

4.2.2.1. Частотные модели
В применение частоты для оценки значимости термина вкладывают следующий смысл: чем чаще используется тот или иной термин, тем теснее он связан с семантикой текста. Этот тезис побуждает связать вес wik термина tk в тексте Di напрямую с частотой, т.е. wik = fik. Однако этого делать нельзя по двум причинам:
бóльшей частотой могут обладать служебные слова типа предлогов, союзов и т.п., которые не связаны с выражением семантики текста;
минимальной частотой могут характеризоваться «узкие» термины, которые хорошо отражают семантику текста.
По этим соображениям формула для расчета веса термина приобретает вид:
wik = fik* К,
где К – коэффициент, который рассчитывается по разным зависимостям в соответствии с разновидностью частотных моделей.
Так, модель, использующую текстовую частоту термина, определяет К:
К = IDFk,
где IDFk (Inverse Document Frequency) – обратная частота tk в наборе из n текстов:
IDFk
=
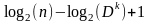 ,
,
Dk – текстовая частота - число текстов набора из n, в которых есть tk.
Модель, учитывающая соотношение «сигнал-шум», рассчитывает К как:
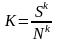 ,
,
где Nk – шум термина tk в наборе из n текстов:
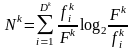 ,
,
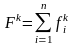 -
суммарная частота термина tk
в наборе из n
текстов,
-
суммарная частота термина tk
в наборе из n
текстов,
Sk - сигнал термина tk в наборе из n текстов:
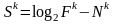 .
.
Модель, учитывающая распределение частоты термина, определяет К по формуле:
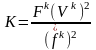 ,
,
где
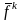 - средняя частота термина tk
в наборе из n
текстов:
- средняя частота термина tk
в наборе из n
текстов:
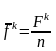 ,
,
(Vk)2 - среднеквадратическое уклонение термина tk:
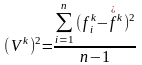 .
.
4.2.2.2. Модель, учитывающая различительную силу термина
В этой модели «хорошим», т.е. имеющим бóльший вес, считается термин, уменьшающий коэффициент подобия текстов. Вес термина здесь также прямо пропорционален его частоте, однако в расчете коэффициента К учитывается роль термина в усилении или уменьшении подобия текстов, что исключает данный метод из числа частотных.
Введем некоторые понятия:
вектор Vi текста Di: Vi = {(tk, fik)} или Vi = {(tk, wik)};
коэффициент подобия S(Di, Dj) текстов Di и Dj:
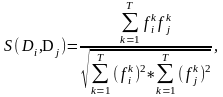
где T = |{tk}| - число индексационных терминов.
Коэффициент подобия принимает значения от 0 до 1: при 0 тексты различны, при 1 – полностью идентичны (по смыслу).
В данной модели К = DVk
где
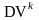 - различительная сила (Difference Volume) термина
tk:
- различительная сила (Difference Volume) термина
tk:
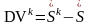 ,
,
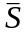 -
среднее значение коэффициента попарного
подобия текстов данного набора в
присутствии термина tk:
-
среднее значение коэффициента попарного
подобия текстов данного набора в
присутствии термина tk:
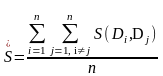 ,
,
 -
то же в отсутствие термина tk.
-
то же в отсутствие термина tk.
Недостатком данной модели является то, что для вычисления средних попарных подобий текстов из набора n текстов требуется n2 операций. Модификация этого метода использует понятие пространства текстов и его характеристик - профиля и плотности пространства текстов.
Пространство текстов – множество текстов, каждый из которых характеризуется вектором. Профиль П пространства из n текстов – это виртуальный текст, вектор которого VП определяется как:
VП = {(tПk, fПk)},
где
{tпk}
=
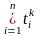 ,
т.е.множество {tпk}
индексационных терминов есть объединение
индексационных терминов текстов набора,
,
т.е.множество {tпk}
индексационных терминов есть объединение
индексационных терминов текстов набора,
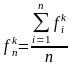 ,
т.е. частоты терминов есть усредненные
частоты терминов по текстам набора.
,
т.е. частоты терминов есть усредненные
частоты терминов по текстам набора.
Плотность Q пространства текстов:
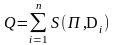 ,
,
где S(П,Di) – коэффициент подобия профиля и текста Di:
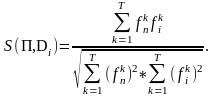
Чем больше Q, тем больше сходство между текстами набора.
С использованием плотности пространства Q можно по другому определить различительную силу DVk термина tk:
DVk = Qk – Q,
где Qk – плотность пространства текстов, когда термин tk исключен из всех текстов набора n,
Q - плотность пространства текстов в присутствии термина tk.