

Лекции ГИС1
.pdfзадачу. Но если вы собираетесь определить объем рудной залежи, то вам придется иметь дело с двумя неровными поверхностями, причем обе — как правило — интерполированы. Тем не менее, вы можете использовать тот же подход, за тем исключением, что теперь вам нужно вычесть значения высот нижней поверхности из соответствующих значений верхней. Объем этой разностной поверхности даст вам искомую величину.
ДРУГИЕ ВИДЫ АНАЛИЗА ПОВЕРХНОСТЕЙ
Помимо рассматривавшихся ранее операций существует множество других способов отображения и использования дополнительных покрытий с использованием данных о поверхности. Например, большинство ГИС позволяют отображать дополнительные покрытия наложенными на трехмерный вид поверхности. Эта возможность позволяет показать отношения между высотой и почвами, растительностью или распределением типов землепользования. Большинство программ также могут создавать покрытия из площади поверхности, занимаемой объемными объектами, такими как холмы. Вы также можете найти полезным определение реальной длины дороги, а не ее длины в плоскости, поскольку будет учтена топографическая поверхность.
ДИСКРЕТНЫЕ ПОВЕРХНОСТИ
Статистические поверхности могут представляться четырьмя различными способами. Мы уже рассмотрели основные методы представления непрерывных данных с использованием матриц высот, моделей TIN, изолиний. Но данные статистических поверхностей могут также встречаться как дискретные объекты. Для них мы должны рассмотреть некоторые дополнительные методы, как отображения, так и анализа.
КАРТЫ ПЛОТНОСТИ ТОЧЕК
Этот подход чаще всего использует конкретные области, в которых подсчитываются объекты (число птиц на округ, тонн собранного зерна на ферму и т.д.). Другая распространенная форма карт плотности точек не использует отобранные области, а обозначает каждый объект одной точкой. Карты учета растений и животных, помещаемые в исследовательских статьях и книгах, или изыскания, проводимые многими службами биологических наблюдений, являются типичными представителями этого подхода.
Когда точка указывает на более чем одно наблюдение, должны быть заданы три взаимосвязанных вопроса: сколько объектов представляется одной точкой, каков размер точки в связи с единицей дискретности, и где мы расположим точки после ответа на первые два вопроса.
В то время как эти вопросы важны для картографического представления, их важность не проявляется, пока нам не придется вводить такие карты в ГИС. Чаще всего, когда нам приходится это делать, точки подсчитываются в каждом полигоне и преобразуются в одно значение. Затем они могут представляться посредством картограмм. Позднее мы рассмотрим эти карты подробнее. Кроме того, точки могут рассматриваться как непрерывные данные, и в таком случае мы можем выбрать центроид или центр тяжести для представления значения каждой области в виде одной точки, а затем выполнять операции над всем набором с помощью изолиний. Таким образом мы можем работать подобно тому, как это делалось с непрерывными данными, применяя интерполяцию или другие методы аппроксимации, анализ уклона и экспозиции и т.д.
Когда каждая точка показывает некоторое количество объектов, скажем, местоположений гнезд птиц, мы должны полагать, что положения точек точны, и только их размер должен нас беспокоить при вводе подсчитанных объектов в ГИС. Однако, мы видим, что подавляющее большинство точечных карт, особенно те, что были созданы до появления
141
современных технологий GPS и телеметрии, отображают точки в широком диапазоне размеров. Обычное дело - увидеть карты масштаба 1:100 000 с точками, которые покрывают сотни и даже тысячи метров на земле. Пока мы не имеем точных координат, мы вынуждены считать, что координаты точек наиболее верно отражаются их центрами. Хотя это и может быть не совсем правильно, у нас нет альтернатив.
В некоторых случаях представляют интерес расстояния и группировки отдельных точечных распределений. Большинство ГИС не очень-то приспособлены для выполнения такого анализа, но это мы рассмотрим уже в следующей главе. Иногда мы также обнаруживаем, что каждая точка сопровождается дополнительными данными, записанными в любой из четырех шкал измерения. Но в контексте статистической поверхности мы обращаем внимание только на те, которые представлены в числовых шкалах. Если мы можем принять, что имеется непрерывность для таких величин, как массы птиц или размеры стай млекопитающих, представленные отдельными точками, то сможем выполнять операции с этими точечными данными, как если бы они были точечной выборкой топографической поверхности, особенно если они записаны в шкале интервалов или отношений. Всё же, предположение непрерывности в большинстве из этих случаев неверно, и нам придется рассматривать и сравнивать эти дискретные события по отдельности, либо статистически, либо через сравнения их пространственных отношений. Этот тип анализа мы рассмотрим опять же в следующей главе.
Мы также упоминали о преобразовании карт распределения отдельных точек в некоторую форму площадного распределения, особенно в связи с зоокартографией. Как мы заметили, не существует точных инструкций о том, как выполнять эти преобразования, а простые графические методы, которые не связаны с функциями животных или других объектов в их окружении, могут давать ошибочные результаты. Чаще всего, если вас просят выполнить анализ таких распределений, вам нужно знать как можно больше о природе явления, либо из ваших собственных исследований, либо в результате подробных консультаций с вашими заказчиками.
КАРТЫ ХОРОПЛЕТ
Довольно часто статистические данные записываются для конкретных областей без учета конкретных местоположений. Мы видели, что можем считать такие данные непрерывными и оперировать с ними как с картами изолиний. Хотя это хорошо работает для распределений по большим поверхностям, чаще всего данные собираются для поиска максимумов и минимумов для каждой единичной области или для сравнения единичных областей с другими единицами других покрытий (более подробно в Главе 12). В Главе 3 мы рассматривали идею картограмм (value-by-area mapping), которые мы назвали также картами хороплет. И мы видели, как такие карты могут делаться с использованием выбранных классов или неклассифицированных данных в методе бесклассного картографирования
хороплет (classless choropleth mapping).
В среде ГИС, где можно создавать широкий спектр выходных карт, нам, скорее всего, нужно иметь исходные данные для каждой области, над которыми и выполняются все эти разнообразные функции ГИС. Здесь, однако, нам нужно пересмотреть
классифицированные карты хороплет (classed choropleth map) вследствие той частоты, с
которой нам приходится вводить такие карты для последующего анализа.
Традиционные классифицированные карты хороплет, основанные на парадигме сообщения, хотя и могут быть введены в ГИС, мало полезны в этом контексте из-за методов их разработки. Обычно для определения того, как полигональные категории помещаются на карту, требуются три параметра: размер и форма областей, количество классов и метод определения границы класса. Как вы могли догадаться, чем больше размеры областей картограммы, тем больше данные обобщаются. Так, например, карта провинций и территорий Канады с лишь двумя классами создаст очень обобщенный набор данных,
142
возможно, мало пригодный для дальнейшего анализа средствами ГИС. И наоборот, если бы показывались отдельные округа, и было бы 15 категорий группировки, мы имели бы больше полезной информации, которая с успехом могла бы быть введена в ГИС для анализа. Традиционные картографы стремятся сохранять формы областей похожими насколько это возможно, но эта практика приводит к модификациям данных, оказывающим влияние на наши возможности их анализа. Кроме того, к статистическим данным могут применяться многие методы численной классификации. Они включают последовательности равных интервалов, систематические неравные классовые интервалы и нерегулярные интервалы. Знание использованного подхода даст вам представление о том, как данные организованы, что может оказаться полезным в последующем анализе. Чаще всего, однако, классифицированные карты хороплет плохо подходят для анализа в ГИС, если только мы не получим больше информации связи областей с другими показателями метод, называемый дасиметрическим картографированием.
ДАСИМЕТРИЧЕСКОЕ КАРТОГРАФИРОВАНИЕ
Для улучшения качества карт хороплет для использования в ГИС иногда применяется методика, называемая дасиметрическим картографированием. Поскольку карты хороплет, как классифицированные, так и бесклассные, отражают структуру областей сбора данных, они часто плохо показывают сами распределения. Дасиметрическое картографирование пытается разрушить эту искусственную структуру, чтобы выявить скрытые распределения. Вместо привязки к искусственным (нормативным) единицам сбора данных эти карты отображают области относительной однородности статистических данных. Они используют те же данные, но соотносят этот материал с другими сопровождающими данными или информацией из иных источников. Эти сравнения позволяют улучшить качество исходных карт хороплет за счет удаления границ областей первичного сбора данных.
Пространственные распределения. Введение.
До сих пор мы фокусировались на характеристиках наблюдаемых объектов. Но для правильной оценки окружения нам нужно знать также отношения между отдельными элементами, которые мы видим, и пространством между ними. Теперь мы будем рассматривать не объем пространства, занимаемый объектом, или его форму, а расположение объектов в пространстве, которое может характеризоваться количеством объектов в определенной области, тем, как они распределены равномерно или группами. Мы рассмотрим отношения удаленности между самими объектами и их связь с общим размером занимаемой области.
Распределения могут наблюдаться во многих ситуациях. Мы знаем, например, что некоторые распределения человеческого населения характеризуются большой разбросанностью, подобно фермам в сельской местности. Другие распределения населения больше сконцентрированы в то, что мы называем городами. Растения и животные могут быть распределены равномерно или тоже в более плотные группы. Даже природные объекты, такие как типы отложений и формы рельефа реки и холмы, горы и долины, могут встречаться как отдельно стоящие так и в больших группах. Антропогенные объекты, такие как дороги, ограждения, дома, также могут быть определенным образом расположены. По мере развития нашего географического фильтра мы будем видеть еще больше. Видение того, что существуют различия в пространственном расположении объектов, позволяет нам формулировать вопросы о том, каковы картины этих распределений, как они могут быть классифицированы, и что они могут поведать нам о процессах, их создавших.
143
Если мы повторно посетим места, где впервые наблюдали расположение объектов, будь то в реальном мире или в мире ГИС, то мы увидим, что наблюдаемая картина изменилась. Регионы, которые прежде имели разрозненные распределения, теперь могут демонстрировать признаки группирования. Объекты, которые были когда-то организованы в пространстве случайным образом, теперь встречаются в регулярных, повторяющихся паттернах. Одни паттерны могут проявлять расширение и рост упорядоченности, другие сжатие или деструктуризацию. Области могут сливаться, отдельные линейные объекты — соединяться в сети, установившиеся дюны перемещаться и рассеиваться. Во всех этих случаях время является важной составляющей частью в нашем понимании расположения в пространстве. И вскоре мы задаёмся вопросом: что за процессы вызывают переход от одного распределения к другому? Мы можем задаваться вопросами: каковы могут быть направления изменений, существуют ли движущие силы, которые мы можем понять, каковы могут быть верхние и нижние пределы этих сил, и т.д.
ПРОСТРАНСТВЕННЫЕ РАСПРЕДЕЛЕНИЯ
Пространственное распределение это расстановка, порядок, концентрация или рассеянность, соединенность или бессвязность многих объектов в пределах заключающего их географического пространства. До сих пор рассматриваемые нами методы имели дело главным образом с отдельными объектами или наборами объектов, когда они могли быть определены как регионы, окрестности или представлены как статистические поверхности. Мы лишь очень кратко касались взаимодействия объектов, регионов, поверхностей и окрестностей с аналогичными объектами других покрытий. Но большинство объектов, встречающихся в одном покрытии, тоже имеют определимые характеристики пространственного расположения, которые могут указывать на механизмы их возникновения.
По традиции, термин "пространственное распределение" обычно относится к простому картографическому отображению пространственно распределенных объектов. Исходя из парадигмы сообщения, мы могли бы сказать, что карта показывает, где объекты находятся и каковы очертания занимаемой ими области. Можно было бы сказать, что этого достаточно. Но интуитивно мы понимаем, что есть что-то ещё, помимо того, что может быть использовано для описания взаимодействий каждого отдельного объекта с его соседями и отношения всех этих объектов ко всему пространству, в котором они расположены. И, конечно, если мы сможем найти способы измерения этих отношений, то сможем найти пути выявления и понимания возможных механизмов, которые создают эти распределения.
РАСПРЕДЕЛЕНИЯ ТОЧЕК
Возможно, наиболее распространенные методы анализа пространственных распределений применяются к точечным паттернам. Точечными объектами могут быть отдельные деревья, дома, животные, фонари и даже города, в зависимости от масштаба (Рисунок 18.1a). Как мы увидим в дальнейшем, точечные объекты могут также представляться в виде линий и областей (Рисунок 18.1b).
144

Рисунок 18.1. Точечное и площадное представление городов. Площадные объекты, в данном случае города,
могут рассматриваться как точки (а) или как области (Ь), в зависимости от масштаба, в котором они представлены. Это указывает на связанность аналитических методов, которые могут применяться.
Простейшей мерой точечного распределения является плотность (density) точек. Она определяется как результат деления числа точек на общую площадь, на которой они расположены. Плотности населения, застройки, деревьев и т.д. широко используются как меры компактности точек. Сравнивая плотности подобных объектов в разных областях, мы можем сравнивать механизмы, которые действуют в этих областях. Или мы могли бы сравнивать точки в том же месте, но в разные моменты времени, чтобы увидеть изменения плотности во времени. Например, мы могли бы обнаружить, что плотность населения в городской местности со временем растёт, или что растёт плотность застройки, или что плотность деревьев снижается по мере их развития и роста конкуренции за пространство и солнечный свет. Даже этот простой статистический показатель, легко вычисляемый на растре и векторах, может дать нам множество полезных идей о наших данных.
Помимо общей плотности распределения, нас может интересовать еще и его форма. Точечные паттерны встречаются в одном из четырех возможных вариантов, характеристик. Распределение является равномерным (uniform), если число точек на единицу площади в каждой малой подобласти такое же, как и в любой другой подобласти. Если точки расположены в узлах сетки, разделенные одинаковыми интервалами по всей области, то равномерное распределение называется регулярным (regular), подобно рассмотренной ранее регулярной сетке отбора точек данных на поверхности. В других случаях равномерно распределенные точки располагаются в случайном (random) порядке по всей рассматриваемой области.
Бывают случаи, когда точки собраны в тесные группы, такое распределение называется сгруппированным или кластерным.
Анализ квадратов
Равномерные точечные распределения определяются на основе отношений между одинаковыми подобластями, называемыми квадратами (quadrats). Это очень распространенный метод анализа дискретных зоологических и агрономических данных. Точками здесь могут быть отдельные растения, муравейники и т.д. Если каждый квадрат содержит примерно одинаковое число точек, то распределение является равномерным. Равномерные распределения редко встречаются среди биологических явлений, так как живым организмам свойственно мигрировать в сторону большей концентрации питательных веществ, лучшего орошения, определенного типа почвы и т.д. Если распределение
145
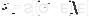
действительно равномерное, то мы можем предположить, что нет существенного механизма, управляющего расположением объектов.
В стандартном методе анализа квадратов (quadrat analysis) [для равномерного распределения] мы предполагаем, что примерно одно и то же число объектов будет находиться в каждой подобласти, равное общему числу объектов, поделённому на количество подобластей. Для проверки равномерности распределения может использоваться относительно простой статистический показатель, который называется критерием χ2 (хи- квадрат)(chi-square test) и выражается формулой:
где Q наблюдаемое число точек в квадрате, Е ожидаемое число точек в квадрате; суммирование проводится по всем квадратам.
Результат этого вычисления может быть сравнен с табулированными критическими величинами. Если полученное число незначительно отличается от ожидаемого, то распределение является равномерным; заметное отличие говорит о некоторой неравномерности, что может означать наличие какого-то процесса, лежащего в основе неравномерности. Хотя этот метод может считаться чисто статистическим, он может быть реализован в некоторых ГИС, особенно в растровых. Такой анализ могут выполнять и многие специализированные программы. Достаточно помнить, что чем больше значение χ2, тем ниже равномерность распределения.
Хотя результатом анализа в ГИС обычно считается карта, в данном случае результатом является одно лишь число. Здесь уместен такой вопрос: "Если распределение не равномерно, то какой механизм может быть ответственен за это?"
Чаще всего наблюдаемые нами точечные паттерны связаны с другими показателями (покрытиями) карты той же области исследования. Эти возможно связанные покрытия могут быть не только точечными, но и площадными. В нашем примере с биологией это могли бы быть параметры почв.
Помимо информации о равномерном распределении анализ квадратов может дать коечто ещё. Например, отношение дисперсии к среднему (математическому ожиданию). Здесь также используется критерий χ2, который вычисляется как произведение отношения дисперсии к среднему на число подобластей за вычетом одной. Высокие значения χ2 указывают на большой разброс между числом точек в каждой области и средним для всей области, то есть на то, что мы имеем кластерное (групповое) распределение. И наоборот, малые значения χ2 означают, что распределение более равномерное. Промежуточные значения указывают на то, что распределение более тесно связано с некоторым случайным процессом, где некоторые квадраты имеют несколько большее, а другие несколько меньшее число, чем среднее.
Как и раньше, результаты анализа говорят, что если распределение не является статистически случайным (т.е. если оно либо равномерное, либо кластерное), то вы можете попытаться определить возможную причину, разумно выбрав набор показателей для сравнения с вашим точечным покрытием. Например, равномерные распределения могут быть регулярными, как плодовые деревья в саду, или случайными, что более свойственно деревьям в лесу. В первом случае в каждой подобласти будет встречаться одинаковое число точек, во втором случае числа будут разными.
Анализ ближайшего соседа
До сих пор мы описывали точечные распределения количеством точек в пределах подобластей. Другими словами, мы рассматривали распределение точек посредством сравнения областей, которые они занимают. Однако, также поучительно рассмотреть
146

локальные отношения внутри пар точек. Чаще всего это делается другим методом анализа точечных распределений анализом ближайшего соседа (nearest neighbor analysis),
общепринятой процедурой определения расстояния от каждой точки до ее ближайшего соседа (РБС) и сравнения этой величины со средним расстоянием между соседями. Вычисление этого статистического показателя включает определение среднего РБС среди всех возможных пар близко лежащих точек (такие точки определяются как ближайшие к выбранной).
Среднее РБС дает меру разреженности точек в распределении. Это ценно само по себе, так как в некоторых случаях точечные объекты могут конфликтовать, если они расположены слишком близко друг к другу. Например, мы знаем, что многим животным требуется определенное жизненное пространство, и когда оно перекрывается с пространством другого представителя того же вида, возможен конфликт.
Но, как и в анализе квадратов, мы можем сравнить среднее РБС с тремя возможными распределениями — регулярным, случайным и кластерным. Этот метод может быть описан в общем [детально см. McGrew and Monroe, 1993] для каждого из этих случаев как вычисление индекса, с которым вы можете сравнить свои результаты, как это указано далее. Для индекса случайного распределения поделите 1 на удвоенный квадратный корень из плотности точек (число точек на единицу площади). Если вам нужен критерий максимальной рассеянности (dispersion) (регулярное распределение), то поделите 1.07453 на квадратный корень из плотности точек. Наконец, для критерия максимальной сгруппированности, когда точки расположены одна под другой, мы можем просто принять, что величина получается делением на ноль (the value is of the divisor 0). В результате мы получаем некоторое неотрицательное значение индекса.
Простое сравнение вашего среднего РБС с тремя индексами даст вам понятие о том, в каком месте диапазона они находятся. Давайте рассмотрим, как это работает на примере данных Таблицы 11.1 и Рисунка 11.2. У нас есть шесть точек, данных в пределах площади в 25 квадратных единиц. Среднее РБС этих данных составляет примерно 1,4. Для случайным образом распределенных данных индекс составит (единица, поделенная на удвоенный корень из плотности точек (6 точек на 25 единиц площади = 0.24), т.е. 1/(2  0.24 ) = 1.02. Наше среднее РБС несколько больше, чем этот индекс.
0.24 ) = 1.02. Наше среднее РБС несколько больше, чем этот индекс.
Таблица 11.1. Вычисление расстояния до ближайшего соседа
Точка |
Координаты |
Ближайший |
РБС |
|
|
X |
Y |
сосед |
|
A |
0.7 |
1.0 |
B |
1.6 |
B |
1.25 |
3.0 |
C |
1.4 |
C |
2.5 |
3.7 |
D |
1.3 |
D |
3.3 |
2.75 |
C |
1.3 |
E |
4.0 |
4.0 |
C |
1.34 |
F |
3.8 |
1.0 |
D |
1.5 |
|
|
|
|
8.44 |
СреднееРБС |
|
|
|
1.4 |
Случайное среднее РБС |
|
|
1.02 |
|
Критерий максимальной рассеянности точек составит 1.07453, поделенное на квадратный корень из плотности точек, т.е. округленно 2.19. Таково было бы значение, если бы наше распределение точек было идеально равномерным. Наше среднее РБС намного меньше этого, но и намного больше, чем 0, который соответствует идеально сгруппированному распределению. Таким образом, мы нашли, что наше распределение несколько более рассеянное, чем случайное, или где-то между истинно равномерным и случайным. Другими словами, оно начинает принимать более регулярную конфигурацию, но пока все еще довольно случайное.
РБС является абсолютным статистическим показателем, следовательно, он не может непосредственно сравниваться с РБС других точечных распределений. Индекс ближайшего
147
соседства может быть нормализован для выполнения таких сравнений. Существуют также и другие методы определения кластеризации, основанные на других статистических показателях.
Рисунок 11.2. Координаты точек для определения РБС. Каждая точка (например, точка А) имеет своего ближайшего соседа (в данном случае, точка В). Расстояния определяются с помощью теоремы Пифагора (см. Таблицу 11.1).
148
Лекция № 19 ПОЛИГОНЫ ТИССЕНА
Точечные распределения могут также характеризоваться с помощью полигонов Тиссена (Thiessen polygons) (называемых также диаграммами Дирихле (Dirichlet diagrams)
и диаграммами Вороного (Voronoi diagrams)). Они основаны на идее, что мы можем нарастить полигоны вокруг точек, чтобы показать их возможные зоны влияния на другие точки покрытия. Например, как мы увидим при работе с моделью гравитации, можно считать, что между точками действуют силы притяжения.
Вдобавок, размер точки например, города часто напрямую связан с силой такого влияния. Мы ограничимся случаем равной величины всех точек, что упрощает описание.
Создание полигонов Тиссена довольно просто концептуально, но может стать запутанным, если количество точек велико. Чтобы понять, как их строить, давайте вначале разберемся, что эти фигуры должны представлять. Если у нас есть несколько точечных объектов, таких как города (опять же, одного размера), мы можем представить себе, что каждая точка окружена одиночным неправильным многоугольником. Но многоугольник имеет одно важное свойство любая точка внутри него находится ближе к очерченной точке, чем любая другая точка покрытия. И наоборот, каждая точка вне полигона ближе к некоторой иной, нежели к очерченной. Другими словами, граница каждого полигона дает окружаемой точке наименьшую возможную область влияния. Каждая точка покрытия будет иметь свой собственный полигон Тиссена, показывающий область исключительно ее влияния
Возьмем простой набор точек (Рисунок 19.1). Образование полигонов Тиссена можно представить как результат роста мыльных пузырей с центром в каждой из точек. В конце концов границы пузырей превращаются в прямые линии, а сами пузыри - в многоугольники. Стороны этих многоугольников ориентированы перпендикулярно линиям, соединяющим соседние точки. Причем длины двух отрезков, получившихся с обеих сторон границы, одинаковы.
Рисунок 19.1. Создание полигонов Тиссена. а) расположение точек; b) построение связанных с ними полигонов
Тиссена.
149
Алгоритмы создания полигонов Тиссена разрабатывались на протяжении десятилетий как для систем компьютерной картографии, так и для ГИС, как векторных, так даже и на структуре данных квадродерева [Mark, 1987].
Зачем же нужны полигоны Тиссена? Они названы в честь климатолога Тиссена (А.Н. Thiessen), который пытался проинтерполировать сильно неравномерные распределения климатических данных. Иначе говоря, он пытался описывать и анализировать точечные данные с помощью площадных символов и аналитических методов. Таким образом, если у нас есть несколько разбросанных точек, и мы хотим охарактеризовать регионы, основанные на этих точках, то используем полигоны Тиссена. Поскольку мы считаем, что в каждом полигоне влияние очерченной точки абсолютно, мы можем обращаться с этими данными как с полигональным покрытием.
Большинство случаев применения полигонов Тиссена связано с определением влияния точечных данных, представляющих торговые центры, фабрики или другие объекты экономики. Если мы изменим, положение общей границы смежных полигонов в зависимости от размера или иного параметра очерчиваемых ими точек, то полученное разбиение будет еще лучше представлять реальное влияние объектов на окружающее пространство. Имея такую информацию, специалист по экономическому размещению может определить, например, какая часть населения города (на основе близости) скорее всего будет регулярно посещать планируемый торговый центр. Полигоны Тиссена используется не только в экономической географии, но и, например, при выявлении пространственных распределений растительности. На самом деле, использование этой методики скорее всего будет расти с расширением функциональных возможностей ГИС и известности среди пользователей.
РАСПРЕДЕЛЕНИЯ ПОЛИГОНОВ
Мы можем начать анализировать распределения областей во многом подобно тому, как мы делали это с точками - через определение плотности полигонов на единицу площади нашей области изучения. Однако, при определении меры плотности полигонов мы должны вначале измерить площадь полигонов каждого класса, из тех, что интересуют нас. Затем мы делим суммарную площадь каждого типа полигонов (т.е. каждого региона) на общую площадь покрытия. Это дает относительную долю полигонов, а не число их на единицу площади. Возможно, конечно, подсчитать число полигонов (или групп ячеек растра) на единицу площади, но из-за возможности широкого варьирования их размеров данный подход вряд ли будет полезен.
Опять же, помимо плотности полигонов, нас может интересовать расположение и формы распределений, создаваемые группами полигонов, которые могут подсказать причины таких расположений. Примерами потенциально взаимодействующих полигонов могут быть усовершенствования в методах вспашки в некоторых хозяйствах, города, поселки и перемещение товаров и услуг внутри них и между ними, и даже водные источники, распределенные по территории, которая могла бы предоставить хорошие места для зимовки птиц. Но перед тем, как рассматривать взаимодействия полигональных объектов, мы должны узнать кое-что о том, как они могут быть расположены. Как и точки, области могут быть сгруппированы, рассеяны (регулярно), или случайным образом разнесены по отношению друг к другу (см. Рисунок 2.8). Кроме этого, площадные объекты могут быть соединены друг с другом, или удалены на некоторые определимое расстояние.
СТАТИСТИК СОЕДИНЕНИЙ
При работе с полигональными покрытиями мы будем нередко создавать бинарные карты (binary maps), т.е. такие, на которых имеются только две категории полигонов, чаще всего таких, которые характеризуют некоторый показатель как хороший или плохой для искомого решения. Например, могут быть плохие и хорошие почвы для пропашных культур, хорошие и плохие уклоны для строительства, хорошие и плохие аспекты для
150