

Контрольные вопросы к теме
Какими способами можно автоматизировать заполнение шаблона?
Зачем используются относительные ссылки при записи макроса?
Назовите элементы управления и их назначение.
Как создать элемент управления на рабочем листе и изменить его параметры?
Назовите способы выполнения макроса.
Тема 10. Моделирование данных. Оценка частотного распределения случайной величины. Сглаживание экспериментальных данных
На оглавление
Цель работы: получить навыки работы с инструментами надстройки «Анализ данных», научиться вычислять статистические характеристики и распределение вероятности для случайных величин.
Теоретические сведения
Статистическая обработка информации средствами MS Excel может быть реализована двумя путями: 1) в режиме пакета анализа; 2) использование статистических функций.
Пакет анализа представляет собой надстройку MS Excel, включающую 19 инструментов. Для использования какого-либо инструмента нужно выполнить команду вкладка Данные—Анализ —Анализ данных, дважды щелкнуть мышкой по его имени и заполнить появившийся диалог.
Пример 10.1. Сгенерировать 40 значений переменной «Число забракованных изделий», распределенной по биномиальному закону с параметрами: вероятность брака отдельного изделия — 0,1; число испытаний — 10.
Решение:
В ячейку А1 ввести имя переменной — Число забракованных изделий.
Выполнить команду Сервис—Анализ данных—Генерация случайных чисел.
Заполнить диалог, как показано на рисунке и нажать ОК.
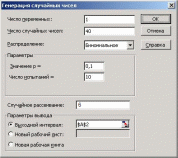
В результате ячейки А2:А41 будут заполнены значениями случайной величины, распределенной по биномиальному закону.
Пример 10.2. Получить распределение переменной «Число забракованных изделий» (см. пример 3.1) по интервалам, используя инструмент Гистограмма. Границы карманов: 0,5; 1,5; 2,5; 3,5.
Решение:
В ячейки С2:С5 ввести границы карманов.
Выполнить команду Сервис—Анализ данных— Гистограмма.
Заполнить диалог, как показано на рисунке и нажать ОК.
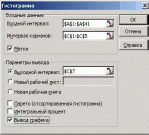
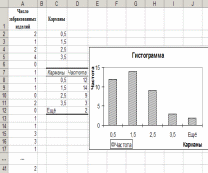
Для вычисления статистических характеристик случайной величины используются следующие функции:
СРЗНАЧ — возвращает среднее арифметическое;
СТАНДОТКЛОН — среднеквадратическое (стандартное) отклонение;
ДИСП — возвращает дисперсию выборки;
СКОС — возвращает асимметрию распределения;
МЕДИАНА, МОДА, ЭКСЦЕСС, МИН, МАКС — возвращают одноименные характеристики.
Аргументом этих функций является диапазон значений случайной величины.
Для нахождения распределения вероятности используются функции:
НОРМРАСП (Х; Среднее; Стандартное_откл; Интегральная1)
Х — значение случайной величины, распределенной по нормальному закону;
Среднее и Стандартное_откл — параметры нормального закона;
БИНОМРАСП (Число_успехов; Число_испытаний; Вероятность_успеха; Интегральная1)
Число_успехов — значение случайной величины, распределенной по биномиальному закону;
Число_испытаний и Вероятность_успеха — параметры биномиального закона;
ПУАССОН (Х; Среднее; Интегральная1)
Х — значение случайной величины, распределенной по закону Пуассона;
Среднее — параметр закона Пуассона;
При проведении анализа взаимного расположения значений случайной величины в ряду данных используются функции:
РАНГ (Число; Ссылка2; Порядок) — возвращает порядковый номер случайной величины, указанной в аргументе Число, в ряду данных. Аргумент Порядок заполнять необязательно, тогда по умолчанию первый ранг присваивается максимальному значению ряда;
ПРОЦЕНТРАНГ (Массив1; Х; Разрядность) — возвращает процентное содержание значения случайной величины, указанного в аргументе Х, в множестве данных. Аргумент Разрядность заполнять необязательно, тогда по умолчанию процентранг вычисляется с точностью 3 знака после запятой. После вычисления процентранга, ячейкам с результатом нужно присвоить формат 0,0%;
ПЕРСЕНТИЛЬ (Массив1; k) — возвращает значение случайной величины для k-го процентранга, т.е. k-ю персентиль;
КВАРТИЛЬ (Массив1; Часть) — возвращает квартиль множества данных;
Пример 10.3. Вычислить плотность распределения вероятности и интегральную функцию распределения для значений случайной величины (диапазон А2:А11), распределенной по нормальному закону.
Решение:
В ячейке F2 вычислить среднее значение: =СРЗНАЧ(А2:А11)
В ячейке F4 вычислить стандартное отклонение: =СТАНДОТКЛОН(А2:А11)
В ячейку В2 ввести формулу: =НОРМРАСП(А2;$F$2;$F$4;0) Протянуть формулу за маркер, чтобы получить плотность распределения вероятности для остальных значений.
В ячейку С2 ввести формулу: =НОРМРАСП(А2;$F$2;$F$4;1) Протянуть формулу за маркер, чтобы получить интегральную функцию распределения для остальных значений.
|
A |
B |
C |
D |
E |
F |
1 |
Случайная величина |
Плотность распределения вероятности |
Интегральная функция распределения |
Ранг |
Процентранг |
Среднее |
2 |
6,77 |
0,359 |
0,112 |
10 |
0,0% |
7,42 |
3 |
6,80 |
0,384 |
0,123 |
9 |
11,1% |
Стандартное отклонение |
4 |
6,86 |
0,434 |
0,148 |
8 |
22,2% |
0,53 |
5 |
7,08 |
0,614 |
0,264 |
7 |
33,3% |
|
6 |
7,32 |
0,738 |
0,428 |
6 |
44,4% |
|
7 |
7,44 |
0,749 |
0,518 |
5 |
55,5% |
|
8 |
7,76 |
0,609 |
0,741 |
4 |
66,6% |
|
9 |
7,94 |
0,462 |
0,838 |
3 |
77,7% |
|
10 |
8,06 |
0,360 |
0,887 |
2 |
88,8% |
|
11 |
8,13 |
0,305 |
0,910 |
1 |
100,0% |
|
Пример 10.4. Для каждого значения случайной величины (см. пример 3.3) вычислить ранг и процентранг.
Решение:
В ячейку D2 ввести формулу: =РАНГ(А2;$А$2:$А$11) Протянуть формулу за маркер, чтобы получить ранг остальных значений.
В ячейку Е2 ввести формулу: =ПРОЦЕНТРАНГ($А$2:$А$11;А2) Протянуть формулу за маркер, чтобы получить процентранг остальных значений. Не отменяя выделения диапазона, выполнить команду Формат—Ячейки—закладка Число, выбрать формат Процентный с одним десятичным знаком.