайнов сглаживания. Степени свободы являются величинами, которые суммируют гибкость кривой. Оранжевые, синие, зеленые квадраты указывают MSE, связанные с соответствующими кривыми в левой панели. У более ограниченной и гладкой кривой есть меньше степеней свободы, чем волнистое примечание кривой, что в рисунке 2.9, линейный процесс в самом строгом конце с двумя степенями свободы. Учебный MSE уменьшается монотонно как гибкость в складках. В этом примере истинная f не линейна и таким образом, оранжевая линейная подгонка не является достаточно гибкой, для оценки f хорошо. У зеленой кривой есть самый низкий учебный MSE всех трех методов, так как это соответствует самой гибкой из трех кривых, помещаются в левую группу.
В этом примере, мы знаем истинную функцию F, и таким образом мы можем также вычислить тест MSE над очень большим набором испытаний, в зависимости от гибкости. Тестовая MSE отображается с помощью красной кривой в правой панели рисунка 2.9. Как и в учебной MSE, тестовая MSE первоначально снижается как уровень гибкости возрастает. Тем не менее, в какой-то момент уровни испытаний MSE гаснут, а затем начинают расти снова. Следовательно, оранжевые и зеленые кривые оба имеют высокий тестовый MSE. Синяя кривая минимизирует тестовую MSE, учитывая, что визуально кажется оценить f лучше в левой панели рисунка 2.9. Горизонтальная пунктирная линия показывает Var (е), неприводимую ошибку в (2.3), что соответствует самой низкой достижимости тестовой MSE среди всех возможных методов. Следовательно, сглаживание сплайна представленный синей кривой близко к оптимальному. В правой части, когда гибкость статистического обучения возрастает, происходит монотонное уменьшение учебной MSE и U-образную форму в тестовом MSE. Это фундаментальное свойство статистического обучения.
когда гибкость модели увеличивается, учебная MSE уменьшается, но тестовая MSE нет. Когда этот метод приводит к маленькому обучению MSE, но к большой тестовой MSE, мы говорим о переобучении данных. Независимо от того, произошло переобучение или нет, всегда ожидается, что учебный процесс MSE будет меньшим чем теcтовая MSE, т.к. большинство статистических методов обучения прямо или косвенно направлены на уменьшение учебной MSE.