

4.4. Сепарабельное программирование
В сепарабельном программировании (СП) рассматриваются задачи, в которых целевая функция и все функции ограничений сепарабельны.
Напомним, что функция многих переменных сепарабельна, если она имеет вид суммы функций отдельных переменных:
f(x1,
x2,
..., xn)
= ![]() (4.18)
(4.18)
Линейные функции всегда сепарабельны, и поэтому линейное программирование можно рассматривать как частный случай сепарабельного.
Решение задач СП основано на преобразовании в задачи линейного программирования путем аппроксимации нелинейных функций кусочно-линейными. Таким образом, исходная нелинейная задача заменяется аппроксимирующей линейной. Поэтому рассматриваемый метод является приближенным, а точность решения напрямую зависит от точности аппроксимации и теоретически может быть сколь угодно высокой.
Существует два основных способа записи аппроксимирующей задачи, отличающихся формой представления исходных переменных: в - или в -постановке.
-постановка. Предполагается, что переменные, которые входят в модель нелинейно, ограничены снизу и сверху:
dj xj Dj. (4.19)
Для кусочно-линейной аппроксимации в этом диапазоне выбираются узловые точки, преимущественно в той части, где сильнее нелинейность функции. При этом первый узел совпадает с нижней границей, а последний – с верхней:
Xj1
=
dj,![]() =
Dj,
=
Dj,
где rj – число интервалов по переменной xj (rj+1 – число узлов). Тогда рассматриваемая переменная xj может быть выражена через новые переменные jk в виде
![]() ;
(4.20)
;
(4.20)
![]() ;
(4.21)
;
(4.21)
![]() .
(4.22)
.
(4.22)
Выражение (4.20) называют уравнением сетки. С учетом (4.21) и (4.22) оно представляет переменную xj в диапазоне (4.19) без потери точности. С использованием узловых точек и новых переменных кусочно-линейная функция, аппроксимирующая fj(xj), записывается в виде
![]() (4.23)
(4.23)
где fj(Xjk)
– значение функции в узловых точках
(рис. 4.6). Очевидно, что ![]() – функция, линейная относительно
jk.
Пусть N
– множество индексов нелинейных fj(xj).
Тогда функция, аппроксимирующая
f(X),
имеет вид
– функция, линейная относительно
jk.
Пусть N
– множество индексов нелинейных fj(xj).
Тогда функция, аппроксимирующая
f(X),
имеет вид
![]() (4.24)
(4.24)
Итак, чтобы построить линейную аппроксимирующую модель, необходимо:
1) для каждой переменной, входящей нелинейно, записать уравнение сетки;
2) во всей модели заменить переменные из п. 1, входящие в линейные fj , соответствующими уравнениями сетки;
3) все функции, содержащие нелинейности, представить в виде уравнения (4.24);
4) добавить ограничения (4.21), (4.22) для всех новых переменных.
Если переменная xj входит нелинейно в несколько функций, узлы сетки выбираются с учетом нелинейности всех таких функций, так как для одной переменной может быть только одно уравнение сетки.
Поясним запись ограничений. Пусть имеется исходное ограничение
ij(xj) bi
со всеми нелинейными ij. Тогда после аппроксимации оно принимает вид
![]() .
.
В общем случае левая часть ограничения записывается аналогично (4.24).
Хотя аппроксимирующая задача линейная, получаемое на ней решение не всегда является приближением к решению исходной задачи. Дело в том, что одно и то же значение xj можно получить по уравнению сетки при разных jk, т.е. представить через разные пары узлов. Например, некоторое значение xj можно выразить через смежные узлы, в интервале которых находится значение, а можно через любую другую пару узлов, лежащих слева и справа, в том числе через первый и последний узел. Во всех случаях, кроме первого, аппроксимация функции будет грубой и тем грубее, чем дальше отстоят узлы от данного значения xj.
Отсюда следует правило смежных весов: из одного уравнения сетки отличными от нуля могут быть не более 2 переменных jk со смежными значениями k.
Если аппроксимирующая задача является задачей выпуклого программирования, то это правило выполняется автоматически и решение находится методом ЛП без каких-либо дополнений. Оптимальное решение аппроксимирующей задачи будет приближением глобального решения исходной задачи.
В противном случае алгоритм ЛП должен включать правило ограниченного ввода: если в базисном решении находится jk, то допустимыми для ввода могут быть только jk+1 или jk–1.
При этом нельзя утверждать, что получаемое решение является приближением к глобальному оптимуму исходной задачи. Скорее оно будет приближением локального оптимума.
Свойства задачи зависят от всех функций модели.
1. Если все ограничения линейные, то для выпуклости задачи достаточно, чтобы были вогнутыми все fj критерия (выпуклы при минимизации).
2. При нелинейности критерия и ограничений для выпуклости задачи должны быть вогнуты все fj и выпуклы все ij.
3. Если хотя бы одна fj не вогнута при максимизации и/или одна ij не выпукла, задача не является выпуклой.
Заметим, что, если все функции кусочно-линейные, переход к новым переменным не связан с потерей точности и при выполнении условий задач выпуклого программирования получаемое решение является точным и глобальным.
Пример 4.3. Задача
f = 6x1 – x12 + 7x2 → max;
2x12 – 5x1 + 3x22 8;
1 x1 < 4, x2 0
является задачей сепарабельного программирования.
Здесь
f1(x1) = 6x1 – x12; f2(x2) = 7x2;
11(x1) = 2x12 – 5x1; 12(x2) = 3x22.
Так как f1(x1) и f2(x2) – вогнутые, а 11(x1) и 12(x2) – выпуклые, имеем задачу выпуклого программирования. Обе переменные входят нелинейно, поэтому нужно строить две сетки. Оценим верхний предел x2: находим min11 = –3,125, затем из ограничения получаем максимально возможное значение x2 = 1,93. Берем D2 = 2. Пусть узловыми будут значения по x1: 1, 2, 3, 4; по x2: 0, 1, 2. Записываем уравнения сеток: x1 = 11 + 212 + 313 + 414, x2 = 22 + 223. В итоге получаем модель аппроксимирующей задачи в виде
![]() 511
+ 812
+ 913
+ 814
+ 722
+ 1423
→
max;
511
+ 812
+ 913
+ 814
+ 722
+ 1423
→
max;
–311 – 212 + 313 + 1214 + 322 + 1223 8;
11 + 212 + 313 + 414 1;
11 + 212 + 313 + 414 4;
11 + 12 + 13 + 14 = 1;
21 + 22 + 23 = 1;
jk 0.
Эта задача решается любым универсальным методом ЛП без добавления правила ограниченного ввода.
-постановка. Построение аппроксимирующей задачи основано также на кусочно-линейном приближении, но меняется уравнение сетки. По узлам сетки вычисляются расстояния между смежными узлами (длины интервалов)
jk = Xjk+1 – Xjk,
и уравнение сетки записывается в виде
xj
= dj
+ ![]() ;
(4.25)
;
(4.25)
0 yjk 1, (4.26)
где yjk – новые переменные.
Из представления переменной в виде уравнений (4.25), (4.26) следует:
xj = dj, когда yjk = 0;
xj находится в первом интервале, когда yj1 (0, 1), остальные yjk = 0;
xj находится во втором интервале, когда yj1 = 1, yj2 (0, 1), остальные yjk = 0;
xj находится в k-м интервале, когда yj1 = yj2 = ... = yjk–1 = 1, 0 yjk 1, остальные yjk = 0.
Таким образом, для правильной аппроксимации должно выполняться установленное соответствие между значениями переменной xj и yjk. Это требование аналогично правилу смежных весов. При ином представлении значения xj будет нарушена кусочно-линейная аппроксимация функции.
Для аппроксимации нелинейной составляющей функции критерия вычисляются разности ее значений в смежных узлах:
jk = fj (Xjk+1) – fj (Xjk),
с помощью которых записывается аппроксимирующая функция
![]() (4.27)
(4.27)
Тогда функция, аппроксимирующая критерий, имеет вид
![]()
Аналогично аппроксимируются ограничения ij(xj):
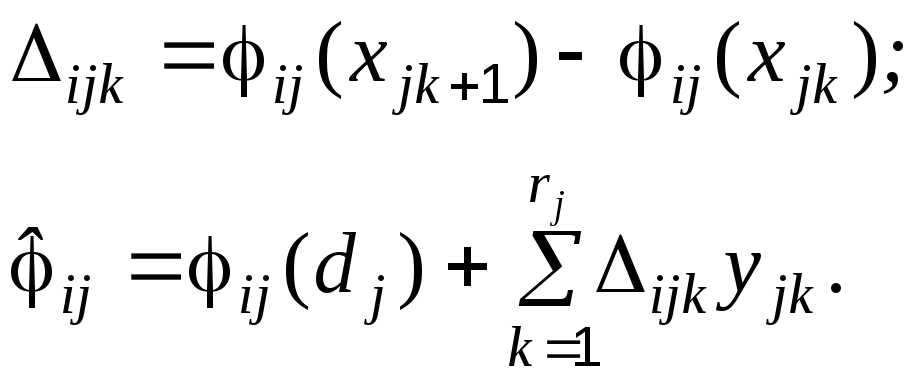
Как и в -постановке, если имеет место задача выпуклого программирования, то требования к переменным yjk выполняются автоматически и полученное решение будет приближенным глобальным решением исходной задачи. В противном случае необходимо придерживаться правила ограниченного ввода относительно переменных yjk: если первые k переменных равны единице, вводить можно только yjk+1.
При практическом решении сепарабельных задач сначала можно взять малое число узлов и получить приближенное оптимальное решение. Затем в качестве исходных принять интервалы, на которых лежат оптимальные xj, и выполнить аппроксимацию функций только на этих интервалах с малыми расстояниями между узлами. Такой способ снижает размерность решаемых задач и повышает точность получаемого решения.
Следует заметить, что в ряде случаев несепарабельная функция может быть преобразована к сепарабельной. Способ преобразования зависит от структуры функции. Например, произведение двух сепарабельных функций S(X)T(X) можно привести к сепарабельному виду, заменив его переменной v с дополнительными равенствами:
S(X) = z – y; T(X) = z + y.
Тогда v = (z – y)(z + y) = z2 – y2 – сепарабельная функция. Так, функция f = x1 + x2x32 заменяется на сепарабельную f = x1 + v с дополнительными сепарабельными ограничениями
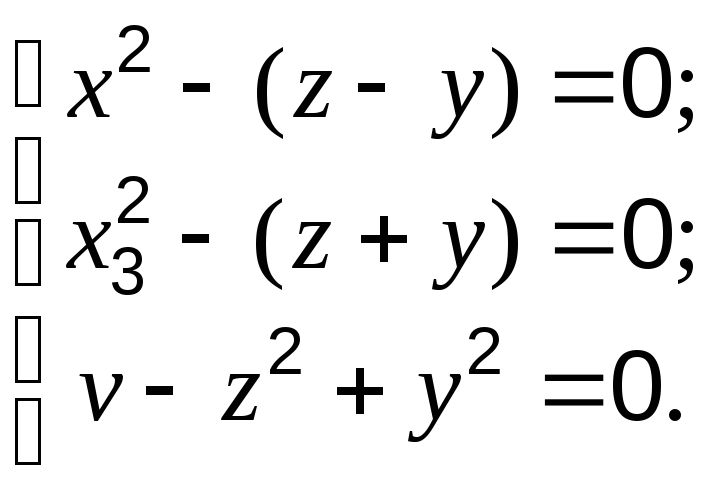
Пример 4.4. Покажем, что некоторые стохастические задачи могут сводиться к сепарабельным. Стохастические модели описывают ситуации выбора решения в условиях риска, обусловленного влиянием случайных факторов. Предполагается, что закон распределения случайных величин известен.
Пусть
зависимости от искомых переменных
линейны, но коэффициенты критерия и
ограничений зависят от случайной
величины
(состояния среды). В этом случае в качестве
критерия берется обычно математическое
ожидание линейной формы M(L)
= M[CT()X]
=
![]() а запись ограничений зависит от требований
к их выполнению. При допустимости
некоторых нарушений условий задачи
ограничения записываются в вероятностной
форме:
а запись ограничений зависит от требований
к их выполнению. При допустимости
некоторых нарушений условий задачи
ограничения записываются в вероятностной
форме:
![]()
где pi – заданное значение вероятности выполнения i-го условия. Такое ограничение заменяется эквивалентным детерминированным условием
![]() (*)
(*)
где ![]() – математические ожидания;
– математические ожидания; ![]() – дисперсия
– дисперсия ![]() ;
;
![]() – дисперсия
– дисперсия ![]() ;
;
![]() = t(pi)
– значение функции, обратной функции
распределения (например, нормального).
= t(pi)
– значение функции, обратной функции
распределения (например, нормального).
В результате детерминированная модель стохастической задачи включает линейный критерий и существенно нелинейные ограничения (*). Очевидно, что она не является сепарабельной. Сделаем простое преобразование. Обозначим
![]() .
.
Тогда каждое ограничение (*) заменяется двумя условиями:

Первое из них – линейное, а второе – сепарабельное. Таким образом, стохастическая задача приведена к сепарабельной.
Примечание. Если случайным является только вектор ограничений, то, как следует из (*), стохастическая задача сводится к линейной.