

Лекции ГИС1
.pdfПоскольку он связан с положением, формой и ориентацией объекта, мы можем легко отнести буферизацию к методам переклассификации на основе положения. Однако, буфер может быть больше чем только отмеренное расстояние от двухмерного объекта; он может быть также связан с, и даже управляться, присутствием поверхностей трения, рельефа, барьеров, и т.д. То есть, хотя буферизация основана на положении, она имеет также и другие существенные компоненты. Область, окружающая реку, которая сообщает что-то о коридоре реки, является примером буфера. На Рисунке 16. буфер был создан переклассификацией области на обеих сторонах для отличия его от аморфного фона. Хотя рисунок показывает и реку, и буфер, обычно буфер создается как отдельный объект и часто хранится в отдельном покрытии. Для создания такого буфера требуется всего лишь отсчет заданного расстояния по всем направлениям от каждой точки границы выбранного объекта. Мы знаем, как ГИС выполняет измерение расстояний в растре и векторах; в действительности, создание буферавсего лишь расширение этой процедуры. Но поскольку эта процедура весьма полезна и часто применяется, большинство ГИС имеют специальные команды для построения буферов.
Буферизация — дело измерения расстояния от объекта, будь то точка, линия или область. В случае точки мы отмеряем одно расстояние по всем направлениям от этой точки (Рисунок 16. ). Буфер линейного объекта показан на Рисунке 9.6. Буфер площадного объекта строится на заданном расстоянии от его периметра. Может даже понадобиться построить второй буфер вокруг первого, третий — вокруг второго и т.д., которые вместе называются многослойным буфером (doughnut buffer), который также показан на Рисунке 16. . Процедура его построения относительно проста, так как каждый новый слой буфера - всего лишь новый буфер вокруг предыдущего слоя.
Рисунок 9.7. Буферы точек и областей. Показан также многослойный буфер точки.
В векторных системах мы должны явно закодировать топологическую информацию для каждого вновь создаваемого полигона. В частности, от нас требуется предоставить топологическую информацию о связях между полигонами. Процедура многослойной буферизации пытается создать островной полигон, который не соединен явно с соседним полигоном. Трудность создания многослойного буфера в векторной системе — в основном следствие используемой модели данных, но, следуя указаниям программы, вы, как правило, можете его получить. Возможно, вам стоит поэкспериментировать на тестовой БД перед тем, как создавать многослойные буферы в реальной работе.
121
Теперь обратимся к вопросу о величине буфера: насколько широким он должен быть? Этот вопрос часто возникает на семинарских занятиях, когда студентов просят создать буфер вокруг некоторого объекта. К сожалению, часто следует ответ: "Это не важно, вам просто нужно попробовать создать буфер". Но: как мы видели, просто создание буфера не многого стоит, если вы не знаете зачем и какой величины. В действительности, цель создания часто если не определяет размер буфера, то, по меньшей мере, влияет на него.
Так какого же размера должен быть буфер? Некоторые буферы показывают, что вокруг объекта, на неизвестное, или даже не могущее быть известным, расстояние простирается регион, который требует защиты, исследования, охраны или иного особого обращения. Такой сценарий не так уж необычен, как можно подумать. Многие буферные зоны в реальном мире так же произвольны, как и те, что мы устанавливаем в наших ГИС. Строители обычно сами создают буфер вокруг стройплощадки, чтобы защитить прохожих от тяжелых машин и падающего строительного мусора. Границы областей, загрязненных ядовитыми газами, радиоактивными материалами, разливами опасных жидкостей обычно устанавливаются правительственными агентствами или правоохранительными органами. Но довольно часто эти зоны устанавливаются лишь предположительно, это произвольные буферы (arbitrary buffers). Чаще всего предположения строятся на интуиции или дилетантской информации из неизвестных источников.
Однако, все они, как правило, больше, чем необходимо. Лишняя площадь буфера, часто так мешающая населению, обычно добавляется к произвольному буферу для безопасности.
Размеры буфера могут также основываться на любой процедуре измерения или переклассификации, которые нам до сих пор встречались, будь они двухмерные или трехмерные. Например, мы могли бы создать другой тип буфера, основанного на функциональном, а не евклидовом расстоянии от объекта. Это был бы мотивированный буфер (causative buffer) — основанный на априорном знании площади буфера. Допустим, например, что мы создаем буфер вдоль реки, чтобы показать возможность загрязнения почвы по обеим ее сторонам. И мы знаем, что с одной стороны реки почва — глинистая, в то время как на другой песчаная. Поскольку загрязняющие вещества проникают через песок быстрее, чем через глину, буфер должен строиться на основе фрикционных или импедансных свойств (frictional or impedance quality) глинистой почвы. В результате буфер будет менее широким со стороны глины, нежели со стороны песка, отражая различия в проницаемости почв разных типов. Использование фрикционных поверхностей и барьеров - обычная практика при построении буферов, так как они дают некоторое основание для выбора размера буфера. Однако, поскольку точное определение величины фрикционного или барьерного импеданса часто затруднительно, буфер, построенный на основе этой величины, может оказаться не более полезным, чем произвольный буфер, построенный из простых соображений.
Буфер может также быть основанным на мерах взаимной видимости. В таком случае буфер выбирается не на основе произвольной или плохо известной фрикционной величины, а на основе определенной, измеримой величины, это - измеримый буфер (measurable buffer). Это третий тип буферов, который мы можем использовать. Измерения не произвольны, а весьма точны, так как основаны на измеримых феноменах. Конечно, всегда есть возможность комбинирования второго и третьего методов буферизации, полагаясь на измеримый феномен, чье влияние на размер буферной области трудно четко определить. Например, мы знаем, что деревья вдоль речного коридора могут играть роль фильтра от загрязняющих материалов. Мы также знаем, что чем больше деревьев, тем лучше фильтрация. Поэтому, мы можем измерить плотность растительности вдоль речного коридора и затем использовать эти значения для создания поверхности импеданса, а уже ее использовать для определения размера буфера. Но при этом мы не имеем точного знания о том, как плотность деревьев связана с движением загрязнителя через растительность в реку.
122
Таким образом, у нас есть некоторые измеримые параметры, и они могут быть логично применены; но при этом мы не знаем точных отношений между ними. Такое часто случается при построении буферов.
Существует еще четвертый вид буферов нормативный (mandated buffer), когда буферизация определяется нормативными актами. Например, если вы строите дом в пределах столетней зоны наводнений, то, скорее всего не сможете приобрести страховку от наводнений. Хотя размер этой зоны измеримая величина, страховая компания могла бы так же легко избрать 75-летнюю зону или 150-летнюю.
Другими словами, сама величина измерима, но выбор ее среди других измеримых величин произволен. Для создания буфера подобного рода обычно нужна БД местности и возможность рассчитать объем воды, который заполнил бы пойму, если бы действительно случилось наводнение такого масштаба, который вряд ли имеет место более одного раза в столетие.
Но могут применяться и другие нормативные буферы. Нам говорят, насколько близко к пожарному гидранту мы можем парковать машину, и какая часть палисадника в действительности принадлежит местному сообществу. Строительные нормы указывают расстояния вокруг объектов коммунальных служб и между зданиями; природоохранные организации создают защитные полосы; вдоль железных дорог и линий электропередачи по закону устанавливаются буферы отчуждения, и т.д. В каждом случае есть нормативное основание для создания буфера определенного размера.
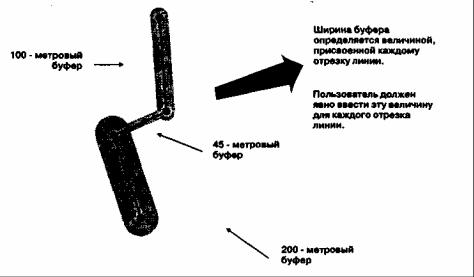
Рисунок 16. Варьируемый буфер. Такие буферы создаются с помощью различных значений импеданса с каждoй стороны линии или указанием своей ширины буфера для каждого отрезка линии. Во втором случае каждый отрезок должен иметь идентифицирующие узлы на каждом конце (в векторной системе); или для каждого набора образующих объект ячеек растра должно отмеряться свое расстояние до границы буфера (в растровой системе).
Независимо от типа буфера (произвольный, мотивированный, измеримый или нормативный) всегда есть вероятность того, что буфер не будет иметь одинаковую ширину вдоль всего линейного объекта или со всех сторон полигона. Такие различия, проиллюстрированные нашим примером буфера разной ширины вдоль реки в зависимости от типа почвы, создают класс буферов, называемых варьируемыми (variable buffers) (Рисунок 16. ). Варьируемый буфер может определяться импедансом, барьерами или любой другой функцией окрестности. Он может выбираться произвольно, на основе измеримого параметра ландшафта, или устанавливаться законом. В каждом случае при создании буфера должны выполняться специальные процедуры. В векторной модели данных узлы между отрезками линии чаще всего могут использоваться для установления различий буфера вдоль линии. В
123
растре ячейки должны выборочно кодироваться, чтобы можно было устанавливать буфер для каждой группы ячеек; чаще всего эти буферы позднее объединяются в отдельное буферное покрытие.
Буферы полезны для классификации ландшафта и являются обычной составной частью многих случаев анализа в ГИС. Основная проблема с буферами состоит в том, что они часто требуют от нас больше знаний о взаимодействии элементов нашего ландшафта, чем мы имеем. Вы всегда должны пытаться преодолеть это препятствие поиском всех возможных знаний о каждой ситуации перед тем, как двигаться дальше. Чем больше вы знаете, тем более надежен ваш выбор определенной ширины буфера. Если же у вас недостаточно сведений для выбора размера буфера, то лучше сделать его с запасом.
124
Лекция № 17 Статистические поверхности
До сих пор мы концентрировались на точечных, линейных, и площадных объектах, но мы делали частые ссылки также и на поверхностные объекты. Поверхности часто используются для моделирования импеданса. Они могут представлять уклоны и экспозиции, а также области видимости и конкретные объекты наподобие долин, холмов и водоразделов. Но поверхности, с которыми мы столкнемся, не всегда будут топографическими. Мы можем различать поверхности, которые являются непрерывными или дискретными, гладкими или неровными, природными или антропогенными. Другими словами, наше определение поверхностей расширится, чтобы включить данные любого типа, которые либо существуют, либо могут подразумеваться существующими как изменяющиеся величины по всей области.
Конечно, топографическая поверхность понимается легко, и в этой главе мы часто будем встречать рельеф местности в качестве классического типа поверхности. Поскольку значения высот существуют для каждой точки Земли, мы говорим, что такая поверхность непрерывна. Однако, когда мы пытаемся записать эту информацию, имея в виду создание обоснованных и количественно определимых описаний, мы обнаруживаем проблему, аналогичную попытке описать все деревья в лесу или все травинки на лугу, данных так много, что мы просто не можем записать полный набор. Поэтому, как и прежде, мы должны произвести осмысленный отбор значений высоты, из которых мы смогли бы реконструировать топографию с заданной точностью. Имеется большое сходство между топографическими поверхностями и распределениями атмосферного давления, температуры и влажности это непрерывные поверхности. Их значения также непрерывно распределены, но мы не можем регистрировать их в каждой точке. Вместо этого мы выбираем отдельные точки для представления всего распределения. Мы познакомимся с тем, как это делается, чтобы гарантировать адекватную запись наших наблюдений.
В то время как даже непрерывные поверхности представляют определенные проблемы для исследователя, многие другие объекты не распределены непрерывно по всей области исследования; наоборот — они встречаются как дискретные объекты в определенных местоположениях. Но поскольку они встречаются очень часто, или потому что мы хотим регистрировать их на очень большой площади, эти дискретные данные также должны подвергаться частичной выборке.
Независимо от того, являются ли наши данные, представленные поверхностями, дискретными или непрерывными, их важность трудно переоценить. Первые ГИС создавались на основе моделей данных, разработанных для явлений, связанных с поверхностями (как, например, моделирование загрязнений). Современное специализированное программное обеспечение, часто связанное с ГИС, разрабатывалось для выполнения разнообразных операций представления данных, моделирования поверхностей, расчета объемов на основе поверхностей. Сейчас имеются огромные объемы поверхностных данных в форме, совместимой с ГИС, особенно связанные с рельефом и климатом. Со временем объем поверхностных данных будет расти со все большей скоростью по мере того, как будет все более очевидной важность анализа поверхностей.
Вследствие высокой важности и доступности поверхностных данных важно рассмотреть данную тему в отдельности, несмотря на ее включение в предыдущие главы. Мы изучим виды данных, которые могут быть использованы в поверхностном моделировании, различные модели поверхностей, которые могут применяться для их отображения, узнаем, как предсказывать отсутствующие данные поверхности и как эти результаты могут использоваться в принятии решений. Мы также рассмотрим некоторые распространенные типы данных, представленных поверхностями, узнаем, как они были
125
созданы, как мы можем использовать их в своей работе, как их можно преобразовывать в модели данных различных типов. И мы увидим, как можно создавать поверхностные данные по точечным наблюдениям разнообразных природных и антропогенных феноменов, чтобы поднять их ценность для моделирования.
Если ваш интерес в ГИС связан с моделированием, планированием, принятием решений или просто разработкой баз данных, вам необходимо знакомство с данными и методами для создания, изменения и моделирования поверхностей. Если ваш интерес к этим данным обусловлен использованием их в собственной работе, применимость этой главы, возможно, более очевидна, чем для тех, кто будет работать над созданием баз данных для других. Для второй группы важно понимание того, когда и почему данные должны представляться в этом формате.
ЧТО ТАКОЕ ПОВЕРХНОСТЬ?
Поверхности это объекты, которые чаще всего представляются значениями высоты Z, распределенными по области, определенной координатами X и Y. Параметр Z чаще всего ассоциируется с высотой рельефа местности, но не обязательно. На самом деле, любые измеримые величины, которые могут встречаться на определенной территории, могут рассматриваться как образующие поверхность. Обычно используется термин "статистическая поверхность" (statistical surface), поскольку значения параметра Z часто можно трактовать как статистическое представление величины рассматриваемых явлений или объектов. Возможно потому, что статистические поверхности расширяют наш географический фильтр включением таких параметров, как плотность населения, доход, плотность животных, атмосферное давление, они рассматриваются как одни из наиболее важных картографических концепций.
За статистическими поверхностями стоит идея о том, что Z-величина либо непрерывна по интересующей нас области, либо может считаться непрерывной в целях моделирования и картографирования. Статистические поверхности, образованные величиной, определенной во всех точках изучаемой области, называются непрерывными (continuous). Те же, что встречаются только индивидуально, но с некоторым различием в числе на единицу площади (такие, как число домов на квадратный километр в каждой окрестности), называются дискретными (discrete). Понимание статистических поверхностей этих двух типов может оказаться сложным, поэтому мы рассмотрим их по отдельности.
Говорят, что непрерывные данные присутствуют в каждой возможной точке области. То, есть, существует возможность получения отсчета этой величины на сколь угодно малой площади где угодно в рассматриваемой области. Мы знаем, например, что температура имеется повсюду. Мы можем измерить ее в любой точке. Если мы это сделаем, то увидим, что она постепенно меняется от точки к точке непрерывной последовательностью. В некоторых случаях эти изменения невелики, возможно, менее чем на одну десятую градуса через 100 метров. Мы говорим, что имеем дело с гладкой поверхностью (smooth surface), с небольшим изменением статистической информации на единицу расстояния. Однако, в других случаях, например, когда мы пересекаем границу между двумя совершенно различными воздушными массами, значения температуры меняются очень резко. Такую поверхность мы называем неровной (rough), поскольку имеется резкое изменение статистических данных на небольшом расстоянии.
Определение статистической поверхности как непрерывной означает, что имеется бесконечное количество точек, в каждой из которых может быть свое значение. Однако, провести измерения в бесконечном числе точек физически невозможно, также как невозможно хранить бесконечный объем данных. Поэтому определение непрерывной поверхности с помощью бесконечного числа точек должно быть заменено моделью, которая использует существенно важные отсчеты (samples) рассматриваемой величины. Эти отсчеты представляют наиболее важные изменения поверхности как упрощенное представление.
126
Изображение поверхностей на картах
Статистические поверхности могут представляться посредством плотности точек, хороплет, дасиметрии и изолиний. Четвертый метод наиболее часто используется для непрерывных данных, хотя он может использоваться и для дискретных данных, если принять, что они являются непрерывными.
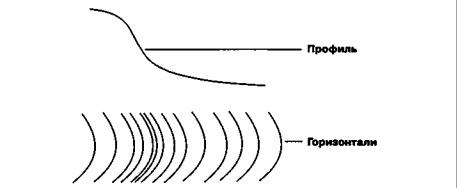
При взгляде сверху изолинии выглядят как последовательность непересекающихся линий. Если они представляют топографический объект, такой как холм, то они замкнуты и очерчивают объект; если нет, то продолжаются до краев карты. То, что мы видим, есть линейные символы для отображения поверхностных данных. Более того, они позволяют нам наблюдать конкретные формы рельефа местности. Например, горизонтали, пересекающие речные долины, обычно выглядят как буква V, указывающая вверх по течению; на крутых склонах горизонтали расположены более плотно по сравнению с пологими склонами. Мы говорили прежде о классификации на основе уклона.
Мы можем обнаружить другой важный аспект изолиний, посмотрев еще раз на Рисунок 10.1. Расстояние по вертикали между любыми горизонталями одинаково, и это не случайно.
Рисунок 10.2. Расстояние между горизонталями и конфигурация поверхности. Более крутой уклон показывается более часто следующими горизонталями.
Расстояние по вертикали выбирается таким, чтобы читающему карту было легче понимать, что эти линии представляют. Каждая карта имеет собственное вертикальное расстояние между горизонталями, в зависимости от быстроты изменения высоты. Эта установленная величина, называемая интервалом между изолиниями (contour interval), используется для деления (или квантования) изменения Z-величины на равные интервалы высот. Если бы мы использовали разные интервалы между соседними горизонталями, то не смогли бы интерпретировать частоту их следования как показатель уклона.
ВЫБОРКА СТАТИСТИЧЕСКИХ ПОВЕРХНОСТЕЙ
Существуют два основных метода получения Z-значений поверхности. Первый использует отобранные точки, и в этом случае карта изолиний называется изометрической (isometric). Этот метод наиболее часто применяется к построению горизонталей. Он также используется при создании карт атмосферного давления, температуры и других, получаемых на основе данных метеостанций, расположенных в определенных точках по всему земному шару. Но мы можем также работать и с данными, представляющими не точки, а небольшие области. Вспомним пример с численностью населения округов США. Хотя мы знаем, что эти
127

данные — дискретные, при желании мы можем обращаться с ними как с непрерывными. Так что, предположив, что каждый из этих округов является точкой, мы можем создать карту изолиний такого же типа, как и в случае измерения параметра в отдельных точках. Изоритмами называются "истинные" изолинии (они же изометрические линии), т.е. линии равных значений непрерывной статистической величины. Существуют также изоплеты линии равных значений дискретной статистической величины, они называются также псевдоизолиниями, так как между ними статистическая величина может изменяться скачком или быть неопределена. Внешне те и другие выглядят одинаково, но суть их различна. Изоплетами обычно изображаются вычисляемые, а не измеряемые непосредственно величины.
Этот тип карт, называемых картами изоплет (isoplethic map), требует от нас определения положений этих точек. Центроиды, которые могут использоваться в качестве таких точек, мы уже рассматривали.
Вслучае изоплетных карт существуют два подхода к выбору точек измерений.
Первый называется регулярной сеткой (regular lattice, regular grid), так как точки расположены в узлах решетки, образованной прямыми линиями (Рисунок 10.За). Регулярная сетка имеет преимущество простоты, когда не требуется задумываться о выборе точек измерения. Правда, существует некоторая сложность в выборе интервала между точками, так как поверхности могут быть как сильно пересеченными, так и сравнительно гладкими. В первом случае говорят о большем количестве информации на единицу площади, поскольку каждое изменение высоты является потенциальным элементом информации о форме поверхности. С увеличением плотности поверхностной информации требуется и большая плотность точек измерений. А это ведет нас ко второму методу отбора точек, основанному на нерегулярной сетке (irregular lattice).
Вслучае нерегулярной сетки мы определяем плотность точек на основе априорного представления о гладкости поверхности. Здесь мы не фиксируем плотность точек ни по горизонтали, ни по вертикали. Нет ограничения и по количеству точек в любой заданной области. Хотя может показаться, что отсутствие ограничений приведет к росту числа точек измерений. На самом деле это не обязательно так.
Рисунок 17. Регулярная (а) и нерегулярная (b) сетки. Точки могут быть как самими местами измерений, так и представителями данных в БД ГИС.
Мы можем получить хорошую модель поверхности при меньшем числе точек, уменьшая их плотность на относительно гладких участках по сравнению с тем, что требовалось бы при использовании регулярной сетки. Более высокая плотность точек на таких участках не дает по существу новой информации, а только приводит к ненужному расходу времени и сил на сбор данных, а также места для их хранения.
128
ЦИФРОВЫЕ МОДЕЛИ РЕЛЬЕФА
Определив процедуры выбора точек измерений, нам нужно понять, как поверхность может быть представлена внутри компьютера, как в растровых, так и в векторных системах. Мы уже имели дело с моделью нерегулярной триангуляционной сети (TIN), однако она является лишь одним из способов представления Z-величин в компьютере, вместе образующих группу "цифровых моделей рельефа" (ЦМР) (digital elevation models (DEMs)). Хотя математические модели весьма полезны, большинство имеющихся сегодня ЦМР являются моделями изображения( ! ). Модели изображения бывают двух типов: основанные на точках и основанные на линиях.
Модели изображения на основе линий — почти что графический эквивалент традиционного метода карт изолиний. Во многих случаях такие модели создаются сканированием или оцифровкой существующих изолиний. Целью является извлечение формы поверхности из имеющихся линий, которые ее представляют. После ввода эти данные представляются либо как линейные объекты, либо как полигоны с определенной высотой в качестве атрибута. Поскольку на такой модели данных неудобно определять уклон, экспозицию или создавать отмывку рельефа, обычно ее преобразуют в точечную модель. В результате получается то, что называют дискретной матрицей высот (discrete altitude matrix).
Эта матрица соответствует методу точечного изображения поверхности, где каждая точка несет одно значение высоты. Это в чем-то похоже на точечную дискретизацию непрерывной поверхности. Матрица высот использует множество точек, отобранных из стереопар или аэрофотоснимков, с применением цифровых фотограмметрических станций. Можно использовать регулярную или нерегулярную сетку. Поскольку регулярная сетка приводит к избыточности данных на участках с минимумом топографической информации и недостатку данных на участках с большим объемом топографической информации, нерегулярная сетка более предпочтительна.
Нерегулярные сетки могут быть преобразованы в модель TIN двумя способами. Первый заключается в использовании самих точек сетки в качестве вершин треугольных граней TIN. Его достоинство — в отсутствии требования ввода дополнительных данных. Во втором подходе расстояния между точками и их значения высот используются при интерполяции (interpolation) значений вершин регулярной матрицы треугольных граней
TIN.
ЦМР легко могут быть получены для многих частей мира как матрицы высот с сетками 63.5 м, полученными с топографических карт масштаба 1:250'000; появляются и сетки с карт более крупного масштаба, таких как 1:25'000, и аэрофотоснимков. Среди преимуществ ЦМР, полученных с помощью интерполяции с созданием регулярной матрицы, является легкость ввода в растровые ГИС. ЦМР, целиком, основанные на нерегулярной сетке, при вводе в растровые ГИС должны будут подвергаться растровой интерполяции.
РАСТРОВЫЕ ПОВЕРХНОСТИ
В растровой модели данных каждая ячейка может иметь только одно значение высоты. По сути, это приводит к тому, что непрерывная пространственная величина получает дискретное представление. Помимо того, что каждая ячейка растра имеет только одно значение высоты, она еще и занимает некоторую площадь, с увеличением которой снижается точность представления поверхности в растровой модели данных.
Таким же важным, как и размер ячейки, является вопрос о том, где в ее пределах находится реальная точка присвоенной ячейке высоты. Вы можете указать это положение: центр ячейки или один из четырех ее углов. При анализе топографических поверхностей выбор этих точек будет иметь влияние на результаты вычислений.
Если бы ячейки были закодированы так, что значение высоты относилось к одному из четырех углов, то вычисленные расстояния были бы смещены по меньшей мере на половину
129
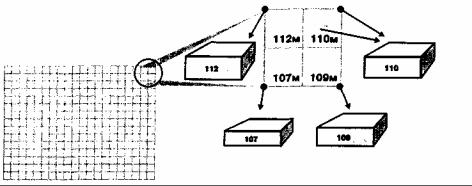
ширины ячейки. Поэтому, прежде чем анализировать такие величины, как расстояния, уклон и экспозицию склона, вам следует уточнить, где ваша растровая ГИС на самом деле помещает значения высот.
Во многих случаях данные будут доступны только для части узлов сетки, используете ли вы растровую или векторную модель. Скорее всего вы получите высотные данные как матрицу высот в одной из двух форм, которые мы обсуждали — регулярной или нерегулярной сетки. Если регулярная сетка достаточно мелка, чтобы соответствовать вашему размеру ячеек растра, то вы сможете легко преобразовать значения высоты в каждой вершине сетки непосредственно в значения высот ячеек растра (опять же, решив заранее, где будут расположены точки высот). Когда данные представлены в форме нерегулярной сетки, перед вами встанет необходимость оценивать или предсказывать все отсутствующие значения. Этот процесс, называемый интерполяцией, необходим, потому что все ячейки растра должны иметь значения высоты. Как мы увидим позже, интерполяция полезный аналитический инструмент для моделирования, как сама по себе, так и при объединении с другими методами анализа для построения более сложных моделей.
Рисунок 10.4. Дискретизация поверхности. Растровое представление непрерывной поверхности. Каждой ячейке присваивается определенное значение высоты. Чтобы обеспечить точный анализ в дальнейшем, важно решить, где именно в пределах ячейки находится точка с этой высотой.
ИНТЕРПОЛЯЦИЯ
Поскольку для непрерывных поверхностей, топографических, экономических, демографических или климатических мы используем выборку, нам нужна возможность изображать с приемлемой точностью наблюдаемые объекты. В традиционной картографии, например, точечные значения выборки высот или значений для других статистических поверхностей преобразуются в визуальную форму, использующую изолинии. Но нам нужна возможность создания и других форм визуального представления, таких как блок-диаграммы и карты отмывки рельефа. И, конечно, нам нужна возможность определения уклонов, экспозиций склонов и поперечных сечений и предсказания неизвестных значений высот для объектов, на которые у нас нет соответствующих данных. Интерполяция обеспечивает многое из того, что нужно для выполнения этих операций.
Линейная интерполяция
Внутри этих простых последовательностей мы можем легко идентифицировать упомянутое выше априорное утверждение, а именно то, что каждое последующее число определяется простым математическим действием. Если мы можем распознать это действие, то сможем восстанавливать пропущенные значения.
130