

Лекция 9-10-11-12 Удаление невидимых линий и поверхностей
З адача
состоит в том, чтобы определить, какие
части объектов, спроектированных на
картинную плоскость (экран), будут видны,
а какие – заслонены другими объектами.
Методы различаются по следующим
параметрам:
адача
состоит в том, чтобы определить, какие
части объектов, спроектированных на
картинную плоскость (экран), будут видны,
а какие – заслонены другими объектами.
Методы различаются по следующим
параметрам:
-
Способу представления объектов (Brep, CSG)
-
Способу визуализации сцены (каркасное или сплошное)
-
Пространству, в котором проводится анализ видимости (объектное или картинная плоскость)
-
Виду получаемого результата (непрерывный (участки ребер) или дискретный (пиксели))
Самый простой непрерывный метод удаления невидимых линий это перебор ребер всех объектов и сравнение их со всеми остальными объектами, такой алгоритм требует времени O(N2). Дискретные методы требуют времени O(CN), С – кол-во пикселей на экране (300 000).
Важную роль для эффективной работы алгоритмов удаления невидимых линий играет когерентность (англ. coherence – связность). Принцип состоит в том, что соседние объекты скорее всего имеют одинаковое состояние.
-
Когерентность в картинной плоскости, если данный пиксель соответствует определенной грани, то и соседние пиксели скорее всего соответствуют этой грани.
-
Когерентность в объектном пространстве, если данный объект виден (невиден), то и соседние, скорее всего, видны (невидны).
-
Когерентность во времени, если данный объект виден (невиден) на текущем кадре, то и на следующем кадре он, скорее всего, будет виден (невиден).
Алгоритм плавающего горизонта

Этот алгоритм применяют для удаления невидимых линий в параллельных проекциях графика функции двух переменных. Функция задана в виде Z=F(X,Y). Это может быть как аналитически заданная функция, так и любая другая (например, задана карта высот для некоторых точек, а промежуточные значения – получаются линейной интерполяцией).

Самый простой алгоритм рисования графика – выбрать некоторый шаг сетки вдоль осей X и Y, рассчитать точки для узлов такой сетки, и вывести их на экран. При этом, чтобы не было разрывов, можно выводить не точки, а отрезки между соседними узлами сетки. Можно заметить, что все отрезки в одном ряде узлов сетки вдоль оси OX будут лежать в одной вертикальной плоскости. Плоскости всех таких рядов будут параллельны, а значит, отрезок из более дальней от наблюдателя плоскости никогда не загородит отрезок из более близкой.
На этом принципе и построен алгоритм плавающего горизонта. Отрезки выводятся в направлении от ближних к дальним, с проверкой, не загорожены ли они уже выведенными отрезками. Для проверки используются два массива нижнего и верхнего горизонтов, это целочисленные массивы их размерность – количество пикселей в строке картинки. При растеризации отрезков первого ряда в эти массивы просто заносятся Y-координаты пикселей этих ребер. Для остальных рядов - Y-координата сравнивается с горизонтами, если она находится между ними, значит она невидна, если же она выше верхнего горизонта или ниже нижнего – она выводится, а соответствующий горизонт модифицируется.
Алгоритм работает в картинной плоскости и является дискретным.
Алгоритм можно использовать и для отрезков, соединяющих узлы соседних рядов. При этом, сначала выводятся отрезки текущего ряда, затем, отрезки, соединяющие этот ряд со следующим, а затем тоже самое делается для следующих рядов. Подобным образом можно изобразить и сплошную поверхность, растеризуя не отрезки, а треугольники.
Нужно уметь выбирать правильное направление рисования, для этого, обычно определяют знак проекции ортов системы координат на направление проектирования (вглубь экрана).
Void PP(x,y) { if (y<MinHor[x]) MinHor[x]=y; else
if (y>MaxHor[x]) MaxHor [x]=y; else return; ... }
Пирамида зрения
П режде,
чем удалять загороженные линии и пов-ти,
следует сначала отбросить все объекты,
не попадающие на экран. Это можно сделать
в пространстве картинной плоскости,
отсекая спроектированные объекты
границами окна. А можно, отсекать их в
объектном пространстве по пирамиде
зрения. Плоскости пирамиды зрения
строятся на точке схода и ребрах окна.
Как правило, к пирамиде зрения добавляют
еще пару плоскостей – дальнюю и ближнюю,
они перпендикулярны направлению зрения
и определяют границы видимости. Для
параллельных проекций – будет призма
зрения. Строится на ребрах и направлении
зрения.
режде,
чем удалять загороженные линии и пов-ти,
следует сначала отбросить все объекты,
не попадающие на экран. Это можно сделать
в пространстве картинной плоскости,
отсекая спроектированные объекты
границами окна. А можно, отсекать их в
объектном пространстве по пирамиде
зрения. Плоскости пирамиды зрения
строятся на точке схода и ребрах окна.
Как правило, к пирамиде зрения добавляют
еще пару плоскостей – дальнюю и ближнюю,
они перпендикулярны направлению зрения
и определяют границы видимости. Для
параллельных проекций – будет призма
зрения. Строится на ребрах и направлении
зрения.
Удаление нелицевых граней
Если
поверхность задана гранями, то, очевидно,
что грани, нормали которых составляют
с направлением проектирования острый
угол, будут отвернуты от наблюдателя
и, следовательно, невидны. Такие грани
называются нелицевыми. Нормали лицевых
граней направлена на наблюдателя. При
параллельном проектировании для
нелицевых граней
![]() ,
где N
– нормаль, L
- направление проектирования (вглубь
экрана). При перспективном проектировании
для нелицевых граней
,
где N
– нормаль, L
- направление проектирования (вглубь
экрана). При перспективном проектировании
для нелицевых граней
![]() ,
где N,D
– параметры плоскости, V
– точка схода (положение наблюдателя).
Для треугольников в экранном пространстве
нелицевые грани можно определить по
знаку pdp
двух его ребер
,
где N,D
– параметры плоскости, V
– точка схода (положение наблюдателя).
Для треугольников в экранном пространстве
нелицевые грани можно определить по
знаку pdp
двух его ребер
![]() .
Если требуется вывести каркасную модель,
то будут невидны те ребра, которые
принадлежат только нелицевым граням.
Удаление нелицевых граней решает задачу
удаления невидимых линий полностью
только когда требуется вывести один
выпуклый полиэдр. В остальных случаях
это лишь дополнительное средство,
которое, тем не менее, позволяет в среднем
в два раза сократить количество
обрабатываемых граней.
.
Если требуется вывести каркасную модель,
то будут невидны те ребра, которые
принадлежат только нелицевым граням.
Удаление нелицевых граней решает задачу
удаления невидимых линий полностью
только когда требуется вывести один
выпуклый полиэдр. В остальных случаях
это лишь дополнительное средство,
которое, тем не менее, позволяет в среднем
в два раза сократить количество
обрабатываемых граней.
Алгоритм Робертса
Это алгоритм типичный пример решения задачи в лоб, методом грубой силы. После отбрасывания нелицевых граней и ребер, рассматривается положение всех ребер по отношению ко всем граням в картинной плоскости. Это могут быть следующие случаи:
-
Грань не закрывает ребро (либо их проекции не пересекаются, либо ребро находится ближе чем грань);
-
Грань полностью закрывает ребро – ребро удаляется из списка видимых ребер;
-
Грань частично закрывает ребро (либо ребро лежит под гранью, но не полностью, либо пересекает ее) – ребро разбивается на несколько частей, и они заносятся вместо него в список ребер;

Такой алгоритм требует O(N2) времени. Его можно немного ускорить, если описать вокруг граней некоторые ограничивающие тела (обычно это либо параллелепипеды (в картинной плоскости– прямоугольники), с ребрами параллельными осям координат, AABB (Axis Aligned Bounding Box), либо сферы (в картинной плоскости – окружности)). Тогда достаточно сначала проверить пересечение этих тел, и только если они пересекаются, проверять пересечение ребра с гранью. Можно ограничивать не только отдельные ребра или грани, но и их группы (например, объекты), и проверять сначала пересечение тел для групп, и только если они пересекаются – для отдельных объектов. Таким образом, можно построить целую иерархию ограничивающих тел.
Алгоритм Аппеля
Алгоритм использует понятие количественной невидимости точки – количество лицевых граней, закрывающих данную точку. Очевидно, что видны будут только те точки, для которых количественная невидимость равна нулю. Для полигональных поверхностей, количественная невидимость изменяется только на контурных линиях проекций этих поверхностей на экран. Это верно только для непересекающихся поверхностей. Контурная линия поверхности образуется ребрами, для которых одна грань лицевая, а другая нелицевая (либо ее просто нет). Для определения видимости ребер некоторой поверхности сначала непосредственно определяется количественная невидимость одной из ее вершин, далее прослеживается изменение количественной невидимости вдоль ребер, выходящих из этой точки. Она изменяется на единицу при прохождении ребра за линией контура. Во входящих точках – увеличивается, в выходящих – уменьшается (для этого контур должен быть направленным). Части ребер с нулевой количественной невидимостью сразу рисуются. Операция повторяется для вершин на концах этих ребер (для них количественная невидимость уже определена) пока не будут проверены все вершины и ребра поверхности.
Алгоритм Варнака
Э тот
алгоритм работает в картинной плоскости.
Сначала определяются все объекты,
лежащие в окне. Если оказывается, что
объектов в окне нет, то не рисуют ничего,
если в окне один объект – рисуют только
его, если же несколько – ищут ближайший
из них, если такой есть – выводят, если
нет – разбивают окно на четыре части и
дальше работают с этими частями. Окно
делят до тех пор, пока оно не станет
равным пикселю, тогда просто выбирают
один из наиболее близких объектов.
тот
алгоритм работает в картинной плоскости.
Сначала определяются все объекты,
лежащие в окне. Если оказывается, что
объектов в окне нет, то не рисуют ничего,
если в окне один объект – рисуют только
его, если же несколько – ищут ближайший
из них, если такой есть – выводят, если
нет – разбивают окно на четыре части и
дальше работают с этими частями. Окно
делят до тех пор, пока оно не станет
равным пикселю, тогда просто выбирают
один из наиболее близких объектов.
Такой алгоритм подходит как для каркасных, так и для сплошных изображений.
А лгоритм
Художника
лгоритм
Художника
Это еще один пример метода грубой силы. Полигоны просто сортируются и выводятся в порядке от дальних к ближним. Таким образом, ближайшие к наблюдателю полигоны рисуются поверх дальних и получается правильная картина. Такой алгоритм подходит только для отображения сплошных поверхностей, не для каркасных. Сортировка полигонов тоже вещь нетривиальная. Если сортировать вдоль оси Z, то всегда может быть случай неправильной сортировки. Или вообще ее невозможности. Тем не менее, алгоритм достаточно прост и часто используется при небольшом количествах полигонов, одним из его достоинств является возможность обрабатывать полупрозрачные объекты. Предыдущие алгоритмы требуют значительной модификации для такой возможности. Полупрозрачный объект выводится по формуле С=С*t+Cг*(1-t), где С – текущий цвет пикселя, Cг – цвет пикселя прозрачной грани, t – коэффициент прозрачности [0..1]. Очевидно, что для формирования правильной картинки необходимо знать цвет предыдущего пикселя.
И спользование
бинарного разбиения пространства для
сортировки полигонов
спользование
бинарного разбиения пространства для
сортировки полигонов
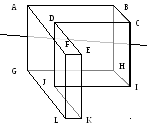
Е сли
в наборе полигонов выбрать одну, то ее
плоскость разбивает все пространство
на две части. Предположим, что эта
плоскость не пересекает остальные
полигоны, значит, одна часть полигонов
будет лежать с одной стороны от плоскости,
а другая – с другой. Тогда, в зависимости,
от того, с какой стороны от плоскости
находится наблюдатель, можно однозначно
определить порядок отрисовки этих групп
полигонов. Сначала рисуются полигоны
из полупространства, в котором нет
наблюдателя, затем полигон с плоскости,
и наконец – полигоны из полупространства,
в котором находится наблюдатель
((B,C),A,(D,E,F)).
Чтобы правильно отсортировать все
полигоны – нужно построить дерево таких
разбиений. Такое дерево и называется
деревом двоичного разбиения пространства
(BSP-tree
binary
space
partitioning
tree).
сли
в наборе полигонов выбрать одну, то ее
плоскость разбивает все пространство
на две части. Предположим, что эта
плоскость не пересекает остальные
полигоны, значит, одна часть полигонов
будет лежать с одной стороны от плоскости,
а другая – с другой. Тогда, в зависимости,
от того, с какой стороны от плоскости
находится наблюдатель, можно однозначно
определить порядок отрисовки этих групп
полигонов. Сначала рисуются полигоны
из полупространства, в котором нет
наблюдателя, затем полигон с плоскости,
и наконец – полигоны из полупространства,
в котором находится наблюдатель
((B,C),A,(D,E,F)).
Чтобы правильно отсортировать все
полигоны – нужно построить дерево таких
разбиений. Такое дерево и называется
деревом двоичного разбиения пространства
(BSP-tree
binary
space
partitioning
tree).
В качестве узлов такого дерева выступают плоскости (и полигоны лежащие на них), а в качестве листьев – области, ограниченные этими плоскостями. Для отрисовки дерева его просто обходят, определяя каждый раз положение наблюдателя относительно плоскостей узлов. (B,C,A,F,D,E).
Для общих случаев, в одной плоскости могут лежать несколько полигонов (порядок их вывода не имеет значения), плоскости могут пересекать полигоны, тогда такие полигоны режут на две части и каждую добавляют в свое полупространство. При построении дерева стараются, чтобы разница в количестве узлов слева и справа от текущего было минимальной и разрезанных полигонов было как можно меньше. Тогда оно будет сбалансированным, при этом глубина дерева будет минимальной, это обеспечивает минимум проверок плоскостей. Идеальное решение этой задачи требует слишком много времени, поэтому очередная разбивающая плоскость выбирается по максимуму весовой функции f=lie-a*|left-right|-b*cross, где lie – кол-во полигонов лежащих в плоскости, left,right - кол-во полигонов слева и справа от плоскости, cross - кол-во полигонов, которые пересекаются плоскостью, a,b – какие-то весовые коэффициенты.
Трассировка лучей
А лгоритм
состоит в том, что для каждого пиксела
в экране определяется ближайшая грань.
Для этого проверяется пересечение
проектирующей прямой, проходящей центр
пикселя, с гранями всех объектов в сцене
и находится ближайшая. Алгоритм достаточно
универсален, может работать как с
объектами, заданными поверхностями,
так и с конструктивной геометрией. Он
позволяет эффективно обрабатывать
полупрозрачные полигоны. В общем случае,
алгоритм требует O(CN)
времени, но если применить некоторые
оптимизации, вроде иерархии описанных
вокруг объектов тел или BSP
можно свести время выполнения к O(ClogN),
что означает практическую независимость
от сложности сцены. Для этого алгоритма
можно очень эффективно использовать
когерентность, например, если найдено
пересечение прямой для текущего пикселя
с некоторой гранью, то прямая для
соседнего тоже скорее всего пересечется
с этой гранью. Значит, можно сначала
проверить пересечение с этой гранью, и
если оно имеет место, проверять не весь
отрезок, а только его часть от наблюдателя
до точки этого пересечения. Можно
построить иерархию описывающих тел, и
проверять пересечение луча сначала с
ними, а затем с объектами. Наконец, можно
использовать и когерентность по времени,
хранить указатели на грани для каждого
пиксела, и сначала проверять пересечение
с ними, только это требует достаточно
много памяти.
лгоритм
состоит в том, что для каждого пиксела
в экране определяется ближайшая грань.
Для этого проверяется пересечение
проектирующей прямой, проходящей центр
пикселя, с гранями всех объектов в сцене
и находится ближайшая. Алгоритм достаточно
универсален, может работать как с
объектами, заданными поверхностями,
так и с конструктивной геометрией. Он
позволяет эффективно обрабатывать
полупрозрачные полигоны. В общем случае,
алгоритм требует O(CN)
времени, но если применить некоторые
оптимизации, вроде иерархии описанных
вокруг объектов тел или BSP
можно свести время выполнения к O(ClogN),
что означает практическую независимость
от сложности сцены. Для этого алгоритма
можно очень эффективно использовать
когерентность, например, если найдено
пересечение прямой для текущего пикселя
с некоторой гранью, то прямая для
соседнего тоже скорее всего пересечется
с этой гранью. Значит, можно сначала
проверить пересечение с этой гранью, и
если оно имеет место, проверять не весь
отрезок, а только его часть от наблюдателя
до точки этого пересечения. Можно
построить иерархию описывающих тел, и
проверять пересечение луча сначала с
ними, а затем с объектами. Наконец, можно
использовать и когерентность по времени,
хранить указатели на грани для каждого
пиксела, и сначала проверять пересечение
с ними, только это требует достаточно
много памяти.
Алгоритм Z-буфера
Как и предыдущий, алгоритм ищет ближайшую грань для каждого пиксела. Только делает это несколько иначе. Заводится двумерный массив, каждый элемент которого соответствует одному пикселу. Этот массив и называется Z-буфером (или буфером глубины). Сначала в него заносят максимальную глубину. Затем отрисовывают все грани сцены. При рисовании очередного пиксела грани, ели значение глубины этого пиксела меньше, чем значение в Z-буфере, то пиксел рисуется, и значение его глубины заносится в Z-буфер.
void PPZB(x,y,z){ if (z<ZBuffer[y][x]) { ZBuffer[y][x]=z; PP(x,y); } }
К ак
правило, расчет глубины осуществляется
при растеризации очередной грани, т.о.
этот алгоритм удаления невидимых
поверхностей, практически не требует
дополнительных вычислений и выполняется
за время O(N).
Из-за своей простоты, он хорошо подходит
для реализации на графических
акселераторах. Тем не менее, алгоритм
требует растеризовать все грани в сцене,
тогда, как большинство из них могут быть
полностью невидимыми, поэтому, как
правило, в дополнение к нему используют
какие-то дополнительные алгоритмы
отброса заведомо невидимых объектов и
граней. Кроме того, здесь тоже можно
использовать когерентность. Например,
если построить вокруг группы граней
AABB
и проверить по Z-буферу,
виден ли он (проверить, все соответствующие
ему пикселы, не занося значения в
Z-буфер).
Если он невиден, то и грани внутри него
не видны.
ак
правило, расчет глубины осуществляется
при растеризации очередной грани, т.о.
этот алгоритм удаления невидимых
поверхностей, практически не требует
дополнительных вычислений и выполняется
за время O(N).
Из-за своей простоты, он хорошо подходит
для реализации на графических
акселераторах. Тем не менее, алгоритм
требует растеризовать все грани в сцене,
тогда, как большинство из них могут быть
полностью невидимыми, поэтому, как
правило, в дополнение к нему используют
какие-то дополнительные алгоритмы
отброса заведомо невидимых объектов и
граней. Кроме того, здесь тоже можно
использовать когерентность. Например,
если построить вокруг группы граней
AABB
и проверить по Z-буферу,
виден ли он (проверить, все соответствующие
ему пикселы, не занося значения в
Z-буфер).
Если он невиден, то и грани внутри него
не видны.
Опять же лучше построить иерархию описывающих тел. Например, описать вокруг всех граней в сцене AABB, затем рекурсивно разбивать его на 8 частей, до тех пор, пока в количество полигонов в текущем AABB не станет достаточно малым, чтобы дальнейшее деление не имело смысла. Получится дерево, узлы – AABB, листья – AABB со списком полигонов в них. Далее, берется начальный AABB дерева (корневой), проверяется на попадание в пирамиду зрения, затем проверяется по Z-буферу, если оказывается, что он виден – тоже самое проделывается для каждого из восьми дочерних AABB. В конце концов, выводятся полигоны в листьях дерева. Важным является порядок обхода дочерних AABB, сначала выводятся ближайшие к наблюдателю, а затем более дальние. Порядок определяется положением наблюдателя относительно плоскостей, разделяющих родительский AABB на дочерние (как в BSP). Выгода от рисования от ближних к дальним в том, что отрисованные ближние грани будут закрывать дальние.
Это было использование когерентности в объектном пространстве, можно использовать и когерентность в картинной плоскости, то, что для соседних пикселов значение глубины отличается несильно. Для этого применяют иерархический Z-буфер. Кроме основного массива, создают его уменьшенный вариант, объединяя четверки соседних пикселей 2х2 в один. Значение глубины для уменьшенного Z-буфера выбирается максимальная. Таким образом формируется набор все меньших Z-буферов вплоть до массива с одним элементом, глубина в нем будет соответствовать максимальной глубине в сцене. Получается своего рода пирамида Z-буферов.
При проверке AABB сначала проверяется самый маленький Z-буфер в иерархии, затем, побольше и т.д. до начального. Таким образом, значительно сокращается количество проверяемых ячеек Z-буфера. Если объект полностью заслоняется, то на некотором уровне пирамиды окажется, что все его пиксели дальше, чем значения Z-буфера на этом уровне. Если объект ближе, то быстро найдутся пикселы, находящиеся внутри объекта, у которых глубина дальше, чем у объекта.
Наконец, когерентность по времени можно использовать, используя то, что чем раньше видимая грань будет выведена, тем больше она заслонит. Для этого заводится список граней, видимых на данном кадре. И на следующем кадре можно сначала вывести их, а затем уже, все остальные.
Для алгоритма Z-буфера можно использовать совершенно различные параметры, характеризующие глубину. Обычно используются либо координата Z (проекция точки на ось вглубь экрана OZ), либо обратная ей величина 1/Z. Обратную величину можно линейно интерполировать вдоль экрана при перспективном проектировании. Более подробно об этом будет рассказано в лекции, посвященной закрашиванию и наложению текстур. Чтобы сохранить увеличение значения в Z-буфере с увеличением расстояния до объекта, используют величину 1-k/Z.
Из-за того, что размер и точность чисел ограничен, необходимо наложить некоторые условия на глубину. Обычно, глубина хранится в виде целого числа, принимающего значения [0..ZBmax]. Тогда, если глубна характеризуется Z- координатой, значение для Z-буфера рассчитывается по формуле V(Z)=Z/Zmax* ZBmax. Цена младшего разряда (дискретность) d для числа V будет Zmax/ZBmax (500/65536~0.01). Для обратной величины V(Z)=(1-k/Z)* ZBmax. Здесь k вычисляется исходя из Zmin. ZV=0 => k=Zmin. Цена младшего разряда не постоянна V(Z+d)-V(Z)=1 => d=Z*Z/(k*ZBmax-Z) = Z*Z/(Zmin*ZBmax-Z) . С увеличением Z цена возрастает, и максимальная цена будет в Zmax (500*500/(0.1*65535-500)=41), а минимальная в Zmin (d=Zmin/(ZBmax-1))=0.1/65536=1e-6), это значит, что последние объекты в последних 40 метрах будут иметь одинаковое значение глубины. Чтобы избежать этого выбирают меньшие Zmax и большие Zmin(100,1=>0.15). Либо увеличение разрядной сетки (до 24-х или 32-х разрядов (500,0.1,24 => 500*500/0.1*16000000=0.15)).
В общем случае алгоритм Z-буфера не позволяет работать с полупрозрачными объектами. Обычно их выводят после вывода непрозрачных, в порядке от дальних к ближним, проверяя Z-буфер. Но можно несколько модифицировать и сам алгоритм, для этого в каждом пикселе добавляется упорядоченный по глубине список прозрачных пикселей. Если в обычном Z-буфере каждому пикселу соответствует пара (С,Z), где C-цвет, Z-глубина, то в модифицированном - (С,Z,t,next), где t-степень прозрачности, next – указатель на следующий элемент в списке. Сначала строится Z-буфер, а затем рисуются все пиксели со списками от дальнего элемента к ближнему.
К достоинствам алгоритма можно отнести исключительную простоту и минимальные затраты времени, к недостаткам – необходимость растеризовать все грани (даже невидимые) и ошибки дискретизации.
Кроме того, к недостаткам можно отнести и большие затраты памяти, хотя с сейчас это не так актуально, как раньше. Тем не менее, существует способ избежать этих затрат, можно разбить изображение на небольшие участки, определить какие грани попадают в каждый участок и растеризовать эти участки отдельно. Для каждого из них будет размер Z-буфера будет небольшим. При этом дополнительно тратится время на определение попадания грани в участок и память для хранения списка этих граней для каждого участка. Если участки представляют собой прямоугольники – такая технология называется тайловой (tile – черепица, плитка), если эти участки – строки пикселей, то – технологией построчного сканирования.
Методы построчного сканирования
Построчное сканирование хорошо согласуется с растеризацией примитивов по спанам, и требует минимального дополнительного времени и памяти. При этом, каждой строке пикселов соответствует сечение сцены плоскостью, проходящей через эту строку. Таким образом, задача сводится к набору плоских задач удаления невидимых отрезков для каждой строки.
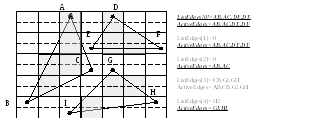
Определить, какие грани попадают в строку i очень просто, достаточно определить, попадает ли Y-координата центров пикселей этой строки в интервал между минимальной и максимальной Y-координатами точек грани Ymin<= i+0.5 <Ymax. Можно поступить следующим образом, при растеризации очередной грани, вместо того, чтобы рисовать спан его заносят в список спанов соответствующей ему строки (ListSpans[i]). Но это требует больших затрат по памяти (нужно хранить все спаны всех граней). Можно работать более эффективно, если воспользоваться когерентностью в картинной плоскости. Достаточно занести каждую грань в списки тех строк, в которые попадает ее первый спан (ListFaces[i]). Строки выводятся последовательно сверху вниз, существует список активных граней ActiveFaces. При переходе на очередную строку i из этого списка выбрасываются все грани, которые заканчиваются в этой строке (Ymax < i+0.5) и заносятся все грани из списка начинающихся в этой строке ListFaces[i]. Затем рассчитываются спаны для всех граней из ActiveFaces. В каждой грани нужно хранить все параметры для формирования следующего спана (s1,s2,k1,k2 и т.д.).
Наконец, можно хранить списки не граней а ребер. Есть списки начинающихся ребер ListEdges[i] и список активных ребер ActiveEdges. Очевидно, что ребра каждой грани можно разделить на три группы: левые, правые и горизонтальные. Горизонтальные ребра – не пересекают горизонтальных прямых, проходящих через центры пикселов и отбрасываются. Левые ребра ограничивают грань слева, правые – справа. Для каждой строки грань ограничена ровно двумя ребрами – левым и правым. Поэтому для получения спана нужно лишь знать эту пару, для этого в ребро заносят указатели на грань, а в грани – два указателя на активные ребра.
При переходе на очередную строку i из списка ActiveEdges выбрасываются все ребра, которые заканчиваются в этой строке (Ymax < i+0.5) и заносятся все ребра из списка начинающихся в этой строке ListEdges[i]. Указатели на закончившиеся ребра удаляются из соответствующих полей граней, которым они соответствуют, а указатели на начинающиеся ребра наоборот заносятся в эти поля. Затем рассчитываются спаны для всех граней, которым соответствуют ребра из ActiveEdges. При этом, пары ребер можно определить либо выбирая из списка только левые (это определяется при расчете ребер) и строя спаны от них до соответствующих правых ребер. Либо отсортировать активные ребра по возрастанию x, тогда первое встреченное ребро будет левым, для него следует выбрать правое, и пометить, его, чтобы не выбрать снова.
struct Edge { Face *face; float x,dx; int Ymax; Edge *next,*prev; };
struct Face { Edge *active_edges[2]; };

Одномерный Z-буфер
Это тоже самое, что и обычный Z-буфер, только для одной строки. OZ-буфер – это одномерный массив глубины для пикселов строки. Перед рисованием очередной строки его нужно очистить, занеся максимальное значение глубины. Также вычисляется глубина для каждого пиксела, сравнивается со значением в OZ-буфере и заносится, если пиксел находится ближе.
void PPOZB(x,y,z){ if (z<OZBuffer[x]) { OZBuffer[x]=z; PP(x,y); } }
Здесь можно использовать когерентность как и в Z-буфере (описанные тела, восьмеричные деревья, пирамидальную иерархию OZ-буферов, сохранение списка видимых на данном кадре граней), плюс когерентность между соседними строками, например запоминать видимые на текущей строке грани и выводить их первыми на следующей.
Список видимых спанов (S-буфер)
Это аналог алгоритма Робертса. Спаны последовательно заносятся в список видимых спанов, в этом списке хранятся только видимые части спанов. При занесении, новый спан поочередно сравнивается с уже существующими, здесь может быть несколько случаев.
-
проекции спанов на строку не пересекаются;
-
спан полностью закрыт другим спаном – он игнорируется;
-
спан частично закрыт другим спаном – он отсекается;
-
два спана пересекаются – они оба отсекаются;

Здесь тоже можно использовать когерентность, например, заносить видимые спаны (на предыдущей строке, кадре) раньше невидимых.
Сортировка ребер
Это аналог алгоритма Аппеля. Список активных ребер сортируется вдоль оси х. Он просматривается слева направо, при встрече левого ребра спан заносится в список активных спанов ActiveSpans, а при встрече правого – удаляется. Таким образом, в списке активных спанов находятся все спаны, закрывающие точку в данный момент, они отсортированы по глубине. В начале этого списка находится ближайший к наблюдателю (видимый) спан, для него количественная невидимость равна нулю, для остальных – она равно положению в списке. Если задать условие, что объекты не пересекаются, то список изменяется только на ребрах, принадлежащих контуру. При добавлении спана в список достаточно определить глубину его начала относительно спанов в списке и вставить его в нужное место. При удалении спана – он просто удаляется из списка. Если пересекается ребро, не принадлежащее контуру, то новый спан просто заносится на место предыдущего.
0:
A :AC
:AC
B:AC,BD
C:CG,BD
D:CG,DF
E:EI,CG,DF
F:EI,CG,FH
G:EI,FH
H:EI
I:
А лгоритм
можно значительно ускорить, если не
заносить в список ребер не принадлежащие
контурам ребра, эти ребра можно получать
из текущего спана, его правое ребро
одновременно является левым для
следующего. Кроме того, нет необходимости
сортировать ребра каждый раз, можно
использовать отсортированный список
с предыдущей строки. При добавлении
ребра в список активных нужно вставлять
его сразу на правильное место. А при
изменении координаты x
ребра следить за сохранением порядка
и, при необходимости, переставлять
ребро.
лгоритм
можно значительно ускорить, если не
заносить в список ребер не принадлежащие
контурам ребра, эти ребра можно получать
из текущего спана, его правое ребро
одновременно является левым для
следующего. Кроме того, нет необходимости
сортировать ребра каждый раз, можно
использовать отсортированный список
с предыдущей строки. При добавлении
ребра в список активных нужно вставлять
его сразу на правильное место. А при
изменении координаты x
ребра следить за сохранением порядка
и, при необходимости, переставлять
ребро.
Этот алгоритм позволяет выводить и полупрозрачные полигоны.
Метод потенциально видимых множеств PVS (Potentially Visible Set)
Д ля
многих сцен, особенно для закрытых
помещений, количество видимых на экране
объектов значительно меньше общего
количества объектов в сцене. Для быстрого
отсеивания большей части невидимых
объектов в статических, неизменных,
сценах и применяется этот метод.
Пространство сцены разбивается на
выпуклые объемы, например комнаты. Для
каждого объема определяется, какие
объекты могут быть видимы хотя бы из
одной точки этого объема. При отображении
сцены определяется объем, в котором
находится наблюдатель, а затем выводятся
все объекты, которые он может увидеть.
Основным недостатком PVS
является потребность в больших объемах
памяти, ведь для каждого объема нужно
хранить карту всех, видимых из него,
объектов. Как правило, хранят не карту
видимых объектов, а карту видимых
объемов, это добавляет объектов при
отрисовке, но значительно уменьшает
требования к памяти. Но доже в этом
случае, размер PVS
растет квадратично с увеличением
количества объемов. Тем не менее, метод
PVS
является очень эффективным и используется
во многих приложениях.
ля
многих сцен, особенно для закрытых
помещений, количество видимых на экране
объектов значительно меньше общего
количества объектов в сцене. Для быстрого
отсеивания большей части невидимых
объектов в статических, неизменных,
сценах и применяется этот метод.
Пространство сцены разбивается на
выпуклые объемы, например комнаты. Для
каждого объема определяется, какие
объекты могут быть видимы хотя бы из
одной точки этого объема. При отображении
сцены определяется объем, в котором
находится наблюдатель, а затем выводятся
все объекты, которые он может увидеть.
Основным недостатком PVS
является потребность в больших объемах
памяти, ведь для каждого объема нужно
хранить карту всех, видимых из него,
объектов. Как правило, хранят не карту
видимых объектов, а карту видимых
объемов, это добавляет объектов при
отрисовке, но значительно уменьшает
требования к памяти. Но доже в этом
случае, размер PVS
растет квадратично с увеличением
количества объемов. Тем не менее, метод
PVS
является очень эффективным и используется
во многих приложениях.
Метод порталов
PVS можно строить и динамически. Для этого между объемами расставляются порталы – выпуклые полигоны, через которые можно, находясь в одном объеме, видеть содержимое соседнего объема. Очевидно, что если наблюдатель находится в некотором объеме, то он может видеть все объекты, лежащие в этом объеме и части объектов и порталов, лежащих на гранях соседних объемов, в которые ведут порталы из текущего. Таким образом, можно построить рекурсивный алгоритм:
-
отобразить все объекты текущего объема;
-
отсечь все порталы, ведущие из текущего объема по текущему порталу и рекурсивно вызвать себя для каждого объема, в который ведут эти порталы;
Начальный портал – портал окна на экране, начальный объем – тот, в котором находится наблюдатель. Недостатком алгоритма является то, что при большом количестве видимых на экране порталов процесс отображения замедляется.


Метод иерархических подсцен
Похож на метод порталов, только порталы в этом случае связывают не выпуклые объемы одной сцены, а несколько подсцен. Причем каждая сцена может храниться и выводиться наиболее подходящим для нее образом. Например, внутренние помещения могут использовать PVS и BSP, а открытые поверхности – сортировку. Каждая такая подсцена должна уметь выводить себя через портал произвольной формы, при этом все ее грани отсекаются по этому порталу. Вывод подсцен происходит рекурсивно, как и в предыдущем случае.
Общая схема визуализации сцены
