

Методы преобразования виртуального адреса в физический при странично-сегментном распределении памяти с использованием tlb
Процесс преобразования адресов посредством таблиц является достаточно длительным и, естественно, приводит к снижению производительности системы. С целью ускорения этого процесса используется специальная полностью ассоциативная кэш-память (рис. 4.17), которая называется буфером преобразования адресов TLB (translation lookaside buffer).
В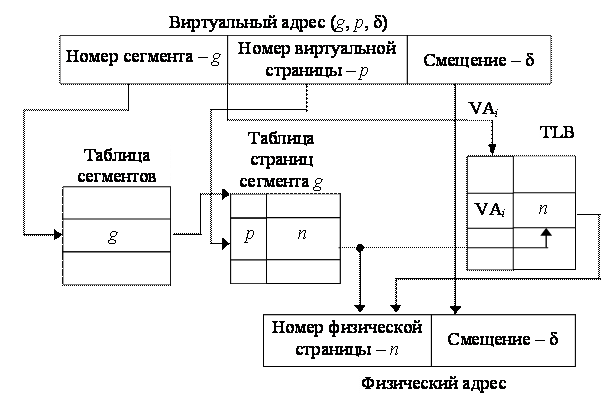 иртуальный
адрес страницы VAi,
составленный из полей g и p,
передается в TLB в качестве
поискового признака (тега). Он сравнивается
с тегами (VA) всех ячеек
TLB, и при совпадении из
найденной ячейки выбирается физический
адрес страницы n,
позволяющий сформировать полный
физический адрес элемента данных,
находящегося в ОП. Если совпадение не
произошло, то трансляция адресов
осуществляется обычными методами через
таблицы сегментов и страниц. Эффективность
преобразования адресов с использованием
TLB зависит от коэффициента
«попадания» в кэш-памяти, т. е. от того,
насколько редко приходится обращаться
к табличным методам трансляции адресов.
Учитывая принцип локальности программ
и данных, можно сказать, что при первом
обращении к странице, расположенной в
ОП, физический адрес определяется с
помощью таблиц и загружается в
соответствующую ячейку TLB.
Последующие обращения к странице
выполняются с использованием TLB.
иртуальный
адрес страницы VAi,
составленный из полей g и p,
передается в TLB в качестве
поискового признака (тега). Он сравнивается
с тегами (VA) всех ячеек
TLB, и при совпадении из
найденной ячейки выбирается физический
адрес страницы n,
позволяющий сформировать полный
физический адрес элемента данных,
находящегося в ОП. Если совпадение не
произошло, то трансляция адресов
осуществляется обычными методами через
таблицы сегментов и страниц. Эффективность
преобразования адресов с использованием
TLB зависит от коэффициента
«попадания» в кэш-памяти, т. е. от того,
насколько редко приходится обращаться
к табличным методам трансляции адресов.
Учитывая принцип локальности программ
и данных, можно сказать, что при первом
обращении к странице, расположенной в
ОП, физический адрес определяется с
помощью таблиц и загружается в
соответствующую ячейку TLB.
Последующие обращения к странице
выполняются с использованием TLB.
Рис. 4.17. Механизм преобразования адресов с использованием TLB
Методы замещения строк в кэш-памяти
Способ определения строки, удаляемой из кэш-памяти, называется стратегией замещения. Для замещения строк кэш-памяти существует несколько методов: метод замещения наиболее давнего по использованию объекта — строки, метод LRU (замещение наименее используемой информации); метод FIFO (первым пришёл — первым вышел) и метод произвольного замещения. В первом случае среди строк, являющихся объектами замещения, выбирается строка, к которой наиболее длительное время не было обращений. По методу FIFO среди всех строк, являющихся объектами замещения, выбирается та, которая самой первой была переслана в кэш-память. И наконец, по последнему методу строка выбирается произвольно. Реализация этих методов упрощается в указанной последовательности, но наибольшим эффектом обладает метод замещения наиболее давнего по использованию объекта (строки).
Для реализации этого метода необходимо манипулировать строками, которые являются объектами замещения, с помощью LRU-стека. При каждой загрузке в этот стек помещается строка, в результате чего при замене используется строка, хранящаяся в наиболее глубокой позиции стека, и эта строка удаляется из стека. При доступе к строке, которая уже содержится в LRU-стеке, эта строка удаляется из стека и заново загружается в него. Стек типа LRU устроен таким образом, что, чем дольше к строке не было доступа, тем в более глубокой позиции она располагается. Реализация стека типа LRU, позволяющего с высокой скоростью выполнять такую операцию, усложняется по мере увеличения числа строк.
По методу частично ассоциативного распределения число строк в каждом стеке LRU равно числу строк в одной группе, и так как это число мало (порядка 2 – 4), то для каждой группы необходимо использовать свой стек. Если число групп сравнительно велико, то оснащение каждой из них стековым механизмом приводит к повышению стоимости.