

III. Сглаживание экспериментальных данных
Используя исходные данные п. II.1, постройте для показателя ХХХ новый ряд методом скользящего среднего с периодом осреднения N. Для улучшения наглядности графика отформатируйте ось значений (см. таблицу ниже).
Постройте для показателя ХХХ новые ряды методом экспоненциального сглаживания с факторами затухания D1 и D2. Для улучшения наглядности графиков отформатируйте ось значений. Оцените влияние фактора затухания на значения ряда.
Вариант |
1 |
2 |
3 |
XXX |
Средняя зарплата |
Вклады населения |
Объем розничного товарооборота |
N |
3 |
4 |
5 |
D1 |
0,22 |
0,26 |
0,29 |
D2 |
0,4 |
0,43 |
0,47 |
Контрольные вопросы:
Поясните заполнение диалога и результат работы одного из инструментов надстройки «Анализ данных»: генерация случайных чисел, описательная статистика, ранг и персентиль, гистограмма.
По каким функциям вычисляются плотность распределения вероятности и интегральная функция для нормального закона, биномиального закона, закона Пуассона? Назовите параметры этих законов.
Назовите функции для вычисления статистических характеристик случайных величин и поясните смысл этих характеристик.
Тема 11. Средства регрессионного анализа в Excel.
На оглавление
Цель работы: научиться проводить анализ взаимосвязи зависимой и независимых переменных, определять коэффициенты линейной, экспоненциальной и полиномиальной регрессии, оценивать их достоверность, прогнозировать.
Теоретические сведения
Регрессионный анализ — это статистический метод, позволяющий найти уравнение, которое наилучшим образом описывает статистическую зависимость между сериями значений каких-либо величин. В электронных таблицах Excel реализованы три способа регрессионного анализа: 1) инструмент Регрессия из надстройки «Анализ данных» (вкладка Данные—Анализ —Анализ данных); 2) трендовые модели; 3) статистические функции. Если надстройка «Анализ данных» не отображается, то необходимо используя кнопку Офис открыть Параметры Excel – Надстройки и выбрать из списка неактивных надстроек приложений Анализ данных и нажать кнопку Перейти.
Функция
ЛИНЕЙН возвращает коэффициенты линейной
регрессии вида
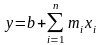 и дополнительную регрессионную
статистику. В
данной формуле:
mi
— коэффициенты
при независимых переменных xi,
n
— количество независимых переменных,
b
— константа.
и дополнительную регрессионную
статистику. В
данной формуле:
mi
— коэффициенты
при независимых переменных xi,
n
— количество независимых переменных,
b
— константа.
Аргументы функции:
1) известные значения Y — диапазон зависимой переменной;
2) известные значения X — диапазон п независимых переменных;
3) конст = 1, чтобы константа b вычислялась обычным образом;
4) статистика = 1, чтобы выводилась дополнительная регрессионная статистика.
Функция вводится как табличная. Для получения результата выделяется 5 строк (чтобы выводилась дополнительная регрессионная статистика) и п + 1 столбцов. Структура результата представлена в таблице:
тп |
тп-1 |
… |
т1 |
b |
[тп ] |
[тп-1 ] |
… |
[т1 ] |
[b] |
R2 |
[y] |
#н/д |
#н/д |
#н/д |
F |
df |
#н/д |
#н/д |
#н/д |
SSreg |
SSresid |
#н/д |
#н/д |
#н/д |
В первой строке таблицы выводятся значения коэффициентов mi и b; во второй — среднеквадратические отклонения коэффициентов при независимых переменных [тi ] и константы [b]; затем располагаются следующие величины:
коэффициент детерминированности R2, который изменяется в пределах [0; 1]. Это величина, характеризующая степень взаимосвязи между зависимой и независимыми переменными. Качественную оценку взаимосвязи можно провести по шкале Чеддока;
R2 |
0,1—0,3 |
0,3—0,5 |
0,5—0,7 |
0,7—0,9 |
0,9—0,99 |
Характеристика силы связи |
слабая |
умеренная |
заметная |
высокая |
весьма высокая |
среднеквадратическое отклонение зависимой переменной [y] ;
F-статистика, используемая для оценки достоверности полученного уравнения;
число степеней свободы df ;
регрессионная SSreg и остаточная SSresid суммы квадратов.
Функция
ЛГРФПРИБЛ определяет параметры
экспоненциального уравнения регрессии
вида
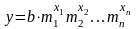 и
дополнительную регрессионную
статистику.
и
дополнительную регрессионную
статистику.
ЛГРФПРИБЛ имеет такие же аргументы, правила ввода и аналогичную структуру результата с функцией ЛИНЕЙН, но в отличие от ЛИНЕЙН во второй строке таблицы результата вместо среднеквадратических отклонений коэффициентов вычисляются их натуральные логарифмы, т.е. ln [тi ] и ln [b].
Функция FРАСП возвращает F-распределение вероятности и используется, чтобы определить, имеют ли два множества данных различные степени разброса результатов. В регрессионном анализе с помощью этой функции оценивается достоверность уравнения — F.
При заполнении аргументов функции FРАСП используются данные полученные с помощью функции ЛИНЕЙН или ЛГРФПРИБЛ:
1) X = F;
2) Степени_свободы1 (числитель степеней свободы) = n;
3) Степени_свободы2 (знаменатель степеней свободы) = df.
Тогда F = 1 – FРАСП (F; n; df )
Функция СТЬЮДРАСП возвращает вероятность для t-распределения Стьюдента. В регрессионном анализе с помощью двустороннего распределения Стьюдента оценивается достоверность коэффициентов — t .
При заполнении аргументов функции СТЬЮДРАСП используются данные полученные с помощью функции ЛИНЕЙН или ЛГРФПРИБЛ:
1) X = t , причем значение t-статистики предварительно вычисляется для каждого коэффициента по формулам:
a)
для линейной и полиномиальной регрессии 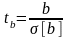
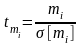
b)
для экспоненциальной регрессии 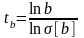
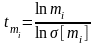
2) Степени_свободы = df ;
3) Хвосты = 2.
Тогда t = 1 – СТЬЮДРАСП (| t | ; df ; 2)
Инструмент Регрессия используется для нахождения коэффициентов линейной регрессии и оценки их достоверности. При заполнении диалога Регрессия следует:
Входной интервал Y — указать диапазон значений зависимой переменной (1 столбец);
Входной интервал X — указать диапазон значений независимых переменных (до 16 столбцов);
Установить флажки Остатки, График остатков;
Выходной интервал — указать верхнюю левую ячейку для вывода результата.
Результаты регрессионного анализа выводятся в четырех таблицах:
1) Вывод итогов — содержит значения среднеквадратического отклонения Y — [y], коэффициента корреляции Пирсона R, коэффициента детерминированности R2;
2) Дисперсионный анализ
|
df |
SS |
MS |
F |
Значимость F |
Регрессия |
n |
SSreg |
SSreg / n |
MSreg/MSresid |
1 – F |
Остаток |
df |
SSresid |
SSresid / df |
|
|
3) Параметры модели
|
Коэффициенты |
Стандартная ошибка |
t-статистика |
P-значение |
Нижние 95% |
Верхние 95% |
Y-пересечение |
b |
[b] |
tb |
1 – tb |
нижняя граница доверительного интервала для b и mi при уровне значимости 95% |
верхняя граница доверительного интервала для b и mi при уровне значимости 95% |
Переменная Х1 |
m1 |
[m1] |
tm1 |
1 – tm1 |
||
… |
… |
… |
… |
… |
||
Переменная Хn |
mn |
[mn] |
tmn |
1 – tm1 |
4) Вывод остатков — содержит расчетные (предсказанные) значения Y и остатки (разность между расчетным и фактическим Y).
Примечание. Смысл буквенных обозначений в таблицах Дисперсионный анализ и Параметры модели пояснен на странице выше при рассмотрении статистических функций. Смысл параметров Значимость F и Р-значение — это вероятность того, что уравнение регрессии и коэффициенты не достоверны, т.е. Значимость F = FРАСП (F; n; df ) и Р-значение = СТЬЮДРАСП (| t | ; df ; 2).
Инструмент Регрессия и функция ЛИНЕЙН могут также использоваться для нахождения коэффициентов полиномиальной регрессии. Например, чтобы получить уравнение зависимости y = f (х1, х2) в виде полинома 2-й степени, нужно предварительно в смежных с х1 и х2 столбцах вычислить х12, х22, х1 х2 и рассматривать их как отдельные переменные. Таким образом, полиномиальная регрессия двух независимых переменных приводится к линейной регрессии пяти переменных:
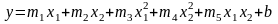 .
.
В случае парной регрессии, если имеется одна зависимая и одна независимая переменная, применим регрессионный анализ по диаграмме, который заключается в построении линий тренда. Порядок его выполнения:
По исходным данным построить диаграмму. Если независимая переменная (х) является временным рядом или ее значения меняются на фиксированный шаг, то тип диаграммы выбирается Гистограмма, График, С областями. Если значения х меняются на произвольный шаг, то строится Точечная диаграмма.
Выполнить команду вкладка Работа с диаграммами – Анализ –Линия тренда – Дополнительные параметры линии тренда или через контекстное меню выбрать команду Добавить линию тренда.
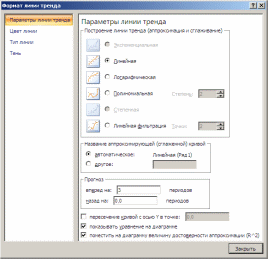
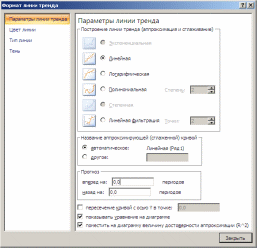
В диалоге Параметры линии тренда выбрать способ аппроксимации (линейный, экспоненциальный, полиномиальный, логарифмический, степенной) и задать:
имя линии тренда;
на сколько шагов делать прогноз вперед и назад (если это требуется);
установить флажки Показывать уравнение на диаграмме и Поместить на диаграмму величину R2.(см. рисунок ниже).
Пример 11.1. Определить, используя соответствующую функцию, уравнение линейной зависимости затрат на ремонт от возраста оборудования и дополнительную регрессионную статистику по данным, расположенным в диапазоне А3:В12. Спрогнозировать по полученному уравнению величину затрат на ремонт для данного возраста оборудования.
Решение:
1) Для вычисления коэффициентов линейной регрессии и дополнительной регрессионной статистики используется функция ЛИНЕЙН, которая возвращает массив результатов. Необходимо поэтому:
выделить 2 столбца, так как одна независимая переменная, и 5 строк (E2:F6);
вставить функцию ЛИНЕЙН и заполнить ее аргументы. Диапазон зависимой переменной — В3:В12; диапазон независимой переменной А3:А12;
не нажимая кнопку ОК, нажать комбинацию клавиш Ctrl + Shift + Enter. Диапазон E2:F6 будет заполнен данными (см. рисунок), по которым можно составить линейное уравнение —
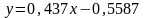
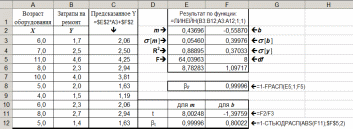
2) Для прогнозирования затрат на ремонт (Yпр) нужно подставить имеющиеся значения возраста оборудования (Х) в полученное уравнение (см. формулу и значения на рисунке в столбце С).
Пример 11.2. Оценить степень взаимосвязи, достоверность уравнения и коэффициентов, найденных в примере 4.1.
Решение:
1) Из результатов предыдущего примера видно, что R2 = 0,889. По шкале Чеддока это соответствует высокой силе связи между переменными.
2) Для оценки достоверности уравнения используется величина F = 64,04 (ячейка Е5) и df = 8 (ячейка F5). Результат вычисления достоверности уравнения и формула приведены на рисунке в ячейках F8 и G8.
3) t-статистика для коэффициентов вычисляется в ячейках E11:F11 как отношение значения коэффициента к его среднеквадратическому отклонению.
4) Для оценки достоверности коэффициентов используется t-статистика и df. Результат вычисления достоверности коэффициентов и формула приведены на рисунке в ячейках Е12:G12.
5) Из полученных результатов следует, что уравнение и коэффициенты имеют высокую достоверность, так как значения F и t близки к 1.
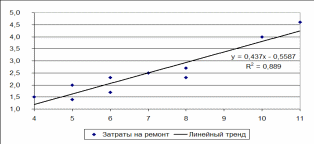
Пример 11.3. Построить линейную трендовую модель зависимости затрат на ремонт от возраста оборудования по исходным данным примера 11.1.
Решение:
1) Выделить диапазон А3:В12 и построить точечную диаграмму зависимости затрат на ремонт от возраста оборудования с помощью мастера диаграмм.
2) Выделить диаграмму, выполнить команду вкладка Работа с диаграммами – Анализ –Линия тренда – Дополнительные параметры линии тренда или через контекстное меню выбрать команду Добавить линию тренда.
3) В открывшемся окне выбрать тип аппроксимации — линейная и задать параметры линии тренда, как показано на рисунке:
4) В результате на диаграмме появится линия тренда, коэффициент детерминированности R2 и линейное уравнение, совпадающее с полученным в примере 11.1.
Пример 11.4. Определить уравнение линейной регрессии, оценить степень взаимосвязи, достоверность уравнения и коэффициентов (исходные данные примера 11.1), используя инструмент Регрессия.
Решение:
1) Выполнить команду вкладка Данные—Анализ —Анализ данных —Регрессия и заполнить открывшийся диалог:
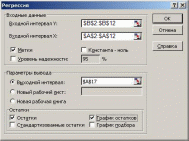
2) После нажатия ОК, начиная с ячейки А17, будут выведены 4 таблицы, которые более компактно представлены на рисунке:
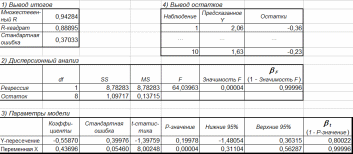
3) столбцы F и t с помощью инструмента не выводятся и вычислены дополнительно по формулам F = 1 – Значимость F и t = 1 – Р-значение.