

Представление выражений с помощью деревьев
С помощью деревьев можно представлять произвольные арифметические выражения (рис. 6.22-6.23). Каждому листу в таком дереве соответствует операнд, а каждому родительскому узлу - операция. В общем случае дерево при этом может оказаться не бинарным. Однако если число операндов любой операции будет меньше или равно двум, то дерево будет бинарным. Причем если все операции будут иметь два операнда, то дерево окажется строго бинарным.

-(A+B)*((C+cos(D+E)-f(a,b,c,d,e))














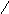





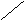
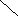
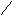



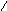
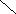



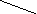

Рис. 6.22. Представление арифметического выражения произвольного вида в виде дерева.
f(a+b,sin
c)











Рис. 6.23. Представление арифметического выражения в виде бинарного дерева.
Бинарные деревья могут быть использованы не только для представления выражений, но и для их вычисления (рис. 6.24). В листьях записываются значения операндов. Затем от листьев к корню производится выполнение операций. В процессе выполнения в узел операции записывается результат ее выполнения. В конце вычислений в корень будет записано значение, которое и будет являться результатом вычисления выражения.
(1+10)*5



























Рис. 6.24. Вычисление арифметического выражения с помощью бинарного дерева.
Помимо арифметических выражений с помощью деревьев можно представлять выражения других типов, например, логические выражения (рис. 6.25). Поскольку функции алгебры логики определены над двумя или одним операндом, то дерево для представления логического выражения будет бинарным.

((aVb)&(cVd))&(e&fVa&b)

















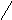
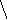

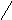

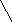
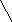




Рис. 6.25. Представление логического выражения в виде бинарного дерева.
5.Сравнительный анализ алгоритмов поиска: линейный, двоичный
Само действие поиска элемента в наборе данных требует возможности отличать элементы друг от друга. Очевидно, сравнение числовых типов не вызывает трудности. В случае сравнения строк процедура усложняется. Можно выполнять сравнение чувствительное или нечувствительное к регистру, сравнение по локальным таблицам символов, когда оно выполняется на основе алгоритмов, специфичных для определенной страны или языка и т.д. При работе с объектами вообще не существует заранее определенной схемы сравнения за исключением сравнения указателей на эти объекты.
В таком случае лучше всего рассматривать процедуру сравнения в виде «черного ящика» – функции с четко определенным интерфейсом, которая в качестве входных параметров принимает указатели на два элемента и возвращает результат сравнения – первый элемент больше, меньше или равен второму.
Линейный поиск. Единственно возможным методом поиска элемента по значению ключа, находящегося в неупорядоченном наборе данных, является последовательный (линейный) просмотр каждого элемента, который продолжается до тех пор, пока не будет найден искомый элемент. Если просмотрен весь набор, но элемент не найден, искомый ключ отсутствует. Для последовательного поиска в среднем требуется (n+1)/2 сравнений и порядок алгоритма линейный O(n).
Программная иллюстрация линейного поиска в неупорядоченном массиве приведена ниже, где aList – исходный массив, aItem – искомый ключ; функция возвращает индекс найденного элемента или -1, если элемент отсутствует.
{ Линейный поиск в неотсортированном массивом }
function LineNonSortedSearch(aList: TList;
aItem: Pointer; aCompare: TCompareFunc): Integer;
var i: Integer;
begin
Result:=-1;
for i:=0 to aList.Count-1 do
if aCompare(aList.List[i],aItem) = 0 then
begin
Result:=i;
Break;
end;
end;
Последовательный поиск для отсортированного массива ничем не отличается от приведенного и имеет линейный порядок алгоритма O(n).
Бинарный поиск. Другим относительно простым методом доступа к элементу является бинарный (двоичный или дихотомичный) поиск, который выполняется в заведомо упорядоченной последовательности элементов. Элементы массива должны располагаться в лексикографическом (символьные ключи) или численно (числовые ключи) возрастающем порядке. Для достижения упорядоченности может быть использован один из методов сортировки.
В методе сначала приближенно определяется запись в середине массива и анализируется значение ее ключа. Если оно слишком велико, то анализируется значение ключа, соответствующего записи в середине первой половины массива, и указанная процедура повторяется в этой половине до тех пор, пока не будет найдена требуемая запись. Если значение ключа слишком мало, испытывается ключ, соответствующий записи в середине второй половины массива, и процедура повторяется в этой половине.
Процесс продолжается до тех пор, пока не найден требуемый ключ или не станет пустым интервал, в котором осуществляется поиск. Чтобы найти элемент, в худшем случае требуется log2(N) сравнений, что значительно лучше, чем при последовательном поиске. Программная иллюстрация бинарного поиска в упорядоченном массиве приведена ниже.
{ Двоичный поиск }
function BinarySearch(aList: TList;
aItem: Pointer; aCompare: TCompareFunc): Integer;
var L, R, M, CompareResult: Integer;
begin
{ Значения индексов первого и последнего элементов }
L:=0; R:=aList.Count-1;
while L <= R do
begin
{ Индекс среднего элемента }
M:=(L + R) div 2;
{ Сравнить значение среднего элемента с искомым }
CompareResult:=aCompare(aList.List[M], aItem);
{ Если значение среднего элемента меньше искомого -
переместить левый индекс на позицию до среднего индекса }
if CompareResult < 0 then
L:=M+1 else
{ Если значение среднего элемента больше искомого -
переместить правый индекс на позицию после среднего индекса }
if CompareResult > 0 then
R:=M-1 else
begin
Result:=M;
Exit;
end;
end;
Result:=-1;
end;
2. Реляционная модель данных. Базовые понятия. Отношения и свойства отношений. Составляющие реляционной модели данных.
Реляционная база данных — база данных, основанная на реляционной модели. Слово «реляционный» происходит от английского «relation» (отношение[1]). Для работы с реляционными БД применяют Реляционные СУБД.
Теория реляционных баз данных была разработана доктором Коддом из компании IBM в 1970 году. В реляционных базах данных все данные представлены в виде простых таблиц, разбитых на строки и столбцы, на пересечении которых расположены данные. Запросы к таким таблицам возвращают таблицы, которые сами могут становиться предметом дальнейших запросов. Каждая база данных может включать несколько таблиц. Кратко особенности реляционной базы данных можно сформулировать следующим образом:
• Данные хранятся в таблицах, состоящих из столбцов ("атрибутов") и строк ("записей");
• На пересечении каждого столбца и строчки стоит в точности одно значение;
• У каждого столбца есть своё имя, которое служит его названием, и все значения в одном столбце имеют один тип.
• Запросы к базе данных возвращают результат в виде таблиц, которые тоже могут выступать как объект запросов.
Строки в реляционной базе данных неупорядочены - упорядочивание производится в момент формирования ответа на запрос.
Общепринятым стандартом языка работы с реляционными базами данных является язык SQL.
Существуют определенные правила, которые должны соблюдаться при создании базы данных. Пользователь должен пройти следующие этапы, которые называют "нормализацией":
• удалить повторяющиеся группы атрибутов. Группой считаются два и более атрибута, их необходимо вынести в отдельную таблицу.
• удалить неключевые атрибуты и те, которые не имеют отношения к первичному ключу или относятся только к части первичного ключа. Если первичный ключ составной, то любой атрибут таблицы должен быть связан с обоими частями ключа.
• описать каждую таблицу: каждому атрибуту дать имя и указать вид информации, который используется в таблице (числовой, дата, денежный и т.п.). Название атрибута должно быть уникальным в рамках одной таблицы, обычно названия пишут латинскими буквами без пробелов.
• работа с пользовательским интерфейсом, обозначение обязательных и необязательных для заполнения полей.
• забота о безопасности, если это необходимо: шифрование данных, ограничение прав доступа.
3. Информация о студенте включает: ФИО, порядковый номер, название факультета, номер специальности, дату рождения, адрес проживания, телефон. Информация о студентах хранится в виде записей в массиве. Число записей в массиве 100. Отсортировать всех студентов в алфавитном порядке. Обосновать выбор алгоритма сортировки.
|
program Project12;
{$APPTYPE CONSOLE}
uses SysUtils, Windows;
//Program Zad_12; //Uses Crt; Type Student = Record Number:Word; FIO:String[20]; Fakul:String[10]; Spech:String[6]; DateRog:String[10]; Addres:String[15]; Teleph:String[10]; End; Var Spisok: array [1..101] of Student; N,i,j,Imin:Integer; Min:String;
Begin //ClrScr; Write('Number of Students = '); Readln(N); For i:=1 To N do Begin Write('Poridkovyi nomer == '); Readln(Spisok[i].Number); Write('FIO == '); Readln(Spisok[i].FIO); Write('Naimenovanie fakulteta == '); Readln(Spisok[i].Fakul); Write('Number spechialnosti == '); Readln(Spisok[i].Spech); Write('Date rogdeniya == '); Readln(Spisok[i].DateRog); Write('Address == '); Readln(Spisok[i].Addres); Write('Telephone == '); Readln(Spisok[i].Teleph); End;
|
For i:=1 To N-1 Do Begin Min:=Spisok[i].FIO; Imin:=i; For j:=i+1 To N Do If Spisok[j].FIO < Min Then Begin Min :=Spisok[j].FIO; Imin:=j; End; Spisok[N+1].Number:=Spisok[i].Number; Spisok[N+1].FIO:=Spisok[i].FIO; Spisok[N+1].Fakul:=Spisok[i].Fakul; Spisok[N+1].Spech:=Spisok[i].Spech; Spisok[N+1].DateRog:=Spisok[i].DateRog; Spisok[N+1].Addres:=Spisok[i].Addres; Spisok[N+1].Teleph:=Spisok[i].Teleph;
Spisok[i].Number:=Spisok[Imin].Number; Spisok[i].FIO:=Min; Spisok[i].Fakul:=Spisok[Imin].Fakul; Spisok[i].Spech:=Spisok[Imin].Spech; Spisok[i].DateRog:=Spisok[Imin].DateRog; Spisok[i].Addres:=Spisok[Imin].Addres; Spisok[i].Teleph:=Spisok[Imin].Teleph; Spisok[Imin].Number:=Spisok[N+1].Number; Spisok[Imin].FIO:=Spisok[N+1].FIO; Spisok[Imin].Fakul:=Spisok[N+1].Fakul; Spisok[Imin].Spech:=Spisok[N+1].Spech; Spisok[Imin].DateRog:=Spisok[N+1].DateRog; Spisok[Imin].Addres:=Spisok[N+1].Addres; Spisok[Imin].Teleph:=Spisok[N+1].Teleph; End; //Clrscr; For i:=1 To N Do Begin Writeln(Spisok[i].Number,' ', Spisok[i].FIO,' ', Spisok[i].Fakul,' ' ,Spisok[i].Spech, ' ',Spisok[i].DateRog); Writeln(' ',Spisok[i].Addres,' ',Spisok[i].Teleph); End; Readln; End.
|
Билет 16.
1. Предваренная, скулемовская и клазуальная формы. Логическое следование. Унификация. Алгоритм унификации. Исчисление метода резолюций.
Предваренная нормальная форма
Для облегчения анализа сложных суждений формулы алгебры предикатов рекомендуется приводить к нормальной форме. Если в алгебре высказываний приняты две нормальные формы (ДНФ - дизъюнктивная и КНФ -конъюнктивная), то в алгебре предикатов - одна предваренная нормальная форма (ПНФ), суть которой сводится к разделению формулы на две части: кванторную и безкванторную. Для этого все кванторы формулы выносят влево, используя законы и правила алгебры предикатов.
В результате этих алгебраических преобразований может быть получена формула вида: x1 x2 xn(M), где {; } , а М – матрица формулы. Кванторную часть формулы x1 x2 xn иногда называют префиксом ПНФ.
В последующем матрицу формулы преобразуют к виду КНФ, что облегчает механизм по принципу резолюции.
Сколемовская стандартная форма
Наличие разноименных кванторов усложняет вывод заключения. Поэтому рассмотрим класс формул, содержащих только кванторы всеобщности. Формула F называется - формулой, если она представлена в ПНФ и содержит только кванторы всеобщности, т.е.
F = x1x2 xn (M).
Для устранения кванторов существования из префикса формулы разработан алгоритм Сколема, вводящий сколемовскую функцию для связывания предметной переменной квантора существования с другими предметными переменными.
Принцип резолюции
Существует эффективный алгоритм логического вывода - алгоритм резолюции. Этот алгоритм основан на том, что выводимость формулы В из множества посылок F1; F2; F3; . . . Fn равносильна доказательству теоремы
(F1F2F3. . .FnB),
формулу которой можно преобразовать так:
(F1F2F3. . .FnB) =
((F1F2F3. . .Fn)B) =
(F1F2F3. . .Fn( F2 B)).
Следовательно, заключение В истинно тогда и только тогда, когда формула (F1F2F3...Fn(B))=л. Это возможно при значении “л” хотя бы одной из подформул Fi илиB.
Для анализа этой формулы все подформулы Fi иB должны быть приведены в конъюнктивную нормальную форму и сформировано множество дизъюнктов, на которые распадаются все подформулы. Два дизъюнкта этого множества, содержащие пропозициональные переменные с противоположными знаками (контрарные атомы) формируют третий дизъюнкт - резольвенту, в которой будут исключены контрарные пропозициональные переменные. Неоднократно применяя это правило к множеству дизъюнктов и резольвент, стремятся получить пустой дизъюнкт. Наличие пустого дизъюнкта свидетельствует о выполнении условия F1F2F3...FnB=л.
Нормальные формы формул
В алгебре высказываний используют две нормальные формы: дизъюнктивную и конъюнктивную нормальные формы формулы (ДНФ и КНФ).
ДНФ формулы есть формула, равносильная формуле исходной логической функции и записанная в виде дизъюнкции элементарных конъюнкций, построенных на пропозициональных переменных, т.е.
F = K1 K2 K3 . . ., где Ki = ( ABC . . .).
В элементарной коньюнкции нет двух одинаковых пропозициональных переменных, т.к. по закону идемпотентности FF=F. В ДНФ нет двух одинаковых элементарных коньюнкций, т.к. по закону идемпотентности FF=F. Если одна из элементарных коньюнкций содержит F и F, то элементарную коньюнкцию следует удалить, т.к. FF=л.
КНФ формулы есть формула, равносильная формуле исходной логической функции и записанная в виде конъюнкции элементарных дизъюнкций, построенных на пропозициональных переменных, т.е.
F = D1 D2 D3 . . . , где Di = ( ABC . . . ).
В элементарной дизьюнкции нет двух одинаковых пропозициональных переменных, т.к. по закону идемпотентности FF=F. В КНФ нет двух одинаковых элементарных дизьюнкций, т.к. по закону идемпотентности FF=F. Если одна из элементарных дизьюнкций содержит F и F, то следует удалить, т.к. FF = и.
2. Структура внешнего описания ПС. Качество ПО. Критерии и примитивы качества.
Программа или логически связанная совокупность программ на носителях данных, снабженная программной документацией, называется программным средством (ПС). Программа позволяет осуществлять некоторую автоматическую обработку данных на компьютере. Программная документация позволяет понять, какие функции выполняет та или иная программа ПС, как подготовить исходные данные и запустить требуемую программу в процесс ее выполнения, а также: что означают получаемые результаты. Кроме того, программная документация помогает разобраться в самой программе, что необходимо, например, при ее модификации.
Разработка ПО - это, прежде всего, нахождение способов получения качественного программного продукта. Качество ПО может измеряться во внешних (например, легкий в использовании, выполняется быстро) или во внутренних характеристиках (например, модульная конструкция, читабельный код).
Характеристики качества программного обеспечения:
- Корректность (правильность). Обеспечивает правильную обработку на правильных данных
- Устойчивость. "Элегантно" завершает обработку ошибок
- Расширяемость. Может легко адаптироваться к изменяющимся требованиям
- Многократность использования. Может использоваться и в других системах, а не только в той, для которой было создано.
- Совместимость. Может легко использоваться с другим программным обеспечением
- Эффективность. Эффективное использование времени, компьютерной памяти, дискового пространства и т.д.
- Переносимость. Можно легко перенести на другие аппаратные и программные средства
- Верификация. Простота проверки, легкость разработки тестов при обнаружении ошибок, легкость обнаружения мест, где программа потерпела неудачу, и т.д.
- Поддержка целостности. Защищает себя от неправильного обращения и неправильного употребления
- Легкость использования для пользователя и для будущих программистов
Корректность и устойчивость
Корректная программа работает, когда поданы на вход правильные данные. Она отвечает всем требованиям к спецификации данных и не терпит неудачу внутри заданного диапазона. Устойчивость подразумевает не только правильность. Устойчивая программа способна обработать ситуации, не запланированные проектом. Эти ситуации включают некорректный ввод пользователя, аппаратный отказ и ошибки во время выполнения программы. Устойчивые системы терпят неудачу без потери критических данных.
Расширяемость
Два основных принципа создания расширяемого программного обеспечения:
- Простота проекта. Более простые проект и архитектура позволяют произвести изменения намного быстрее и легче, чем при сложном проекте.
- Децентрализация. Разбиение сложных проблем на малые. Управляемость и независимость фрагментов, означающая, что они могут быть поделены внутри себя. Это значит, что изменения, могут быть выполнены без перекраивания других частей системы.
Многократность использования и совместимость
Многократное использование может просматриваться на различных уровнях: при анализе, проектировании и реализации. Оно поддерживает качество следующими способами:
- Если проекты и код могут повторно использоваться, то мы можем начинать с уже проверенных, опробованных и правильных компонент, качество которых уже является высоким.
- Время и энергия, сохраненные через многократное использование, могут применяться для улучшения других характеристик качества программы (например, корректности или устойчивости).
Совместимость программного обеспечения - мера того, насколько просто объединить различные программные изделия вместе для нового применения. Совместимое ПО поддерживает качество посредством использования прошлых усилий при формировании новых систем.
Понятность – легкость понимания документации, сопровождающей ПИ.
Каждое ПИ должно создаваться с учетом требований пользователя, определенных в техническом задании. Характеристики понятности:
Информативность – ПИ обладает информативностью, если оно содержит информацию, обеспечивающую понимание назначения ПИ, принятых ограничений, смыслового значения результатов работы отдельных компонентов ПИ.
Открытость – дает возможность понять назначение каждого оператора ПИ при чтении ее текста, т.е. каждый из идентификаторов должен нести смысловую нагрузку, например, SUM= CENA*KOL.
Согласованность ПИ – бывает внутренняя и внешняя.
Внутренняя согласованность должна обеспечивать единую терминологию, единую трактовку понятий и значений. Особое значение эта характеристика приобретает при создании программных комплексов, когда над проектом работает группа специалистов, и в процессе работы необходимы контакты по взаимоувязке программных модулей.
Внешняя согласованность обеспечивается однозначным соответствием создаваемого ПИ требованиям, изложенным в техническом проекте на его разработку.
Структурированность ПИ – делает его понятным для пользователя. Она предполагает создание ПИ в соответствии с определенными требованиями:
1 - Использование при программировании трех базовых конструкций:
а) линейная структура
б) условный переход
в) цикл (или последовательная).
2 - Подробное комментирование текста программ.
3 - Использование модульного программирования.
4 - Ограничение на объем модулей (количество операторов).
Надежность – свойство ПИ сохранять работоспособность в течение определенного периода времени в определенных условиях эксплуатации с учетом последствий для пользователя при любом отказе. Она характеризуется:
Завершенность – завершенное ПИ включает все необходимые для функционирования программные компоненты.
Точность - характеристика, определяющая точность результатов расчета в соответствии с их назначением. Например: если ведутся расчеты банковских операций, то разумная точность – 3 знака после запятой, с последующим округлением до 2 знаков. Если в программе производятся расчеты по биологическим экспериментам, на молекулярном уровне, то точность по 10-12 знаков после запятой.
Эффективность – выполнение требуемых функций при минимальных затратах ресурсов. Причем под ресурсами подразумевается: объем оперативной памяти, время работы процессора, объем внешней памяти, пропускная способность канала.
Модифицируемость – эта характеристика отражает возможность внесения изменений в ПИ без значительных затрат времени на последующую отладку. Эта характеристика включает в себя характеристику расширяемости ПИ, которая предполагает модификацию ПИ в части увеличения объема памяти либо числа функциональных модулей.
Оцениваемость – это существование критерия оценки ПИ и способа проверки соответствия этому критерию, по которым можно сравнить с другими подобными ПИ (критерии оценки в техническом проекте соответствует заданным требованиям: время работы модуля и т.д.).
Человеческий фактор (сервис):
Легкость использования ПИ.
ПИ должно удовлетворять требованиям пользователя.
ПИ должно реализовывать потенциальные потребности пользователя.
Мобильность – возможность работы ПИ в различных ОС
Качество программного обеспечения определяется в стандарте ISO 9126 как вся совокупность его характеристик, относящихся к возможности удовлетворять высказанные или подразумеваемые потребности всех заинтересованных лиц.
Отличие тестирования от контроля качества. Целью тестирования является нахождение максимального числа ошибок. Задача контроля качества является оценка результатов работы проектной группы (всех сотрудников и результатов их деятельности в процессе разработки ПО: программистов, тестировщиков, менеджеров проекта и т.д.).
Качеством можно управлять. Для этого разрабатывается план управления качеством, который включает в себя:
Определение метрик для измерения тех или иных аспектов процесса разработки программного продукта и самого разрабатываемого продукта.
Метрики нужны для численного измерения уровня качества. Как правило, в качестве метрик используются следующие характеристики:
Число строк кода
Время, за которое написано N строк кода
Степень дефектности (Число дефектов/Число строк кода) (под дефектами понимаются ошибки, найденные в результате тестирования)
Относительная оценка по 10-бальной шкале
План проведения инспектирования
План валидации и верификации
К контролю качества относится процедура аттестации ПО. Аттестация ПО проводится сторонними организациями, уполномоченными проверять ПО на соответствие определенным отраслевым стандартам.
Критерии качества программного обеспечения
1 Функциональные возможности
-функциональная пригодность
-корректность-правильность
-способность к взаимодействию (с ОС и аппаратурой, м-ду др программами)
-защищенность (от предумышленных угроз, случайных дефектов программ)
2 Надежность
-завершенность (наработка на отказ при отсутствии рестарта)
-устойчивость к дефектам (наработка при наличие рестарта)
-восстанавливаемость
-доступность, готовность
3 Эффективность
-временная эффективность
- используемые ресурсы (процессорное время, память и т.д)
4 Практичность
-понятность
-простота использования
-изучаемость
-привлекательность
5 Сопровождаемость
-анализируемость
-изменяемость
-стабильность
-тестируемость
6 Мобильность
-адаптируемость
-простота установки
-сосуществование соответствия
-замещаемость
3. Написать программу на языке С++, реализующую телефонный справочник. В справочнике содержится следующая информация о каждом абоненте: имя и телефон. Реализовать вывод всей информации из справочника, поиск телефона по имени, поиск имени по телефону.
#include <iostream.h>
#include <conio.h>
#include <string.h>
#include <stdio.h>
void main()
{
struct Teleph
{
char FIO[20];
char Nomer[20];
} spisok [10];
int N,i,K;
char Str[20];
do
{
cout<<"\n 1. Cteate spravochnik";
cout<<"\n 2. Print spravochnik";
cout<<"\n 3. Find po FIO";
cout<<"\n 4. Find po Telephone";
cout<<"\n 5. Exit";
cout<<"\n Vvedite N ==";
cin>>N;
if(N==1)
{
cout<<"\n Vvedite kolichestvo ==";
cin>>K;
for (i=1;i<=K;i++)
{
cout<<"\n Vvedite FIO ==";
cin>>spisok[i].FIO;
cout<<"\n Vvedite Telephone ==";
cin>>spisok[i].Nomer;
}
}
if(N==2)
{
cout<<"\n Print...";
for(i=1;i<=K;i++)
{
cout<<"\n FIO = "<<spisok[i].FIO;
cout<<" Telephone = "<<spisok[i].Nomer;
}
}
if(N==3)
{
cout<<"\n Vvedite FIO == ";
cin>>Str;
for(i=1;i<=K;i++)
if (strcmp(spisok[i].FIO,Str)==0)
cout<<"\n Telephone = > "<<spisok[i].Nomer;
cout<<"\n";
}
if(N==4)
{
cout<<"\n Vvedite TELEPHONE == ";
cin>>Str;
for(i=1;i<=K;i++)
if(strcmp(spisok[i].Nomer,Str)==0)
cout<<"\n FIO => "<<spisok[i].FIO;
cout<<"\n";
}
} while (N!=5);
}
Билет 17.
1. Понятия прерывания. Виды прерываний. Механизмы прерываний.
Прерывания – механизм, позволяющий координировать параллельное функционирование отдельных устройств вычислительной системы и реагировать на особые ситуации, возникающие при работе процессора. Прерывания – принудительная передача управления от выполняемой программы к системе, происходящее при возникновении определенного события.
Прерывания, возникающие при работе вычислительной системы, можно разделить на два основных класса:
- внешние (асинхронные);
- внутренние (синхронные).
Внешние прерывания вызываются асинхронными событиями, которые происходят вне прерываемого процесса, например:
- прерывания от таймера;
- прерывания от внешнего устройства (прерывания по вводу/выводу);
- прерывания по нарушению питания;
- прерывания с пульта оператора вычислительной системы;
- прерывания от другого процессора или другой вычислительной системы.
Внутренние прерывания вызываются событиями, которые связаны с работой процессора и являются синхронными с его операциями, например:
- нарушение адресации;
- наличие в поле адреса несуществующей инструкции;
- деление на нуль;
- переполнение или исчезновение порядка;
- ошибка четности;
- ошибка в работе различных аппаратных устройств.
Собственно программные прерывания происходят по соответствующей команде прерывания, то есть по этой команде процессор производит те же действия, что и при обычных внутренних прерываниях. Данный механизм введен для того, чтобы переключение на системные программные модули происходило не как переход в подпрограмму, а как обычное прерывание. Этим обеспечивается автоматическое переключение процессора в привилегированный режим с возможностью выполнения всех команд.
Основная цель введения прерываний – реализация асинхронного режима работы и распараллеливание работы отдельных устройств вычислительного комплекса.
Механизм прерываний реализуется аппаратно-программным способом. Прерывание всегда влечет за собой изменение порядка выполнения команд процессором.
Механизм обработки прерываний включает следующие шаги:
1) установление факта прерывания и его идентификация;
2) запоминание состояния прерванного процесса (счетчика команд, содержимого регистров процессора, спецификации режима и др.);
3) аппаратная передача управления подпрограмме обработки прерываний;
4) сохранение информации о прерванной программе, которую не удалось сохранить на шаге 2 с помощью действий аппаратуры, иногда большого объема информации;
5) обработка прерываний;
6) восстановление информации, относящейся к прерванному процессу;
7) возврат в прерванную программу.
Шаги 1 – 3 реализуются аппаратно, а шаги 4 –7 программно.
Главные функции механизма прерываний:
- распознавание или классификация прерываний;
- передача управления на обработку прерываний;
- корректное возвращение к прерванной программе.
2. Стадии и этапы разработки базы данных.
Этапы разработки баз данных
Как отмечалось выше, база данных является одним из основных компонентов любой информационной системы, поэтому при её проектировании преследуются те же цели, что и при проектировании автоматизированной системы управления (АСУ) предприятием, а этапы и стадии её создания практически совпадают с работами по созданию АСУ. При разработке базы данных принято выделять следующие этапы, при помощи которых осуществляется переход от предметной области к её конкретной реализации:
• изучение предметной области;
• разработка моделей предметной области;
• разработка логической модели данных;
• разработка физической модели данных;
• разработка собственно базы данных.
Изучение предметной области заключается в выявлении существенных процессов и факторов, оказывающих определяющее влияние на достижение целей внедрения информационной системы.
Модель предметной области – это записанные знания об объектах реального мира, которыми необходимо управлять наиболее рациональным образом. Эти знания могут быть представлены как в чисто текстовом виде, так и с использованием методологий структурного функционального моделирования - SADT, IDEF0, IDEF3, методологий и стандартов описания состава, структуры и взаимосвязей используемой в деятельности предприятия информации – IDEF1, DFD и соответствующих инструментальных case-средств – BPWin, AIO WIN, ProCap, ProSim, SmartER.
Логическая модель данных описывает понятия предметной области и их взаимосвязи и является прототипом будущей базы данных. Логическая модель разрабатывается в терминах информационных понятий, но без какой-либо ориентации на конкретную СУБД. Наиболее широко используемым средством разработки логических моделей баз данных являются диаграммы «сущность-связь» - Entity-Relationship (ER-диаграммы). Следует заметить, что логическая модель данных, представленная ER-диаграммами, в принципе, может быть преобразована как в реляционную модель данных, так и в иерархическую, сетевую, постреляционную.
Физическая модель данных строится на базе логической модели и описывает данные уже средствами конкретной СУБД. Отношения, разработанные на стадии логического моделирования, преобразуются в таблицы, атрибуты в столбцы, домены в типы данных, принятых в выбранной конкретной СУБД. На этапах логического и физического моделирования, как правило, используется стандарт IDEF1X и case-средства ERWin или SmartER. Указанные инструментальные средства проектирования поддерживают несколько десятков наиболее популярных СУБД. Результатом физического моделирования является генерация программного кода базы данных на соответствующем выбранной СУБД диалекте структурированного языка запросов SQL.
Несмотря на постоянно совершенствуемые возможности case-средств по автоматической генерации кода баз данных, детальное её проектирование все-таки остается работой и заботой человека. Case-средства помогают создать прототип базы данных, на котором строится её рабочая версия. Поскольку практически любая база данных кроме таблиц содержит дополнительный программный код в виде триггеров и хранимых процедур, которые пишутся на процедурных расширениях языка SQL или универсальном языке программирования, то полностью автоматизировать её создание из логической модели пока не представляется возможным, а может быть и нужным.
Хранимые процедуры, основным назначением которых является реализация бизнес процессов предметной области, – это процедуры и функции, хранящиеся непосредственно в базе данных в откомпилированном виде, которые могут запускаться непосредственно пользователем или прикладными программами, работающими с базой данных.
Триггеры – это хранимые процедуры, связанные с некоторыми событиями, происходящими во время работы базы данных. В качестве таких событий обычно выступают операции вставки, обновления и удаления строк таблиц. Если в базе данных определен некоторый триггер, то он запускается автоматически всегда при возникновении события. Важным является то, что пользователи не могут обойти триггер, независимо от того, кто из них и каким образом инициировал запускающее его событие. Основным назначением триггеров является автоматическая поддержка целостности базы данных, но они могут использоваться и для реализации достаточно сложных ограничений, накладываемых предметной областью, например, с операцией вставки нового товара в накладную может быть связан триггер, который проверяет наличие необходимого товара на складе и выполняет другие необходимые действия.
3. Дан массив типа word размерностью n. Найти сумму всех элементов не прерывающих заданного m, далее вывести на экран.
|
program Project3; {$APPTYPE CONSOLE} uses SysUtils, Windows; //Program Zadanie_3; //Uses Crt; Const K = 100; Var N,i,M,S:Word; A:Array[1..K] of Word; Begin //ClrScr; Write('Number of elements array = '); Readln(N); If (N>0) and (N<100) Then Begin Writeln('Elements of array...');
|
For i:=1 To N Do Begin Write('A[',i,'] = '); Readln(a[i]); End; Write('Number M = '); Readln(M); S:=0; For i:=1 To N Do If (A[i]<=M) Then S:=S+A[i]; Writeln; Writeln('Summa of elements <= M == ',S); End Else Writeln('Uncorrectly number N'); Writeln('For exit press any key'); Readln; end.
|
Билет 18.
1. Понятие о способах коммутации в распределенных вычислительных системах(коммутации каналов, коммутация пакетов).
Коммута́ция — процесс соединения абонентов коммуникационной сети через транзитные узлы.
В общем случае решение каждой из частных задач коммутации — определение потоков и соответствующих маршрутов, фиксация маршрутов в конфигурационных параметрах и таблицах сетевых устройств, распознавание потоков и передача данных между интерфейсами одного устройства, мультиплексирование/демультиплексирование потоков и разделение среды передачи — тесно связано с решением всех остальных. Комплекс технических решений обобщенной задачи коммутации в совокупности составляет базис любой сетевой технологии. От того, какой механизм прокладки маршрутов, продвижения данных и совместного использования каналов связи заложен в той или иной сетевой технологии, зависят ее фундаментальные свойства.
Среди множества возможных подходов к решению задачи коммутации абонентов в сетях выделяют два основополагающих: коммутация каналов (circuit switching); коммутация пакетов (packet switching).
Внешне обе эти схемы соответствуют приведенной на рис. 6.1 структуре сети, однако возможности и свойства их различны.
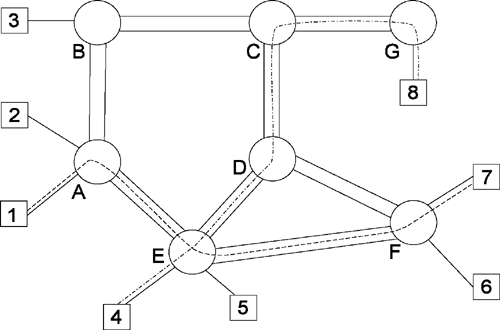 Рис.
6.1. Общая
структура сети с коммутацией абонентов
Рис.
6.1. Общая
структура сети с коммутацией абонентов
Сети с коммутацией каналов имеют более богатую историю, они произошли от первых телефонных сетей. Сети с коммутацией пакетов сравнительно молоды, они появились в конце 60-х годов как результат экспериментов с первыми глобальными компьютерными сетями. Каждая из этих схем имеет свои достоинства и недостатки, но по долгосрочным прогнозам многих специалистов, будущее принадлежит технологии коммутации пакетов, как более гибкой и универсальной.