

2.1.3 Компромисс между прогнозированием точности и моделью интерпретируемости.
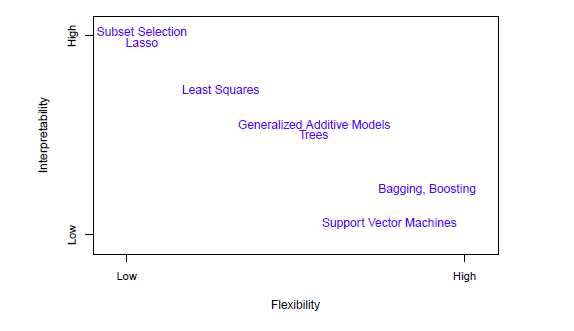
рис 2.7
Рис 2.7 иллюстрация компромисса между гибкостью и интерпретируемостью для некоторых методов. Метод наименьших квадратов линейной регрессии, не гибкий, но вполне интерпретируемый.
2.1.4 Контролируемое против неконтролируемого обучения
Большинство проблем статистического обучения относится к оной из двух категорий: контролируемое или неконтролируемое. Примеры, которые мы обсуждали, попадают в контролируемую область обучения. Для каждого наблюдения за измерениями предсказателя xi, i = 1,...,n есть связанное измерение ответа yi. Неконтролируемое обучение описывает сложную ситуацию, в которой для каждого наблюдения i = 1,...,n, мы наблюдаем вектор измерений xi. Невозможно соответствовать линейной модели регрессии, т.к. нет никакой переменной ответа, чтобы предсказать. В этих условиях нам не хватает переменной ответа, которая может контролировать наш анализ. Одним статистическим инструментом обучения, который мы можем использовать в этой ситуации, является кластерный анализ или кластеризация. Цель кластерного анализ состоит в том, чтобы установить, на основе статистических данных, попадают ли эти наблюдения в различные группы. Например, в сегментации рынка исследования, мы могли бы наблюдать несколько характеристик (переменных) для потенциальных клиентов, такие как почтовый индекс, семейный доход и прочее. Мы могли бы полагать, что клиенты попадают в различные группы, такие как, кто много тратит по сравнению с низкими транжирами. Если информация о структуре расходов каждого клиента была бы доступна, то контролируемы анализ был бы возможен. Однако эта информация недоступна..т.е. мы не знаем, является ли наш потенциальный клиент крупным расточителем или нет. В этих условиях, мы можем попытаться сгруппировать клиентов на основе измеренных переменных, чтобы определить различные группы потенциальных клиентов. Идентификация таких групп может представить интерес, потому что могло бы случиться так, что группы отличаются относительно некоторой собственности интереса, такие как, покупательские привычки.
Рис 2.8 показывает проблему кластеризации. В левой части это относительно простая задача, в отличие от правой, он иллюстрирует более сложную задачу, в которой есть некоторые совпадения между группами. Метод кластеризации состоит в том, чтобы группы не пересекались (синий, зеленый, оранжевый)
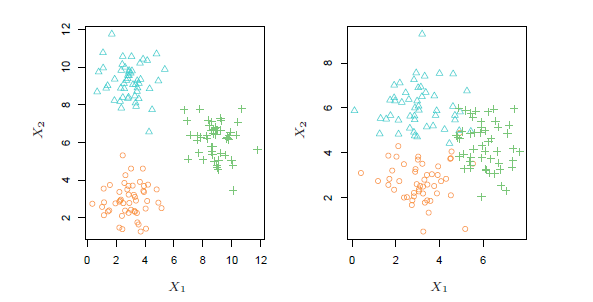
Рис 2.8
В примерах на данном рисунке, есть только две переменные, и таким образом, можно просто рассмотреть графики разброса наблюдений с целью определения групп. Однако, на практике, мы часто сталкиваемся с наборами данных, которые содержат больше, чем две переменные. В этом случае мы не можем легко построить наблюдения. Например, если есть p переменные в нашем наборе данных, то могут быть сделаны p(p-1)/2 различных разброса участков, и визуальный осмотр просто не является способом определения кластеров и следовательно автоматизированные способы кластеризации важны.
Многие проблемы попадают в контролируемые и неконтролируемые парадигмы обучения. Например, предположим, что у нас есть набор n – наблюдений. Для m – наблюдений, где m < n, у нас есть и измерение предсказателя и измерение ответа. Для остальных n – m наблюдений, у нас есть прогнозирующие измерения, но нет результата измерения. Такой сценарий может возникнуть, если предсказатели могут быть измерены относительно дешево, но соответствующие ответы на много более дороже. Мы называем эту установку, как Задача обучения полу-контроля. В этих условиях, мы хотим использовать статистический метод обучения, который может включать m наблюдений, для которых измерение ответа доступны, а также n-m наблюдений, для которых они не доступны.