

Предположим, что мы – статистические консультанты, нанятые клиентом, для предоставления консультации о том, как улучшить продажи конкретного продукта.
Набор данных состоит из продаж этого продукта в 200 различных рынках, наряду с рекламными бюджетами для продукта в каждом из трех рынков для трех видов сми: телевидение, радио, газеты.

Рис 2.1
Для нашего клиента невозможно увеличить продажи продукта. С другой стороны, они могут контролировать свои расходы на рекламу в каждой из трех сред. Цель состоит в том, чтобы разработать точную модель, которая может использоваться при прогнозировании продаж на основе трех бюджетов СМИ.
Рекламные бюджеты являются входными переменными (Х1, .. , Хр), а продажи выходными (У). В целом, мы наблюдаем количественный ответ У и р - различных предикаторов (Х1, .. , Хр). Мы предполагаем, что есть некоторое отношение между У и Х:
Y = f(X)+epsilon (2.1)
F – Некоторая фиксированная, но неизвестная функция (Х1, .. , Хn), и epsilon – случайная величина ошибки, которая не зависит от Х и близка к нулю. F – систематизированная информация , что Х близко к У.
Рассмотрим следующий пример: рис2.2: график доходов по сравнению с годами обучения для 30 человек в наборе данных Доходы. Тем не менее, функция F, соединяющая входную переменную с выходной – неизвестна. В этом случае, необходимо оценить f на основе наблюдаемых точек. Т.к. прибыль это инсценировка набора данных, f известно и показано синей кривой в правой части рис2.2. Вертикальные линии это ошибка epsilon. Некоторые из 30 наблюдений лежат ниже кривой. В целом, ошибка примерно равна 0.
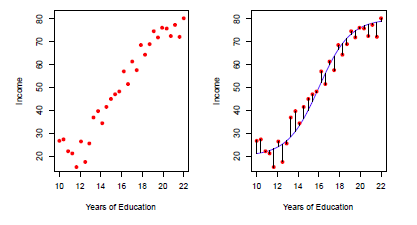
Рис 2.2
В общем, функция f может состоять из более чем одной переменной. На рис 2.3 мы наносим доход в зависимости от года обучения и стажа. Здесь, f – двумерная поверхность, которая должна быть оценена на основе наблюдаемых данных.
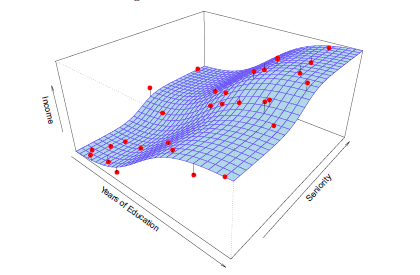
Рис 2.3
2.1.1 Почему оценка f?
1) прогнозирование 2) вывод.
1) Во многих ситуациях, набор данных Х легко доступен, но вывод У не может быть легко получен. В этих условиях, полагая остаточный член epsilon = 0, мы можем показать У, используя:
Y^ = f^(X) (2.2)
F^ - оценка для f. Y^ - результирующий прогноз для Y. В этих условиях, F часто рассматривается как черный ящик, в том смысле, что никто обычно не интересуется точной формой f, при условиях, что он дает точные прогнозы У.
В качестве примера, предположим, что (Х1,…,Хp) – являются характеристиками пациента – Образцы крови, которые могут быть легко измерены в лаборатории, и У это переменная, обозначающая реакцию на конкретное лекарство. Естественно предсказать У с помощью Х, т.к. мы можем затем избежать передачи лекарства пациентам, которые подвергаются высокому риску неблагоприятной реакции, т.е. оценка У для пациента является высокой.
Точность У^ как предсказание для У зависит от двух величин: приводимые и неприводимые ошибки. В общем, f^ не будет идеальной оценкой f, и эта неточность может ввести некоторые ошибки. Эта ошибка является приводимой, т.к. можно потенциально улучшить точность f, используя наиболее подходящий метод статистического обучения оценки f. Тем не менее, даже если было бы возможно сформировать идеальную оценку f, так что предполагаемый ответ принял форму:
Y^ = f(X)
Прогноз будет по-прежнему иметь некоторые ошибки в тесте. Это вызвано тем, что У является также функцией epsilon, которая не может быть предсказана с помощью Х (по определению). Т.о. изменчивость, связанная с epsilon, также влияет на точность предсказаний. Это и есть неприводимые ошибки, потому что независимо от того, насколько хорошо бы не оценивали f, нельзя уменьшить погрешность, вносимую epsilon.
Неприводимая ошибка больше нуля. Количество epsilon может содержать неизмеримые переменные, которые полезны в прогнозировании У: так как мы не можем их измерить, f не может использовать их в своем прогнозировании. Количество epsilon может также содержать неизмеримое изменение. Например, риск неблагоприятной реакции может варьироваться для данного пациента в данный день в зависимости от изменения производства самого препарата или от общего самочувствия пациента в этот день.
Рассмотрим эту оценку f и набор предикторов Х, которые дают предсказание У = f(Х). Предположим, что обе функции F и Х фиксированы.
Затем легко показать, что:
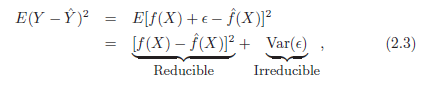
Эта функция показывающая среднее или математическое ожидание квадрата разности между предсказанным и фактическим значением Y, и Var(e) – дисперсия, связанная с ошибкой e.
Вывод
Мы часто заинтересованы в понимании того, как У порождается изменениями Хi. В этой ситуации нам необходимо оценить f, но цель состоит в том чтобы понять отношение между У и Х или понять как У изменяется в зависимости от Хi. В этих условиях, нас интересуют ответы на такие вопросы, как:
Предикторы связаны с ответом? Часто бывает, что только небольшая часть из имеющихся предикторов существенно связана с У. Выделение нескольких важных предсказателей среди большого набора возможных переменных может быть чрезвычайно полезно, в зависимости от приложения.
Какова связь между ответом и каждый предиктором? Некоторые предсказатели могут иметь могут иметь позитивные отношения с У, в том смысле, что увеличение предиктора связано с увеличением значения У. Другие предикторы могут иметь обратное соотношение. В зависимости от сложности f, отношения между реакцией и предиктором могут также зависеть от значения других предсказателей.
Может ли отношение между У и каждым предиктором быть представлено с использованием линейного уравнения? Большинство методов оценки f имеют линейную форму. В некоторых ситуациях, такое предположение разумно или даже желательно. Но часто истинное отношение является более сложным, в таком случае линейная модель не может обеспечить точное соотношение между входными и выходными переменными.
Рассмотрим организацию, которая заинтересована в проведении маркетинговой компании. Цель состоит в том, чтобы выявить лиц, которые будут положительно реагировать на рассылки по почте, основанные на наблюдениях демографических переменных, измеренные на каждом человеке. В этом случае, демографические переменные служат в качестве предсказателей, и ответ на маркетинговую компанию (положительный или отрицательный) служит результатом. Компания не заинтересована в получении глубокого понимания взаимосвязей между каждым отдельным предсказателем и ответом; вместо этого, компания желает получить точную модель для прогнозирования ответа, используя предикторы. Это пример моделирования прогнозирования.
Рассмотрим рекламные данные на рисунке 2.1. Кто-то может быть заинтересован в ответе на вопросы:
Какие СМИ способствуют продажам?
какие СМИ производят самое большое повышение продаж?
насколько могут быть увеличены продажи, связанные с увеличением рекламы на ТВ?
Эта ситуация попадает в парадигмы вывода.
Рассмотри другой пример связанный с моделированием бренда продукта, который клиент может покупать на основе переменных, таких как цель, местоположение магазина, размер скидок и т.д. В этой ситуации можно было бы действительно быть наиболее заинтересованным в том, как каждая из переменных влияет на вероятность покупки. Например, какой эффект будет при изменении цены продукта? Это пример моделирования для вывода.
Наконец, некоторое моделирование может быть проведено и для прогнозирования и для вывода. Например, в условиях недвижимости, можно связать стоимость дома. На вход: уровень преступности, зонирование, расстояние от реки, школы, магазины и т.д. В этом случае можно было бы быть заинтересованным в том, как отдельные входные переменные влияют на цены. Это – проблема вывода. В качестве альтернативы, можно просто быть заинтересованным в предсказании стоимости дома с учетом характеристики: у этого дома занижена или завышена оценка? это – проблема предсказания. В зависимости от того, является ли нашей целью предсказание, вывод или комбинация их двоих, различные методы для оценки f могут быть соответствующими.