

В чем суть mmx-технологии и потоковых simd-расширений?
Еще одним примером SIMD - архитектуры является технология MMX, которая существенно улучшила архитектуру микропроцессоров фирмы Intel. Она разработана для ускорения выполнения мультимедийных и коммуникационных программ. В ММХ используются 4 новых типа данных и 57 новых инструкций. Команды ММХ выполняют одну и ту же функцию с различными частями данных, например: 8 байт графических данных передаются в процессор как одно упакованное 64-х разрядное число и обрабатываются одной командой.
Следующим шагом по пути использования SIMD-архитектуры в микропроцессорах фирмы Intel (Pentium III) явились потоковые SIMD-расширения (SSE), которые реализуют 70 новых SIMD-инструкций, оперирующих со специальными 128-битными регистрами. Каждый из этих регистров хранит 4 вещественных числа одинаковой точности. Таким образом, выполняя операцию над двумя регистрами, SSE фактически оперирует четырьмя парами чисел, т.е. благодаря этому процессор может выполнять до четырех операций одновременно.
В чем суть матричного и векторно-конвейерного способов организации simd-архитектуры
Суть матричной структуры заключается в том, что имеется множество процессорных элементов, исполняющих одну и ту же команду над различными элементами матрицы, объединенных коммутатором. Основная проблема заключается в программировании обмена данными между процессорными элементами через коммутатор.
В отличие от матричной структуры, векторно-конвейерная структура компьютера содержит конвейер операций, на котором обрабатываются параллельно элементы векторов и полученные результаты последовательно записываются в единую память. При этом отпадает необходимость в коммутаторе процессорных элементов, служащем камнем преткновения в матричных компьютерах.
Иерархическая структура памяти компьютера
Стоимость памяти составляет значительную часть общей стоимости ЭВМ. Исходя из этого, память ЭВМ организуется в виде иерархической структуры запоминающих устройств, обладающих различным быстродействием и емкостью. Чем выше уровень, тем выше быстродействие соответствующей памяти, но меньше её емкость. Система управления памятью обеспечивает обмен информационными блоками между уровнями, причем обычно первое обращение к блоку информации вызывает его перемещение с низкого медленного уровня на более высокий. Это позволяет при последующих обращениях к данному блоку осуществлять его выборку с более быстродействующего уровня памяти.
Сравнительно небольшая емкость оперативной памяти компенсируется практически неограниченной емкостью внешних запоминающих устройств. Однако эти устройства работают намного медленнее, чем оперативная память. Исходя из этого, вычислительный процесс должен протекать с возможно меньшим числом обращений к внешней памяти.
Н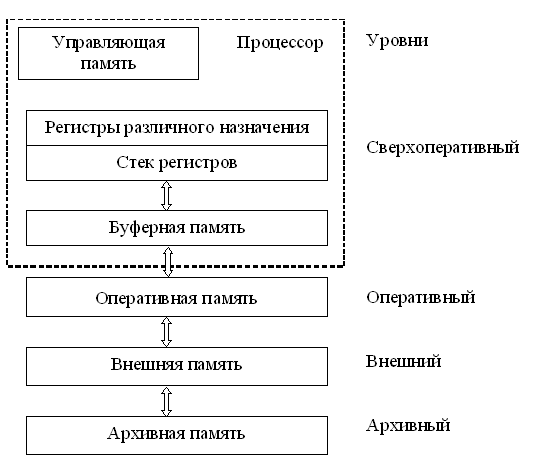 епрерывный
рост производительности ЭВМ проявляется,
в первую очередь, в повышении скорости
работы процессора. Быстродействие ОП
также растет, но все время отстает от
быстродействия аппаратных средств
процессора в значительной степени
потому, что одновременно происходит
опережающий рост её емкости, что делает
более трудным уменьшение времени цикла
работы памяти. Вследствие этого
быстродействие ОП часто оказывается
недостаточным для обеспечения требуемой
производительности ЭВМ.Возникающая
проблема выравнивания их пропускных
способностей решается путем использования
сверхоперативной буферной памяти
небольшой емкости и повышенного
быстродействия.
епрерывный
рост производительности ЭВМ проявляется,
в первую очередь, в повышении скорости
работы процессора. Быстродействие ОП
также растет, но все время отстает от
быстродействия аппаратных средств
процессора в значительной степени
потому, что одновременно происходит
опережающий рост её емкости, что делает
более трудным уменьшение времени цикла
работы памяти. Вследствие этого
быстродействие ОП часто оказывается
недостаточным для обеспечения требуемой
производительности ЭВМ.Возникающая
проблема выравнивания их пропускных
способностей решается путем использования
сверхоперативной буферной памяти
небольшой емкости и повышенного
быстродействия.
При обращении к блоку данных, находящемуся на оперативном уровне, его копия пересылается в сверхоперативную буферную память (СБП). Последующие обращения производятся к копии блока данных, находящейся в СБП. Поскольку время выборки из сверхоперативной буферной памяти tСБУ (несколько наносекунд) много меньше времени выборки из оперативной памяти tОП, введение в структуру памяти СБП приводит к уменьшению эквивалентного времени обращения tЭ по сравнению с tОП:
tЭ = tСБП + atОП ,
где a = (1 — q) и q — вероятность нахождения блока в СБП в момент обращения к нему, т. е. вероятность «попадания».
В основе такой организации взаимодействия ОП и СБП лежит принцип локальности обращений, согласно которому при выполнении какой-либо программы (практически для всех классов задач) большая часть обращений в пределах некоторого интервала времени приходится на ограниченную область адресного пространства ОП, причем обращения к командам и элементам данных этой области производятся многократно. Это позволяет копии наиболее часто используемых участков программ и некоторых данных загрузить в СБП и таким образом обеспечить высокую вероятность попадания q. Высокая эффективность применения СБП достигается при q i 0,9.
Буферная память не является программно доступной. Это значит, что она влияет только на производительность ЭВМ, но не должна оказывать влияния на программирование прикладных задач. Поэтому она получила название кэш-памяти (в переводе с английского — тайник). В структуре одних ЭВМ используется объединенная кэш-память команд и данных, в других ЭВМ — раздельные кэш-памяти для команд и для данных. В современных компьютерах применяют многоуровневую кэш-память (до трех уровней), которая еще больше способствует производительности ЭВМ.