

3.4.1.4. Рандомизация
Этот метод доступа имеет несколько названий: перемешивание, рандомизация, хэширование. Общая схема представлена на рисунке.
О бласть
размещения записей файла
бласть
размещения записей файла
Область размещения записей файла делится на участки – бакеты. При добавлении записей файла в соответствии со значениями первичных ключей Кi алгоритм рандомизации определяет не адрес отдельной записи (как это было в предыдущих случаях), а номер (адрес) бакета. Сама запись размещается в бакете в первом свободном месте – после уже имеющихся в нем записей. Таким образом, записи внутри бакета не упорядочены.
При поиске записи алгоритм рандомизации по первичному ключу определяет вначале номер бакета, в котором должна находиться запись. Затем уже в найденном бакете способом последовательного сканирования делается попытка найти нужную запись.
Алгоритм рандомизации состоит из следующих шагов:
этот шаг выполняется только для нечисловых значений ключа и состоит в их преобразовании в числовые значения. Для этого каждому символу алфавита, который используется для записи значения ключа, приписывается десятичная цифра от 0 до 9 и ключ переписывается. Например, пусть значения ключа формируются из букв русского алфавита. Припишем им десятичные цифры:
а
(1)
б в г д е ё ж з и й к л м н о п р с т у ф х ц ч ш щ ь ъ ы э ю я0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2
Тогда, например, ключ Сидоров запишется как 8945752 (различие прописных и строчных букв игнорируется). Очевидно, такая замена может привести к тому, что разные нечисловые значения будут иметь одинаковые числовые замены. Это одна из причин потери информации при выполнении алгоритмов рандомизации;
порядок числового значения ключа приводится к порядку максимального номера бакета. Например, если максимальный номер бакета - четырехзначное число, то числовой ключ 8945752, полученный в предыдущем шаге, должен быть преобразован в четырехзначное число. Для такого преобразования существуют разные способы. Некоторые из них показаны ниже (в предположении, что максимальный номер бакета – четырехзначное число):
метод квадратов: значение ключа возводится в квадрат. В полученном числе выбирается средняя часть, состоящая из требуемого количества цифр. Например, для числа 8945752 такое преобразование будет иметь вид:
8
 945752
80026478845504
4788;
945752
80026478845504
4788;
средняя часть числа,
состоящая из 4 цифр
сдвиг разрядов: разряды ключа делятся на старшие и младшие и сдвигаются друг к другу так, чтобы число перекрывающихся разрядов соответствовало требуемому числу цифр. Совмещенные цифры складываются. Например, для числа 8945752 такое преобразование будет иметь вид:
8
 945752
894 (13)(16)92 4792;
945752
894 (13)(16)92 4792;
 5752
5752
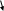
старшие младшие совмещенные результат окончательный
разряды разряды разряды сложения результат совмещенных разрядов
метод складывания: ключ делится на 3 части, средняя из которых по количеству цифр равна требуемому порядку. Первая и третья части налагаются на среднюю часть и совмещенные цифры складываются. Например, для числа 8945752 такое преобразование будет иметь вид:
8
 945752 9457 (17)47(12) 8473.
945752 9457 (17)47(12) 8473.

 8
25
8
25
с редняя
результат окончательный
редняя
результат окончательный
часть наложенные сложения результат
части числа
Очевидно, рассмотренные методы могут дать одинаковые результаты для разных числовых значений ключа. Это вторая причина потери информации при рандомизации. Выбор того или иного метода из трех рассмотренных выполняется экспериментально: лучшим считается тот метод, при использовании которого бакеты заполняются записями относительно равномерно;
полученное на предыдущем шаге число умножается на константу С, которая рассчитывается как отношение максимального номера бакета Nmax к максимальному n-разрядному числу, где n – порядок максимального номера бакета. Это позволяет сформировать реальные номера бакетов. Например, пусть максимальный номер бакета – 7000 (это Nmax). Очевидно, n = 4. Тогда упомянутая константа С имеет значение:
С=7000/9999=0,7.
Рассчитаем реальный номер бакета для результата предыдущего шага, полученного методом складывания: 8473*0,7=5931.