

-
Критерии сравнения алгоритмов.
Основным критерием является коэффициент сжатия и скорость компрессии и декомпрессии. Лучший, худший и средний коэффициенты сжатия. Следует отметить, что средний коэффициент следует считать по отношению к тем изображениям, на которые ориентирован алгоритм (например, реальную эффективность алгоритма сжатия факсимильных сообщений бессмысленно измерять на тесте из фотографий). Худший коэффициент, кстати, может быть и больше 1.
-
Алгоритмы архивации без потерь.
При рассмотрении алгоритмов без потерь, стоит отметить несколько важных моментов. Во-первых, поскольку алгоритмы не изменяют исходные данные, то мы можем считать любой алгоритм сжатия информации алгоритмом сжатия изображений без потерь (кстати, не так много алгоритмов сжатия без потерь разрабатывались специально для изображений)
Во-вторых, невозможно построить алгоритм сжатия без потерь, который для любой первоначальной цепочки данных давал бы меньшую по длине цепочку. Если есть цепочки, которые алгоритм укорачивает, то есть те, которые он удлиняет. Хотя, впрочем, можно модифицировать алгоритм, так чтобы в худшем случае увеличение составляло всего 1 бит, а именно, в случае если алгоритм увеличивает цепочку, писать в выходной поток единицу, а потом исходную цепочку, в противном случае писать ноль и архивированную цепочку.
Алгоритм RLE.
Суть алгоритма состоит в том, что сначала вытягивается по строкам растра, а потом повторяющиеся пиксели заменяются парой (счетчик, значение).
В формате PCX это реализовано следующим образом: в выходной поток пишется либо непосредственно значение пикселя (если в двух его старших разрядах не единицы):
[ XX значение ]
либо пара
[ 11 счетчик ] [ что повторять ]
причем повторяемый символ повторяется число раз, на единицу большую счетчика (не имеет смысл повторять 0 раз). Например, строку из 64 повторяющихся байтов мы превратим в два байта. С другой стороны, если в двух старших разрядах пикселя – единицы, и он не повторяется, то мы будем вынуждены записать:
[ 11 000000 ] [ значение ]
то есть, в худшем случае увеличим размер файла в два раза.
Данный алгоритм рассчитан на изображения с большими областями, залитыми одним цветом. В основном на черно-белые.
В формате BMP немного хитрее, все цепочки начинаются с 2-х байтового префикса (кол-во),(значение). Если первый байт (кол-во) нулевой - то в следующем байте находится число неупакованных байт, а сами байты располагаются сразу после префикса.
Например цепочка (04,50,00,03,F1,30,60,03,11) распакуется в следующую цепочку (50,50,50,50,F1,30,60,11,11,11). Это позволяет значительно сократить размеры изображений, которые плохо пакуются предыдущим алгоритмом.
Алгоритм LZW.
Основан на упаковке не только повторяющихся символов, но и повторяющихся последовательностей. Существует огромное количество различных реализаций алгоритма сжатия LZW (Lempel, Ziv, Welch). Наиболее распространенный формат, использующий такой алгоритм – GIF. Рассмотрим одну из реализаций:
-
Создаем таблицу на 4096 элементов, каждый элемент таблицы соответствует цепочке символов, первые 256 – последовательности, состоящие из одного соответствующего символа. Для кода очистки (ClearCode) и кода конца информации (CodeEndOfInformation) зарезервированы значения 256 и 257. соответственно под коды цепочек остаются значения 258…4095.
-
Берем очередной символ из входной последовательности и добавляем его в конец текущей цепочки (в начале цепочка пуста).
-
Проверяем, есть ли в нашей таблице текущая цепочка. Если есть, то запоминаем ее код и переходим к шагу 2.
-
Если цепочки нет, то заносим ее в таблицу. В выходную последовательность заносим запомненный код, а текущая цепочку полагаем равной последнему считанному символу. Далее переходим к шагу 2. Если таблица закончилась – нужно записать в выходной поток код очистки и перейти к шагу 1.
Пусть мы сжимаем последовательность 0,1,1,2,1,1,1. Тогда, согласно изложенному выше алгоритму добавим к изначально пустой цепочке “0” и проверим, есть ли цепочка “0” в таблице. Поскольку мы при инициализации занесли в таблицу все цепочки из одного символа, то цепочка “0” есть в таблице. Далее мы читаем следующий символ “1” из входного потока и проверяем, есть ли цепочка “0,1” в таблице. Такой цепочки в таблице пока нет. Мы заносим в таблицу цепочку “0,1” (с первым свободным кодом 258) и записываем в поток код “0”. Можно коротко представить архивацию так:
-
“0” — есть в таблице;
-
“0,1” — нет. Добавляем в таблицу <258>“0,1”. В поток: <0>;
-
“1,1” — нет. В таблицу: <259>“1,1”. В поток: <1>;
-
“1,2” — нет. В таблицу: <260>“1,2”. В поток: <1>;
-
“2,1” — нет. В таблицу: <261>“2,1”. В поток: <2>;
-
“1,1” — есть в таблице;
-
“1,1,1” — нет. В таблицу: “1,1,1” <262>. В поток: <259>;
Последовательность кодов для данного примера, попадающих в выходной поток: <0>, <1>, <1>, <2>, <259>.
Данный алгоритм можно улучшить, заметив, что в компрессированном файле не может появится значение 512, до того как появилось 511. Таким образом, числа можно записывать сначала как 9-ти битные, потом, после встречи числа 512 как 10 битные, и так далее.
Алгоритм Хаффмана.
Использует то, что некоторые символы во входной цепочке встречаются более часто, чем другие. Сжатие происходит за счет того, что символы кодируются разным кол-вом битов, тем, что встречаются чаще соответствует более короткий код, чем для тех, что встречаются реже. Например, есть цепочка в которой встречаются символы A,B,C,D. При обычной кодировке каждый из них можно закодировать 2 битами A=00,B=01,C=10,D=11. И цепочка из 1000 символов будет иметь длину 2000 бит. Если некоторые символы встречается более часто, чем другие (например, в цепочке 800 символов A, 100 символов B, 50 символов С и 50 символов D), то если сопоставить символам коды разной длины A=0, B=10, C=110,D=111, то общая закодированной длина цепочки составит 800*1+100*2+50*3+50*3=1300 бит. Правда еще придется хранить таблицу соответствия кодов, но она занимает сравнительно немного места при больших размерах цепочек. Обычно коэффициент сжатия составляет около 2-х. Этот алгоритм редко применяют самостоятельно, но вместе с алгоритмом RLE или LZW он дает неплохие результаты.
Алгоритм JPEG.
Это алгоритм сжатия с потерями придуманный Объединенной группой экспертов по фотографии (Joint Photographic Experts Group). Хорошо подходит для фото-изображений, имеет коэффициент сжатия до 20. В нем изображение проходит через несколько стадий сжатия:
-
сначала оно прореживается по цвету. Человеческий глаз более чувствителен к изменениям яркости, чем и изменению цвета. Сначала изображение переводится в систему YUV (Y-яркость, U,V- цветовые составляющие). Затем цветовые составляющие прореживаются, так, что из каждого квадратика пикселов 2х2 исходного изображения получается один пиксел (фактически изображение приводится к вдвое меньшему разрешению). За счет этого происходит сжатие в (4+4+4)/(4+1+1)=2,66 раз.
-
Изображение разбивается на квадратики 8х8 пикселов и к каждому такому квадратику применяется дискретное косинусное преобразование (по каждой составляющей). Его цель – перейти к спектру значений яркости и цветности в квадратике. Так как глаз более чувствителен к низкочастотным составляющим спектра, а высокочастотные воспринимаются как шум – можно отбросить несколько высокочастотных коэффициентов, и за счет этого получить сжатие. Чем больше коэффициентов будет отброшено, тем больше коэффициент сжатия и искажения изображения.
-
Наконец, эти коэффициенты кодируются с помощью RLE и Хаффмана.
Алгоритм S3TC.
Это алгоритм сжатия текстур (S3 Texture Compression). Это достаточно простой метод, изображение разбивается на квадратики 4х4, каждый квадратик приводится к палитре в 4 цвета. Таким образом, начальное изображение пакуется с коэффициентом (16*4*4)/(16*4+2*4*4)=2,66. Это сжатие с потерями. При этом распаковка происходит очень быстро, что важно для текстур.
Алгоритм MPEG.
Это алгоритм сжатия видео, здесь используется предположение, что соседние кадры мало отличаются друг от друга. Поэтому достаточно описать лишь разницу между ними. В этом алгоритме изображение как и в JPEG прореживается по цвету, а затем разбивается на блоки 16x16. Первый кадр кодируется как обычное изображение, а для последующего для каждого блока ищется наиболее похожий блок в предыдущем кадре. Причем он может быть смещен на некоторый вектор. Если блоки совпадают полностью – можно просто сохранить этот вектор, если отличаются – то можно сохранить разницу между ними, она должна занять меньше места, чем сам блок. Кроме того, можно посчитать среднее между блоком с предыдущего кадра и блоком со следующего, которое может лучше соответствовать данному.




















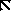








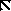


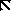








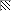



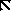

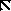

Существует три типа закодированных кадров. I-фремы - это кадры, закодированные как неподвижные изображения - без ссылок на последующие или предыдущие. Они используются как стартовые.
P-фреймы - это кадры, предсказанные из предыдущих I- или P-кадров. Каждый блок в P-фрейме может идти с вектором и разностью коэффициентов ДКП от соответствующего блока последнего раскодированного I или P, или может быть закодирован как в I, если не соответствующего блока не нашлось.
И, наконец, существуют B-фреймы, которые предсказаны из двух ближайших I или P-фреймов, одного предыдущего и другого - последующего. Соответствующие блоки ищутся в этих кадрах и из них выбирается лучший. Ищется прямой вектор, затем обратный и вычисляется среднее между соответствующими блоками в прошлом и будущем. Если это не работает, то блок может быть закодирован как в I-фрейме.
Последовательность раскодированных кадров обычно выглядит как
I B B P B B P B B P B B I B B P B B P B ...
Здесь 12 кадров от I до I фрейма. Это основано на требовании произвольного доступа, согласно которому начальная точка должна повторяться каждые 0.4 секунды. Соотношение P и B основано на опыте.
Чтобы декодер мог работать, необходимо, чтобы первый P-фрейм в потоке встретился до первого B, поэтому сжатый поток выглядит так:
0 x x 3 1 2 6 4 5 ...
где числа - это номера кадров. xx может не быть ничем, если это начало последовательности, или B-фреймы -2 и -1, если это фрагмент из середины потока.
Сначала необходимо раскодировать I-фрейм, затем P, затем, имея их оба в памяти, раскодировать B. Во время декодирования P показывается I-фрейм, B показываются сразу, а раскодированный P показывается во время декодирования следующего.
Алгоритм Фрактальной упаковки.
Он основан на том, что в изображении присутствуют похожие фрагменты, причем в отличии от RLE или LZW алгоритмов, которые хорошо работают только с полностью идентичными фрагментами, он может упаковывать и довольно сильно отличающиеся по размеру, яркости и расположению части изображения.
Фрактальная архивация основана на том, что мы представляем изображение в более компактной форме — с помощью коэффициентов системы итерируемых функций (Iterated Function System — далее по тексту как IFS). Прежде, чем рассматривать сам процесс архивации, разберем, как IFS строит изображение, т.е. процесс декомпрессии.
Строго говоря, IFS представляет собой набор трехмерных аффинных преобразований, в нашем случае переводящих одно изображение в другое. Преобразованию подвергаются точки в трехмерном пространстве (х_координата, у_координата, яркость).
Наиболее наглядно этот процесс можно представить как Фотокопировальную Машину, состоящую из экрана, на котором изображена исходная картинка, и системы линз, проецирующих изображение на другой экран:
-
Линзы могут проецировать часть изображения произвольной формы в любое другое место нового изображения.
-
Области, в которые проецируются изображения, не пересекаются.
-
Линза может менять яркость и уменьшать контрастность.
-
Линза может зеркально отражать и поворачивать свой фрагмент изображения.
-
Линза должна масштабировать (уменьшать)свой фрагмент изображения.

Расставляя линзы и меняя их характеристики, мы можем управлять получаемым изображением. Одна итерация работы Машины заключается в том, что по исходному изображению с помощью проектирования строится новое, после чего новое берется в качестве исходного. Утверждается, что в процессе итераций мы получим изображение, которое перестанет изменяться. Оно будет зависеть только от расположения и характеристик линз, и не будет зависеть от исходной картинки. Это изображение называется “неподвижной точкой” или аттрактором данной IFS. Соответствующая теория гарантирует наличие ровно одной неподвижной точки для каждой IFS.
Поскольку отображение линз является сжимающим, каждая линза в явном виде задает самоподобные области в нашем изображении. Благодаря самоподобию мы получаем сложную структуру изображения при любом увеличении. Таким образом, интуитивно понятно, что система итерируемых функций задает фрактал (нестрого — самоподобный математический объект).
Наиболее известны два изображения, полученных с помощью IFS: “треугольник Серпинского” и “папоротник Барнсли”. “Треугольник Серпинского” задается тремя, а “папоротник Барнсли” четырьмя аффинными преобразованиями (или, в нашей терминологии, “линзами”). Каждое преобразование кодируется буквально считанными байтами, в то время как изображение, построенное с их помощью, может занимать и несколько мегабайт.