

3.4.1.6. Инвертированные файлы
Основной файл не изменяется. Строятся индексы в нужном количестве. В индекс включаются все значения соответствующего вторичного ключа, а также все ссылки на записи основного файла с данным значением вторичного ключа.
Пусть основной файл показан в таблице:
сотрудник
№ п/п |
ФИО |
ученая степень |
научное звание |
контактные данные |
название (кафедры) |
название (должности) |
1 |
Иванов И.И. |
к.т.н. |
доцент |
234567 |
СУиВТ |
доцент |
2 |
Петров П.П. |
к.т.н. |
нет |
456789 |
ТАМ |
доцент |
3 |
Сидоров С.С. |
нет |
нет |
123456 |
СУиВТ |
ассистент |
4 |
Яковлев Я.Я. |
д.т.н. |
профессор |
345678 |
ТАМ |
профессор |
Соответствующие индексы показаны в таблицах:
ученая степень |
ссылки |
|
научное звание |
ссылки |
|
название (кафедры) |
ссылки |
|
название (должности) |
ссылки |
д.т.н. |
4 |
|
доцент |
1 |
|
СУиВТ |
1, 3 |
|
ассистент |
3 |
к.т.н. |
1, 2 |
|
нет |
2, 3 |
|
ТАМ |
2, 4 |
|
доцент |
1, 2 |
нет |
3 |
|
профессор |
4 |
|
|
|
|
профессор |
4 |
Расположение всех ссылок для некоторого вторичного ключа в одном поле позволяет исключить перебор записей в цепочке записей при их поиске.
Рассмотрим, как выполняется задача поиска нужной записи.
Пусть надо определить список всех сотрудников, работающих в должности доцента, Кдоступ=<название (должности)=доцент>. Поиск осуществляется последовательным выполнением шагов:
по индексу для ключа название (должности) находится соответствующий элемент: это вторая запись в файле;
выбираются ссылки для этой записи: это множество {1, 2};
по основному файлу выбираются последовательно записи с номерами 1 и 2 и выводится содержимое поля ФИО для этих записей; получаем список - Иванов И.И. и Петров П.П. Работа алгоритма закончена.
3.4.2. Методы физического проектирования для иерархических моделей
Традиционными способами организации хранения иерархических моделей являются: множественные ссылки на порожденные записи, ссылки на порожденные и подобные записи; кольцевые структуры; справочники, битовые отображения.
3.4.2.1. Множественные ссылки на порожденные записи
Для хранения подобных записей в иерархических структурах используются реляционные структуры. Записи файлов могут иметь одно или несколько полей, среди которых можно выделять первичные и вторичные ключи. Для указания связей, которые образуют иерархические структуры, применяют систему ссылок. В случае, когда это ссылки на порожденные записи, каждая из них ссылается на некоторую порожденную запись. Количество таких ссылок соответствует числу порожденных записей. Поскольку у записей, соответствующих элементам максимального уровня иерархии дерева, нет порожденных записей, у них отсутствуют какие-либо ссылки.
Рассмотрим данную организацию хранения элементов для дерева, описывающего состав кафедр некоторого факультета:
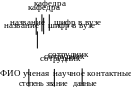
Этому абстрактному дереву соответствует следующая структура, показывающая конкретный состав кафедр вуза (верхний уровень описывает кафедры, нижний - сотрудников):
|
СУиВТ |
239 |
|
|
|
ТАМ |
145 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Иванов И.И. |
к.т.н. |
доцент |
234567 |
|
Петров П.П. |
к.т.н. |
нет |
456789 |
Сидоров С.С. |
нет |
нет |
123456 |
|
Яковлев Я.Я. |
д.т.н. |
профессор |
345678 |

Поскольку в этом дереве есть два множества подобных элементов (кафедры и сотрудники), сформируем для них таблицы:
сотрудник кафедра
№ п/п |
ФИО |
ученая степень |
научное звание |
контактные данные |
|
№ п/п |
название |
шифр в вузе |
1 |
Иванов И.И. |
к.т.н. |
доцент |
234567 |
|
1 |
СУиВТ |
239 |
2 |
Петров П.П. |
к.т.н. |
нет |
456789 |
|
2 |
ТАМ |
145 |
3 |
Сидоров С.С. |
нет |
нет |
123456 |
|
|
|
|
4 |
Яковлев Я.Я. |
д.т.н. |
профессор |
345678 |
|
|
|
|
Теперь надо показать связи между элементами, указанные в дереве. Для этого, в соответствии с рассматриваемым способом, сформируем у таблицы, описывающей кафедры, дополнительное поле ссылки, в котором и зафиксируем требуемые связи. Получим таблицу:
название |
шифр в вузе |
ссылки |
СУиВТ |
239 |
1, 3 |
ТАМ |
145 |
2, 4 |
В таком дереве «хорошо» решаются задачи поиска записей в направлении от корня к терминальным вершинам.
Пусть надо сформировать список сотрудников кафедры СУиВТ (эта задача подобна задаче поиска по вторичному ключу для линейных списков), т.е. Кдоступ = <название (кафедры) = СУиВТ>. Задача решается следующим образом:
по таблице (файлу) кафедра находят требуемую кафедру (для решения этой задачи применимы методы поиска, рассмотренные ранее для последовательной организации данных) – это строка (запись) с номером 1;
выбирают ссылки – это множество {1, 3};
по таблице (файлу) сотрудник обращаются к строкам (записям) с номерами 1 и 3. Получают список сотрудников: Иванов И.И., Сидоров С.С. Алгоритм заканчивает работу.