

Редукция аудиоданных, обусловленная психоакустическими особенностями
Человек со своими органами чувств в состоянии принимать огромные потоки информации. Но сознательно он способен обрабатывать лишь около 100 бит/с информации. Поэтому можно говорить о присущей ЗС избыточности. Значительной проблемой при цифровом представлении ЗС является сокращение имеющейся в них статистической и психофизической избыточности. Это позволяет уменьшить скорость цифрового потока при кодировании ЗС до предельно возможной величины, при которой шумы, помехи и искажения остаются еще незаметными на слух даже для высококвалифицированных экспертов. Особенно важную роль играет сокращение психофизической избыточности ЗС, основанное на учете такого феномена слухового восприятия, как маскировка, и ряда динамических свойств слуха. Напомним наиболее основные для дальнейшего изложения свойства слуха.
Большое значение имеет такое понятие, как порог слышимости, ниже которого акустические сигналы не воспринимаются. Величина порога слышимости не постоянна, она согласуется со звуковыми событиями и зависит, во-первых, от частоты и, во-вторых, от уровня других сигналов, на фоне которых воспринимается данный звук. Например, вследствие маскировки громкий звук может сделать неслышимым тихое звучание. При этом значение имеют формы спектров ЗС, их уровни и временная последовательность. Важно и то, идет ли речь о тонах или звуках, имеющих широкополосные спектры. Достаточно полно исследовано, как изменяется (сдвигается) временно порог слышимости одного сигнала в присутствии другого, как тон и шум делают неслышимым звучание в соседних частотных полосах диапазона слышимых частот (см. кривые изменения относительного порога слышимости тона NaT в присутствии узкополосного мешающего шума Nа ш, показанные на рис. 1.27, а) и как громкое звуковое событие маскирует восприятие более тихих звуков, которые начинаются несколько раньше, т.е. опережают сигнал высокого уровня на интервал времени –30…20 мс (явление предмаскировки), или позже, т.е. запаздывают по времени на 0…120 мс (явление послемаскировки).
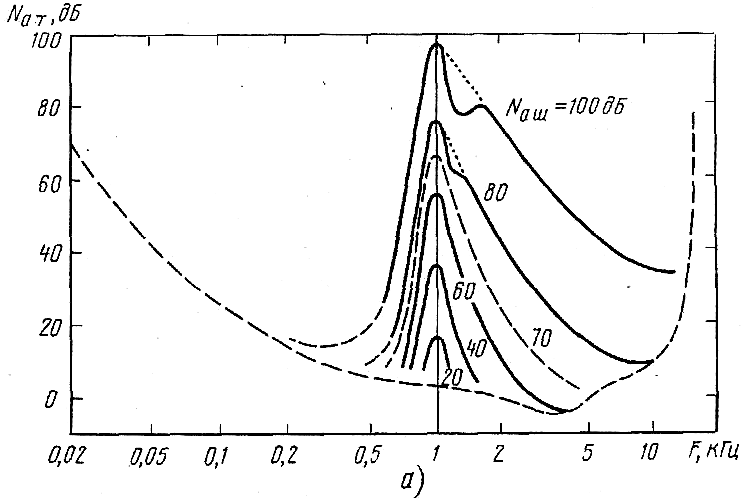

Рис. 1.27 — Зависимость изменения относительного порога слышимости тона при его маскировке узкополосным шумом со средней частотой
1000 Гц для разных уровней последнего (а) и структурная схема кодера musicam с дополнительным спектральным анализом для оценки
относительного порога слышимости (б)
Если известно, какие доли (части) ЗС ухо воспринимает, а какие нет вследствие явления маскировки, то нужно вычленить и затем передать по каналу связи лишь те части сигнала, которые ухо способно воспринять, а неслышимые доли (части, составляющие сигнала) можно отбросить.
Кроме того, сигналы можно квантовать с возможно меньшим разрешением так, чтобы шумы квантования, изменяясь по величине с изменением уровня самого сигнала, еще не становились бы слышимыми.
Учет всех этих свойств слуха и связанных с ним особенностей восприятия позволяет сильно сократить общее число бит, требуемое для цифрового представления ЗС, т.е. сократить то количество информации, которое необходимо передать или запомнить без потери качества звучания. За счет устранения психофизической избыточности можно уменьшить требуемый объем для высококачественной передачи (записи) цифровых аудиоданных более чем в 10 раз.
Исследования, выполненные в данном направлении, позволили разработать два принципиально новых высокоэффективных метода цифрового представления ЗС: ASPEC — Audio Spectral Perceptual Entropics Coding (разработан фирмой AT&T, Thomson Brand und Fraunhofer Geselschaft) и MUSICAM — Masking Pattern Universal Subband Integrated Coding And Multiplexing (разработан Институтом техники радиовещания в Мюнхене, фирмой Филипс и ССЕТТ). Методы позволят в будущем использовать для передачи высококачественных сигналов ЗВ узкополосные каналы (телефон, сети ISDN). Рассмотренные методы предполагается использовать также в системах цифрового радиовещания (Digital Audio Broadcasting — DAB).
Кроме учета свойств слуха и связанным с этим сокращением объема цифровой информации, приняты во внимание также и экономические факторы. В частности, декодер должен быть максимально простым, что возможно, если алгоритм обработки сигналов при их декодировании четко определен (задан). Тогда декодер будет максимально дешевым при массовом производстве. Кодирование даже при минимизации всех затрат может оставаться сложным, а значит, и дорогим, особенно если учитывать свойства человеческого уха. Алгоритм обработки сигналов не должен быть жестким, ибо наши знания о механизмах слуха постоянно развиваются и уточняются, меняются и характеристики звукового материала. Поэтому должна иметься возможность изменения сигналов управления при кодировании, которые формируются на стороне передачи и затем доводятся до декодера. Такой подход открывает возможность улучшения качества передачи. При этом пользователям не нужно будет постоянно менять свои декодирующие устройства, что важно с потребительской точки зрения. В будущем изменения, по-видимому, коснутся методов кодирования на стороне передачи.
В идее MPEG (Moving Pictures Experts Group) содержатся две психоакустические модели, которые могут альтернативно служить в качестве основы для редукции аудиоданных при их обработке с целью сокращения избыточности передаваемых (консервируемых) цифровых ЗС. Возможная редукция аудиоданных в обоих моделях различна. Однако для декодирования этих сигналов используется один и тот же декодер.
В стандарте ISO/IEC 11172-3 (часть 3) предусмотрено несколько уровней (ступеней, слоев) компрессии цифровых аудиоданных, при этом декодеры более высокой ступени могут декодировать сигналы, подвергнутые меньшей компрессии на стороне передачи. Возможны три ступени компрессии, каждой из которых соответствуют своя скорость цифрового потока и своя рекомендуемая область применения. Перечислим основные характеристики ступеней:
«Layer 1» (слой 1) — рекомендуется для применения в профессиональной области и в системах записи с достаточной емкостью памяти, перезаписью и записью со студийным качеством, очень высоким качеством звука, характеризуется небольшой сложностью и не слишком высокой степенью редукции аудиоданных. Основные параметры: скорость цифрового потока при передаче составляет 192 кбит/с в полосе частот ЗС, равной 15 кГц; коэффициент компрессии равен 4; запаздывание (задержка) сигнала при обработке составляет 20 мс.
«Layer 2» (слой 2) — потребительская область, простые профессиональные случаи применения, высококачественное радиовещание, средняя сложность и средняя степень компрессии аудиоданных при их цифровой обработке. Основные параметры: скорость цифрового потока 128 кбит/с в полосе частот ЗС, равной 15 кГц; коэффициент компрессии 6; запаздывание сигнала 40...50 мс.
«Layer 3» (слой 3) — рекомендуется для передачи речи по узкополосным каналам в сети ISDN в профессиональной области (в радиовещании и в системах записи с малой емкостью памяти и средним качеством), отличается высокой сложностью и характеризуется следующими параметрами: скорость цифрового потока 64 кбит/с в полосе частот сигнала 15 кГц; время задержки сигнала более 50 мс.
Напомним, что уже в аналоговых системах для расширения динамического диапазона передаваемого ЗС в новейших компандерных системах (« Dolby-A», -В, -С; dBx; «Highom»; «Panda») учитываются свойства слуха и прежде всего явление маскировки. Общим для таких систем является то, что на стороне передачи с помощью сжимателя поднимают уровни сигнала при тихих пассажах, а затем после передачи (или записи) при воспроизведении они обрабатываются снова в расширителе с целью компенсации ранее внесенных изменений.
Однако даже если при этом используется раздельная обработка частей сигнала в полосах частот, то важным является то, что эти выделенные частотные диапазоны довольно широкополосные (например, «Dolby-A»), а значит, имеющиеся в них помехи и шумы отличаются сравнительно невысокими значениями порогов маскировки.
Сокращение объема цифровой информации, применяемое, например, при методе MUSICAM, предусматривает отбор по времени и спектру долей сигнала таким образом, чтобы выше порога слышимости помехи, шумы и искажения отсутствовали при слуховом восприятии. Иначе говоря, после обработки в сигнале должны отсутствовать те частотные компоненты и те временные отрезки, которые при слуховом восприятии маскируются, частотные области без сигнала при этом должны быть свободны от информации и, следовательно, от шумов. Величина шага квантования изменяется так, что шум квантования остается неслышимым, т.е. маскируется полезным сигналом. Соотношение амплитуды полезного сигнала и минимального относительного порога слышимости определяет в этом случае величину необходимого шага квантования. Чтобы этот подход имел высокую эффективность, предварительно широкополосный ЗС разделяют фильтрами на узкополосные составляющие, близкие по полосе к критическим полосам слуха, где маскировка наиболее ощутима, так как обработка ЗС в слуховой системе выполняется именно в этих полосах.
В MUSICAM-кодере спектр входного цифрового ЗС разделяется блоком полифазных фильтров на 32 узкополосные составляющие (рис. 1.27, б). Преимуществом этих фильтров является относительно малое время задержки сигнала при одновременной компенсации искажений, возникающих за счет интерференции сигналов в местах стыковки полос. К тому же их реализация не очень сложна. Все n = 32 полос пропускания блока цифровых фильтров имеют постоянную ширину:
![]() (1.46)
(1.46)
где fд — частота дискретизации ЗС. После фильтрации следующие по времени друг за другом значения отсчетов каждой отдельной полосы собираются в один блок, после чего в нем определяется максимальное значение отсчета, которое определяет коэффициент масштаба. Масштабный коэффициент кодируется с помощью 6 бит, что обеспечивает перекрытие динамического диапазона сигнала в 120 дБ.
Параллельно этому в кодере в так называемой психоаутенической модели вычисляется относительный порог слышимости для спектральных компонент выборки ЗС. Далее с учетом этого полученного значения рассчитываются величина SNR (отношение сигнал/маска) и требуемый шаг квантования. Обратим внимание (см. рис. 1.27, б), что параллельно фильтрации для ЗС осуществляется быстрое преобразование Фурье (БПФ). Оно необходимо для расчета глобального порога маскировки и далее отношения SNR для каждой субполосы.
Параллельный анализ банком фильтров и применение БПФ обеспечивают незначительное время прохождения сигнала (менее 25 мс в кодере).
На рис. 1.28 в качестве примера показан амплитудный спектр (SPL, вертикальные линии с точками) в сравнении с относительным порогом слышимости (кривая LT сложной формы) и допустимыми максимальными по величине шумами квантования в полосах (заштрихованный диапазон) кодирования ЗС по методу MUSICAM.
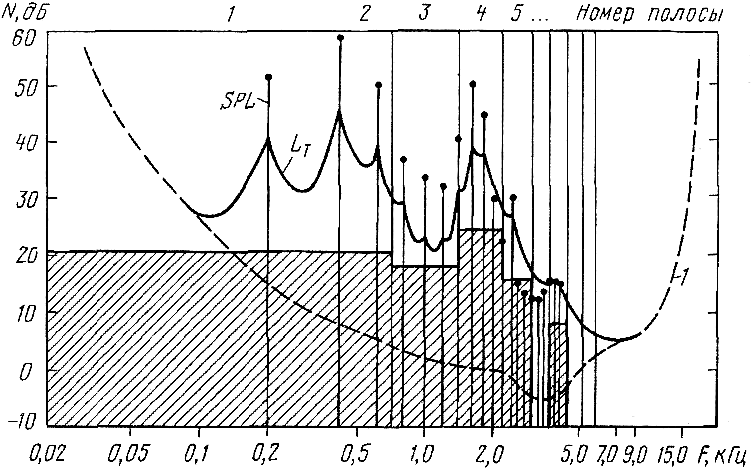
Рис. 1.28 — Спектр звука «ео» (вокал), зависимость изменения относительно порога слышимости и допустимые уровни шумов квантования при его полосной обработке в кодере MUSICAM (заштрихованные области)
Полезным сигналом является певческое исполнение сочетания звуков «ео» с основным тоном, равным 200 Гц, и целым рядом сопутствующих ему обертонов. Штриховая линия представляет собой абсолютный порог слышимости тона в тишине (кривая 1). Не все части этого сложного сигнала, если они существуют одновременно, могут быть восприняты слухом, несмотря на то, что каждая спектральная компонента лежит выше абсолютного порога слышимости, полученного для тонального сигнала. Те части сигнала и шумы, которые находятся ниже относительного порога слышимости LT, неслышны.
Этот порог получается из учета уровней спектральных частей (основного тона и обертонов) сигнала, попадающих в каждую отдельную полосу частот. Для другого звука кривая порога LT очевидно будет выглядеть иначе. Все спектральные компоненты сигнала, оказавшиеся в одной полосе, обрабатываются в кодере MUSICAM совместно с одинаковым шагом квантования. В разных полосах величина шага квантования имеет свое значение и в соответствии с этим свой уровень шумов квантования (см. рис. 1.28, заштрихованная область). Уровень мешающего сигнала лежит всегда ниже относительного порога слышимости (кривая LT). Те спектральные компоненты, которые лежат по уровню ниже кривой LT, передавать не требуется.
Итак, для сокращения объема цифровой информации с учетом психоакустической модели необходимы следующие шаги и вычисления:
Пересчет спектральных компонентов с помощью БПФ из временной области в частотную.
Определение уровня интенсивности сигнала в каждой частотной полосе.
Определение абсолютного порога слышимости.
Выделение тональных (синусоподобных) и нетональных частей (шумоподобных) спектральных компонент.
Редуцирование спектральных компонент.
Вычисление индивидуальных кривых маскировки, оставшихся после редуцирования спектральных компонент.
Вычисление (расчет) глобального порога маскировки.
Вычисление наименьшего значения порога маскировки для каждой частотной субполосы.
Расчет SNR (отношения сигнал/маска) для каждой субполосы.
Весь этот комплекс вычислений выполняется в психоаутенической модели MPEG-кодера. Последовательность операций, выполняемых в MPEG-кодере (ISO/ICE 11172-3), представлена на рис. 1.29.
Блоком полифазных фильтров (с оптимизированным окном) входной сигнал разделяется на 32 части (субполосы), в каждой из которых для совместной обработки используются 12 или 36 значений отсчетов, объединенных в группу. Субполосы имеют одинаковую ширину. Полосные сигналы дискретизируются с частотами, кратными 32 кГц. В слое 3 («Layer 3») в группы объединяются 6 или 18 значений отсчетов (6x32 или 18x32). Быстрое преобразование Фурье выполняется для 512 («Layer 1») или 1024 («Layer 2») значений отсчетов. Разрешение подсистемы при этом составляет fд/512 или соответственно fд/1024. В качестве частот дискретизации предусмотрены уже известные нам значения 48, 44,1 и 32 кГц.

Рис. 1.29 — Алгоритм кодирования ЗС в соответствии
со стандартом ISO/IEC 11172-3
После того, как в кодере определены уровни сигнала в отдельных частотных субполосах, определяется абсолютный порог слышимости и анализируется, идет ли речь о тональных (синусоподобных) или нетональных (шумовых) частях сигнала. На основе использованной психоакустической модели идентифицируются доли (части) сигнала, которые в значительной степени маскируются, и затем вычисляется отношение SNR, при котором шум еще маскируется полезным сигналом. Эти расчеты в слоях 1 и 2 выполняются для каждой субполосы, а в слое 3 — для групп частотных полос. С помощью вычисленных значений SNR и уровней сигнала для каждой субполосы рассчитываются шаги квантования и необходимое для кодирования число бит. Общее число бит распределяется между субполосами так, чтобы выполнялись требования, относящиеся как к скорости передачи сигнала, так и к маскировке шумов в каждой субполосе. При большой компрессии неизбежные слышимые искажения стараются оформить по возможности как «приятные».
Расчеты, выполняемые для слоя 3 («Layer 3»), более трудоемкие, поскольку обрабатываются несколько выборок исходного поворота ЗС одновременно. При форматировании цифровых данных объединяются информационные аудиоданные и данные управления. В слоях 1 и 2 для кодирования в каждой субполосе применяется обычная ИКМ с линейным квантованием, при этом в слое 2 квантованные значения могут быть объединены в группы. В случае слоя 3 применяются коды Хаффмена, длина которых переменная и тем самым адаптирована (по возможности) к низким скоростям передачи битов. Наверняка многим известен код Морзе, в котором часто встречающиеся буквы имеют мало битов, а редко встречающиеся — много битов. В кодере слоя 3 («Layer 3») использована и эта идея для получения большей компрессии данных.
Декодер сигналов (рис. 1.30), кодированных методом MUSICAM, проверяет входящие данные на ошибки, а также разделяет данные управления процессом декодирования и сжатые информационные аудиоданные. Прежде всего разделенные на отдельные полосы сигналы экспандируются с помощью информации управления, в результате происходит их обратное преобразование в исходную форму. В инверсном блоке фильтров различные спектральные части ЗС вновь объединяются в первоначальный сигнал. Результатом этого является цифровой поток аудиоданных на выходе декодера, который уже подготовлен для цифроаналогового преобразования.
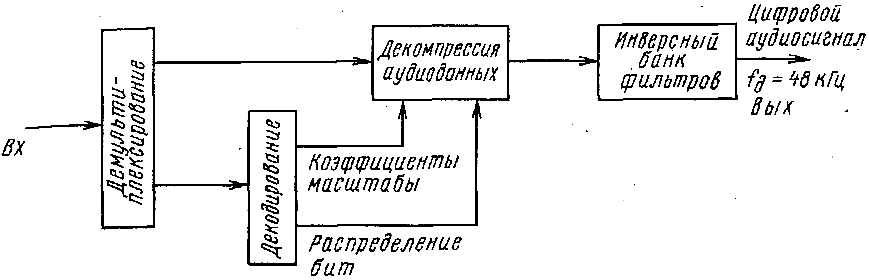
Рис. 1.30 — Структура декодера системы кодирования MUSICAM
Поскольку при каждой передаче могут возникать ошибки, то для борьбы с ними (как об этом уже говорилось ранее) применяют коды с проверочными битами (см. разд. 1.7), которые служат для распознавания и коррекции ошибок. Затраты на эти операции должны быть как можно меньше. Поэтому есть смысл выяснить, какие погрешности передачи слышимы, менее слышимы и неслышимы вообще. Эффективная защита в соответствии с этой оценкой должна реализоваться с разной силой. В нормах MPEG ошибки по их слышимости классифицируются по пяти ступеням. Сильно заметными на слух (катастрофическими) являются ошибки в битах, определяющих место (позицию) отдельных частей данных и значение коэффициента масштаба. Заметными являются ошибки в трех старших битах коэффициента масштаба, менее мешающими — ошибки в младших низкозначимых битах коэффициента масштаба и в старших информационных битах субполосных составляющих ЗС, практически неслышимыми — ошибки в обоих самых младших низкозначимых информационных битах субполосных сигналов.
В настоящее время декодеры MUSICAM разработаны в виде интегральных микросхем, которые могут декодировать сигналы слоев 1, 2 и 3. Единый декодер, который может обрабатывать сигнал слоев 1, 2 и 3 одновременно, находится еще в стадии разработки. Не выясненной пока остается также и предельно допустимая степень сжатия D сигнала, при которой искажения остаются еще незаметными на слух, особенно это относится к передаче стереофонического сигнала, где при сжатии D могут возникать и другие искажения, связанные с пространственным демаскированием.
Контрольные вопросы
Назовите основные погрешности при аналого-цифровом преобразовании. Поясните причины, их вызывающие.
Сравните равномерное и неравномерное квантования отсчетов ЗС с точки зрения скорости передачи и отношения сигнал/шум.
Нарисуйте спектр АИМ колебания. В каких случаях может возникнуть эффект наложения спектров?
В чем трудность реализации неравномерного квантования? Как можно определить допустимое значение динамического диапазона сигнала, если задана разрядность кодового слова?
Перечислите основные трудности в реализации цифроаналогового преобразования.
Как можно оценить выигрыш от применения компандера при цифровом преобразовании ЗС?
Какие законы компрессии обычно применяются в ЗВ? Поясните их особенности и принципы реализации.
Какие свойства сигнала и слуха используются при почти мгновенном компандировании?
Что такое статистическая избыточность цифрового ЗС?
Почему можно говорить о психоакустической избыточности цифровых ЗС и как можно ее уменьшить?
Перечислите основные особенности системы кодирования «MUSICAM».