

27.Інформаційні сховища: склад і структура, багатомірна модель даних, проектування багатомірних баз даних, застосування технологій olap для обробки даних.
Сховище даних (DW) - система, що підтримує несуперечливу інтегровану предметно-орієнтовану сукупність історичних даних організації з метою підтримки прийняття стратегічних рішень. Сховище даних представляє також різнобічні інструментальні засоби для аналізу даних.
Концепція сховищ даних - це концепція підготовки даних для подальшого аналізу. Інформаційні сховища призначені для систем підтримки прийняття рішень. Сховища даних розробляються з урахуванням специфіки предметної області, а не застосувань, які обробляють дані. Дані у сховищі повинні бути інтегровані, зведені до єдиного синтаксичного і семантичного вигляду, перевірені на цілісність і несуперечливість.
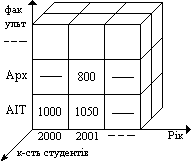
Приклад: багатомірні дані
1). Представлення у вигляді двомірної матриці
Факультет |
Рік |
К-сть студентів |
АІТ |
2000 |
1000 |
АІТ |
2001 |
1050 |
АРХ |
2001 |
800 |
Факультет Рік |
2000 |
2001 |
… |
АІТ |
1000 |
1050 |
|
АРХ |
|
800 |
|
2). Представлення інформації у вигляді тривимірного куба
Decision Cube

С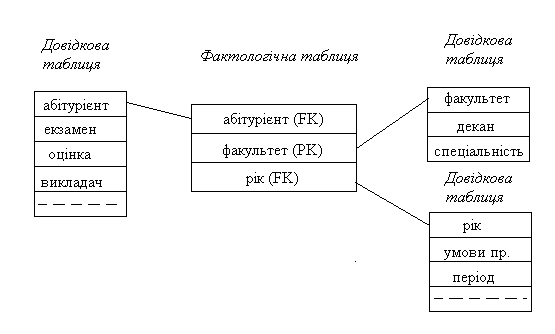 творення
гіпер кубу на мові SQL
має наступний вигляд:
творення
гіпер кубу на мові SQL
має наступний вигляд:
Create cube university (
Domension Faculted
Level Type varchar ()
Level Type varchar ()
Domension Speciality
Level ITP
Level IUST
Domension Year
Level 2000
Level 2001
Основні операції над гіпер кубом:
переріз – передбачає формування підмножини гіперкуба, в якому значення одного або більшої
кількості вимірів є фіксованим.
обертання – передбачає зміну порядку вимірів.
деталізація – передбачає подання інформації по певному пареметру у більш детальному вигляді.
згортання- це консолідація даних, тобто заміна одного з вимірів іншим більш високого рівня.
Основними поняттями багатомірної моделі є: вимірювання та значення.
Вимірювання – це множина, яка утворює одну з граней гіпер кубу і є аналогом домену в реляційній моделі.
З начення
– це дані, які знаходяться по комірках
гіпер кубу.
начення
– це дані, які знаходяться по комірках
гіпер кубу.
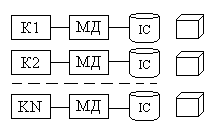
Найбільш відомою схемою збереження гіпер кубу є схема зірка. Зірка представляє собою структуру в центрі якої знаходиться таблиця даних, яка вміщує фактичні дані і яка оточена таблицями розмінностей, які вміщують посилкові дані.
При створенні сховища даних однією з основних задач є визначення оптимальної структури зберігання даних з точки зору забезпечення прийнятного часу відповіді на аналітичні запити і потрібного об'єму пам'яті.
Всі дані в сховищі даних поділяються на такі категорії: детальні дані; агреговані дані; метадані.
Д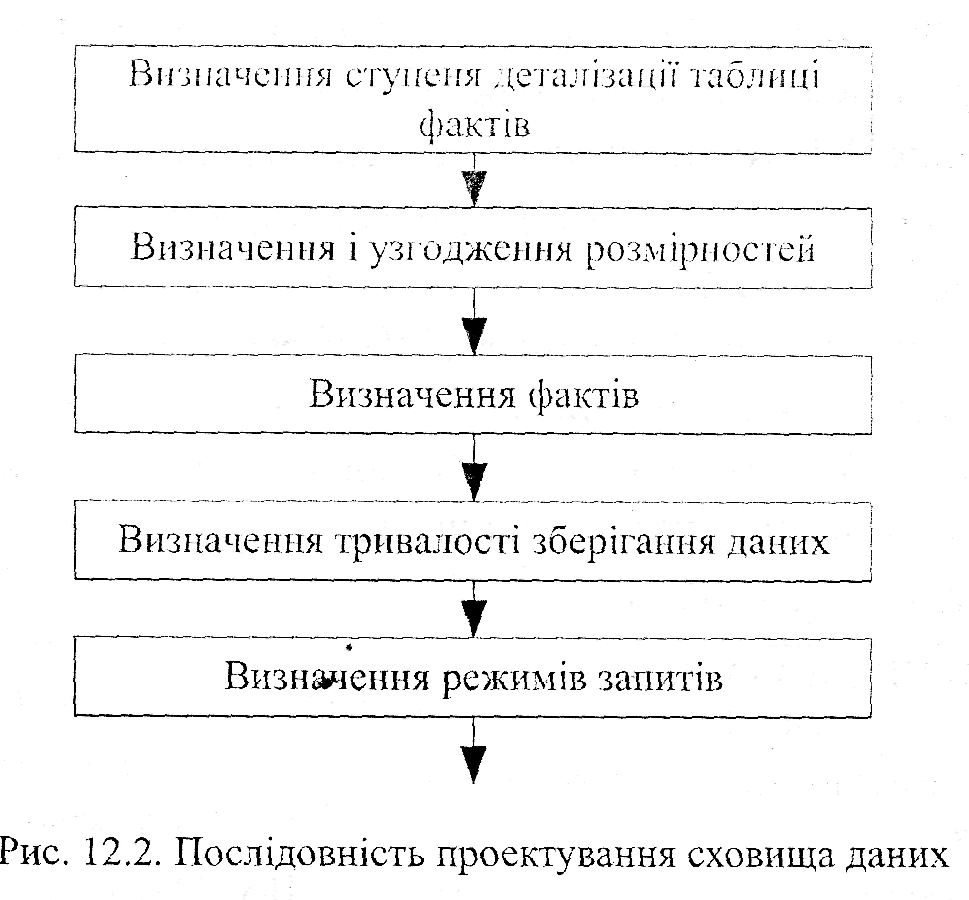 етальні
дані -
дані, які переносяться безпосередньо
від оперативних джерел інформації
(ОLТР).
Вони
відповідають елементарним подіям, що
фіксуються в звичайних БД. Всі дані
поділяються на виміри і факти. Вимірами
називаються
набори даних, які необхідні для опису
подій (студенти, факультети і т.ін.).
Вимір є аналогом домену в реляційній
моделі. Фактами
називаються
дані, які відображають сутність події
(результати екзамену, кількість студентів
і т.ін.). Агреговані
дані -
дані, які отримують агрегуванням
детальних даних по певних вимірах.
Метадані
- це
високорівневі засоби відображення
інформаційної моделі. Метадані містять
таку інформацію: опис структури даних
сховища, структури даних, які імпортуються
з різних джерел, відомості про періодичність
імпортування, методах завантаження і
узагальнення даних, засобах доступу і
правилах представлення інформації,
оцінки витрат часу на отримання
відповіді на запит.
етальні
дані -
дані, які переносяться безпосередньо
від оперативних джерел інформації
(ОLТР).
Вони
відповідають елементарним подіям, що
фіксуються в звичайних БД. Всі дані
поділяються на виміри і факти. Вимірами
називаються
набори даних, які необхідні для опису
подій (студенти, факультети і т.ін.).
Вимір є аналогом домену в реляційній
моделі. Фактами
називаються
дані, які відображають сутність події
(результати екзамену, кількість студентів
і т.ін.). Агреговані
дані -
дані, які отримують агрегуванням
детальних даних по певних вимірах.
Метадані
- це
високорівневі засоби відображення
інформаційної моделі. Метадані містять
таку інформацію: опис структури даних
сховища, структури даних, які імпортуються
з різних джерел, відомості про періодичність
імпортування, методах завантаження і
узагальнення даних, засобах доступу і
правилах представлення інформації,
оцінки витрат часу на отримання
відповіді на запит.
Послідовність проектування сховища даних показана на рис.
При моделюванні сховищ даних використовуються концепції ЕК-моделювання з деякими обмеженнями. Кожна модель складається з таблиці зі складовим ключом, яка називається таблицею фактів, і набору невеликих таблиць, які називаються таблицями розмірностей. У таблиці фактів розміщуються дані, які найбільш інтенсивно використовуються для аналізу. У довідковій таблиці перелічені можливі значення одного з вимірів гіперкуба. Кожен вимір описується своєю власною таблицею.
Кожна таблиця розмірності має простий первинний ключ, який точно відповідає одному з компонентів складового ключа в таблиці фактів. Тобто первинний ключ таблиці фактів складається з декількох зовнішніх ключів. Така нейтралізована структура називається схемою "зірка".
В основі концепції сховищ даних лежить ідея розподілу на дві групи даних, що використовуються: для оперативної обробки (ОLТР) і для рішення задач аналізу (ОLАР).
ОLТР — системи оперативной обробки траизакцій, які призначені для підтримки поточної діяльності різного роду організацій.
ОLАР - системи оперативної аналітичної обробки, які призначені для підтримки прийняття рішень і орієнтовані головним чином на нерегламентовані запити. Термін ОLАР дозволяє описувати технологію обробки даних, в якій застосовується багатомірне представлення апретованих даних для забезпечення швидкого доступу до даних для поглибленого аналізу.
В основі інформаційних сховищ знаходиться багатомірна модель даних , яка наз. гіперкубом.
Математичні методи обробки аналітичної інформації: регресія; кореляція;прогнозування; пластермізація.
Data Mining – система самостійно на основі великих масивів інформації приймає рішення про нові закономірності та зв’язки.
Розрізняють OLAP: MOLAP – Multi OLAP, передбачає створення інформаційних сховищ на основі БД фізично.
ROLAP – Relation OLAP, реляційна OLAP, модель даних, яка існує віртуально.
HOLAP – Hybrid OLAP, застосування і фізичного, і віртуального збереження інформації.
У багатьох випадках замість OLAP застосовують так звані магазини даних, які представляють собою підмножину сховища даних, які підтримують вимоги окремого підрозділу організації.
28.Документальні інформаційні системи, їхній склад і структура; порівняти фактографічні і документальні системи; пояснити яким чином організовано збереження документів, як виконується індексація і пошук документів.
Інформація є: фактографічна (числа ,символи) та документальна.
Фактографічні моделі – містять відомості, які представленні у вигляді спеціальним чином організованих сукупностей формалізованих записів даних.
Документальні моделі даних відповідають представленню про слабко структуровану інформацію, яка орієнтована на вільні формати документів текстів або природні мови.
Слабоструктуровані дані-це дані, які не достатньо формалізовані, або не повні і які мають структуру, яка може швидко і не передбачено змінюватись.
Зберігати дані можна наступним чином:
у вигляді файлової системи;
використання звичайної СУБД;
розробка інформаційної пошукової системи, яка забезпечує пошук або:
по спеціально виділених атрибутах;
повнотекстовий пошук.
4. розробка гіпертекстової системи.
Існує 3 підходи:
1. збереження окремих документів;
2. на кожен документ свор. картка (автор,назва,рік),картки утворюють журнал;
3. інформ.-пошукові системи : по окремим словам,повнотекстові (интернет);розмітка документів
(html,xml).
Модель документу:
Структура- характеризує логічну організацію документів.
Форма-харак. зовнішнє представлення документу.
Фізична організація- характеризує фізичне зберігання документів на зовнішніх носіях інформації.
Розрізняють документи: прості (зміст, структура, фізичне представлення, форми); складні (документ, який включає в себе певні структури-графіка, відео, ауді); віртуальний це документ, який фізично ,як єдине ціле не існує але користувачу представляється як єдине ціле.
Документ характеризується: розподіленою обробкою, захистом документів, багатоверсійністю, колективною роботою над документом, архітектура обробки клієнт-сервер, масштабування.
Системи автоматизованої обробки технічних документів включають в себе:
підсистема управління документами; підсистема управління даними о проектах;
підсистема маршрутизації документів.
PDM передбачає управління данними на протязі всього життєвого циклу документів.
PDM включає в себе :
документацію по САПР
виробничу документацію
маркетингова документація
експлуатація документація
PDM забезпечує розвинену систему пошуку за різними критеріями.
Організація збереження інформації представляє собою бд в якій збер. інформація про проекти, а також картотека з інформацією про документи.

Пошук інформації
Розрізняють: швидкий (по першим літерам);атрибутивний (за картотекою);пошук за електронним підписом;пошук за змістом документу.
Управління доступом: підсистема контролю доступом;підсистема моніторингу доступу до архиву документів.
Функції документальних систем.
Система управління документами (СУД) виконує наступні функції: введення документів; індексування документів (атрибутивне, повнотекстове); функція збереження документів, яка передбачає архівування та підтримку багатоверсійності документів; організація групової роботи над документами; організація прав доступу до документів; формування звітів.
Мови розмітки документів:
SGML-standart genetralised makup language. Ця мова визначає допустимий набір тегів їх атрибутів.
За допомогою SGML можна описувати структуру документу.
HTML –hyper text markup language –дозволяє оформлювати документи, розмічати їх за допомогою
тегів.
XML-extensible markup language –це мова розмітки, яка описує цілий клас об’єктів які називаються
XML-документами. На відміну від HTML ця мова дозволяє зберігати внутрішню структуру
документу. Популярне поєднання : СУБД + XML+WEB
Переваги гіпертекстових систем:наявність користувацького інтерфейсу ,можливість встановлення зв”зків між вузлами і отримання від нього ін фор.; наявність розвиненої системи пошуку ; наявність системи збереження територіально розподіленої інформації.
Значення мови XML для бази даних: Стандартизований засіб представлення інформації;стандартизованиц засіб опису представлення баз даних (XML може працювати з браузером).; чіткий розводіл структури,змісту і відображення інформації; можливість перевірки змісту документів; підтримка міжнародних стандартів для типів документів.
XML працює зі слабо структурованими даними, які є неповними або недостатньо формалізованими і мають структуру що може швидко змінюватись..