

4.2.3. Динамический метод назначения весов
Вес wik термина tk в тексте Di определяется как:
wik = IVik,
где IVik – информативность (Information Value) термина tk в тексте Di, принимает значения от 0 до 2.
И
1
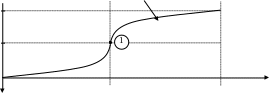
нформативность того или иного термина определяется экспериментально, а первоначально всем терминам приписываются одинаковые значения информативности, например, равные 1 (точка на рисунке).
Таким образом, начальными условиями для динамического назначения информативности для каждого tik являются: IVik = 1 и xik = 0. Тогда в случае полезности термина в процессе его использования его информативность увеличивается, а в случае бесполезности – уменьшается, причем указанные изменения имеют синусоидальный характер.
IV IV=1+sin(x)
2
1
0
-/2 0 /2 x
Увеличение (+) или уменьшение (-) информативности выполняется по формуле
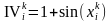 ,
,
где
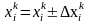 ,
,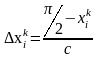 ;
;
c – константа, имеющая смысл: число экспериментов для установления информативности термина.
Таким образом, в результате индексирования набора из n текстов (любым из рассмотренных методов) формируется справочник со структурой:
Термин tk |
Текст Di |
|||
Ф1 |
Ф2 |
... |
Фn |
|
t1 |
w11 |
w21 |
|
wn1 |
t2 |
w12 |
w22 |
|
wn2 |
... |
|
|
|
|
tT |
w1T |
w2T |
|
wnT |
Такие справочники характерны для инвертированных файлов.
4.3. Кластеризация текстов
Для организации хранения кластерных файлов требуется их разбиение на кластеры.
Методы кластеризации основаны на построении полной матрицы подобия текстов заданного пространства, в которой для каждой пары текстов Di, Dj приводится коэффициент подобия S(Di,Dj). Затем вводится некоторое пороговое значение коэффициента подобия Ŝ: если S(Di,Dj)> Ŝ, тексты Di, Dj включаются в кластер, иначе – не включаются.
4.4. Поиск релевантных текстов
Как отмечалось, наиболее употребляемыми на практике являются два способа – инвертированные и кластерные файлы. Рассмотрим, как решается задача поиска релевантных текстов в этих случаях.
4.4.1. Поиск в инвертированных файлах
Пусть есть пространство текстов размером n, каждый из которых характеризуется вектором Vi = {(tk; wki)}. Пусть запрос содержит множество ключевых слов (терминов): q = ({tkq}). Определим формально текст, релевантный запросу q, как такой текст ТБД, для которого коэффициент подобия с запросом отличен от нуля.
Для расчета коэффициента подобия запроса и текстов ТБД применяются вектора текстов и запроса. Определим вектор запроса Vq:
Vq = {(tkq; wkq)},
где tkq – термин запроса;
wkq - вес этого термина.
Тексты Di характеризуются векторами Vi:
Vi = {(tk; wki)},
где tk – термин вектора текста – индексационный термин;
wki - вес этого термина:
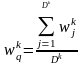
Тогда при поиске релевантного текста (текстов) по запросу q рассчитываются коэффициенты подобия запроса и каждого из текстов ТБД:
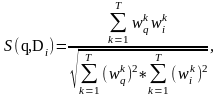
После определения релевантных текстов возможны два подхода:
тексты упорядочиваются по убыванию релевантности, т.е. коэффициента подобия запросу, и предоставляются пользователю в таком упорядоченном виде;
вводится пороговый коэффициент подобия Ŝ: пользователю выдаются только те тексты ТБД, для которых подобие с запросом превышает пороговое значение.