

10.4. Клиническая статистика
Клиническая статистика изучает достоверность результатов клинических и лабораторных испытаний, связанных с выбором методов лечения, оценкой существенности различий в течение болезни и т. д. Выводы, основанные на данных клинической статистики, зависят от численности наблюдаемых единиц (л) и от методов их сбора. Установление значимых факторов достигается применением группировок, после чего с помощью, например, дисперсионного анализа определяется статистическая значимость различий между группами, т. е. делается вывод о значимости или незначимости фактора, положенного в основу группировки.
Исходная информация, как правило, содержит количественные и неколичественные переменные. Они обобщаются в "перекрестные таблицы» —таблицы сопряженности, чаще всего четырехклеточные, в которых для каждого объекта устанавливается: присутствуют или отсутствуют у него признаки А и Б (табл. 10.8).
Прежде чем собрать
данные, необходимо установить объемы
выборки, поскольку от того, сколько
объектов охвачено, зависят выводы, Чаще
всего клинические испытания основаны
на сравнении двух групп (двух выборок)
равного объема, и проверяется
существенность различий долей. т. е.
пропорций в этих группах—
и
.
Для этого рассчитывается объем выборки,
обеспечивающий достаточную степень
приближения при заданных уровнях
значимости и мощности. Разработаны
специальные таблицы, которые содержат
требуемые размеры для двух равных по
объему выборок из двух групп при различных
значениях предполагаемых пропорций
и
для различных уровней значимости
(
=0,1,0,02;
0,05 и др.) и различных значений мощности
(![]() =0,5; 0,95; 0,99).
=0,5; 0,95; 0,99).
Таблица 10.8
Четырехклеточная таблица сопряженности
Группы по наличию признака А |
Группа по наличию признака Б |
Итого |
||||
|
Есть |
Нет |
|
|||
Есть |
|
|
|
|||
Нет |
|
|
|
|||
Итого |
|
|
|
|||
В исследованиях, характеризующих жизнь и здоровье людей, уровень значимости (вероятность ошибки первого рода) должен быть достаточно мал: 0,02, 0,01 или 0,005. Таблицы требуемого объема выборок при заданных условиях приведены, например, в книге Дж. Флейса1.
Выводы клинического и лабораторного исследования во многом зависят от того, как проводился отбор объектов. Последние должны быть отобраны случайно, т. е. необходима рандомизация (от англ. слова random — случайность), которая гарантирует, что наши наклонности и предпочтения не повлияют на формирование групп.
Рандомизация проводится разными способами. Если, например, нужно в клинических условиях испытать лекарственный препарат, чтобы установить его эффективность, то одним 30 больным можно назначать этот лекарственный препарат, а другим 30 больным — нейтральный препарат. Эксперимент можно начать сразу в полном масштабе, отобрав по таблице случайных чисел числа, соответствующие номерам объектов (скажем, с 1 по 60), и организовать испытание медикамента,
Возможен и иной вариант: например, отбирать для обследования группы по 10 человек. Тогда из таблицы случайных чисел отбираются числа от 0 до 9. При этом пяти первым отобранным номерам будут соответствовать те лица, которые будут принимать активный препарат, а остальным — тех, кто будет принимать нейтральный препарат. Если, например, отбор начинается с седьмого столбца таблицы случайных чисел, то первыми пятью пациентами окажутся лица с номерами 1, 5, 9, 0 (т. е. 10), 4 —им должно быть назначено лекарство, а остальным номерам — 2, 6, 3, 7, 8 нейтральный препарат. Из следующих десяти — лица с номерами 7, 8,1, 9,3 получат активный препарат, остальные—нейтральный и т. д.
Можно отбирать не единицами, а парами: один из пациентов пары будет получать активный, а другой — нейтральный препарат. По первой букве фамилии или имени выбирают одного из двух как первого пациента. Чтобы решить вопрос, какой препарат он будет принимать, договариваются о том, что если первая цифра в первом столбце будет нечетная, то первый будет применять активный препарат, а второй — нейтральный; если первая цифра четная, то второй пациент будет применять активный препарат, а первый — нейтральный.
1См.: Флейс Дж. Статистические методы для изучения таблиц долей и пропорций: Пер. с англ. / Под ред. Ю. Н. Благовещенского. — М.: Финансы и статистика 1989.
Таблица 10.9
Распределение новорожденных-первенцев по весу и возрасту матери
Возраст матери, лет |
Вес новорожденного, г |
Итого |
|
до 3000 |
3000 и более |
||
20—29 |
15 |
135 |
150 |
30—39 |
10 |
40 |
50 |
Итого |
25 |
175 |
200 |
Описанные методы рандомизации чаще применяют в сочетании со стратификацией (от лат. stratum — слой + facere — делать), т. е. разделение пациентов на определенные страты (группы). Например, предварительно выделяют из всех пациентов мужчин в возрасте 20—29 лет, 30—39 лет; женщин в возрасте 20—29 лет, 30—39 лет и т. д. Затем внутри каждой страты применяют методы рандомизированного отбора. Стратификация может производиться не только по полу и возрасту, но и по профессиональным группам, различиям в стадии и тяжести заболевания, месту жительства пациентов и т. д.
Если собранные данные представлены в четырехклеточной таблице сопряженности, то обычно проверяется гипотеза об отсутствии связи между признаками, по которым проведена группировка. Это может быть анализ связи между весом новорожденного-первенца и возрастом матери (табл. 10.9).
Проверим гипотезу о независимости признаков с помощью критерия хи-квадрат (без теоретических частот, с учетом поправки на непрерывность):
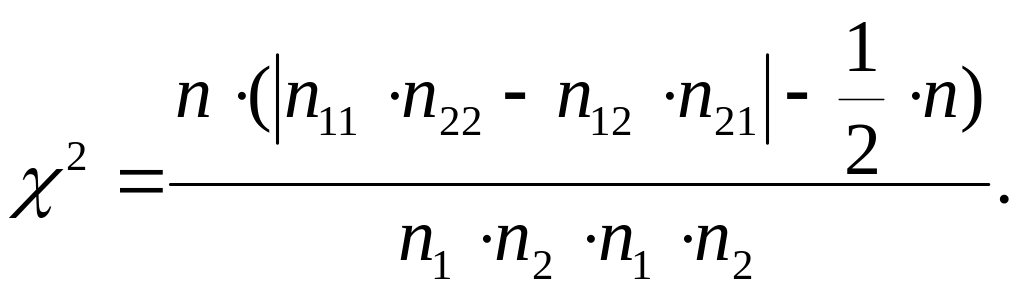
По данным табл. 10.9 получаем:
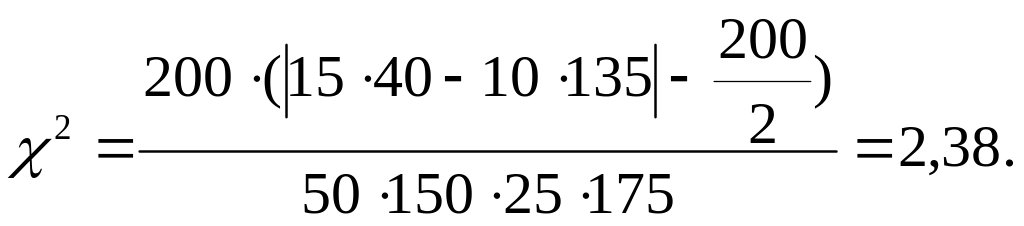
Поскольку эта
величина меньше табличного значения
критерия
![]() при уровне значимости
= 0,05, числе степеней свободы (2 - 1) • (2 -
1) = 1, то связь между весом новорожденного
и возрастом матери статистически
незначима.
при уровне значимости
= 0,05, числе степеней свободы (2 - 1) • (2 -
1) = 1, то связь между весом новорожденного
и возрастом матери статистически
незначима.
В случае таблицы сопряженности большего размера применяется метод ее декомпозиции: выделяются фрагменты 2х2, производятся расчет критерия хи-квадрат для каждого фрагмента, оценка статистической значимости связи для каждого фрагмента и измерение вклада в общую величину критерия хи-квадрат, основанного на всей исходной таблице. Применение этого метода анализа показано в главе 7.
В клинической статистике проверяются не только непараметрические, но и параметрические гипотезы, например, гипотезы о равенстве среднего содержания холестерина в крови у пациентов разных возрастных групп и т. д.
Одним из основных инструментов клинической статистики является дисперсионный анализ, используемый для установления факта значимого или незначимого влияния каких-либо признаков и их взаимодействия. Применяются методы многомерной классификации данных. Часто возникает необходимость решения задачи отнесения больного к той или иной группе. Для этого используется дискриминантный анализ. Этот же метод применяется для оценки влияния совокупности факторов риска на развитие заболевания. Так, в книге А. Афифи и С. Эйзена1 дается пример дискриминантного анализа для описания зависимости от семи факторов риска апостериорной вероятности развития ише-мической болезни у 1929 мужчин и 2540 женщин в возрасте от 30 до 62 лет, причем в начале обследования все пациенты были здоровы, В качестве факторов риска были взяты: возраст (лет), количество холестерина в крови (мг/100 мл), систолическое давление (мм. рт. ст.), относительный вес (100вес—средний вес обследуемых той или иной половой группы), количество гемоглобина в крови (г/100 мл), количество выкуриваемых вдень сигарет (0 — для некурящих, 1 — выкуривающих менее одной пачки, 2 — одну пачку, 3 — более одной пачки), электрокардиограмма (0 — нормальная, 1 —ненормальная или неясная). В результате расчета вероятности развития ишемической болезни для каждого пациента было определено ожидаемое число случаев болезни,
Клиническая статистика позволяет установить социально значимые связи. Например, в результате специальных обследований в США установлено, что примерно 80% детей, родившихся недоношенными (весом до 1 кг), имеют отставание в умственном развитии. Поскольку успехи медицины повышают шансы выживания недоношенных, общество должно быть готово принять на себя определенные обязательства по социальной защите этой категории. Большое общественное значение имеют результаты клинической статистики, связанные с проверкой влияния загрязнения окружающей среды на здоровье населения.
1См.: Афифи А., Эйзен С. Статистический анализ. Подход с использованием ЭВМ /Пер. с англ. — М,: Мир, 1982, — С. 333.