

Подходы к анализу пространственно распределенных данных
Существует несколько подходов к анализу пространственно распределенных данных, которые можно условно разделить на 4 группы:
Детерминистические методы (интерполяторы).
Геостатистика – модели, базирующие на статистической интерпретации данных.
Алгоритмы искусственного интеллекта (искусственные нейронные сети, генетические алгоритмы).
Модели, базирующиеся на статистической теории обучения.
Такое деление является крайне условным. Так, геостатистические модели можно изложить в детерминистической формулировке и наоборот, ряд детерминистических моделей имеют близкие статистические аналоги.
При использовании
детерминистических методов предполагается,
что анализируемые данные описываются
некоторой детерминистической функцией
V(x),
определенной на исследуемой области
(S),
где
![]() –
координата точки. Задача состоит в том,
чтобы, базируясь на известных данных
(Vi=V(xi)
– значения измеренные в точках
–
координата точки. Задача состоит в том,
чтобы, базируясь на известных данных
(Vi=V(xi)
– значения измеренные в точках
![]() )
и на другой информации об исследуемом
явлении, построить функциюV(x)
для всей исследуемой области S.
После этого значение в любой точке
исследуемой области может быть просто
вычислено по формуле. Для двумерного
случая такую функцию можно представить
как поверхность Z=f(x,y),
рис.6.
)
и на другой информации об исследуемом
явлении, построить функциюV(x)
для всей исследуемой области S.
После этого значение в любой точке
исследуемой области может быть просто
вычислено по формуле. Для двумерного
случая такую функцию можно представить
как поверхность Z=f(x,y),
рис.6.
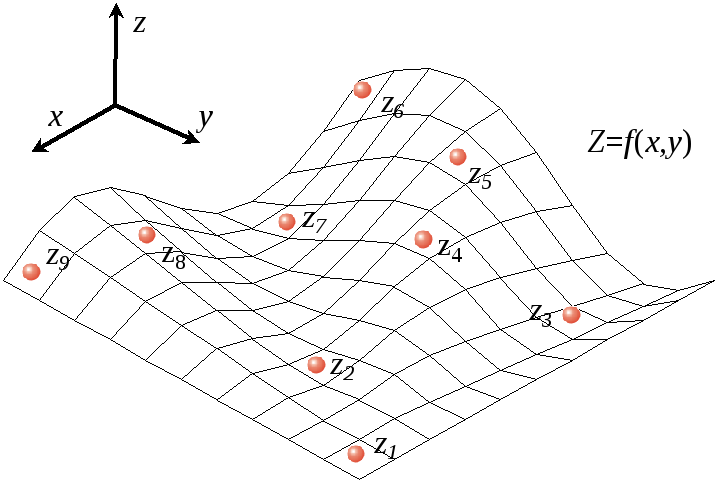
Рисунок 6 – Построение поверхности
1.4. Детерминистские методы интерполяции
Детерминистские методы для интерполяции используют математические функции (зависимости) и строят поверхность по опорным точкам, основываясь либо на степени схожести точек выборки (как например, метод взвешенных расстояний), либо на степени сглаживания (как например, радиальные базисные функции).
Детерминистские методы интерполяции могут быть разделены на две группы: глобальные и локальные.
Глобальные методы вычисляют искомые значения с использованием всего набора данных.
Локальные методы используют для вычисления искомых значений только опорные точки, расположенные в окрестностях искомой, и относятся только к небольшим участках изучаемой территории.
Построение непрерывной поверхности для представления определенных измерений - одно из ключевых требований, предъявляемых к большинству ГИС-приложений.
Возможно, наиболее часто используемый тип поверхности - это цифровая модель рельефа или распределение климатических характеристик. Такие наборы данных в мелком масштабе есть в готовом виде для различных территорий мира.
Однако, как уже говорилось, любое измеренное значение в точке ландшафта, земной коры или атмосферы может быть использовано для построения непрерывной поверхности.
Главная проблема, с которой сталкиваются специалисты, занимающиеся моделированием в ГИС, - построение наиболее точной из возможных поверхностей на основе существующих опорных точек, наряду с оценкой ошибки интерполяции и отклонений в значениях проинтерполированной поверхности.
Вновь построенные поверхности впоследствии используются в ГИС-моделировании и анализе, наряду с их трехмерной визуализацией. Понимание качества этих данных может значительно улучшить эффективность и направленность ГИС-моделирования. Эта роль и отводится модулю Geostatistical Analyst.
Анализ свойств поверхности в окрестностях опорной точки
В целом, объекты, расположенные ближе друг к другу, как правило, более похожи между собой, чем удаленные друг от друга объекты. Это один из основных принципов географии (ТоЫег, 1970).
Представьте себе, что вы занимаетесь планированием в городе, и перед вами стоит задача разбить в своем городе живописный парк. У вас есть несколько предполагаемых мест, и вам необходимо смоделировать обзор для каждой проектируемой точки.
Для этого вам необходим подробный набор данных с высотами поверхности на изучаемую территорию. Предположим, что у вас уже есть данные о высотах для 1000 точек, расположенных по всему городу. Эти данные вы можете использовать для построения новой поверхности высот.
При построении поверхности высот, вы можете предположить, что значения высот в точках, для которых выполняется интерполяция, и значения в опорных точках, расположенных к ним ближе всего, будут похожи. Но возникает вопрос: сколько опорных точек следует рассматривать? И следует ли значения во всех опорных точках учитывать одинаково?
По мере того, как вы удаляетесь от искомой точки, влияние опорных точек будет уменьшаться. Учет в вычислениях точки, удаленной на значительное расстояние от опорной, может быть ошибочным, поскольку точка может находиться на участке местности, кардинальным образом отличающимся от того, на котором расположена искомая точка.
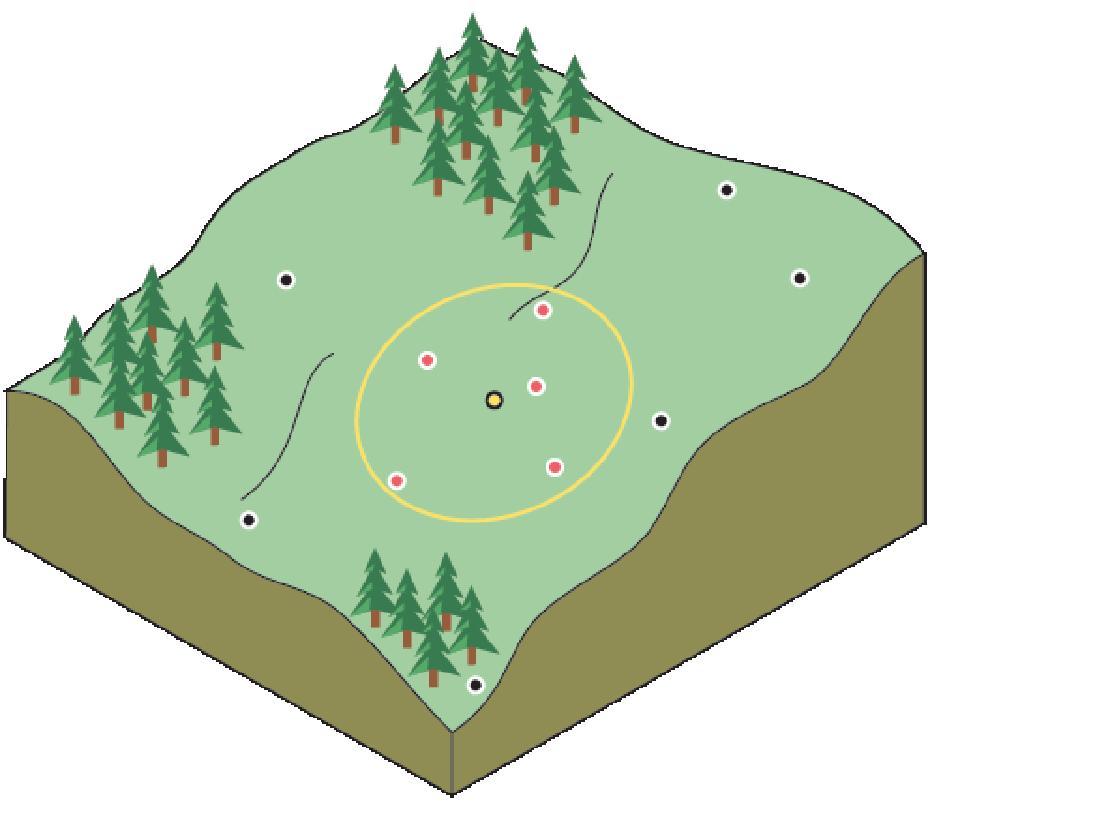
Рисунок 7 – Схема места для строительства
Одно из решений - учитывать достаточное количество точек, образующих небольшую, но репрезентативную выборку. Число точек будет варьировать в зависимости от общего количества опорных точек и их расположения в пространстве, а также от характера поверхности.
Если выборки с высотами относительно равно мерно распределены, и характеристики поверхности не меняются в различных частях ландшафта, вы можете с достаточной точностью интерполировать значения поверхности на основе значений в близлежащих точках.
Чтобы учесть различную удаленность точек от искомой точки, значениям опорных точек, расположенных ближе к ней, присваивается больший вес.
Это основа метода интерполяции, известного как Метод (обратных) взвешенных расстояний - Inverse Distance Weighting (IDW). Как следует из названия, вес значения уменьшается по мере увеличения расстояния от искомой точки. Рассмотрим позже.