

Достоинства коммутации пакетов
Высокая общая пропускная способность сети при передаче пульсирующего трафика.
Возможность динамически перераспределять пропускную способность физических каналов связи между абонентами в соответствии с реальными потребностями их трафика.
Недостатки коммутации пакетов
Неопределенность скорости передачи данных между абонентами сети, обусловленная тем, что задержки в очередях буферов коммутаторов сети зависят от общей загрузки сети.
Переменная величина задержки пакетов данных, которая может быть достаточно продолжительной в моменты мгновенных перегрузок сети.
Возможные потери данных из-за переполнения буферов.
В настоящее время активно разрабатываются и внедряются методы, позволяющие преодолеть указанные недостатки, которые особенно остро проявляются для чувствительного к задержкам трафика, требующего при этом постоянной скорости передачи. Такие методы называются методами обеспечения качества обслуживания (Quality of Service, QoS).
Сети с коммутацией пакетов, в которых реализованы методы обеспечения качества обслуживания, позволяют одновременно передавать различные виды трафика, в том числе такие важные как телефонный и компьютерный. Поэтому методы коммутации пакетов сегодня считаются наиболее перспективными для построения конвергентной сети, которая обеспечит комплексные качественные услуги для абонентов любого типа. Тем не менее, нельзя сбрасывать со счетов и методы коммутации каналов. Сегодня они не только с успехом работают в традиционных телефонных сетях, но и широко применяются для образования высокоскоростных постоянных соединений в так называемых первичных (опорных) сетях технологий SDH и DWDM, которые используются для создания магистральных физических каналов между коммутаторами телефонных или компьютерных сетей. В будущем вполне возможно появление новых технологий коммутации, в том или ином виде комбинирующих принципы коммутации пакетов и каналов.
Моде́м (аббревиатура, составленная из слов модулятор-демодулятор) — устройство, применяющееся в системах связи и выполняющее функцию модуляции и демодуляции. Модулятор осуществляет модуляциюнесущего сигнала, то есть изменяет его характеристики в соответствии с изменениями входного информационного сигнала, демодулятор осуществляет обратный процесс. Частным случаем модема является широко применяемое периферийное устройство длякомпьютера, позволяющее ему связываться с другим компьютером, оборудованным модемом, черезтелефоннуюсеть (телефонный модем) иликабельнуюсеть (кабельный модем).
Модем выполняет функцию оконечного оборудования линии связи. При этом формирование данных для передачи и обработку принимаемых данных осуществляеттерминальное оборудование, в простейшем случае —персональный компьютер.
ТИПЫ МОДЕМОВ
По исполнению: внешние — подключаются через COM, USB порт или стандартный разъем в сетевой карте RJ-45 обычно имеют внешний блок питания (существуют USB-модемы, питающиеся от USB и LPT-модемы). внутренние — устанавливаются внутрь компьютера в слот ISA, PCI, PCI-E, PCMCIA, AMR, CNR. встроенные — являются внутренней частью устройства, например ноутбука или док-станции.
По принципу работы: аппаратные — все операции преобразования сигнала, поддержка физических протоколов обмена, производятся встроенным в модем вычислителем (например с использованием DSP, контроллера). Так же в аппаратном модеме присутствует ПЗУ, в котором записана микропрограмма, управляющая модемом. винмодемы — аппаратные модемы, лишённые ПЗУ с микропрограммой. Микропрограмма такого модема хранится в памяти компьютера, к которому подключён модем. Работоспособен только при наличии драйверов, которые обычно писались исключительно под операционные системы семейства MS Windows. полупрограммные (Controller based soft-modem) — модемы, в которых часть функций модема выполняет компьютер, к которому подключён модем. программные (Host based soft-modem) — все операции по кодированию сигнала, проверке на ошибки и управление протоколами реализованы программно и производятся центральным процессором компьютера. При этом в модеме находится аналоговая схема и преобразователи: АЦП, ЦАП, контроллер интерфейса (например USB).
По виду соединения: Модемы для коммутируемых телефонных линий — наиболее распространённый тип модемов. ISDN — модемы для цифровых коммутируемых телефонных линий. DSL — используются для организации выделенных (некоммутируемых) линий используя обычную телефонную сеть. Отличаются от коммутируемых модемов тем, что используют другой частотный диапазон, а также тем, что по телефонным линиям сигнал передается только до АТС. Обычно позволяют одновременно с обменом данными осуществлять использование телефонной линии в обычном порядке. Кабельные — используются для обмена данными по специализированным кабелям — к примеру, через кабель коллективного телевидения по протоколу DOCSIS. Беспроводные, радиомодемы. Сотовые - работают по протоколам сотовой связи - GPRS, EDGE, 3G, 4G и т. п. Часто имеют исполнения в виде USB-брелка. В качестве таких модемов также часто используют терминалы мобильной связи. Спутниковые, PLC — используют технологию передачи данных по проводам бытовой электрической сети. Наиболее распространены в настоящее время: внутренний программный модем, внешний аппаратный модем, встроенные в ноутбуки модемы.
СОСТАВ: Порты ввода-вывода — схемы, предназначенные для обмена данными между телефонной линией и модемом с одной стороны, и модемом и компьютером — с другой. Для взаимодействия с аналоговой телефонной линией зачастую используется трансформатор. Сигнальный процессор (Digital Signal Processor, DSP) Обычно модулирует исходящие сигналы и демодулирует входящие на цифровом уровне в соответствии с используемым протоколом передачи данных. Может также выполнять другие функции. Контроллер управляет обменом с компьютером. Микросхемы памяти: ROM — энергонезависимая память, в которой хранится микропрограмма управления модемом — прошивка, которая включает в себя наборы команд и данных для управления модемом, все поддерживаемые коммуникационные протоколы и интерфейс с компьютером. Обновление прошивки модема доступно в большинстве современных моделей, для чего служит специальная процедура описанная в руководстве пользователя. Для обеспечения возможности перепрошивки для хранения микропрограмм применяется флэш-память (EEPROM). Флэш-память позволяет легко обновлять микропрограмму модема, исправляя ошибки разработчиков и расширяя возможности устройства. В некоторых моделях внешних модемов она так же используется для записи входящих голосовых и факсимильных сообщений при выключенном компьютере. NVRAM — энергонезависимая электрически перепрограммируемая память, в которой хранятся настройки модема. Пользователь может изменять установки, например используя набор AT-команд. RAM — оперативная память модема, используется для буферизации принимаемых и передаваемых данных, работы алгоритмов сжатия и прочего.
ДОП возможности: Факс-модем — позволяет компьютеру, к которому он присоединён, передавать и принимать факсимильные изображения на другой факс-модем или обычную факс-машину. Голосовой модем — имеет функцию оцифровки сигнала с телефонной линии и воспроизведение произвольного звука в линию. Часть голосовых модемов имеет встроенный микрофон. Это позволяет осуществить: передачу голосовых сообщений в режиме реального времени на другой удалённый голосовой модем и приём сообщений от него и воспроизведение их через внутренний динамик; использование такого модема в режиме автоответчика и для организации голосовой почты.
2. Процессы управления разработкой ПС. Структура управления разработки ПС. Планирование составление расписания по разработке ПС. Аттестация ПС.
Управление проектом – управление производством продукта в рамках отведенных ограниченных средств и времени, с учетом требований к продукту.
Вся деятельность предприятия делится на проектную и операционную. Операционная деятельность представляет собой ежедневную рутину, например: ведение бухгалтерского учета, расчетно-кассовое обслуживание и т.д. Внутренняя проектная деятельность предприятия направлена на оптимизацию его операционной деятельности. Примеры: внедрение ПО с целью автоматизации бизнес-процессов, консолидация офисного пространства, маркетинговая акция.
Управление проектом (project management) – это обеспечение достижения задач проекта в рамках отведенных средств, человеческих ресурсов и времени.
Динамика проекта обусловлена влиянием следующих параметров:
Стоимость
Функционал ПО
Сроки
Качество
Эти 4 параметра (иногда 3, исключая качество) согласуются заказчиком и поставщиком ПО и определяются на начальном этапе проекта.
2. Инициация (запуск) проекта
В компаниях, где проектная деятельность не является исключением из правил, при запуске проекта составляется следующая нормативная документация:
Паспорт (устав) проекта
Расписание проекта
Положение о проектной группе
План управления рисками
1. Паспорт (устав) проекта.
Содержит наименование проекта, согласованные значения параметров на момент запуска, краткое описание проекта, предварительную оценку эффективности. Паспорт должен составлять общую картину, доступную для понимания руководством компании. Иногда в паспорте проекта приводят оценку рисков, связанных с действиями руководства, чтобы показать желаемую степень участия руководства в проекте. В целом, этот документ должен содержать только основную суть, конкретные сроки, стоимость и минимум деталей. Паспорт проекта обязан быть легко читабельным и хорошо смотреться - по аналогии, например, с веб-сайтом.
2. Расписание проекта.
Это документ, например, составленный в MS Project, в котором представляется декомпозиция задачи на подзадачи, а также устанавливаются зависимости и сроки подзадач.
3. Положение о проектной группе
Положение о проектной группе регламентирует состав команды, ведущей проект. В эту команду могут входить сотрудники и со стороны заказчика, и со стороны поставщика ПО. Для сотрудников, задействованных в проекте не полностью, устанавливаются примерные проценты их загрузки на подзадачах. Следует также понимать, что в отличие от механической ручной работы, задачи, связанные с программированием и внедрением ПО, часто оказываются неделимы. Заменить программиста или аналитика в процессе выполнения задачи - означает начать задачу заново. В связи с этим, нельзя требовать от персонала ровно того процента загрузки, который указан в расписании проекта. Согласование процентов загрузки лишь позволяет менеджеру проекта получить в свое распоряжение сотрудника из неподчиненного подразделения на некоторое время, в перерыве между другими его рядовыми заданиями.
Варианты организационной структуры проекта
Организационная структура проекта не всегда оформляется документально, но в любом случае должен быть назначен ответственный за каждую отдельную задачу во избежание перекладывания ответственности участниками друг на друга. Для проектов сравнительно небольшой стоимости, где участвуют 2-3 сотрудника, этот пункт не обсуждается. Как правило, если у компании-заказчика имеется специальное подразделение, занимающееся исключительно проектной деятельностью (например, управление развития в департаменте ИТ), оргструктура проекта является подструктурой этого подразделения. В таком случае по-умолчанию применяется иерархическая структура.
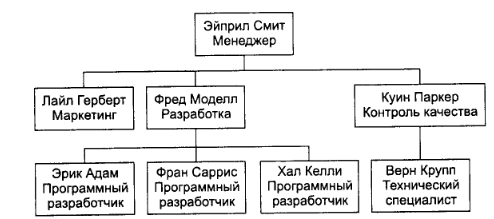
1.Иерархическая
Этот вид организационной структуры отражает «естественные» связи подчинения. В классификации подразделений самым крупным явлается департамент, за ним следуют (по уменьшению величины) управление, отдел, группа. Преимуществом является четкое определение ответственного за весь проект и за отдельные задачи.
2. Горизонтальная
Если проект требует взаимодействия многих подразделений, применяется горизонтальная модель.
Например, под проект требуется закупка нового оборудования, настройка сети, установка серверного ПО, развертывание клиентских рабочих мест, настройка и доработка установленного ПО в соответствии с особенностями предприятия-заказчика. Таким образом, будут задействованы: отдел закупок, техники, системные администраторы, программисты, системные аналитики, администраторы баз данных, сотрудники техподдержки. Понятно, что «ближайший общий начальник» (по аналогии с наименьшим общим кратным) для них – это, как минимум, директор департамента ИТ, который ни в коей мере не должен входить в проектную группу. Поэтому ответственным за координацию деятельности всех этих сотрудников является только менеджер проекта, а сами сотрудники не имеют формальных связей подчинения между собой:
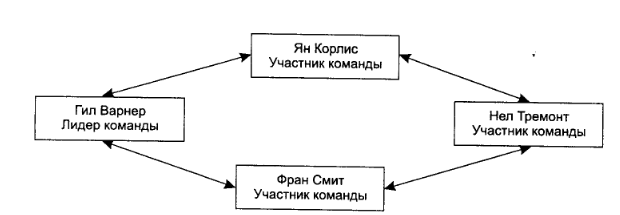
3. Матричная
Применяется в условиях дефицита трудовых ресурсов, по принципу «если останется время». Связи подчинения отсутствуют, за исключением подчинения менеджеру проекта. Для каждого сотрудника устанавливается примерный процент его загрузки на той или иной задаче проекта, а также его роль в проекте. Преимуществом такого подхода является возможность профессионального роста в результате частой смены деятельности, например, программист может выступать в роли аналитика и т.д.
Управление рисками
Риск – это фактор, который может появиться в ходе работ и оказать негативное влияние на проект. При управлении рисками требуется эти риски выявить, оценить и, по мере возможности, устранить.
Выявление рисков
Практически для любого проекта внедрения характерны следующие риски:
Вмешательство в проект высшего руководства (например, резкое изменение постановки задачи в результате непонимания руководством основного предназначения ПО)
Привлечение неадекватных пользователей (например, не умеющих работать за компьютером в нужной степени)
Нехватка знаний/навыков у персонала
Конфликты в проектной группе
Увольнение ключевого сотрудника
Технические моменты
Оценка рисков
Оценить риск – значит оценить его критичность для проекта. В процессе оценки рисков рассчитывается приоритет каждого из них:
Возможна оценка рисков к зависимости от одного параметра - их стоимости - вместо стоимости и затрат времени.
Альтернативы по управлению рисками (Устранение рисков)
Набор альтернатив по управлению риском включает:
- избежание риска – данная единица портфеля рисков исключается из него посредством устранения причин потенциальных рисковых событий (например, отказ от услуг определенного поставщика);
- передача риска – заключение специального соглашения, по которому данный риск принимает на себя другая компания (например, страхование, ответственность производителя за используемое в проекте оборудование и др.);
- снижение риска – принятие мер по снижению вероятности и/или ущерба от возникновения рисковых событий (при выработке таких мер важно сбалансировать их стоимость с ожидаемой денежной выгодой от снижения риска)
- принятие риска – в этом случае компания оставляет для риска возможности для реализации, формируя под него соответствующие резервы (стоит отметить, что часть рисков, оставшаяся после снижения, принимается автоматически).
3. Написать HTML код для отображения в браузере таблицы:
1 2
3 4
5 6 7
|
<html>
<head> <title>Задание № 6</title> </head> <body> <table border = 5> <tr> <td>1</td> <td>2</td> </tr>
|
<tr> <td > </td> <td > 3</td> <td >4</td> </tr>
|
<tr> <td >5</td> <td >6</td> <td >7</td> </tr>
</body>
</html> |
Билет 19.
1. Характеристики транспортного и прикладного уровней стека протоколов TCP/IP.
TCP/IP - аббревиатура термина Transmission Control Protocol/Internet Protocol (Протокол управления передачей/Интернет Протокол) - это согласованный заранее стандарт, служащий для обмена данных между двумя узлами(компьютерами в сети), причём неважно, на какой платформе эти компьютеры и какая между ними сеть. TCP/IP служит как мост, соединяющий все узлы сети воедино, за это он и завоевал свою популярность. TCP/IP зародился в результате исследований, профинансированных ARPA (Advanced Research Project Agency) - специальным отделением правительства США в 1970-х годах. Он был задуман, как общий стандарт, который объединит все сети в единую виртуальную "сеть сетей"(internetwork). Таким образом был создан Интернет, в результате преобразования существующего конгломерата вычислительных сетей, носивших название ARPAnet, с помощью TCP/IP. Название "TCP/IP" связано с двумя протоколами: TCP и IP. Но TCP/IP - это не только эти два протокола. Это целое семейство протоколов, объединенное под одним началом - IP-протоколом. В это семейство входят протоколы, которые взаимодействуют с протоколом IP и с его помощью строят свои каналы данных. Это сам TCP, а также UDP, ICMP, telnet, SMTP, FTP и многие другие.
Структура стека TCP/IP
|
Уровень I |
Прикладной уровень |
|
Уровень II |
Основной (транспортный) уровень |
|
Уровень III |
Уровень межсетевого взаимодействия |
|
Уровень IV |
Уровень сетевых интерфейсов |
Транспортный уровень – Основной
Поскольку на сетевом уровне не устанавливается соединение, то нет никаких гарантий того, что все пакеты будут доставлены в место назначения целыми и невредимыми или придут в том же порядке, в котором они были отправлены. Эту задачу - обеспечение надежности информационной связи между двумя конечными узлами - решает основной уровень стека TCP/IP, называемый также транспортным. На этом уровне функционируют протокол управления передачей TCP и протокол дейтаграмм пользователя UDP. Протокол TCP обеспечивает надежную передачу сообщений между удаленными прикладными процессами за счет образования логических соединений. Этот протокол позволяет равноранговым объектам на компьютере-отправителе и на компьютере-получателе поддерживать обмен данными в дуплексном режиме. TCP позволяет без ошибок доставлять сформированный на одном из компьютеров поток байт в любой другой компьютер, входящий в составную сеть. TCP делит поток байт на части - сегменты и передает их нижележащему уровню межсетевого взаимодействия. После того, как эти сегменты будут доставлены в пункт назначения, протокол TCP снова соберет их в непрерывный поток байт. Протокол UDP обеспечивает передачу прикладных пакетов дейтаграммным способом, как и главный протокол уровня межсетевого взаимодействия IP, и выполняет только функции связующего звена (мультиплексора) между сетевым протоколом и многочисленными системами прикладного уровня, или пользовательскими процессами.
Прикладной уровень
Прикладной уровень объединяет все службы, представляемые системой пользовательским приложениям. За долгие годы использования в сетях различных стран и организаций стек TCP/IP накопил большое число протоколов и служб прикладного уровня. Прикладной уровень реализуется программными системами, построенными в архитектуре клиент-сервер, базирующейся на протоколах нижних уровней. В отличие от протоколов остальных трех уровней, протоколы прикладного уровня занимаются деталями конкретного приложения и "не интересуются" способами передачи данных по сети. Этот уровень постоянно расширяется за счет присоединения к старым, прошедшим многолетнюю эксплуатацию сетевым службам типа Telnet, FTP, TFTP, DNS, SNMP, сравнительно новых служб, таких, например, как протокол передачи гипертекстовой информации HTTP.
2. Трехуровневая архитектура схем баз данных в СУБД.
Первая попытка создания стандартной терминологии и общей архитектуры СУБД была предпринята в 1971 году группой DBTG, признавшей необходимость использования двухуровневого подхода, построенного на основе использования системного представления, т.е. схемы , и пользовательских представлений, т.е. подсхем . Сходные терминология и архитектура были предложены в 1975 году Комитетом планирования стандартов и норм SPARC (Standards Planning and Requirements Committee) Национального Института Стандартизации США (American National Standard Institute - ANSI), ANSI/X3/SPARC (ANSI, 1975). Комитет ANSI/SPARC признал необходимость использования трехуровневого подхода. Хотя модель ANSI/SPARC не стала стандартом, тем не менее она все еще представляет собой основу для понимания некоторых функциональных особенностей СУБД.
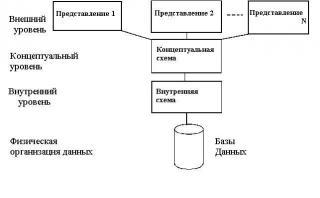
В данном случае для нас наиболее важным моментом в этих и последующих разработках является идентификация трех уровней абстракции, т.е. трех различных уровней описания элементов данных. Эти уровни формируют трехуровневую архитектуру, которая охватывает внешний, концептуальный и внутренний уровни, как показано на рис.
Уровень, на котором воспринимают данные пользователи, называется внешним уровнем (external level), тогда как СУБД и операционная система воспринимают данные на внутреннем уровне (internal level). Именно на внутреннем уровне данные реально сохраняются с использованием всех тех структур и файловой организации. Концептуальный уровень (conceptual level) представления данных предназначен для отображения внешнего уровня на внутренний и обеспечения необходимой независимости друг от друга.
енным в наиболее удобной для него форме. Внешнее представление содержит только те сущности, атрибуты и связи предметной области, которые интересны пользователю.
Помимо этого, различные представления могут поразному отображать одни и те же данные. Например, один пользователь может просматривать даты в формате (день, месяц, год), а другой - в формате (год, месяц, день). Некоторые представления могут включать производные или вычисляемые данные, которые не хранятся в базе данных как таковые, а создаются по мере надобности. Представления могут также включать комбинированные или производные данные из нескольких объектов.
Концептуальный уровень. Промежуточным уровнем в трехуровневой архитектуре является концептуальный уровень. Этот уровень содержит логическую структуру всей базы данных (с точки зрения АБД). Фактически, это полное представление требований к данным, которое не зависит от любых соображений относительно способа их хранения. На концептуальном уровне представлены следующие компоненты: все сущности, их атрибуты и связи; накладываемые на данные ограничения; семантическая информация о данных; информация о мерах обеспечения безопасности и поддержки целостности данных.
Концептуальный уровень поддерживает каждое внешнее представление, в том смысле, что любые доступные пользователю данные должны содержаться (или могут быть вычислены) на этом уровне. Однако этот уровень не содержит никаких сведений о методах хранения данных.
Внутренний уровень. Внутренний уровень описывает физическую реализацию базы данных и предназначен для достижения оптимальной производительности и обеспечения экономного использования дискового пространства. Он содержит описание структур данных и организации отдельных файлов, используемых для хранения данных в запоминающих устройствах. На этом уровне осуществляется взаимодействие СУБД с методами доступа операционной системы с целью размещения данных на запоминающих устройствах, создания индексов, извлечения данных и т.д. На внутреннем уровне хранится следующая информация: сведения о распределении дискового пространства для хранения данных и индексов; описание подробностей сохранения записей (с указанием реальных размеров сохраняемых элементов данных); сведения о размещении записей; сведения о сжатии данных и выбранных методах их шифрования.
3. Написать HTML код для отображения в браузере таблицы:
1 2
3 4
5 6 7
<html>
<head>
<title>Задание № 6</title>
</head>
<body>
<table border = 5>
<tr>
<td>1</td>
<td>2</td>
</tr>
<tr>
<td > </td>
<td > 3</td>
<td >4</td>
</tr>
<tr>
<td >5</td>
<td >6</td>
<td >7</td>
</tr>
</body>
</html>
Билет 20.
1. Формальные языки и грамматики. Классификация грамматик по Хомскому.
формальный язык — это множество конечных слов (строк, цепочек) над конечным алфавитом.
Формальная грамматика или просто грамматика в теории формальных языков — способ описания формального языка, то есть выделения некоторого подмножества из множества всех слов некоторого конечного алфавита. Различают порождающие и распознающие (или аналитические) грамматики — первые задают правила, с помощью которых можно построить любое слово языка, а вторые позволяют по данному слову определить, входит оно в язык или нет.
Теория формальных языков (формальных грамматик) занимается описанием, распознаванием и переработкой языков
Существуют два основных способа описания отдельных классов языков. Первый из них основан на ограничениях, которые налагаются на систему полусоотношений Туэ (продукций), на базе которых определяются грамматики как механизмы, порождающие цепочки символов. Другим способом является определение языка в терминах множества цепочек, с помощью некоторого распознающего устройства.
Такие устройства будем называть автоматами (автоматами-распознавателями). Хомский определил четыре типа грамматик, на основе которых оцениваются возможности других способов описания языков.
Типы грамматик по Хомскому обозначают: тип 0, тип 1, тип 2 и тип 3. Соответствующий тип грамматики определяется теми ограничениями, которые налагаются на продукцию Р.
Если таких ограничений нет, грамматика принадлежит к типу 0.
Единственное
ограничение, налагаемое на длину цепочек
α и β: ![]() относит
грамматики к
типу 1.
Такие грамматики также называют
контекстно-зависимыми, то есть грамматиками
непосредственных составляющих
(НС-грамматиками).
относит
грамматики к
типу 1.
Такие грамматики также называют
контекстно-зависимыми, то есть грамматиками
непосредственных составляющих
(НС-грамматиками).
В
том случае, когда цепочка α состоит из
одного символа, т. е. ![]() ,
грамматики относят к типу
2.
В этом случае их называют бесконтекстными
(контекстно-свободными или КС-грамматиками).
,
грамматики относят к типу
2.
В этом случае их называют бесконтекстными
(контекстно-свободными или КС-грамматиками).
Наконец,
регулярными грамматиками (типа
3)
называют такие, для которых![]() .
Иными словами, правые части продукций
регулярных грамматик состоят либо из
одного терминального и одного
нетерминального символов, либо из одного
терминального символа.
.
Иными словами, правые части продукций
регулярных грамматик состоят либо из
одного терминального и одного
нетерминального символов, либо из одного
терминального символа.
Языком
L(G), порождаемым грамматикой G, будем
называть множество цепочек ![]() ,
каждая из которых порождается из
начального символа S в смысле полу-туэвских
соотношений Р данной грамматики. Другими
словами,
,
каждая из которых порождается из
начального символа S в смысле полу-туэвских
соотношений Р данной грамматики. Другими
словами, ![]()
Н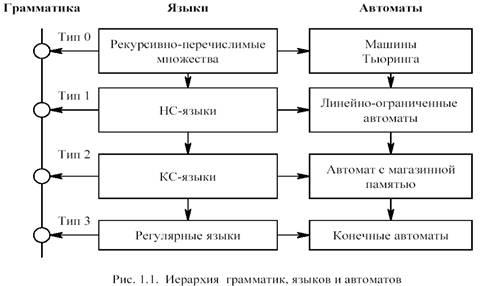 етрудно
видеть, что каждая регулярная грамматика
является бесконтекстной, а каждая
бесконтекстная грамматика является
контекстно-зависимой. В свою очередь,
каждая контекстно-зависимая грамматика
– это грамматика типа 0. Обратное
утверждение неверно. Очевидно, что
имеется некоторая иерархия грамматик,
которой соответствует иерархия формальных
языков, каждый из них может быть порожден
некоторой формальной грамматикой. При
этом тип языка соответствует типу той
грамматики, с помощью которой он может
быть порожден.
етрудно
видеть, что каждая регулярная грамматика
является бесконтекстной, а каждая
бесконтекстная грамматика является
контекстно-зависимой. В свою очередь,
каждая контекстно-зависимая грамматика
– это грамматика типа 0. Обратное
утверждение неверно. Очевидно, что
имеется некоторая иерархия грамматик,
которой соответствует иерархия формальных
языков, каждый из них может быть порожден
некоторой формальной грамматикой. При
этом тип языка соответствует типу той
грамматики, с помощью которой он может
быть порожден.
С другой стороны, типы языков могут быть определены типами абстрактных распознающих устройств (автоматов). При этом язык определяется как множество цепочек, допускаемых распознающим устройством определенного типа. На рис. 1.1 приведена иерархия языков и соответствующие ей иерархии грамматик и автоматов как распознающих устройств.
Любое множество, порождаемое автоматическим устройством произвольного вида, порождается некоторой грамматикой типа 0 по Хомскому. Заметим, что для любого естественного языка, в принципе, возможно построить математическую модель, использующую такую грамматику.
Таким образом, грамматики типа 0 представляют собой порождающие устройства очень общего характера. А те формальные языки, с которыми имеют дело автоматно-лингвистические модели (язык программирования, ограниченные естественные языки), как показывает практика, всегда описываются языками типа 1 или 2.
Языки типа 3, которые называют автоматными языками, языками с конечным числом состояний, нашли широкое применение в исследовании электронных схем, а также в ряде других областей (например, исследование цепей Маркова).
2. Методы разработки структуры ПС. Восходящая разработка ПС. Нисходящая разработка. Конструктивный подход. Архитектурный подход разработки ПС.
В качестве модульной структуры программы принято использовать древовидную структуру, включая деревья со сросшимися ветвями. В узлах такого дерева размещаются программные модули, а направленные дуги (стрелки) показывают статическую подчиненность модулей, т.е. каждая дуга показывает, что в тексте модуля, из которого она исходит, имеется ссылка на модуль, в который она входит.
В процессе разработки программы ее модульная структура может по-разному формироваться и использоваться для определения порядка программирования и отладки модулей, указанных в этой структуре. Поэтому можно говорить о разных методах разработки структуры программы. Обычно в литературе обсуждаются два метода: метод восходящей разработки и метод нисходящей разработки.
Метод восходящей разработки заключается в следующем. Сначала строится модульная структура программы в виде дерева. Затем поочередно программируются модули программы, начиная с модулей самого нижнего уровня (листья дерева модульной структуры программы), в таком порядке, чтобы для каждого программируемого модуля были уже запрограммированы все модули, к которым он может обращаться. После того, как все модули программы запрограммированы, производится их поочередное тестирование и отладка в принципе в таком же (восходящем) порядке, в каком велось их программирование. На первый взгляд такой порядок разработки программы кажется вполне естественным: каждый модуль при программировании выражается через уже запрограммированные непосредственно подчиненные модули, а при тестировании использует уже отлаженные модули. Однако, современная технология не рекомендует такой порядок разработки программы. Во-первых, для программирования какого-либо модуля совсем не требуется текстов используемых им модулей - для этого достаточно, чтобы каждый используемый модуль был лишь специфицирован (в объеме, позволяющем построить правильное обращение к нему), а для тестирования его возможно используемые модули заменять их имитаторами (заглушками). Во-вторых, каждая программа в какой-то степени подчиняется некоторым внутренним для нее, но глобальным для ее модулей соображениям (принципам реализации, предположениям, структурам данных и т.п.), что определяет ее концептуальную целостность и формируется в процессе ее разработки. При восходящей разработке эта глобальная информация для модулей нижних уровней еще не ясна в полном объеме, поэтому очень часто приходится их перепрограммировать, когда при программировании других модулей производится существенное уточнение этой глобальной информации (например, изменяется глобальная структура данных). В-третьих, при восходящем тестировании для каждого модуля (кроме головного) приходится создавать ведущую программу (модуль), которая должна подготовить для тестируемого модуля необходимое состояние информационной среды и произвести требуемое обращение к нему. Это приводит к большому объему "отладочного" программирования и в то же время не дает никакой гарантии, что тестирование модулей производилось именно в тех условиях, в которых они будут выполняться в рабочей программе.
Метод нисходящей разработки заключается в следующем. Как и в предыдущем методе сначала строится модульная структура программы в виде дерева. Затем поочередно программируются модули программы, начиная с модуля самого верхнего уровня (головного), переходя к программированию какого-либо другого модуля только в том случае, если уже запрограммирован модуль, который к нему обращается. После того, как все модули программы запрограммированы, производится их поочередное тестирование и отладка в таком же (нисходящем) порядке. При таком порядке разработки программы вся необходимая глобальная информация формируется своевременно, т.е. ликвидируется весьма неприятный источник просчетов при программировании модулей. Существенно облегчается и тестирование модулей, производимое при нисходящем тестировании программы. Первым тестируется головной модуль программы, который представляет всю тестируемую программу и поэтому тестируется при "естественном" состоянии информационной среды, при котором начинает выполняться эта программа. При этом все модули, к которым может обращаться головной, заменяются на их имитаторы (заглушки). Каждый имитатор модуля представляется весьма простым программным фрагментом, сигнализирующим, в основном, о самом факте обращения к имитируемому модулю с необходимой для правильной работы программы обработкой значений его входных параметров (иногда с их распечаткой) и с выдачей, если это необходимо, заранее запасенного подходящего результата. После завершения тестирования и отладки головного и любого последующего модуля производится переход к тестированию одного из модулей, которые в данный момент представлены имитаторами, если таковые имеются. Для этого имитатор выбранного для тестирования модуля заменяется на сам этот модуль и добавляются имитаторы тех модулей, к которым может обращаться выбранный для тестирования модуль. При этом каждый такой модуль будет тестироваться при "естественных" состояниях информационной среды, возникающих к моменту обращения к этому модулю при выполнении тестируемой программы. Таким образом, большой объем "отладочного" программирования заменяется программированием достаточно простых имитаторов используемых в программе модулей.
Некоторым недостатком нисходящей разработки, приводящим к определенным затруднениям при ее применении, является необходимость абстрагироваться от базовых возможностей используемого языка программирования, выдумывая абстрактные операции, которые позже нужно будет реализовать с помощью выделенных в программе модулей. Однако способность к таким абстракциям представляется необходимым условием разработки больших программных средств, поэтому ее нужно развивать.
В рассмотренных методах восходящей и нисходящей разработок модульная древовидная структура программы должна разрабатываться до начала программирования модулей. Однако такой подход вызывает ряд возражений: представляется сомнительным, чтобы до программирования модулей можно было разработать структуру программы достаточно точно и содержательно. На самом деле это делать не обязательно: так при конструктивном и архитектурном подходах к разработке программ модульная структура формируется в процессе программирования модулей.
Конструктивный подход к разработке программы представляет собой модификацию нисходящей разработки, при которой модульная древовидная структура программы формируется в процессе программирования модуля. Сначала программируется головной модуль, исходя из спецификации программы в целом, причем спецификация программы является одновременно и спецификацией ее головного модуля, так как последний полностью берет на себя ответственность за выполнение функций программы. В процессе программирования головного модуля, в случае, если эта программа достаточно большая, выделяются подзадачи (внутренние функции), в терминах которых программируется головной модуль. Это означает, что для каждой выделяемой подзадачи (функции) создается спецификация реализующего ее фрагмента программы, который в дальнейшем может быть представлен некоторым поддеревом модулей. Важно заметить, что здесь также ответственность за выполнение выделенной функции берет головной (может быть, и единственный) модуль этого поддерева, так что спецификация выделенной функции является одновременно и спецификацией головного модуля этого поддерева. В головном модуле программы для обращения к выделенной функции строится обращение к головному модулю указанного поддерева в соответствии с созданной его спецификацией. Таким образом, на первом шаге разработки программы (при программировании ее головного модуля) формируется верхняя начальная часть дерева.
Аналогичные действия производятся при программировании любого другого модуля, который выбирается из текущего состояния дерева программы из числа специфицированных, но пока еще не запрограммированных модулей.
Архитектурный подход к разработке программы представляет собой модификацию восходящей разработки, при которой модульная структура программы формируется в процессе программирования модуля. Но при этом ставится существенно другая цель разработки: повышение уровня используемого языка программирования, а не разработка конкретной программы. Это означает, что для заданной предметной области выделяются типичные функции, каждая из которых может использоваться при решении разных задач в этой области, и специфицируются, а затем и программируются отдельные программные модули, выполняющие эти функции. Так как процесс выделения таких функций связан с накоплением и обобщением опыта решения задач в заданной предметной области, то обычно сначала выделяются и реализуются отдельными модулями более простые функции, а затем постепенно появляются модули, использующие ранее выделенные функции. Такой набор модулей создается в расчете на то, что при разработке той или иной программы заданной предметной области в рамках конструктивного подхода могут оказаться приемлемыми некоторые из этих модулей. Это позволяет существенно сократить трудозатраты на разработку конкретной программы путем подключения к ней заранее заготовленных и проверенных на практике модульных структур нижнего уровня. Так как такие структуры могут многократно использоваться в разных конкретных программах, то архитектурный подход может рассматриваться как путь борьбы с дублированием в программировании. В связи с этим программные модули, создаваемые в рамках архитектурного подхода, обычно параметризуются для того, чтобы усилить применимость таких модулей путем настройки их на параметры.
Все эти методы имеют еще различные разновидности в зависимости от того, в какой последовательности обходятся узлы (модули) древовидной структуры программы в процессе ее разработки. Это можно делать, например, по слоям (разрабатывая все модули одного уровня, прежде чем переходить к следующему уровню). При нисходящей разработке дерево можно обходить также в лексикографическом порядке (сверху-вниз, слева-направо). Возможны и другие варианты обхода дерева. Так, при конструктивной реализации для обхода дерева программы целесообразно следовать идеям Фуксмана, которые он использовал в предложенном им методе вертикального слоения. Сущность такого обхода заключается в следующем. В рамках конструктивного подхода сначала реализуются только те модули, которые необходимы для самого простейшего варианта программы, которая может нормально выполняться только для весьма ограниченного множества наборов входных данных, но для таких данных эта задача будет решаться до конца.
Вместо других модулей, на которые в такой программе имеются ссылки, в эту программу вставляются лишь их имитаторы, обеспечивающие, в основном, контроль за выходом за пределы этого частного случая. Затем к этой программе добавляются реализации некоторых других модулей (в частности, вместо некоторых из имеющихся имитаторов), обеспечивающих нормальное выполнение для некоторых других наборов входных данных. И этот процесс продолжается поэтапно до полной реализации требуемой программы. Таким образом, обход дерева программы производится с целью кратчайшим путем реализовать тот или иной вариант (сначала самый простейший) нормально действующей программы. В связи с этим такая разновидность конструктивной реализации получила название метода целенаправленной конструктивной реализации. Достоинством этого метода является то, что уже на достаточно ранней стадии создается работающий вариант разрабатываемой программы.
3. Написать программу на языке С++ для удаления из списка целых всех элементов, равных 0. Например: [1,0,2,0,3,0] [1,2,3].
|
#pragma hdrstop #include <iostream.h> void main() { int X[10],Y[10],N,j=0,i; cout<<"\n Vvedite N (<10) =="; cin>>N; for(i=1;i<=N;i++) { cout<<"\n X["<<i<<"] =="; cin>>X[i]; }
|
for(i=1;i<=N;i++) { if (X[i]!=0) { j++; Y[j]=X[i]; } }
|
for(i=1;i<=j;i++) { cout<<"\n X["<<i<<"] == "<<Y[i]; } }
|
Билет 21.
1. Конечные автоматы, автомат со стековой памятью (магазин).
Конечный
автомат
— абстрактный автомат без выходного
потока, число возможных состояний
которого конечно. Результат работы
автомата определяется по его конечному
состоянию.
Существуют
различные варианты задания конечного
автомата. Например, конечный автомат
может быть задан с помощью пяти параметров:
![]()
Q — конечное множество состояний автомата;
q0
— начальное
(стартовое) состояние
автомата (![]()
F
— множество заключительных
(или допускающих)
состояний, таких что
![]()
Σ — допустимый входной алфавит (конечное множество допустимых входных символов), из которого формируются строки, считываемые автоматом;
δ
— заданное отображение множества
![]()
![]()
![]()
(иногда δ называют функцией переходов автомата).
Автомат начинает работу в состоянии q0, считывая по одному символу входной строки. Считанный символ переводит автомат в новое состояние из Q в соответствии с функцией переходов. Если по завершении считывания входного слова (цепочки символов) автомат оказывается в одном из допускающих состояний, то слово «принимается» автоматом. В этом случае говорят, что оно принадлежит языку данного автомата. В противном случае слово «отвергается». Конечные автоматы широко используются на практике, например в синтаксических, лексических анализаторах, и тестировании программного обеспечения на основе моделей. В теории автоматов, автомат с магазинной памятью — это конечный автомат, который использует стек для хранения состояний.
Формальное определение

диаграмма автомата с магазинной памятью
В
отличие от конечных автоматов, автомат
с магазинной памятью является набором:![]()
K
— конечное множество состояний автомата![]()
![]()
Σ — допустимый входной алфавит, из которого формируются строки, считываемые автоматом
S
— алфавит памяти (магазина)![]()
Память
работает как стек, то есть для чтения
доступен последний записанный в неё
элемент. Таким образом, функция перехода
является отображением
![]() e,
в магазин ничего не добавляется, а
элемент с вершины стирается. Если магазин
пуст, то срабатывают правила с e
в левой части.
Автомат
с магазинной памятью может распознать
любой контекстно-свободный язык.
В
чистом виде автоматы с магазинной
памятью используются крайне редко.
Обычно это модель используется для
наглядного представления отличия
обычных конечных автоматов от
синтаксических грамматик. Реализация
автоматов с магазинной памятью отличается
от конечных автоматов тем, что текущее
состояние автомата сильно зависит от
любого предыдущего.
e,
в магазин ничего не добавляется, а
элемент с вершины стирается. Если магазин
пуст, то срабатывают правила с e
в левой части.
Автомат
с магазинной памятью может распознать
любой контекстно-свободный язык.
В
чистом виде автоматы с магазинной
памятью используются крайне редко.
Обычно это модель используется для
наглядного представления отличия
обычных конечных автоматов от
синтаксических грамматик. Реализация
автоматов с магазинной памятью отличается
от конечных автоматов тем, что текущее
состояние автомата сильно зависит от
любого предыдущего.
2. Организация шин.
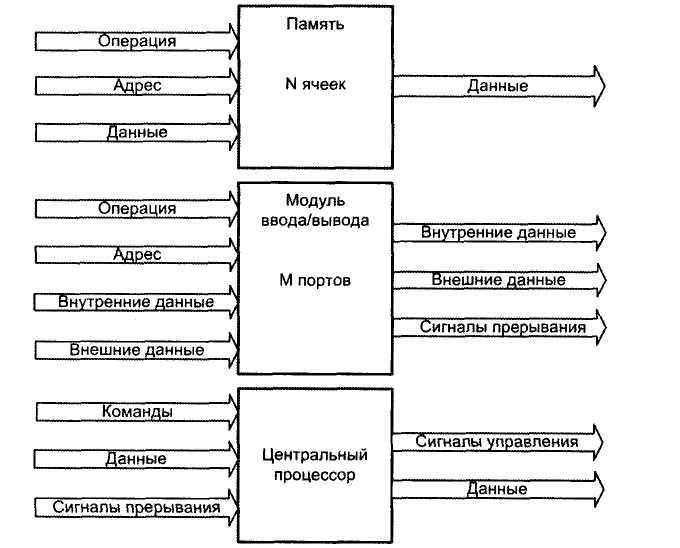
Совокупность трактов, объединяющих между собой основные устройства ВМ (центральный процессор, память и модули ввода/вывода), образует структуру взаимосвязей вычислительной машины.
Структура взаимосвязей должна обеспечивать обмен информацией между: центральным процессором и памятью; центральным процессором и модулями ввода/вывода; памятью и модулями ввода/вывода.
С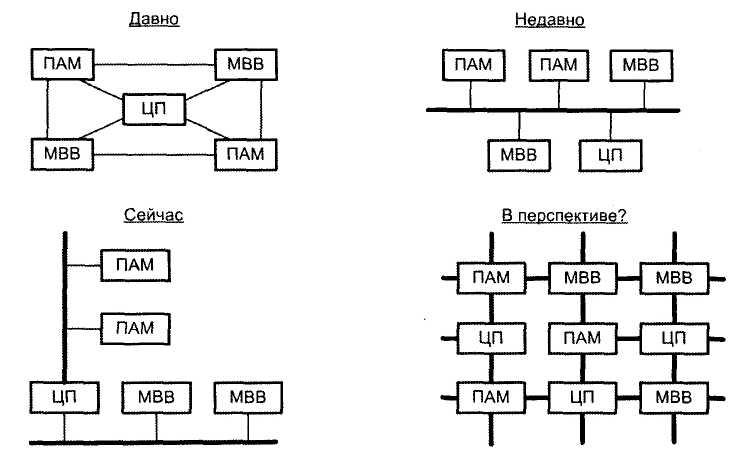 развитием вычислительной техники
менялась и структура взаимосвязей
устройств ВМ (рис. 4.2). На начальной
стадии преобладали непосредственные
связи между взаимодействующими
устройствами ВМ. С появлением мини-ЭВМ,
и особенно первых микроЭВМ, все более
популярной становится схема с одной
общей шиной. Последовавший за этим
быстрый рост производительности
практически всех устройств ВМ привел
к неспособности единственной шины
справиться с возросшим трафиком, и ей
на смену приходят структуры взаимосвязей
на базе нескольких шин. Дальнейшие
перспективы повышения производительности
вычислений связаны не столько с
однопроцессорными машинами, сколько с
многопроцессорными вычислительными
системами. Способы взаимосвязей в таких
системах значительно разнообразнее,
и их рассмотрению посвящен один из
разделов учебника. Возвращаясь к
вычислительным машинам, более внимательно
рассмотрим вопросы, связанные с
организацией взаимосвязей на базе шин.
развитием вычислительной техники
менялась и структура взаимосвязей
устройств ВМ (рис. 4.2). На начальной
стадии преобладали непосредственные
связи между взаимодействующими
устройствами ВМ. С появлением мини-ЭВМ,
и особенно первых микроЭВМ, все более
популярной становится схема с одной
общей шиной. Последовавший за этим
быстрый рост производительности
практически всех устройств ВМ привел
к неспособности единственной шины
справиться с возросшим трафиком, и ей
на смену приходят структуры взаимосвязей
на базе нескольких шин. Дальнейшие
перспективы повышения производительности
вычислений связаны не столько с
однопроцессорными машинами, сколько с
многопроцессорными вычислительными
системами. Способы взаимосвязей в таких
системах значительно разнообразнее,
и их рассмотрению посвящен один из
разделов учебника. Возвращаясь к
вычислительным машинам, более внимательно
рассмотрим вопросы, связанные с
организацией взаимосвязей на базе шин.
Рис. 4.2. Эволюция структур взаимосвязей (ЦП — центральный процессор, ПАМ — модуль основной памяти, МВВ — модуль ввода/вывода)
Взаимосвязь частей ВМ и ее «общение» с внешним миром обеспечиваются системой шин. Большинство машин содержат несколько различных шин, каждая из которых оптимизирована под определенный вид коммуникаций. Часть шин скрыта внутри интегральных микросхем или доступна только в пределах печатной платы. Некоторые шины имеют доступные извне точки, с тем чтобы к ним легко можно было подключить дополнительные устройства, причем большинство таких шин не просто доступны, но и отвечают определенным стандартам, что позволяет подсоединять к шине устройства различных производителей.
Чтобы охарактеризовать конкретную шину, нужно описать (рис. 4.3): совокупность сигнальных линий; физические, механические характеристики и электрические характеристики шины используемые сигналы арбитража, состояния, управления и синхронизации;
правила взаимодействия подключенных к шине устройств (протокол шины).
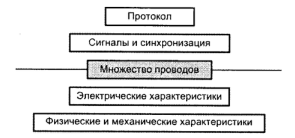
Рис. 4.3. Параметры, характеризующие шину
Шину образует набор коммуникационных линий, каждая из которых способна передавать сигналы, представляющие двоичные цифры 1 и 0. По линии может пересылаться развернутая во времени последовательность таких сигналов. При совместном использовании несколько линий могут обеспечить одновременную (параллельную) передачу двоичных чисел. Физически линии шины реализуются в виде отдельных проводников, как полоски проводящего материала на монтажной плате либо как алюминиевые или медные проводящие дорожки на кристалле микросхемы.
Операции на шине называют транзакциями. Основные виды транзакций — транзакции чтения и транзакции записи. Если в обмене участвует устройство ввода/вывода, можно говорить о транзакциях ввода и вывода, по сути эквивалентных транзакциям чтения и записи соответственно. Шинная транзакция включает в себя две части: посылку адреса и прием (или посылку) данных.
Когда два устройства обмениваются информацией по шине, одно из них должно инициировать обмен и управлять им. Такого рода устройства называют ведущими (bus master). В компьютерной терминологии «ведущий» — это любое устройство, способное взять на себя владение шиной и управлять пересылкой данных. Ведущий не обязательно использует данные сам. Он, например, может захватить управление шиной в интересах другого устройства. Устройства, не обладающие возможностями инициирования транзакции, носят название ведомых (bus slave). В принципе к шине может быть подключено несколько потенциальных ведущих, но в любой момент времени активным может быть только один из них: если несколько устройств передают информацию одновременно, их сигналы перекрываются и искажаются. Для предотвращения одновременной активности нескольких ведущих в любой шине предусматривается процедура допуска к управлению шиной только одного из претендентов (арбитраж). В то же время некоторые шины допускают широковещательный режим записи, когда информация одного ведущего передается сразу нескольким ведомым (здесь арбитраж не требуется). Сигнал, направленный одним устройством, доступен всем остальным устройствам, подключенным к шине.
Английский эквивалент термина «шина» — «bus» — восходит к латинскому слову omnibus, означающему «для всего». Этим стремятся подчеркнуть, что шина ведет себя как магистраль, способная обеспечить всевозможные виды трафика.
Типы шин Важным критерием, определяющим характеристики шины, может служить ее целевое назначение. По этому критерию можно выделить: шины «процессор-память»; шины ввода/вывода; системные шины.
Шина «процессор-память» обеспечивает непосредственную связь между центральным процессором (ЦП) вычислительной машины и основной памятью (ОП). В современных микропроцессорах такую шину часто называют шиной переднего плана и обозначают аббревиатурой FSB (Front-Side Bus). Интенсивный трафик между процессором и памятью требует, чтобы полоса пропускания шины, то есть количество информации, проходящей по шине в единицу времени, была наибольшей. Роль этой шины иногда выполняет системная шина (см. ниже), однако в плане эффективности значительно выгоднее, если обмен между ЦП и ОП ведется по отдельной шине. К рассматриваемому виду можно отнести также шину, связывающую процессор с кэш-памятью второго уровня, известную как шина заднего плана — BSB (Back-Side Bus). BSB позволяет вести обмен с большей скоростью, чем FSB, и полностью реализовать возможности более скоростной кэш-памяти.
Поскольку в фон-неймановских машинах именно обмен между процессором и памятью во многом определяет быстродействие ВМ, разработчики уделяют связи ЦП с памятью особое внимание. Для обеспечения максимальной пропускной способности шины «процессор-память» всегда проектируются с учетом особенностей организации системы памяти, а длина шины делается по возможности минимальной
Шина ввода/вывода служит для соединения процессора (памяти) с устройствами ввода/вывода (УВВ). Учитывая разнообразие таких устройств, шины ввода/вывода унифицируются и стандартизируются. Связи с большинством УВВ (но не с видеосистемами) не требуют от шины высокой пропускной способности. При проектировании шин ввода/вывода в учет берутся стоимость конструктивна и соединительных разъемов. Такие шины содержат меньше линий по сравнению с вариантом «процессор-память», но длина линий может быть весьма большой. Типичными примерами подобных шин могут служить шины PCI и SCSI.
Системная шина С целью снижения стоимости некоторые ВМ имеют общую шину для памяти и устройств ввода/вывода. Такая шина часто называется системной. Системная шина служит для физического и логического объединения всех устройств ВМ. Поскольку основные устройства машины, как правило, размещаются на общей монтажной плате, системную шину часто называют объединительной шиной (backplane bus), хотя эти термины нельзя считать строго эквивалентными.
Системная шина в состоянии содержать несколько сотен линий. Совокупность линий шины можно подразделить на три функциональные группы (рис. 4.4): шину данных, шину адреса и шину управления. К последней обычно относят также линии для подачи питающего напряжения на подключаемые к системной шине модули.
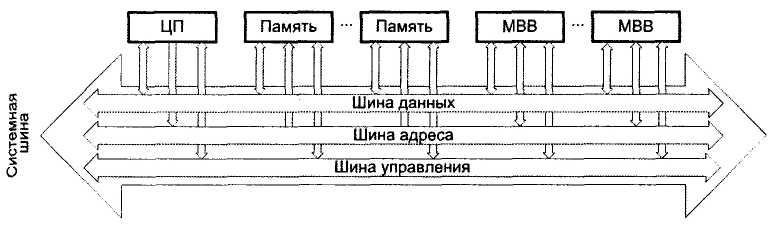
Функционирование системной шины можно описать следующим образом. Если один из модулей хочет передать данные в другой, он должен выполнить два действия: получить в свое распоряжение шину и передать по ней данные. Если какой-то модуль хочет получить данные от другого модуля, он должен получить доступ к шине и с помощью соответствующих линий управления и адреса передать в другой модуль запрос. Далее он должен ожидать, пока модуль, получивший запрос, пошлет данные.
Физически системная шина представляет собой совокупность параллельных электрических проводников. Этими проводниками служат металлические полоски на печатной плате. Шина подводится ко всем модулям, и каждый из них подсоединяется ко всем или некоторым ее линиям. Если ВМ конструктивно выполнена на нескольких платах, то все линии шины выводятся на разъемы, которые затем объединяются проводниками на общем шасси.
3. На языке С++ вычислить сумму ряда целых чисел от 1 до n.
#pragma hdrstop
//---------------------------------------------------------------------------
#include <iostream.h>
void main()
{
int N,S=0,i;
cout<<"\n Vvedite N ==";
cin>>N;
for(i=1;i<=N;i++) S=S+i;
cout<<"\n Summa =="<<S;
}
Билет 22.
1. Сети Петри. Моделирование процессов на основе сетей Петри.
Для моделирования производственных процессов широко применяют имитационные модели. Имитационные модели применяют, когда необходимо обеспечить наблюдение за ходом процесса в течение определенного временного периода (или когда невозможно применить аналитические модели математического программирования к решению задач управления). При построении имитационных моделей выбирают некоторые базовые единицы модели – объекты, или сущности. Это могу различные физические объекты, например, производственный участок, единица оборудования, деталь, узел и т.д. Объектам присваивают атрибуты. Фиксированные атрибуты описывают природу и характеристики объекта, переменные – состояние объекта. Состояние моделируемой системы описывается состояниями всех характеризующих ее объектов. Связи между объектами задаются атрибутами. Фиксированные атрибуты описывают статические, переменные – динамические связи. В зависимости от характера изменения атрибутов различают непрерывные и дискретные модели. В моделях дискретных событий выделяют набор работ. Такими работами, например, могут быть технологические операции по обработке деталей. Построение модели в этом случае состоит в логико-математическом описании соответствующих работ, событий и процессов.
Абстрактные автоматы
Абстрактные автоматы используют для описания объектов АСУ, для которых характерно наличие дискретных состояний и дискретный характер работы во времени. К числу таких объектов относятся элементы и узлы ЭВМ, устройства контроля и регулирования, системы коммутации, программы и операционные системы.
Абстрактный автомат можно представить видом:
, где
- конечное множество входных сигналов (входной алфавит автомата);
- конечное множество выходных сигналов (выходной алфавит автомата);
- выходное множество состояний автомата;
- начальное состояние автомата;
- функция переходов автомата,
- функция выходов или сдвинутая функция выходов.
Функции и задают однозначное отображение множества , где и в множества X и Y. Автомат, заданный функцией выходов, называется автоматом первого рода, автомат, заданный сдвинутой функцией выходов, - автоматом второго рода.
Абстрактный автомат функционирует в дискретном времени, принимающем целые неотрицательные значения В каждый момент времени автомат имеет определенное состояние из множества Z состояний автомата, причём в начальный момент времени автомат всегда находится в начальном состоянии , т.е. . В каждый момент времени , отличный от начального, автомат способен воспринимать входной сигнал - и выдавать соответствующий выходной сигнал. Закон функционирования абстрактного автомата первого рода задаётся уравнениями ;
Сети Петри
В абстрактном автомате рассматриваются последовательные переходы состояния. Поэтому такая модель неприменима для объектов, способных выполнять свои функции параллельно. Для моделирования таких объектов используют сети Петри. Сети Петри – это инструмент описания и исследования мультипрограммных, асинхронных, распределенных, параллельных, недетерминированных и/или стохастических систем обработки информации.
В качестве графического средства сети Петри могут использоваться для наглядного представления моделируемой системы, подобно блок-схемам, структурным схемам и сетевым графикам. Вводимое в этих сетях понятие фишек позволяет моделировать динамику функционирования систем и параллельные процессы. В качестве математического средства аналитическое представление сети Петри позволяет составлять уравнения состояния, алгебраические уравнения и другие математические соотношения, описывающие динамику систем.
Моделирование в сетях Петри осуществляется на событийном уровне. Определяются, какие действия происходят в системе, какие состояние предшествовали этим действиям и какие состояния примет система после выполнения действия. Выполнения событийной модели в сетях Петри описывает поведение системы. Анализ результатов выполнения может сказать о том, в каких состояниях пребывала или не пребывала система, какие состояния в принципе не достижимы. Однако такой анализ не дает числовых характеристик, определяющих состояние системы.
Простая Сеть Петри из трех элементов: множество мест, множество переходов и отношение инцидентности. Сети Петри имеют удобную графическую форму представления в виде графа, в котором места изображаются кружками, а переходы прямоугольниками. Места и переходы соединяются направленными дугами, каждой дуге сопоставляется некоторое натуральное число. Это число называется кратностью дуги, которое графически изображается рядом с дугой. Дуги, имеющие единичную кратность, обозначаются без приписывания единицы.
Само по себе понятие сети имеет статическую природу. Для задания динамических характеристик используется понятие маркировки сети. Графически маркировка изображается в виде точек, называемых метками (tokens), и располагающихся в кружках, соответствующих местам сети. Отсутствие меток в некотором месте говорит о нулевой маркировке этого места.
Сети Петри могут применяться:
1) Для моделирования бизнес-процессов. Функциональные диаграммы в нотации IDEF3 могут быть преобразованы в сеть Петри. Каждой работе на диаграмме соответствует переход сети Петри. Позиции соответствуют стрелкам, соединяющим работы напрямую и перекресткам. Метки соответствуют продукции, документов и т.д. Причем в зависимости от перехода интерпретация метки может отличаться.
2) Для моделирования параллельных вычислений и устройств. Если представить себе переход как процедуру, то она корректно выполняется при наличии значений всех своих аргументов и вырабатывает значения всех выходных переменных. В таком случае входные позиции перехода соответствуют аргументам, выходные – возвращаемым значениям. В другой интерпретации переход может представлять некоторое устройство. Устройство может (но не должно) сработать, если выполнились все входные условия.
3) Для моделирования процесса обучения. Тогда позиция соответствует некоторому состоянию процесса обучения, метка сопоставляется обучаемому, переход ассоциируется с изучением какой-либо темы обучаемым.
Сети Петри — математический аппарат для моделирования динамических дискретных систем. Впервые описаны Карлом Петри в 1962 году.
Сеть Петри представляет собой двудольный ориентированный граф, состоящий из вершин двух типов — позиций и переходов, соединённых между собой дугами, вершины одного типа не могут быть соединены непосредственно. В позициях могут размещаться метки (маркеры), способные перемещаться по сети.
Событием называют срабатывание перехода, при котором метки из входных позиций этого перехода перемещаются в выходные позиции. События происходят мгновенно, разновременно при выполнении некоторых условий.
Виды сетей Петри
Некоторые виды сетей Петри:
Временная сеть Петри — переходы обладают весом, определяющим продолжительность срабатывания (задержку).
Стохастическая сеть Петри — задержки являются случайными величинами.
Функциональная сеть Петри — задержки определяются как функции некоторых аргументов, например, количества меток в каких-либо позициях, состояния некоторых переходов.
Цветная сеть Петри — метки могут быть различных типов, обозначаемых цветами, тип метки может быть использован как аргумент в функциональных сетях.
Ингибиторная сети Петри — возможны ингибиторные дуги, запрещающие срабатывания перехода, если во входной позиции, связанной с переходом ингибиторной дугой находится метка.
Анализ сетей Петри
Основными свойствами сети Петри являются:
Ограниченность — число меток в любой позиции сети не может превысить некоторого значения K.
Безопасность — частный случай ограниченности, K=1.
Сохраняемость — постоянство загрузки ресурсов, постоянна. Где Ni — число маркеров в i-той позиции, Ai — весовой коэффициент.
Достижимость — возможность перехода сети из одного заданного состояния (характеризуемого распределением меток) в другое.
Живость — возможностью срабатывания любого перехода при функционировании моделируемого объекта.
В основе исследования перечисленных свойств лежит анализ достижимости.
Моделирование в сетях Петри осуществляется на событийном уровне. Определяются, какие действия происходят в системе, какие состояние предшествовали этим действиям и какие состояния примет система после выполнения действия. Выполнения событийной модели в сетях Петри описывает поведение системы. Анализ результатов выполнения может сказать о том, в каких состояниях пребывала или не пребывала система, какие состояния в принципе не достижимы. Однако, такой анализ не дает числовых характеристик, определяющих состояние системы. Развитие теории сетей Петри привело к появлению, так называемых, “цветных” сетей Петри. Понятие цветности в них тесно связано с понятиями переменных, типов данных, условий и других конструкций, более приближенных к языкам программирования. Несмотря на некоторые сходства между цветными сетями Петри и программами, они еще не применялись в качестве языка программирования.
Не смотря на описанные выше достоинства сетей Петри, неудобства применения сетей Петри в качестве языка программирования заключены в процессе их выполнения в вычислительной системе. В сетях Петри нет строго понятия процесса, который можно было бы выполнять на указанном процессоре. Нет также однозначной последовательности исполнения сети Петри, так как исходная теория представляет нам язык для описания параллельных процессов.
2. Организация памяти ЭВМ.
В любой ВМ, вне зависимости от ее архитектуры, программы и данные хранятся в памяти. Функции памяти обеспечиваются запоминающими устройствами (ЗУ), предназначенными для фиксации, хранения и выдачи информации в процессе работы ВМ. Процесс фиксации информации в ЗУ называется записью, процесс выдачи информации — чтением или считыванием, а совместно их определяют как процессы обращения к ЗУ.
Характеристики систем памяти Перечень основных характеристик, которые необходимо учитывать, рассматривая конкретный вид ЗУ, включает в себя: место расположения; емкость; единицу пересылки; метод доступа; быстродействие; физический тип; физические особенности; стоимость.
По месту расположения ЗУ разделяют на процессорные, внутренние и внешние. Наиболее скоростные виды памяти (регистры, кэш-память первого уровня) обычно размещают на общем кристалле с центральным процессором, а регистры общего назначения вообще считаются частью ЦП. Вторую группу (внутреннюю память) образуют ЗУ, расположенные на системной плате. К внутренней памяти относят основную память, а также кэш-память второго и последующих уровней (кэш-память второго уровня может также размещаться на кристалле процессора). Медленные ЗУ большой емкости (магнитные и оптические диски, магнитные ленты) называют внешней памятью, поскольку к ядру ВМ они подключаются аналогично устройствам ввода/вывода.
Емкость ЗУ характеризуют числом битов либо байтов, которое может храниться в запоминающем устройстве. На практике применяются более крупные единицы, а для их обозначения к словам «бит» или «байт» добавляют приставки: кило, мега, гига, тера, пета, экза (kilo, mega, giga, tera, peta, exa). Стандартно эти приставки означают умножение основной единицы измерений на 103, 10G, 109, 1012, 1015и 101 соответственно. В вычислительной технике, ориентированной на двоичную систему счисления, они соответствуют значениям достаточно близким к стандартным, но представляющим собой целую степень числа 2, то есть 210, 220, 230, 240, 250, 260. Во избежание разночтений, в последнее время ведущие международные организации по стандартизации, например IEEE (Institute of Electrical and Electronics Engineers), предлагают ввести новые обозначения, добавив к основной приставке слово binary (бинарный): kilobinary, megabinary, gigabinary, terabinary, petabinary, exabinary. В результате вместо термина «килобайт» предлагается термин «киби-байт», вместо «мегабайт» — «мебибайт» и т. д. Для обозначения новых единиц предлагаются сокращения: Ki, Mi, Gi, Ti, Pi и Ei.
Важной характеристикой ЗУ является единица пересылки. Для основной памяти (ОП) единица пересылки определяется шириной шины данных, то есть количеством битов, передаваемых по линиям шины параллельно. Обычно единица пересылки равна длине слова, но не обязательно. Применительно к внешней памяти данные часто передаются единицами, превышающими размер слова, и такие единицы называются блоками.
При оценке быстродействия необходимо учитывать применяемый в данном типе ЗУ метод доступа к данным. Различают четыре основных метода доступа:
Последовательный доступ. ЗУ с последовательным доступом ориентировано на хранение информации в виде последовательности блоков данных, называемых записями. Для доступа к нужному элементу (слову или байту) необходимо прочитать все предшествующие ему данные. Время доступа зависит от положения требуемой записи в последовательности записей на носителе информации и позиции элемента внутри данной записи. Примером может служить ЗУ на магнитной ленте.
Прямой доступ. Каждая запись имеет уникальный адрес, отражающий ее физическое размещение на носителе информации. Обращение осуществляется как адресный доступ к началу записи, с последующим последовательным доступом к определенной единице информации внутри записи. В результате время доступа к определенной позиции является величиной переменной. Такой режим характерен для магнитных дисков.
Произвольный доступ. Каждая ячейка памяти имеет уникальный физический адрес. Обращение к любой ячейке занимает одно и то же время и может производиться в произвольной очередности. Примером могут служить запоминающие устройства основной памяти.
Ассоциативный доступ. Этот вид доступа позволяет выполнять поиск ячеек, содержащих такую информацию, в которой значение отдельных битов совпадает с состоянием одноименных битов в заданном образце. Сравнение осуществляется параллельно для всех ячеек памяти, независимо от ее емкости. По ассоциативному принципу построены некоторые блоки кэш-памяти.
Быстродействие ЗУ является одним из важнейших его показателей.
Для количественной оценки быстродействия обычно используют три параметра:
Время доступа (ТД). Для памяти с произвольным доступом оно соответствует интервалу времени от момента поступления адреса до момента, когда данные заносятся в память или становятся доступными. В ЗУ с подвижным носителем информации — это время, затрачиваемое на установку головки записи/считывания (или носителя) в нужную позицию.
Длительность цикла памяти или период обращения (Гц). Понятие применяется к памяти с произвольным доступом, для которой оно означает минимальное время между двумя последовательными обращениями к памяти. Период обращения включает в себя время доступа плюс некоторое дополнительное время. Дополнительное время может требоваться для затухания сигналов на линиях, а в некоторых типах ЗУ, где считывание информации приводит к ее разрушению, — для восстановления считанной информации.
Скорость передачи. Это скорость, с которой данные могут передаваться в память или из нее. Говоря о физическом типе запоминающего устройства, необходимо упомянуть три наиболее распространенных технологии ЗУ — это полупроводниковая память, память с магнитным носителем информации, используемая в магнитных дисках и лентах, и память с оптическим носителем — оптические диски.
В зависимости от примененной технологии следует учитывать и ряд физических особенностей ЗУ, например энергозависимость. В энергозависимой памяти информация может быть искажена или потеряна при отключении источника питания. В энергонезависимых ЗУ записанная информация сохраняется и при отключении питающего напряжения. Магнитная и оптическая память — энергонезависимы. Полупроводниковая память может быть как энергозависимой, так и нет, в зависимости от ее типа. Помимо энергозависимости нужно учитывать, приводит ли считывание информации к ее разрушению.
3. Информация о студенте включает: ФИО, порядковый номер, название факультета, номер специальности, дату рождения, адрес проживания, телефон. Информация о студентах хранится в виде записей в массиве. Число записей в массиве 100. Отсортировать всех студентов в алфавитном порядке. Обосновать выбор алгоритма сортировки.
|
program Project12;
{$APPTYPE CONSOLE}
uses SysUtils, Windows;
//Program Zad_12; //Uses Crt; Type Student = Record Number:Word; FIO:String[20]; Fakul:String[10]; Spech:String[6]; DateRog:String[10]; Addres:String[15]; Teleph:String[10]; End; Var Spisok: array [1..101] of Student; N,i,j,Imin:Integer; Min:String;
Begin //ClrScr; Write('Number of Students = '); Readln(N); For i:=1 To N do Begin Write('Poridkovyi nomer == '); Readln(Spisok[i].Number); Write('FIO == '); Readln(Spisok[i].FIO); Write('Naimenovanie fakulteta == '); Readln(Spisok[i].Fakul); Write('Number spechialnosti == '); Readln(Spisok[i].Spech); Write('Date rogdeniya == '); Readln(Spisok[i].DateRog); Write('Address == '); Readln(Spisok[i].Addres); Write('Telephone == '); Readln(Spisok[i].Teleph); End;
|
For i:=1 To N-1 Do Begin Min:=Spisok[i].FIO; Imin:=i; For j:=i+1 To N Do If Spisok[j].FIO < Min Then Begin Min :=Spisok[j].FIO; Imin:=j; End; Spisok[N+1].Number:=Spisok[i].Number; Spisok[N+1].FIO:=Spisok[i].FIO; Spisok[N+1].Fakul:=Spisok[i].Fakul; Spisok[N+1].Spech:=Spisok[i].Spech; Spisok[N+1].DateRog:=Spisok[i].DateRog; Spisok[N+1].Addres:=Spisok[i].Addres; Spisok[N+1].Teleph:=Spisok[i].Teleph;
Spisok[i].Number:=Spisok[Imin].Number; Spisok[i].FIO:=Min; Spisok[i].Fakul:=Spisok[Imin].Fakul; Spisok[i].Spech:=Spisok[Imin].Spech; Spisok[i].DateRog:=Spisok[Imin].DateRog; Spisok[i].Addres:=Spisok[Imin].Addres; Spisok[i].Teleph:=Spisok[Imin].Teleph; Spisok[Imin].Number:=Spisok[N+1].Number; Spisok[Imin].FIO:=Spisok[N+1].FIO; Spisok[Imin].Fakul:=Spisok[N+1].Fakul; Spisok[Imin].Spech:=Spisok[N+1].Spech; Spisok[Imin].DateRog:=Spisok[N+1].DateRog; Spisok[Imin].Addres:=Spisok[N+1].Addres; Spisok[Imin].Teleph:=Spisok[N+1].Teleph; End; //Clrscr; For i:=1 To N Do Begin Writeln(Spisok[i].Number,' ', Spisok[i].FIO,' ', Spisok[i].Fakul,' ' ,Spisok[i].Spech, ' ',Spisok[i].DateRog); Writeln(' ',Spisok[i].Addres,' ',Spisok[i].Teleph); End; Readln; End.
|
Билет 23.
1. Понятия прерывания. Виды прерываний. Механизмы прерываний.
Прерывания – механизм, позволяющий координировать параллельное функционирование отдельных устройств вычислительной системы и реагировать на особые ситуации, возникающие при работе процессора. Прерывания – принудительная передача управления от выполняемой программы к системе, происходящее при возникновении определенного события.
Прерывания, возникающие при работе вычислительной системы, можно разделить на два основных класса:
- внешние (асинхронные);
- внутренние (синхронные).
Внешние прерывания вызываются асинхронными событиями, которые происходят вне прерываемого процесса, например:
- прерывания от таймера;
- прерывания от внешнего устройства (прерывания по вводу/выводу);
- прерывания по нарушению питания;
- прерывания с пульта оператора вычислительной системы;
- прерывания от другого процессора или другой вычислительной системы.
Внутренние прерывания вызываются событиями, которые связаны с работой процессора и являются синхронными с его операциями, например:
- нарушение адресации;
- наличие в поле адреса несуществующей инструкции;
- деление на нуль;
- переполнение или исчезновение порядка;
- ошибка четности;
- ошибка в работе различных аппаратных устройств.
Собственно программные прерывания происходят по соответствующей команде прерывания, то есть по этой команде процессор производит те же действия, что и при обычных внутренних прерываниях. Данный механизм введен для того, чтобы переключение на системные программные модули происходило не как переход в подпрограмму, а как обычное прерывание. Этим обеспечивается автоматическое переключение процессора в привилегированный режим с возможностью выполнения всех команд.
Основная цель введения прерываний – реализация асинхронного режима работы и распараллеливание работы отдельных устройств вычислительного комплекса.
Механизм прерываний реализуется аппаратно-программным способом. Прерывание всегда влечет за собой изменение порядка выполнения команд процессором.
Механизм обработки прерываний включает следующие шаги:
1) установление факта прерывания и его идентификация;
2) запоминание состояния прерванного процесса (счетчика команд, содержимого регистров процессора, спецификации режима и др.);
3) аппаратная передача управления подпрограмме обработки прерываний;
4) сохранение информации о прерванной программе, которую не удалось сохранить на шаге 2 с помощью действий аппаратуры, иногда большого объема информации;
5) обработка прерываний;
6) восстановление информации, относящейся к прерванному процессу;
7) возврат в прерванную программу.
Шаги 1 – 3 реализуются аппаратно, а шаги 4 –7 программно.
Главные функции механизма прерываний:
- распознавание или классификация прерываний;
- передача управления на обработку прерываний;
- корректное возвращение к прерванной программе.
2. Инструментальные среды разработки и сопровождения программных средств и принципы их классификации. Основные классы инструментальных сред разработки и сопровождения программных средств.
В настоящее время с каждой системой программирования связываются не отдельные инструменты (например, компилятор), а некоторая логически связанная совокупность программных и аппаратных инструментов, поддерживающих разработку и сопровождение ПС на данном языке программирования или ориентированных на какую-либо конкретную предметную область. Такую совокупность называют инструментальной средой разработки и сопровождения ПС.
Инструментальная среда не обязательно должна функционировать на том компьютере, на котором должно будет применяться разрабатываемое с помощью ее ПС. Различают три основных класса инструментальных сред разработки и сопровождения ПС:
• среды программирования,
• рабочие места компьютерной технологии,
• инструментальные системы технологии программирования.
Среда программирования предназначена в основном для поддержки процессов программирования (кодирования), тестирования и отладки ПС. Рабочее место компьютерной технологии ориентировано на поддержку ранних этапов разработки ПС (спецификаций) и автоматической генерации программ по спецификациям. Инструментальная система технологии программирования предназначена для поддержки всех процессов разработки и сопровождения в течение всего жизненного цикла ПС и ориентирована на коллективную разработку больших программных систем с длительным жизненным циклом. Для таких систем стоимость сопровождения обычно превышает стоимость разработки.
Инструментальные среды программирования.
Инструментальные среды программирования содержат, прежде всего, текстовый редактор, позволяющий конструировать программы на заданном языке программирования, инструменты, позволяющие компилировать или интерпретировать программы на этом языке, а также тестировать и отлаживать полученные программы. Кроме того, могут быть и другие инструменты, например, для статического или динамического анализа программ. Взаимодействуют эти инструменты между собой через обычные файлы с помощью стандартных возможностей файловой системы.
Различают следующие классы инструментальных сред программирования:
• среды общего назначения,
• языково-ориентированные среды.
Инструментальные среды программирования общего назначения содержат набор программных инструментов, поддерживающих разработку программ на разных языках программирования (например, текстовый редактор, редактор связей или интерпретатор языка целевого компьютера) и обычно представляют собой некоторое расширение возможностей используемой операционной системы. Для программирования в такой среде на каком-либо языке программирования потребуются дополнительные инструменты, ориентированные на этот язык (например, компилятор).
Языково-ориентированная инструментальная среда программирования предназначена для поддержки разработки ПС на каком-либо одном языке программирования и знания об этом языке существенно использовались при построении такой среды. Вследствие этого в такой среде могут быть доступны достаточно мощные возможности, учитывающие специфику данного языка. Такие среды разделяются на два подкласса:
• интерпретирующие среды,
• синтаксически-управляемые среды.
Интерпретирующая инструментальная среда программирования обеспечивает интерпретацию программ на данном языке программирования, т.е. содержит прежде всего интерпретатор языка программирования, на который эта среда ориентирована. Такая среда необходима для языков программирования интерпретирующего типа (таких, как Лисп), но может использоваться и для других языков (например, на инструментальном компьютере). Синтаксически-управляемая инструментальная среда программирования базируется на знании синтаксиса языка программирования, на который она ориентирована. В такой среде вместо текстового используется синтаксически-управляемый редактор, позволяющий пользователю использовать различные шаблоны синтаксических конструкций (в результате этого разрабатываемая программа всегда будет синтаксически правильной). Одновременно с программой такой редактор формирует (в памяти компьютера) ее синтаксическое дерево, которое может использоваться другими инструментами.
Понятие компьютерной технологии разработки программных средств и ее рабочие места.
В настоящее время компьютерную технологию разработки ПС можно характеризовать использованием:
• программной поддержки для разработки графических требований и графических спецификаций ПС,
• автоматической генерации программ на каком-либо языке программирования или в машинном коде (частично или полностью),
• программной поддержки прототипирования.
Говорят также, что компьютерная технология разработки ПС является "безбумажной", т.е. рассчитанной на компьютерное представление программных документов.
На наш взляд, главное отличие ручной технологии разработки ПС от компьютерной заключается в следующем. Ручная технология ориентирована на разработку документов, одинаково понимаемых разными разработчиками ПС, тогда как компьютерная технология ориентирована на обеспечение семантического понимания (интерпретации) документов программной поддержкой компьютерной технологии. Компьютерное представление документов еще не означает такого их понимание. Тогда как семантическое понимание документов дает программной поддержке возможность автоматической генерации программ, а необходимость обеспечения такого понимания делает желательными и различные графические формы входных документов. Именно это позволяет рационально изменить и саму совокупность технологических процессов разработки и сопровождения ПС.
Из проведенного обсуждения сущности компьютерной технологии можно понять и связанные с ней изменения в жизненном цикле ПС. Если при использовании ручной технологии основные усилия по разработке ПС делались на этапах собственно программирования (кодирования) и отладки (тестирования), то при использовании компьютерной технологии - на ранних этапах разработки ПС (определения требований и функциональной спецификации). При этом существенно изменился характер документации: вместо целой цепочки неформальных документов, ориентированной на передачу информации от заказчика (пользователя) к различным категориям разработчикам, формируются прототип ПС, поддерживающий выбранный пользовательский интерфейс, и формальные функциональные спецификации, достаточные для автоматического синтеза (генерации) программ ПС (или хотя бы значительной их части). При этом появилась возможность автоматической генерации части документации, необходимой разработчикам и пользователям. Вместо ручного программирования (кодирования) - автоматическая генерация программ, что делает не нужной автономную отладку и тестирование программ: вместо нее добавляется достаточно глубокий автоматический семантический контроль документации. Существенно изменяется и характер сопровождения ПС: все изменения разработчиком-сопроводителем вносятся только в спецификации (включая и прототип), остальные изменения в ПС осуществляются автоматически.
Прототипирование позволяет заменить косвенное описание взаимодействия между пользователем и ПС при ручной технологии (при определении требований к ПС и внешнем описании ПС) прямым выбором пользователем способа и стиля этого взаимодействия с фиксацией всех необходимых деталей. По-существу, на этом этапе производится точное описание пользовательского интерфейса, понятное программной поддержке компьютерной технологии, причем с ответственным участием пользователя: разработчик показывает пользователю на мониторе различные возможности и пользователь выбирает приемлемые для него варианты, пользователь с помощью разработчика вводит обозначения обрабатываемых им информационных объектов и операций над ними, он выбирает способ доступа к ним и связывает их с различными окнами, меню, виртуальными клавиатурами и т.п. Все это базируется на наличие в программной поддержке компьютерной технологии настраиваемой оболочки с обширной библиотекой заготовок различных фрагментов и деталей экрана. В результате указанных действий определяется оболочка ПС - верхний управляющий уровень ПС. Такое прототипирование, по-видимому, является лучшим способом преодоления барьера между пользователем и разработчиком.
Разработка спецификаций распадается на несколько разных процессов. Если исключить начальный этап разработки спецификаций (определение требований), то в этих процессах используются методы, приводящие к созданию формализованных документов, т. е. используются формализованные языки спецификаций. При этом широко используются графические методы спецификаций, приводящие к созданию различных схем и диаграмм, которые достаточно формализованно определяют структуру информационной среды и структуру управления ПС. К таким структурам привязываются фрагменты описания данных и программ, представленные на алгебраических языках спецификаций (например, использующие операционную или аксиоматическую семантику), или логических языках спецификаций (базирующихся на логическом подходе к спецификации программ). Такие спецификации позволяют в значительной степени или полностью автоматически генерировать программы.
Инструментальные системы технологии программирования.
Для компьютерной поддержки разработки и сопровождения больших ПС с продолжительным жизненным циклом используются инструментальные системы технологии программирования. Инструментальная система технологии программирования - это интегрированная совокупность программных и аппаратных инструментов, поддерживающая все процессы разработки и сопровождения больших ПС в течение всего его жизненного цикла в рамках определенной технологии. Из этого определения вытекают следующие основные черты этого класса компьютерной поддержки:
• комплексность,
• ориентированность на коллективную разработку,
• технологическая определенность,
• интегрированность.
Комплексность компьютерной поддержки означает, что она охватывает все процессы разработки и сопровождения ПС и что продукция этих процессов согласована и взаимоувязана. Тем самым, система в состоянии обеспечить, по-крайней мере, контроль полноты (комплектности) создаваемой документации (включая набор программ) и согласованности ее изменения (версионности). Тот факт, что компьютерная поддержка охватывает и фазу сопровождения ПС, означает, что система должна поддерживать работу сразу с несколькими вариантами ПС, ориентированными на разные условия применения ПС и на разную связанную с ним аппаратуру, т.е. должна обеспечивать управление конфигурацией ПС.
Ориентированность на коллективную разработку означает, что система должна поддерживать управление (management) работой коллектива и для разных членов этого коллектива обеспечивать разные права доступа к различным фрагментам продукции технологических процессов.
Технологическая определенность компьютерной поддержки означает, что ее комплексность ограничивается рамками какой-либо конкретной технологии программирования. Инструментальные системы технологии программирования представляют собой достаточно большие и дорогие ПС, чтобы как-то была оправданна их инструментальная перегруженность. Поэтому набор включаемых в них инструментов тщательно отбирается с учетом потребностей предметной области, используемых языков и выбранной технологией программирования.
Интегрированность компьютерной поддержки означает
• интегрированность по данным, •
• интегрированность по пользовательскому интерфейсу,
• интегрированность по действиям (функциям).
Интегрированность по данным означает, что инструменты действуют в соответствии с фиксированной информационной схемой (моделью) системы, определяющей зависимость различных используемых в системе фрагментов данных (информационных объектов) друг от друга. Интегрированность по пользовательскому интерфейсу означает, что все инструменты объединены единым пользовательским интерфейсом. Интегрированность по действиям означает, что, во-первых, в системе имеются общие части всех инструментов и, во-вторых, одни инструменты при выполнении своих функций могут обращаться к другим инструментам.
С учетом обсужденных свойств инструментальных систем технологии программирования можно выделить три их основные компоненты:
• база данных разработки (репозиторий),
• инструментарий,
• интерфейсы.
Репозиторий - центральное компьютерное хранилище информации, связанной с проектом (разработкой) ПС в течение всего его жизненного цикла. Инструментарий - набор инструментов, определяющий возможности, предоставляемые системой коллективу разработчиков. Обычно этот набор является открытым: помимо минимального набора (встроенные инструменты), он содержит средства своего расширения (импортированными инструментами), - и структурированным, состоящим из некоторой общей части всех инструментов (ядра) и структурных (иногда иерархически связанных) классов инструментов. Интерфейсы разделяются на пользовательские и системные. Пользовательский интерфейс обеспечивает доступ разработчикам к инструментарию (командный язык и т.п.), реализуется оболочкой системы. Системные интерфейсы обеспечивают взаимодействие между инструментами и их общими частями. Системные интерфейсы выделяются как архитектурные компоненты в связи с открытостью системы - их обязаны использовать новые (импортируемые) инструменты, включаемые в систему.
Различают два класса инструментальных систем технологии программирования: инструментальные системы поддержки проекта и языково-зависимые инструментальные системы. Инструментальная система поддержки проекта - это открытая система, способная поддерживать разработку ПС на разных языках программирования после соответствующего ее расширения программными инструментами, ориентированными на выбранный язык. Такая система содержит ядро (обеспечивающее, в частности, доступ к репозиторию), набор инструментов, поддерживающих управление разработкой ПС, независимые от языка программирования инструменты, поддерживающие разработку ПС (текстовые и графические редакторы, генераторы отчетов и т.п.), а также инструменты расширения системы. Языково-зависимая инструментальная система - это система поддержки разработки ПС на каком-либо одном языке программирования, существенно использующая в организации своей работы специфику этого языка. Эта специфика может сказываться и на возможностях ядра (в том числе и на структуре репозитория), и на требованиях к оболочке и инструментам. Примером такой системы является среда поддержки программирования на Аде (APSE).
3. Построить программу на языке С++ для работы со структурой Дата. Программа должна обеспечивать простейшие функции для работы с данными структуры: увеличение/уменьшение на 1 день, ввод значений, вывод значений.
interface
Uses SysUtils;
type TUserDate = class
private
fNumber:Word;
fMonth:word;
fYear:Integer;
public
Function SetUserDate(ANumber:Word;AMonth:Word;AYear:Integer):Boolean;
Function GetUserDate:String;
Function ModifyDate(AModify:Integer):String;
end;
implementation
Function TUserDate.SetUserDate;
Begin
If AYear>0 Then
Begin
fYear:=AYear;
if (AMonth >0) and (AMonth<=12) Then
Begin
fMonth:=AMonth;
fNumber:=0;
if ((fMonth=1)or(fMonth=3)or(fMonth=5)or(fMonth=7)or(fMonth=8)or(fMonth=10)or(fMonth=12))and(ANumber>0)and(ANumber<=31) Then
fNumber:=ANumber;
if ((fMonth=4)or(fMonth=6)or(fMonth=9)or(fMonth=11))and(ANumber>0)and(ANumber<=30) Then
fNumber:=ANumber;
if (fMonth=2) Then
if (fYear mod 4 = 0) Then
if (ANumber>0) and (ANumber<=29) Then fNumber:=ANumber
else
if (ANumber>0) and(ANumber<=28) Then fNumber:=ANumber;
if fNumber<>0 Then Result:=True else Result:=False;
end
else Result:=False;
end
else
Result:=False;
End;
Function TUserDate.GetUserDate;
Var str,Itog:String;
Begin
Itog:='';
str:=IntToStr(fNumber);
If length(str)=1 Then Itog:=Itog+'0';
Itog:=Itog+str+'.';
str:=IntToStr(fMonth);
if length(str)=1 Then Itog:=Itog+'0';
Itog:=Itog+str+'.';
Itog:=Itog+IntToStr(fYear);
Result:=Itog
End;
//Данная функция очень утрирована
Function TUserDate.ModifyDate;
Begin
fNumber:=fNumber+ AModify;
Result:=GetUserDate;
End;
end.
Тело программы
program Zad_17;
{$APPTYPE CONSOLE}
uses
SysUtils,
STR_Date in 'STR_Date.pas';
var UsDate:TUserDate;
Y:Integer;
N,M:Word;
F:Boolean;
begin
repeat
Write('Vvedite YEAR = ');
Readln(Y);
Write('Vvedite MONTH = ');
Readln(M);
Write('Vvedite Number = ');
Readln(N);
UsDate:=TUserDate.Create;
F:=UsDate.SetUserDate(N,M,Y);
if F=False Then Writeln('ERROR Date');
Until F;
Writeln('Vvedena Date =>> ',UsDate.GetUserDate);
Write('Vvedite znachenie izmenenij = ');
Readln(Y);
Writeln('New date =>> ',UsDate.ModifyDate(Y));
Readln;
{ TODO -oUser -cConsole Main : Insert code here }
end.
Билет 24.
1. Динамическое поведение объектов. Состояния, события, сигналы и сообщения. Модели взаимодействия объектов.
Рассмотрим существующие типы сообщений и приемы их визуального представления с помощью диаграмм последовательности. При одностороннем вызове управление возвращается объекту, инициировавшему вызов, сразу после принятия вызова объектом-получателем (рис. 1.24 а). Объект-отправитель продолжает функционировать одновременно с выполнением запрашиваемой операции. Синхронизация между объектами отсутствует.
Односторонние вызовы используются объектом-отправителем, когда не требуется ожидать завершения выполнения операции. Операция не возвращает результат своей работы. Следовательно, подразумевается, что такая операция не может нарушить целостность работы объекта-получателя.
При выполнении синхронных вызовов (рис. 1.24 б) объект-отправитель блокируется на все время выполнения операции объектом-получателем. Результат работы операции или сообщение о возникших ошибках возвращаются объекту-отправителю. Только после этого объект сможет продолжить свою дальнейшую работу. Типичный пример синхронного вызова – выполнение методов объекта. Способы ослабления синхронности показаны на рис. 1.24 (в, г).
Отсроченные синхронные вызовы объединяют свойства двух выше рассмотренных. Как и односторонние, они сразу же возвращают управление, но могут использоваться в тех случаях, когда необходимо получить результат выполнения операции. Для этой цели существует специальный объект-посредник, который создается в момент завершения операции и которому передается служебная информация объектом-получателем.
В результате объект-отправитель получает информацию об операции от объект-посредника. Недостатком такого способа является необходимость периодической проверки (опроса), что, конечно, повышает его ресурсоемкость. Типичный прием применения техники отсроченного синхронного вызова заключается в использовании флага (некоторой булевой переменной), находящегося в области видимости обоих объектов. После выполнения операции статус флага изменяется, а объект-отправитель периодически его проверяет, отслеживая изменение.
Асинхронные вызовы не ожидают окончания работы объекта-получателя, а выполняются в отдельном потоке управления. Передача асинхронных сообщений предполагает существование множественных потоков управления и в основном характерна для инженерных приложений и приложений реального времени.
Обратные вызовы позволяют проинформировать объект-отправитель о завершении обработки сообщения путем передачи ему асинхронного сообщения (рис. 1.24 г.). Перед выполнением вызова объекту-получателю сообщается адрес некоторой функции обратного вызова (callback function) объекта-отправителя. По завершении обработки сообщения выполняется обратный вызов.
Автосообщения предназначены для передачи объектом сообщений самому себе. В этом случае происходит локальный вызов – один метод вызывает другой метод одного и того же объекта. Само название автосообщение заимствовано из языка SmallTalk. Применительно к объекту в языках C++ и Java автосообщению соответствует термин this, а в языке Object Pascal – self. Соответствующий объект представляет собой константу, которая хранит идентификатор объекта OID. При необходимости автообъект может быть передан как аргумент в сообщении.
|
а). Односторонний вызов. |
б). Синхронный вызов. |
|
в). Отсроченный синхронный вызов. |
г). Обратный вызов.
|
Рис. 1.24. Способы синхронизации объектов.
В UML сообщения имеют специальное обозначение (рис. 1.25). Направление стрелки указывает на получателя сообщения. Стрелка на рис. 1.25 а обозначает простой вызов процедуры. Обычно такие сообщения являются синхронными. Стрелка на рис. 1.25 б обозначает простой поток управления. Каждая такая стрелка изображает один этап в последовательности потока управления. Стрелка на рис. 1.25 в используется для обозначения асинхронного потока управления. Соответствующие сообщения формируются в произвольные, заранее не известные моменты времени, как правило, активными объектами. Стрелка на рис. 1.25 г обозначает возврат из вызова процедуры.
В UML предусмотрены стандартные действия (стереотипы), выполняемые в ответ на получение соответствующего сообщения. Они могут быть явно указаны на диаграмме рядом с сообщением, к которому они относятся. В этом случае они записываются в кавычках.
Используются следующие обозначения для моделирования действий:
"call" (вызвать) – сообщение, требующее вызова операции или процедуры принимающего объекта. Если сообщение с таким стереотипом рефлексивное, то оно инициирует локальный вызов операции у пославшего это сообщение объекта;
"return" (возвратить) – сообщение, возвращающее значение выполненной операции вызвавшему ее объекту;
"create" (создать) – сообщение, требующее создания другого объекта для выполнения определенных действий. Созданный объект может получить фокус управления;
"destroy" (уничтожить) – сообщение с требованием уничтожить соответствующий объект. Посылается в том случае, когда объект больше не нужен и должен освободить задействованные им системные ресурсы;
"send" (послать) – обозначает посылку другому объекту некоторого сообщения, который асинхронно (без временной синхронизации) инициируется одним объектом и принимается (перехватывается) другим.
Наряду с сообщениями в UML определены понятия события и сигнала. Событием является сообщение, при получении которого объектом происходит изменение его внутреннего состояния. Сигнал является событием особого рода, при котором событие передается асинхронно от одного объекта к другому. Если говорить точнее, сигнал – именованный объект, асинхронно возбуждаемый одним объектом и принимаемый другим. Примером могут служить объекты исключений, которые поддерживаются в ряде объектно-ориентированных языках программирования для обработки ошибок.
Активные и пассивные классы
Взаимодействия между объектами описываются сообщениями, которыми они обмениваются. Сообщения передают некоторую информацию от одного объекта другому. При этом первый объект ожидает, что после получения сообщения вторым объектом последует выполнение некоторого действия. Таким образом, сообщения являются причиной создания, уничтожения объектов и выполнения ими определенных операций.
Когда объект посылает сообщение другому объекту, объект-получатель может инициировать передачу нового сообщения следующему объекту и т.д. Такой поток сообщений формирует последовательность, которая всегда имеет начало в некотором потоке. Каждый поток в системе определяет отдельный поток управления. В каждом потоке управления сообщения упорядочены по времени.
Потоки не существуют сами по себе. Они порождаются процессами. Процесс (Process) – ресурсоемкий поток управления, который выполняется параллельно с другими процессами. Можно сказать, что поток (Thread) – это облегченный поток управления, т.е. требующий меньше системных ресурсов, и выполняемый одновременно с другими потоками в рамках одного процесса.
В UML каждый независимый поток управления моделируется как активный объект. Активный объект описывает поток и способен инициировать некоторое управляющее воздействие. Активный класс – это класс, экземплярами которого являются активные объекты. Для явного различения, обычные классы иначе называют пассивными, указывая тем самым, что класс не способен инициировать независимое управляющее воздействие.
Активный класс используется для представления потока, в контексте которого выполняется независимый поток управления, работающий параллельно с другими равноправными потоками в рамках данного процесса. Когда создается активный объект, запускается на выполнение ассоциированный с ним поток управления. Когда активный объект уничтожается, работка потока завершается.
Процесс известен операционной системе и располагается в отдельном адресном пространстве. Все потоки всегда выполняются в контексте некоторого процесса. Кроме того, процессы и потоки никогда не бывают вложенными. Современные операционные системы обеспечивают возможность существования множества процессов и одновременного (параллельного) исполнения множества потоков в контексте каждого процесса.
Активным классам присущи свойства обычных классов: они имеют атрибуты, методы, участвуют в отношениях зависимости, обобщения, ассоциации.
Активные и пассивные объекты могут взаимодействовать друг с другом посредством обмена сообщениями. Рассмотрим возможные комбинации такого взаимодействия. Первый случай – пассивный объект передает сообщение другому такому же. Если оба объекта существуют в одном потоке, такое сообщение есть обычный вызов метода другого объекта.
Второй случай – активный объект передает сообщение другому активному. Здесь имеет место межпотоковое взаимодействие, т.к. каждому активному объекту соответствует свой собственный поток. Заметим, что здесь мы не оговариваем, принадлежат ли потоки одному процессу или разным процессам. В любом случае возможны два варианта взаимодействия.
В первом случае объект, вызывающий операцию другого объекта ждет ее окончания для получения результата. На все время выполнения операции оба потока будут заблокированы, а после ее выполнения будут вновь работать независимо друг от друга. Такой вариант называется синхронным вызовом.
Во втором случае вызов выполняется асинхронно: объект запрашивает операцию, и, не дожидаясь окончания ее выполнения, продолжает работу. Если принимающая сторона не сможет сразу получить сообщение, сообщение ставится в очередь, из которой в дальнейшем оно будет извлечено. Таким образом, объекты не синхронизированы, получают и обрабатывают сообщения по мере их поступления.
Третий случай – передача сообщения от активного объекта пассивному. Здесь чрезвычайно важна синхронизация активных объектов между собой, т.к. они не могут одновременно передать сообщение пассивному объекту. Для решения этой задачи существуют специальные способы синхронизации.
Наконец, последний вариант взаимодействия – передача сообщения от пассивного объекта активному. Учитывая, что каждый поток управления принадлежит некоторому активному объекту, взаимодействие в этом случае сводится к взаимодействию между двумя активными объектами
2. Типы структур вычислительных машин и систем, перспективы и развития.
Типы структур вычислительных машин и систем Достоинства и недостатки архитектуры вычислительных машин и систем изначально зависят от способа соединения компонентов. При самом общем подходе можно говорить о двух основных типах структур вычислительных машин и двух типах структур вычислительных систем.
Структуры вычислительных машин В настоящее время примерно одинаковое распространение получили два способа построения вычислительных машин: с непосредственными связями и на основе шины. Типичным представителем первого способа может служить классическая фон-неймановская ВМ. В ней между взаимодействующими устройствами (процессор, память, устройство ввода/вывода) имеются непосредственные связи. Особенности связей (число линий в шинах, пропускная способность и т. п.) определяются видом информации, характером и интенсивностью обмена. Достоинством архитектуры с непосредственными связями можно считать возможность развязки «узких мест» путем улучшения структуры и характеристик только определенных связей, что экономически может быть наиболее выгодным решением. У фон-неймановских ВМ таким «узким местом» является канал пересылки данных между ЦП и памятью, и «развязать» его достаточно непросто. Кроме того, ВМ с непосредственными связями плохо поддаются реконфигурации.
В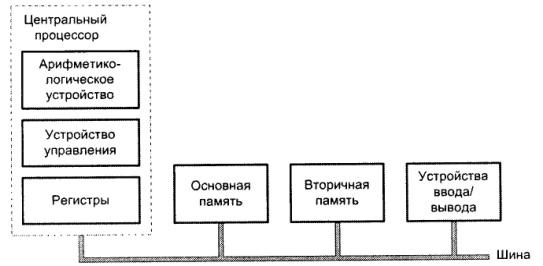 варианте с общей шиной все устройства
вычислительной машины подключены к
магистральной шине, служащей единственным
трактом для потоков команд, данных и
управления. Наличие общей шины существенно
упрощает реализацию ВМ, позволяет
легко менять состав и конфигурацию
машины. Благодаря этим свойствам шинная
архитектура получила широкое
распространение в мини-и микроЭВМ.
Вместе с тем, именно с шиной связан и
основной недостаток архитектуры: в
каждый момент передавать информацию
по шине может только одно устройство.
Основную нагрузку на шину создают обмены
между процессором и памятью, связанные
с извлечением из памяти команд и данных
и записью в память результатов
вычислений. На операции ввода/вывода
остается лишь часть пропускной способности
шины. Практика показывает, что даже при
достаточно быстрой шине для 90% приложений
этих остаточных ресурсов обычно не
хватает, особенно в случае ввода или
вывода больших массивов данных.
варианте с общей шиной все устройства
вычислительной машины подключены к
магистральной шине, служащей единственным
трактом для потоков команд, данных и
управления. Наличие общей шины существенно
упрощает реализацию ВМ, позволяет
легко менять состав и конфигурацию
машины. Благодаря этим свойствам шинная
архитектура получила широкое
распространение в мини-и микроЭВМ.
Вместе с тем, именно с шиной связан и
основной недостаток архитектуры: в
каждый момент передавать информацию
по шине может только одно устройство.
Основную нагрузку на шину создают обмены
между процессором и памятью, связанные
с извлечением из памяти команд и данных
и записью в память результатов
вычислений. На операции ввода/вывода
остается лишь часть пропускной способности
шины. Практика показывает, что даже при
достаточно быстрой шине для 90% приложений
этих остаточных ресурсов обычно не
хватает, особенно в случае ввода или
вывода больших массивов данных.
В целом следует признать, что при сохранении фон-неймановской концепции последовательного выполнения команд программы шинная архитектура в чистом ее виде оказывается недостаточно эффективной. Более распространена архитектура с иерархией шин, где помимо магистральной шины имеется еще несколько дополнительных шин. Они могут обеспечивать непосредственную связь между устройствами с наиболее интенсивным обменом, например процессором и кэш-памятью. Другой вариант использования дополнительных шин — объединение однотипных устройств ввода/вывода с последующим выходом с дополнительной шины на магистральную. Все эти меры позволяют снизить нагрузку на общую шину и более эффективно расходовать ее пропускную способность.
Структуры вычислительных систем Понятие «вычислительная система» предполагает наличие множества процессоров или законченных вычислительных машин, при объединении которых используется один из двух подходов.
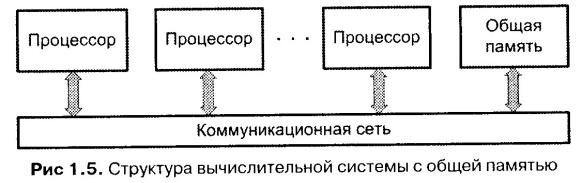
В вычислительных системах с общей памятью имеется общая основная память, совместно используемая всеми процессорами системы. Связь процессоров с памятью обеспечивается с помощью коммуникационной сети, чаще всего вырождающейся в общую шину. Таким образом, структура ВС с общей памятью аналогична рассмотренной выше архитектуре с общей шиной, в силу чего ей свойственны те же недостатки. Применительно к вычислительным системам данная схема имеет дополнительное достоинство: обмен информацией между процессорами не связан с дополнительными операциями и обеспечивается за счет доступа к общим областям памяти.
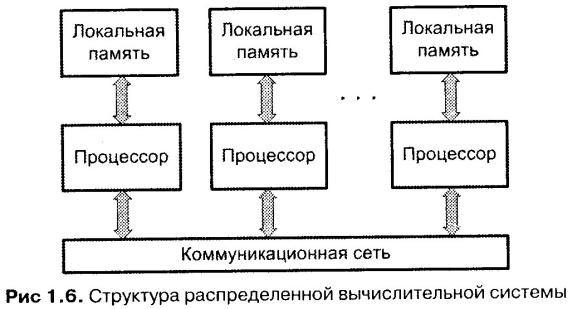
Альтернативный вариант организации — распределенная система, где общая память вообще отсутствует, а каждый процессор обладает собственной локальной памятью. Часто такие системы объединяют отдельные ВМ. Обмен информацией между составляющими системы обеспечивается с помощью коммуникационной сети посредством обмена сообщениями.
Подобное построение ВС снимает ограничения, свойственныe для общей шины, но приводит к дополнительным издержкам на пересылку сообщений между процессорами или машинами.
3. Построить программу на языке С++ для работы со структурами – квадратными матрицами. Структура должна включать соответствующие поля: порядок, набор коэффициентов. Программа должна обеспечивать простейшие функции для работы с данными структуры: ввод матрицы, транспонирование матрицы, вывод матрицы в удобной форме.
Класс
nit Str_Matr;
interface
uses SysUtils;
const N=20;
type Mas= array [1..N,1..N] of Integer;
TMatr=class
private
fZnacn:Mas;
fPorjd:Word;
public
Procedure InitMas(AMas:Mas);
Procedure PrintMas;
Procedure Transport;
Property Poradok:word read fPorjd write fPorjd;
end;
implementation
Procedure TMatr.InitMas;
Begin
fZnacn:= AMas;
End;
Procedure TMatr.PrintMas;
var i,j:Integer;
Begin
Writeln('Matricha ==>');
For i:=1 To fPorjd do
begin
For j:=1 to fPorjd do write(IntToStr(fznacn[i,j])+' ');
writeln;
end;
End;
Procedure TMatr.Transport;
var b:mas;
Begin
end;
end.
Тело
program Zad_19;
{$APPTYPE CONSOLE}
uses
SysUtils,
Str_Matr;
var UsMatr:TMatr;
A:Mas;
i,j:Integer;
begin
UsMatr:=TMatr.Create;
UsMatr.Poradok:=5;
For i:=1 to UsMatr.Poradok do
For j:=1 to UsMatr.Poradok do
Begin
Write('Vvedite A[',inttostr(i),',',InttoStr(j),'] == ');
readln(A[i,j]);
end;
UsMatr.InitMas(A);
UsMatr.PrintMas;
Readln;
{ TODO -oUser -cConsole Main : Insert code here }
end.
Билет 25
1. Структура данных типа СТЕК. Логическая структура стека. Машинное представление стека и реализация операций.
Стек - такой последовательный список с переменной длиной, включение и исключение элементов из которого выполняются только с одной стороны списка, называемого вершиной стека. Применяются и другие названия стека - магазин и очередь, функционирующая по принципу LIFO (Last - In - First- Out - "последним пришел - первым исключается"). Примеры стека: винтовочный патронный магазин, тупиковый железнодорожный разъезд для сортировки вагонов.
Основные операции над стеком - включение нового элемента (английское название push - заталкивать) и исключение элемента из стека (англ. pop - выскакивать).
Полезными могут быть также вспомогательные операции:
определение текущего числа элементов в стеке;
очистка стека;
неразрушающее чтение элемента из вершины стека, которое может быть реализовано, как комбинация основных операций:
x:=pop(stack); push(stack,x).
Некоторые авторы рассматривают также операции включения/исключения элементов для середины стека, однако структура, для которой возможны такие операции, не соответствует стеку по определению.
Для наглядности рассмотрим небольшой пример, демонстрирующий принцип включения элементов в стек и исключения элементов из стека. На рис. 4.1 (а,б,с) изображены состояния стека:
а). пустого;
б-г). после последовательного включения в него элементов с именами 'A', 'B', 'C';
д, е). после последовательного удаления из стека элементов 'C' и 'B';
ж). после включения
в стек элемента 'D'. 
Машинное представление стека и реализация операций
При представлении стека в статической памяти для стека выделяется память, как для вектора. В дескрипторе этого вектора кроме обычных для вектора параметров должен находиться также указатель стека - адрес вершины стека. Указатель стека может указывать либо на первый свободный элемент стека, либо на последний записанный в стек элемент. (Все равно, какой из этих двух вариантов выбрать, важно в последствии строго придерживаться его при обработке стека.) В дальнейшем мы будем всегда считать, что указатель стека адресует первый свободный элемент и стек растет в сторону увеличения адресов.
При занесении элемента в стек элемент записывается на место, определяемое указателем стека, затем указатель модифицируется таким образом, чтобы он указывал на следующий свободный элемент (если указатель указывает на последний записанный элемент, то сначала модифицируется указатель, а затем производится запись элемента). Модификация указателя состоит в прибавлении к нему или в вычитании из него единицы (помните, что наш стек растет в сторону увеличения адресов.
Операция исключения элемента состоит в модификации указателя стека (в направлении, обратном модификации при включении) и выборке значения, на которое указывает указатель стека. После выборки слот, в котором размещался выбранный элемент, считается свободным.
Операция очистки стека сводится к записи в указатель стека начального значения - адреса начала выделенной области памяти.
Определение размера стека сводится к вычислению разности указателей: указателя стека и адреса начала области.
Программный модуль, представленный в примере 4.1, иллюстрирует операции над стеком, расширяющимся в сторону уменьшения адресов. Указатель стека всегда указывает на первый свободный элемент.
const SIZE = ...;
type data = ...;
{==== Программный пример 4.1 ====}
{ Стек }
unit Stack;
Interface
const SIZE=...; { предельный размер стека }
type data = ...; { эл-ты могут иметь любой тип }
Procedure StackInit;
Procedure StackClr;
Function StackPush(a : data) : boolean;
Function StackPop(Var a : data) : boolean;
Function StackSize : integer;
Implementation
Var StA : array[1..SIZE] of data; { Стек - данные }
{ Указатель на вершину стека, работает на префиксное вычитание }
top : integer;
Procedure StackInit; {** инициализация - на начало }
begin top:=SIZE; end; {** очистка = инициализация }
Procedure StackClr;
begin top:=SIZE; end;
{ ** занесение элемента в стек }
Function StackPush(a: data) : boolean;
begin
if top=0 then StackPush:=false
else begin { занесение, затем - увеличение указателя }
StA[top]:=a; top:=top-1; StackPush:=true;
end; end; { StackPush }
{ ** выборка элемента из стека }
Function StackPop(var a: data) : boolean;
begin
if top=SIZE then StackPop:=false
else begin { указатель увеличивается, затем - выборка }
top:=top+1; a:=StA[top]; StackPop:=true;
end; end; { StackPop }
Function StackSize : integer; {** определение размера }
begin StackSize:=SIZE-top; end;
END.
2. Основные понятия, определения и назначение САПР
Система автоматизированного проектирования — автоматизированная система, реализующая информационную технологию выполнения функций проектирования, представляет собой организационно-техническую систему, предназначенную для автоматизации процесса проектирования, состоящую из персонала и комплекса технических, программных и других средств автоматизации его деятельности. Также для обозначения подобных систем широко используется аббревиатура САПР.