

2) Статистическое имитационное моделирование
Статистическое имитационное моделирование основывается на генерации случайных величин, имитации функционирования системы и статистической обработке результатов моделирования. Методом моделирования может быть исследована СМО любой степени сложности.
Для проведения моделирования могут использоваться как универсальные языки программирования так и проблемно-ориентированные - GPSS, SIMULA и др.
Параметры функционирования системы оцениваются при моделировании по результатам многократного обслуживания требований (многократных испытаний). При имитации работы системы случайные величины (длительность обслуживания в каналах, интервалы между поступлениями требований, время возврата требований в систему, моменты возникновения отказов каналов и их длительность и др.) получают генерацией по ранее приведенным алгоритмам в зависимости от вида распределения (закон, усечение, смещение).
Число обслуживаний (опытов) необходимо принимать таким, чтобы обеспечить оценку интересующих параметров с заданной точностью при принятой доверительной вероятности.
Таким образом, определение числа опытов производится по аналогии с расчетом размера выборки для исследования случайных величин. При этом это число рекомендуется определять в ходе моделирования на основе оценки точности рассчитываемых параметров.
Алгоритмы моделирования ранее рассмотренных систем массового обслуживания приведены на рисунках 2.18 и 2.19. Число моделируемых обслуживаний определяется на основе формулы для нормального закона распределения, а в качестве интересующего показателя принята средняя продолжительность ожидания требованием начала обслуживания. Отноcительная точность оценивания задана равной с односторонней доверительной вероятностью = 0.95 (квантиль равна 1.645).
Структура алгоритмов следующая:
блок 2– ввод и вывод на принтер исходных данных;
блоки 3-6 – формирование начальных условий моделирования;
блоки 7-10 – поиск канала (источника) с минимальным значением момента времени освобождения от предыдущего обслуживания (прибытия на обслуживание);
блоки 11-18– имитация обслуживания требований и накопление сумм длительностей времени простоев и обслуживания;
блоки 19-21– принятие решения об окончании моделирования или его продолжении;
блок 22 – наращивание номера опыта (испытания);
блоки 23-24 – вычисление средних значений параметров и вывод их на монитор (принтер).
56.Генерация случайных чисел по экспоненциальному закону распределения
Закон рас-пределения |
Получение случайных чисел для базового закона |
Получение случайных чисел для усеченных (xн<x<xв) или сдвинутых распределений (x>xc) |
Экспонен-циальный |
= 1/xм |
Для сдвинутого
с= 1/(xм -xc) |
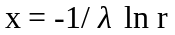
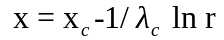
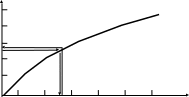
Генерация случайных чисел основана на том, что интегральная функция распределения F(x) ставит в соответствие любому заданному числу х вероятность от 0. до 1. Тогда наоборот некоторому значению F(x), равному, например r , соответствует определенная величина x (рисунок 2.14):
х = F-1(r ),
где F-1 – функция, обратная F.
1.0
F(x)
0.80
0.60 r
0.40
0.20
xr x
Рисунок 2.14 – Графическая интепретация получения случайных чисел по заданному закону распределения
Отсюда следует способ формирования случайных чисел с заданным законом распределения, называемый методом обратных функций. Метод реализуется как по функциональным, так и аппроксимирующим зависимостям. При этом значения r должны быть распределены в интервале 0. – 1. случайно по равномерному закону.
Для нормального закона распределения применяется также метод, основанный на центральной предельной теореме теории вероятностей, согласно которой большое число n независимых случайных чисел с одним и тем же распределением вероятностей дает нормально распределенные числа с математическим ожиданием, равным сумме этих чисел и геометрической суммой среднеквадратических отклонений:
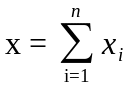 ;
;
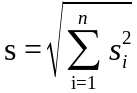 .
.
Формулы для получения случайных чисел по некоторым законам распределения приведены в таблице 2.1.
Псевдослучайные равномерно распределенные числа в интервале 0. – 1.0 можно получать по специальным алгоритмам или применить стандартные функции и подпрограммы языков программирования – RND (Basic), RANDOM (Pascal), RAN, RANDU (Fortran – функция и подпрограмма). Генерируемая последовательность может задаваться с помощью оператора, например RANDOMIZE.
57.Генерация случайных чисел по различным законам распределения
Генерация случайных чисел основана на том, что интегральная функция распределения F(x) ставит в соответствие любому заданному числу х вероятность от 0. до 1. Тогда наоборот некоторому значению F(x), равному, например r , соответствует определенная величина x (рисунок 2.14):
х = F-1(r ),
где F-1 – функция, обратная F.
1.0
F(x)
0.80
0.60 r
0.40
0.20
xr x
Рисунок 2.14 – Графическая интепретация получения случайных чисел по заданному закону распределения
Отсюда следует способ формирования случайных чисел с заданным законом распределения, называемый методом обратных функций. Метод реализуется как по функциональным, так и аппроксимирующим зависимостям. При этом значения r должны быть распределены в интервале 0. – 1. случайно по равномерному закону.
Для нормального закона распределения применяется также метод, основанный на центральной предельной теореме теории вероятностей, согласно которой большое число n независимых случайных чисел с одним и тем же распределением вероятностей дает нормально распределенные числа с математическим ожиданием, равным сумме этих чисел и геометрической суммой среднеквадратических отклонений:
; .
Формулы для получения случайных чисел по некоторым законам распределения приведены в таблице 2.1.
Псевдослучайные равномерно распределенные числа в интервале 0. – 1.0 можно получать по специальным алгоритмам или применить стандартные функции и подпрограммы языков программирования – RND (Basic), RANDOM (Pascal), RAN, RANDU (Fortran – функция и подпрограмма). Генерируемая последовательность может задаваться с помощью оператора, например RANDOMIZE.
58.Вычисление статистических моментов
д) Определить числовые характеристики выборки: начальные k и центральные статистические ck моменты k -го порядка и рассчитываемые через них параметры – оценки математического ожидания xm, выборочной дисперсии s2, среднеквадратического (стандартного) отклонения s, коэффициентов вариации V и сдвинутого (смещенного) распределения Vc, коэффициентов асимметрии A и эксцесса E
;
;
;
1.0
Fэ
0.6
0.4
0.2
Xmin Xmax x
X0 X1 X2 XJ (j=N)
Рисунок 2.11 – График эмпирической функции распределения (пример)
или или ;
;
V= s / xм ;
Vc= s /( xм - xc );
;
.
Поправочные коэффициенты kс, kа и kе служат для получения несмещенной оценки параметров и определяются по формулам:
kс = n / (n-1);
kа = n2 / ( n 2 - 3 n + 2 );
kе ≈ 1.
59.Вычисление основных характеристик эмпирического распределения случайной величины
Одним из возможных алгоритмов расчета характеристик эмпирического распределения непрерывной случайной величины является следующий:
а) по результатам наблюдения (замеров) необходимо получить заданное число n значений исследуемого параметра для процесса, явления, предмета;
б) составить интервальные статистические ряды распределения частот и частостей полученных значений случайной величины:
1) найти в выборке минимальное Хмin и максимальное Хмах значения случайной величины и размах варьирования Хр=Хмах-Хмin;
2) определить число интервалов N разбиения случайной величины
Nп = 1 + int(3.32 lg n);
N= max (Nп; 5),
где n – размер выборки случайной величины;
3) рассчитать длину интервала h
h = Хр / N ;
4) определить границы Хj (верхнюю), Хj-1 (нижнюю) и середину Хсj каждого j-го интервала распределения случайной величины ( )
Xj = Xмin + j h ; Xj-1 = Xмin + (j-1) h;
Xсj = (Xj-1 + Xj)/2 .
5) подсчитать число попаданий случайной величины в каждый j-й интервал (частоты Мj), для чего пересмотреть все числа xi ( ) относительно границ интервалов
Мj
= М
j +
1 , если X
j-1
xi
< X j
при
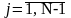 ;
;
Мj = М j + 1 , если X j-1 xi X j при j = N;
6) определить частости (эмпирические вероятности) pэj попадания значений случайной величины в каждый из интервалов путем деления соответствующих частот на объем выборки n, т.е. pэj = Мj / n. Сумма всех частот равна объему выборки
,
а сумма частостей pэj соответственно равна единице.
7) представить интервальные статистические ряды в виде массивов
Номер интервала, j |
1 |
2 |
|
N |
Нижняя граница Xj-1 |
X0 |
X1 |
|
XN-1 |
Верхняя граница Xj |
X1 |
X2 |
|
XN |
Середина интервала Xсj |
Xс1 |
Xс2 |
|
XcN |
Частоты Mj |
M1 |
M2 |
|
MN |
Частости pэj |
pэ1 |
pэ2 |
|
pэN |
в) Построить гистограмму или полигон эмпирического распределения
Для построения гистограммы по оси х откладывают границы интервалов значений случайной величины и для каждого из интервалов строится прямоугольник, высота которого равна частному от деления частости данного интервала на величину интервала: fэj= pэj/h, где fэj – эмпирическая функция плотности вероятности. Полигон строится также по значениям fэj, но на серединах интервалов в виде ломаной линии (рисунок 2.10).
1
0.25
fэj
0.15
0.10 2
0.05
Xмin Xmax х
X0 X1 X2 Xj (j=N)
Рисунок 2.10 – Гистограмма (1) и полигон (2) эмпирического распределения (пример)
г) определить значения эмпирической функции распределения и построить ее график
(рисунок 2.11). При этом ( j=0).
д) Определить числовые характеристики выборки: начальные k и центральные статистические ck моменты k -го порядка и рассчитываемые через них параметры – оценки математического ожидания xm, выборочной дисперсии s2, среднеквадратического (стандартного) отклонения s, коэффициентов вариации V и сдвинутого (смещенного) распределения Vc, коэффициентов асимметрии A и эксцесса E
;
;
;
1.0
Fэ
0.6
0.4
0.2
Xmin Xmax x
X0 X1 X2 XJ (j=N)
Рисунок 2.11 – График эмпирической функции распределения (пример)
или
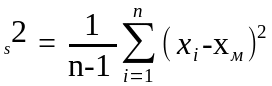 или
;
или
;
;
V= s / xм ;
Vc= s /( xм - xc );
;
.
Поправочные коэффициенты kс, kа и kе служат для получения несмещенной оценки параметров и определяются по формулам:
kс = n / (n-1);
kа = n2 / ( n 2 - 3 n + 2 );
kе ≈ 1.
60.Оценивание коэффициентов временного ряда Фурье
Временные ряды с периодическими изменениями наиболее часто описываются рядом Фурье. Таким периодическим изменениям подвержены многие физические и экономические явления, связанные с сезонной, недельной, суточной и другой изменчивостью. Например, имеется такая изменчивость по дням недели для транспортной подвижности населения и нет зависимости от дня недели для температуры воздуха. Выражения, связывающие фактор (время) и зависимую переменную, имеют следующий вид:
 или
или
,
где y тi – значение теоретической функции в i-й расчетной точке;
aо – свободный член уравнения;
n – верхнее значение номера гармоники ряда Фурье;
k – номер гармоники;
ak , bk – коэффициенты ряда Фурье при k-й гармонике соответственно при cos и sin;
t i – значение фактора (времени) в i-й расчетной точке;
T – интервал времени, за который рассматривается временной ряд;
m – общее число чисел во временном ряду.
Вторая формула может применяться только для случая, когда показатели зафиксированы через равные интервалы времени, а первая – в любом случае.
Параметры (коэффициенты) уравнений определяются соответственно по следующим зависимостям:
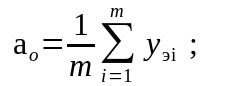
или
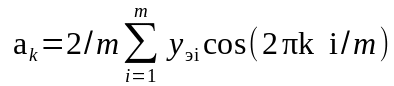 ;
;
или
,
где yэi – экспериментальные значения зависимой переменной в i-х расчетных точках.
Проверка адекватности полученного уравнения (многочлена ряда Фурье) экспериментальным данным производится по критерию Фишера и средней линейной ошибке аппроксимации. При этом при расчете числа степеней свободы под числом факторов понимается число использованных гармоник ряда Фурье.
При проведении расчетов номера гармоник, включаемые в уравнение, рекомендуется принимать адаптивно по максимуму значения статистики критерия Фишера F или минимуму средней линейной ошибки аппроксимации E. Гармоники, которые вызывают уменьшение значения F или увеличение значения E, не включаются в модель связи. При этом верхнее значение номера гармоник не должно быть больше чем m/2.
Компьютерная программа выравнивания динамических рядов с помощью многочлена ряда Фурье приведена в приложении 6.
61.Шаговые методы одномерной безусловной оптимизации
Среди численных находят применение следующие методы: дихотомии, золотого сечения, Фибоначчи, шаговые и аппроксимации кривыми.
Шаговые методы основаны на том, что текущему приближению к решению xп на каждом новом шаге дается приращение h как xп=xп+h и вычисляется f(xп). Если новое значение целевой функции "лучше" предыдущего, то переменной x дается новое приращение. Если функция "ухудшилась", то поиск в данном направлении завершен.
Имеется ряд разновидностей шагового метода поиска экстремума целевых функций (прямой поиск, поразрядного приближения, Зейделя и др.).
Графическая интепретация и алгоритм поиска экстремума функции на основе поразрядного приближения приведены на рисунках 3.6, 3.7.
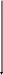 f(x)
f(x)

 f(xп+h)
f(xп+h)
f(xп) На минимум
xп xп+h x
Рисунок 3.6 – Графическая интепретация метода поразрядного приближения
62.Представление постановки транспортной задачи линейного программирования в табличной форме