

Симметричные криптосистемы. Функции криптосистем
Все недостатки непосредственного применения криптоалгоритмов устраняются в криптосистемах. Криптосистема – это завершенная комплексная модель, способная производить двусторонние криптопреобразования над данными произвольного объема и подтверждать время отправки сообщения, обладающая механизмом преобразования паролей и ключей и системой транспортного кодирования. Таким образом, криптосистема выполняет три основные функции:
усиление защищенности данных,
облегчение работы с криптоалгоритмом со стороны человека
обеспечение совместимости потока данных с другим программным обеспечением.
Конкретная программная реализация криптосистемы называется криптопакетом.
Общая схема симметричной криптосистемы
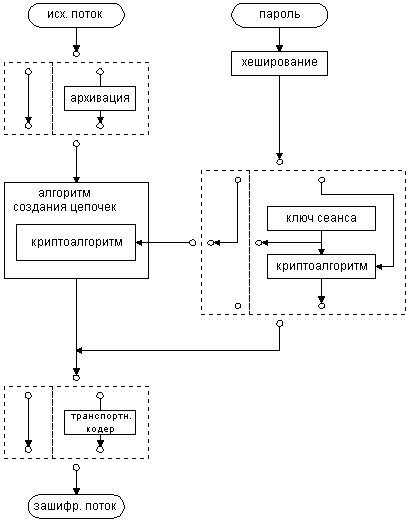
Алгоритмы создания цепочек
Первая задача, с которой мы столкнемся при шифровании данных криптоалгоритмом – это данные с длиной, неравной длине 1 блока криптоалгоритма. Эта ситуация будет иметь место практически всегда.
Первый вопрос:
– Что можно сделать, если мы хотим зашифровать 24 байта текста, если используется криптоалгоритм с длиной блока 8 байт? – Последовательно зашифровать три раза по 8 байт и сложить их в выходной файл так, как они лежали в исходном. – А если данных много и некоторые блоки по 8 байт повторяются, это значит, что в выходном файле эти же блоки будут зашифрованы одинаково - это очень плохо.
Второй вопрос :
– А что если данных не 24, а 21 байт.
Не шифровать последние 5 байт или чем-то заполнять еще 3 байта, – а потом при дешифровании их выкидывать. – Первый вариант вообще никуда не годится, а второй применяется, но чем заполнять?
Для решения этих проблем и были введены в криптосистемы алгоритмы создания цепочек (англ. chaining modes). Самый простой метод мы уже в принципе описали. Это метод ECB (Electronic Code Book). Шифруемый файл временно разделяется на блоки, равные блокам алгоритма, каждый из них шифруется независимо, а затем из зашифрованных пакетов данных компонуется в той же последовательности файл, который отныне надежно защищен криптоалгоритмом. Название алгоритм получил из-за того, что в силу своей простоты он широко применялся в простых портативных устройствах для шифрования – электронных шифрокнижках. Схема данного метода приведена на рис.1.
 Рис.1.
Рис.1.
В том случае, когда длина пересылаемого пакета информации не кратна длине блока криптоалгоритма возможно расширение последнего (неполного) блока байт до требуемой длины либо с помощью генератора псевдослучайных чисел, что не всегда безопасно в отношении криптостойкости, либо с помощью хеш-суммы передаваемого текста. Второй вариант более предпочтителен, так как хеш-сумма обладает лучшими статистическими показателями, а ее априорная известность стороннему лицу равносильна знанию им всего передаваемого текста.
Указанным выше недостатком этой схемы является то, что при повторе в исходном тексте одинаковых символов в течение более, чем 2*N байт (где N – размер блока криптоалгоритма), в выходном файле будут присутствовать одинаковые зашифрованные блоки. Поэтому, для более "мощной" защиты больших пакетов информации с помощью блочных шифров применяются несколько обратимых схем "создания цепочек". Все они почти равнозначны по криптостойкости, каждая имеет некоторые преимущества и недостатки, зависящие от вида исходного текста. Все схемы создания цепочек основаны на идее зависимости результирующего зашифровываемого блока от предыдущих, либо от позиции его в исходном файле. Это достигается с помощью блока "памяти" – пакета информации длины, равной длине блока алгоритма. Блок памяти (к нему применяют термин IV – англ. Initial Vector) вычисляется по определенному принципу из всех прошедших шифрование блоков, а затем накладывается с помощью какой-либо обратимой функции (обычно XOR) на обрабатываемый текст на одной из стадий шифрования. В процессе раскодирования на приемной стороне операция создания IV повторяется на основе принятого и расшифрованного текста, вследствие чего алгоритмы создания цепочек полностью обратимы.
Два наиболее распространенных алгоритма создания цепочек – CBC и CFB. Их структура приведена на рис.2 и рис.3. Метод CBC получил название от английской аббревиатуры Cipher Block Chaining – объединение в цепочку блоков шифра, а метод CFB – от Cipher FeedBack – обратная связь по шифроблоку.
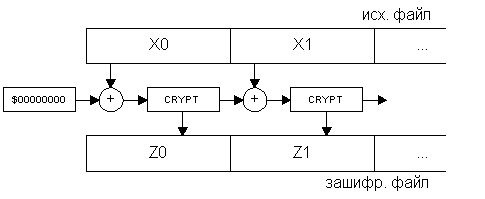 Рис.2.
Рис.2.
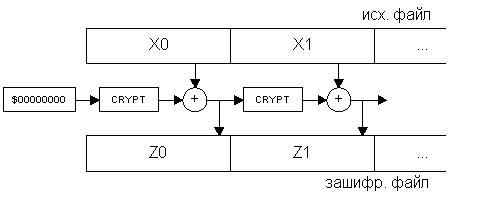 Рис.3.
Рис.3.
Еще один метод OFB (англ. Output FeedBack – обратная связь по выходу) имеет несколько иную структуру (она изображена на рис.4.) : в нем значение накладываемое на шифруемый блок не зависит от предыдущих блоков, а только от позиции шифруемого блока (в этом смысле он полностью соответствует скремблерам), и из-за этого он не распространяет помехи на последующие блоки. Очевидно, что все алгоритмы создания цепочек однозначно восстановимы. Практические алгоритмы создания и декодирования цепочек будут разработаны на практическом занятии.
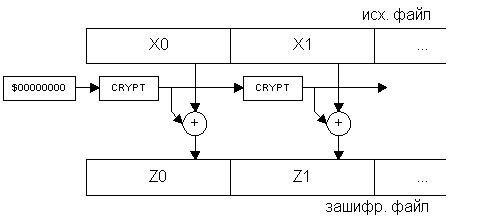 Рис.4.
Рис.4.
Сравним характеристики методов создания цепочек в виде таблицы.
|
Метод |
Шифрование блока зависит от |
Искажение одного бита при передаче |
Кодируется ли некратное блоку число байт без дополнения? |
На выход криптосистемы поступает |
|
ECB |
текущего блока |
портит весь текущий блок |
нет |
выход криптоалгоритма |
|
CBC |
всех предыдущих блоков |
портит весь текущий и все последующие блоки |
нет |
выход криптоалгоритма |
|
CFB |
всех предыдущих блоков |
портит один бит текущего блока и все последующие блоки |
да |
XOR маска с исходным текстом |
|
OFB |
позиции блока в файле |
портит только один бит текущего блока |
да |
XOR маска с исходным текстом |
3. Написать процедуру, которая выполняет вставку компоненты по заданному ключу.
include <stdio.h>
#include <stdlib.h>
#define MyType int
//Будем считать, что ключ в нашем случае - это эзначение типа int.
//Хранение значений -в виде двоичного однонаправленного дерева. Левое поддерево - данные, со значением ключа меньше, чем вершина, прваое - большим, чем вершина.
typedef struct element //элемент-вершина дерева.
{
int key;
struct element * left_el;
struct element * right_el;
MyType val;
} MyElement;
typedef struct
{
MyElement * tree_root; //корень;
int size;
} MyMap; //сама структура хранилища.
MyMap initNewMap()
{
MyMap mm;
mm.tree_root=NULL;
mm.size=0;
return mm;
}
int add_element(MyMap * mm, int k, MyType el) //добавить пару ключ-значение
{
MyElement * new_el = malloc(sizeof(MyElement));
if(new_el)
{
new_el->key=k;
new_el->val=el;
new_el->left_el=NULL;
new_el->right_el=NULL;
if(mm->tree_root==NULL)
{
mm->tree_root=new_el;
mm->size++;
return 0;
}
if(!paste_element(new_el, mm->tree_root))
{
mm->size++;
//printf("SIZE: %d \n", mm->size);
return 0;
}
else
{
printf("ERROR!\n");
}
}
else
{
return -1;
}
}
int paste_element(MyElement * me, MyElement * root) //рекурсивная функция вставки. 0 - в случае успеха, -1 - ошибка
{
if(root==NULL)
{
return -1;
}
if(me->key==root->key)
{
root->val=me->val;
return 0;
//printf("ALREADY EXIST!\n"); //Значиение с совпадающим ключем заменяет текущее
}
if(me->key<root->key)
{
if(root->left_el==NULL)
{
//printf("ADD LEFT!\n");
root->left_el=me;
return 0;
}
else
root=root->left_el;
}
if(me->key>root->key)
{
if(root->right_el==NULL)
{
//printf("ADD Right!\n");
root->right_el=me;
return 0;
}
else
root=root->right_el;
}
paste_element(me, root);
}
MyType get_value(MyMap *mm, int key)
{
return find_element(key, mm->tree_root);
}
MyType find_element(int key, MyElement * root)
{
if(root==NULL)
{
return -1;
}
if(key==root->key)
return root->val;
else
{
if(key<root->key)
{
if(root->left_el==NULL)
{
return -1;
}
else
root=root->left_el;
}
if(key>root->key)
{
if(root->right_el==NULL)
{
return -1;
}
else
root=root->right_el;
}
find_element(key, root);
}
}
int main(void)
{
MyMap m_map = initNewMap();
add_element(&m_map, 12, 13);
add_element(&m_map, 15, 14);
add_element(&m_map, 14, 16);
add_element(&m_map, 15, 12);
add_element(&m_map, 19, 123);
add_element(&m_map, 39, 121);
printf ("VALUE 15: %d\n",get_value(&m_map, 15));
printf ("VALUE 19: %d\n",get_value(&m_map, 19));
printf ("VALUE 12: %d\n",get_value(&m_map, 12));
printf ("VALUE 12: %d\n",get_value(&m_map, 552));
return 0;
}
Билет 4.
1. Нормальный алгоритм Маркова.
Норма́льный алгори́тм Ма́ркова (НАМ) — один из стандартных способов формального определения понятия алгоритма. Понятие нормального алгоритма введено А. А. Марковымв конце1940-хгодов. Традиционно, когда говорят об алгоритмах Маркова, используют слово «алгорифм».
Нормальный алгоритм описывает метод переписывания строк, похожий по способу задания на формальные грамматики.НАМ является Тьюринг-полнымязыком, что делает его по выразительной силе эквивалентныммашине Тьюрингаи следовательно современным языкам программирования. ( про машину Тьюринга лучше не упоминать, чтобы не было дополнительных вопросов, но в курсе дела надо быть).
На основе НАМ был создан функциональныйязык программированияРефал.
Нормальные
алгоритмы являются вербальными, то есть
предназначенными для применения к
словам в различных алфавитах. Определение
всякого нормального алгоритма состоит
из двух частей: определения алфавита
алгоритма (к словам из символов которого
алгоритм будет применяться) и определения
его схемы. Схемой нормального алгоритма
называется конечный упорядоченный
набор т. н. формул подстановки,
каждая из которых может быть простой
или заключительной. Простыми формулами
подстановки называются слова вида ![]() ,
где L и D —
два произвольных слова в алфавите
алгоритма (называемые, соответственно,
левой и правой частями формулы
подстановки). Аналогично, заключительными
формулами подстановки называются слова
вида
,
где L и D —
два произвольных слова в алфавите
алгоритма (называемые, соответственно,
левой и правой частями формулы
подстановки). Аналогично, заключительными
формулами подстановки называются слова
вида ![]() ,
где L и D —
два произвольных слова в алфавите
алгоритма. При этом предполагается, что
вспомогательные буквы
,
где L и D —
два произвольных слова в алфавите
алгоритма. При этом предполагается, что
вспомогательные буквы ![]() и
и ![]() не
принадлежат алфавиту алгоритма (в
противном случае на исполняемую ими
роль разделителя левой и правой частей
следует избрать другие две буквы).
не
принадлежат алфавиту алгоритма (в
противном случае на исполняемую ими
роль разделителя левой и правой частей
следует избрать другие две буквы).
Примером схемы нормального алгоритма в пятибуквенном алфавите | * abc может служить схема
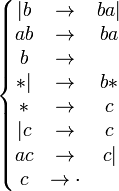
Процесс
применения нормального алгоритма к
произвольному слову V в
алфавите этого алгорифма представляет
собой дискретную последовательность
элементарных шагов, состоящих в следующем.
Пусть V' —
слово, полученное на предыдущем шаге
работы алгорифма (или исходное слово V,
если текущий шаг является первым). Если
среди формул подстановки нет такой,
левая часть которой входила бы в V',
то работа алгоритма считается завершённой,
и результатом этой работы считается
слово V'.
Иначе среди формул подстановки, левая
часть которых входит в V',
выбирается самая верхняя. Если эта
формула подстановки имеет вид ![]() ,
то из всех возможных представлений
слова V' в
виде RLS выбирается
такое, при котором R —
самое короткое, после чего работа
алгоритма считается завершённой с
результатом RDS.
Если же эта формула подстановки имеет
вид
,
то из всех возможных представлений
слова V' в
виде RLS выбирается
такое, при котором R —
самое короткое, после чего работа
алгоритма считается завершённой с
результатом RDS.
Если же эта формула подстановки имеет
вид ![]() ,
то из всех возможных представлений
слова V' в
виде RLS выбирается
такое, при котором R —
самое короткое, после чего слово RDSсчитается
результатом текущего шага, подлежащим
дальнейшей переработке на следующем
шаге.
,
то из всех возможных представлений
слова V' в
виде RLS выбирается
такое, при котором R —
самое короткое, после чего слово RDSсчитается
результатом текущего шага, подлежащим
дальнейшей переработке на следующем
шаге.
Например, в ходе процесса применения алгорифма с указанной выше схемой к слову | * | | последовательно возникают слова | b * | , ba | * | , a | * | , a | b * , aba | * , baa | * , aa | * ,aa | c, aac, ac | и c | | , после чего алгорифм завершает работу с результатом | | . Другие примеры смотрите ниже.
Нормальные алгорифмы оказались удобным средством для построения многих разделов конструктивной математики. Кроме того, заложенные в определении нормального алгорифма идеи используются в ряде ориентированных на обработку символьной информации языков программирования — например, в языкеРефал.
Пример
Данный алгоритм преобразует двоичные числав «единичные», то есть на выходе получается строка из N единичек, если на входе у нас было N в двоичной системе. Например, 101 преобразуется в 5 единиц:
Правила:
«|0» → "0||"
«1» → "0|"
«0» → "" (пустая строка)
Исходная строка:
«101»
Выполнение:
«0|01»
«00||1»
"00||0|"
"00|0|||"
"000|||||"
"00|||||"
"0|||||"
"|||||"
2. Парадигмы интерфейсов.
Для пользовательских интерфейсов (ПИ) программ существует три парадигмы: технологическая, метафорическая и идиоматическая. Технологическая парадигма основана на понимании механизма работы программы – сложный подход. Метафорическая основана на интуитивном понимании – проблематичный подход. Идиоматическая парадигма основана на знании о том, как решать ту или иную задачу – естественный для человека процесс.
Технологическая парадигма ПИ означает, что интерфейс выражается в понятиях его конструкции, как он был построен. Чтобы успешно им пользоваться, пользователь должен понимать, как работает программа. Технологическая парадигма понятна инженерам, которые хотят знать, как все устроено. Они предпочитают видеть все шестеренки, рычаги и клапаны, потому что это позволяет им понять, что происходит внутри машины. Им кажется неважным, что эти артефакты без необходимости засоряют интерфейс. Но большинство пользователей – не инженеры и совершенно не хотят разбираться в устройстве программ или же не имеют на это времени. Для них важнее выполнять свою работу, а не набираться опыта, что инженерам часто трудно понять.
Метафорическая парадигма
Современный графический интерфейс пользователя был изобретен в Исследовательском Центре Пало Альто фирмы Хerox (PARC) и был сразу же подхвачен промышленностью. Графический интерфейс пользователя, разработанный в PARC состоял из различных объектов: окна, кнопки, иконки, метафоры, меню. Первой успешной в коммерческом плане реализацией интерфейса PARC стал Макинтош, с его метафорами рабочего стола, мусорной корзины и папок с файлами.
Метафоры плохо "масштабируются". Метафора, хорошо работающая для простого случая в простой программе часто перестает работать, как только задача усложняется и увеличивается в размере. Метафоры мы понимаем интуитивно. Мы схватываем смысл метафорического элемента управления в интерфейсе, мысленно отождествляя его с каким-либо другим процессом или предметом, на познавание которого мы уже затратили время и силы. Эффективность этого метода огромна, потому что она использует грозное оружие человеческого ума – способность делать логические выводы. Процессор этого делать не умеет. Слабая сторона этого метода в том, что он зависит от капризного человеческого ума, который может не иметь знаний или логических способностей, необходимых для совершения отождествления. Метафоры не ответственны за то, как их понимают. Метафорическая парадигма – шаг вперед, потомучто ее интуитивное понимание происходит без всякого знания механизма работы программ.
Идиоматическая парадигма
Идиоматический метод разработки ПИ основан на том, как мы узнаем и используем идиомы, или фигуры речи, как например "рояль в кустах" или "первый блин комом". Они легко понятны, но не так, как метафоры. Мы понимаем идиомы, потому что уже знаем их. Большинство элементов управления в графическом интерфейсе пользователя – идиомы. Кнопки, выпадающие списки и полосы прокрутки – это то, что мы узнаем автоматически, а не догадываемся метафорически.
Всем хорошо знакомая мышь не является метафорой чего-либо. Люди обучаются работе с ней идиоматически. В мыши нет ничего, что указывало бы на цель ее применения. Она также не напоминает ничего из нашего опыта, так что обучение работе с ней не интуитивно. Однако научиться работать мышью очень легко. Некто наверняка потратил секунды три, чтобы в первый раз показать вам, как она работает, и вы сразу поняли. Нам не нужно знать, как устроена мышь, но, тем не менее, мы можем прекрасно ею пользоваться. Это и есть идиоматическое обучение.
Профессионалам маркетинга хорошо знаком способ взять простое действие или символ и наполнить его смыслом. Синтезированные идиомы – основа продвижения торговой марки продукта, когда компания наполняет свое название или название продукта новым смыслом. Конечно, идиомы могут быть и визуальными. Золотые арки МакДональдс, три алмаза Мицубиси и даже летящее окно Майкрософт – не метафорические идиомы, которые наполнены внутренним смыслом и опознаются сразу же.
Ирония в том, что большинство знакомых нам элементов GUI, которые считаются метафорическими, на самом деле являются идиоматическими. Такие артефакты, как кнопки закрытия окна, бесконечно вложенные папки с файлами, щелчки мышью и перетаскивание пиктограмм – не метафорические операции, потому что их нет в реальном мире. Их сила лишь в простой идиоматической узнаваемости.
3. На языке С++ вычислить сумму ряда целых чисел от 1 до n.
#pragma hdrstop
//---------------------------------------------------------------------------
#include <iostream.h>
void main()
{
int N,S=0,i;
cout<<"\n Vvedite N ==";
cin>>N;
for(i=1;i<=N;i++) S=S+i;
cout<<"\n Summa =="<<S;
}
Билет 5.
1. Понятие процесса. Состояние процессов. Алгоритмы планирования процессов.
Важнейшей частью операционной системы, непосредственно влияющей на функционирование вычислительной машины, является подсистема управления процессами. Процесс (или по-другому, задача) - абстракция, описывающая выполняющуюся программу. Для операционной системы процесс представляет собой единицу работы, заявку на потребление системных ресурсов. Подсистема управления процессами планирует выполнение процессов, то есть распределяет процессорное время между несколькими одновременно существующими в системе процессами, а также занимается созданием и уничтожением процессов, обеспечивает процессы необходимыми системными ресурсами, поддерживает взаимодействие между процессами.
Алгоритмы планирования процессов
Планирование процессов включает в себя решение следующих задач:
А) определение момента времени для смены выполняемого процесса;
Б)выбор процесса на выполнение из очереди готовых процессов;
В)переключение контекстов "старого" и "нового" процессов.
Первые две задачи решаются программными средствами, а последняя в значительной степени аппаратно
Среди этого множества алгоритмов рассмотрим подробнее две группы наиболее часто встречающихся алгоритмов: алгоритмы, основанные на квантовании, и алгоритмы, основанные на приоритетах.
В соответствии с алгоритмами, основанными на квантовании, смена активного процесса происходит, если:
А)процесс завершился и покинул систему,
Б)произошла ошибка,
В)процесс перешел в состояние ОЖИДАНИЕ,
Г)исчерпан квант процессорного времени, отведенный данному процессу.
Процесс, который исчерпал свой квант, переводится в состояние ГОТОВНОСТЬ и ожидает, когда ему будет предоставлен новый квант процессорного времени, а на выполнение в соответствии с определенным правилом выбирается новый процесс из очереди готовых. Таким образом, ни один процесс не занимает процессор надолго, поэтому квантование широко используется в системах разделения времени.
Другая группа алгоритмов использует понятие "приоритет" процесса. Приоритет - это число, характеризующее степень привилегированности процесса при использовании ресурсов вычислительной машины, в частности, процессорного времени: чем выше приоритет, тем выше привилегии.
Приоритет может выражаться целыми или дробными, положительным или отрицательным значением. Чем выше привилегии процесса, тем меньше времени он будет проводить в очередях. Приоритет может назначаться директивно администратором системы в зависимости от важности работы или внесенной платы, либо вычисляться самой ОС по определенным правилам, он может оставаться фиксированным на протяжении всей жизни процесса либо изменяться во времени в соответствии с некоторым законом. В последнем случае приоритеты называются динамическими.
Существует две разновидности приоритетных алгоритмов: алгоритмы, использующие относительные приоритеты, и алгоритмы, использующие абсолютные приоритеты.
В обоих случаях выбор процесса на выполнение из очереди готовых осуществляется одинаково: выбирается процесс, имеющий наивысший приоритет. По разному решается проблема определения момента смены активного процесса. В системах с относительными приоритетами активный процесс выполняется до тех пор, пока он сам не покинет процессор, перейдя в состояние ОЖИДАНИЕ (или же произойдет ошибка, или процесс завершится). В системах с абсолютными приоритетами выполнение активного процесса прерывается еще при одном условии: если в очереди готовых процессов появился процесс, приоритет которого выше приоритета активного процесса. В этом случае прерванный процесс переходит в состояние готовности.
Во многих операционных системах алгоритмы планирования построены с использованием как квантования, так и приоритетов. Например, в основе планирования лежит квантование, но величина кванта и/или порядок выбора процесса из очереди готовых определяется приоритетами процессов.
2. Общие сведения об ассиметричных криптоалгоритмах. Понятие электронной цифровой подписи.
Асимметричная криптография изначально задумана как средство передачи сообщений от одного объекта к другому (а не для конфиденциального хранения информации, которое обеспечивают только симметричные алгоритмы). Поэтому дальнейшее объяснение мы будем вести в терминах "отправитель" – лицо, шифруюшее, а затем отпраляющее информацию по незащищенному каналу и "получатель" – лицо, принимающее и восстанавливающее информацию в ее исходном виде. Основная идея асимметричных криптоалгоритмов состоит в том, что для шифрования сообщения используется один ключ, а при дешифровании – другой.
Кроме того, процедура шифрования выбрана так, что она необратима даже по известному ключу шифрования – это второе необходимое условие асимметричной криптографии. То есть, зная ключ шифрования и зашифрованный текст, невозможно восстановить исходное сообщение – прочесть его можно только с помощью второго ключа – ключа дешифрования. А раз так, то ключ шифрования для отправки писем какому-либо лицу можно вообще не скрывать – зная его все равно невозможно прочесть зашифрованное сообщение. Поэтому, ключ шифрования называют в асимметричных системах "открытым ключом", а вот ключ дешифрования получателю сообщений необходимо держать в секрете – он называется "закрытым ключом". Напрашивается вопрос : "Почему, зная открытый ключ, нельзя вычислить закрытый ключ ?" – это третье необходимое условие асимметричной криптографии – алгоритмы шифрования и дешифрования создаются так, чтобы зная открытый ключ, невозможно вычислить закрытый ключ.
В целом система переписки при использовании асимметричного шифрования выглядит следующим образом. Для каждого из N абонентов, ведущих переписку, выбрана своя пара ключей : "открытый" Ej и "закрытый" Dj, где j – номер абонента. Все открытые ключи известны всем пользователям сети, каждый закрытый ключ, наоборот, хранится только у того абонента, которому он принадлежит. Если абонент, скажем под номером 7, собирается передать информацию абоненту под номером 9, он шифрует данные ключом шифрования E9 и отправляет ее абоненту 9. Несмотря на то, что все пользователи сети знают ключ E9 и, возможно, имеют доступ к каналу, по которому идет зашифрованное послание, они не могут прочесть исходный текст, так как процедура шифрования необратима по открытому ключу. И только абонент №9, получив послание, производит над ним преобразование с помощью известного только ему ключа D9 и восстанавливает текст послания. Заметьте, что если сообщение нужно отправить в противоположном направлении (от абонента 9 к абоненту 7), то нужно будет использовать уже другую пару ключей (для шифрования ключ E7, а для дешифрования – ключ D7).
Как мы видим, во-первых, в асимметричных системах количество существующих ключей связано с количеством абонентов линейно (в системе из N пользователей используются 2*N ключей), а не квадратично, как в симметричных системах. Во-вторых, при нарушении конфиденциальности k-ой рабочей станции злоумышленник узнает только ключ Dk : это позволяет ему читать все сообщения, приходящие абоненту k, но не позволяет вывадавать себя за него при отправке писем. Кроме этого, асимметричные криптосистемы обладают еще несколькими очень интересными возможностями, которые мы рассмотрим через несколько разделов.
Цифровые подписи
Некоторые из асимметричных алгоритмов могут использоваться для генерирования цифровой подписи. Цифровой подписью называют блок данных, сгенерированный с использованием некоторого секретного ключа. При этом с помощью открытого ключа вы имеете возможность проверить, что данные были действительно сгенерированы с помощью этого секретного ключа. Алгоритм генерации цифровой подписи должен обеспечивать, чтобы было невозможно без секретного ключа создать подпись, которая при проверке окажется правильной. Цифровые подписи используются для того, чтобы подтвердить, что сообщение пришло действительно от данного отправителя (в предположении, что лишь отправитель обладает секретным ключом, соответствующим его открытому ключу). Также подписи используются для проставления штампа времени (timestamp) на документах: сторона, которой мы доверяем, подписывает документ со штампом времени с помощью своего секретного ключа и, таким образом, подтверждает, что документ уже существовал в момент, объявленный в штампе времени. Цифровые подписи также вы имеете возможность использовать для удостоверения (сертификации — to certify) того, что документ принадлежит определенному лицу. Это делается так: открытый ключ и информация о том, кому он принадлежит подписываются стороной, которой доверяем. При этом доверять подписывающей стороне мы можем на основании того, что ее ключ был подписан третьей стороной. Таким образом возникает иерархия доверия. Очевидно, что некоторый ключ должен быть корнем иерархии (то есть ему мы доверяем не потому, что он кем-то подписан, а потому, что мы верим a-priori, что ему можно доверять). В централизованной инфраструктуре ключей имеется очень небольшое количество корневых ключей сети (например, облеченные полномочиями государственные агентства; их также называют сертификационными агентствами — certification authorities). В распределенной инфраструктуре нет необходимости иметь универсальные для всех корневые ключи, и каждая из сторон может доверять своему набору корневых ключей (скажем своему собственному ключу и ключам, ею подписанным). Эта концепция носит название сети доверия (web of trust) и реализована, например, в PGP. Цифровая подпись документа обычно создается так: из документа генерируется так называемый дайджест (message digest) и к нему добавляется информация о том, кто подписывает документ, штамп времени и прочее. Получившаяся строка далее зашифровывается секретным ключом подписывающего с использованием того или иного алгоритма. Получившийся зашифрованный набор бит и представляет собой подпись. К подписи обычно прикладывается открытый ключ подписывающего. Получатель сначала решает для себя, доверяет ли он тому, что открытый ключ принадлежит именно тому, кому должен принадлежать (с помощью сети доверия или априорного знания), и затем дешифрует подпись с помощью открытого ключа. В случае, если подпись нормально дешифровалась, и ее содержимое соответствует документу (дайджест и др.), то сообщение считается подтвержденным. Свободно доступны несколько методов создания и проверки цифровых подписей. Наиболее известным является алгоритм RSA.
3. Вычислить факториал числа 8.
int res = 1;
for (int i = 2; i<9; i++)
{
res = res*i;
}
Билет 6.
1. Файловая система FAT.
FAT является наиболее простой из поддерживаемых Windows NT файловых систем. Основой файловой системы FAT является таблица размещения файлов, которая помещена в самом начале тома. На случай повреждения на диске хранятся две копии этой таблицы. Кроме того, таблица размещения файлов и корневой каталог должны храниться в определенном месте на диске (для правильного определения места расположения файлов загрузки).
Диск, отформатированный в файловой системе FAT, делится на кластеры, размер которых зависит от размера тома. Одновременно с созданием файла в каталоге создается запись и устанавливается номер первого кластера, содержащего данные. Такая запись в таблице размещения файлов сигнализирует о том, что это последний кластер файла, или указывает на следующий кластер.
Обновление таблицы размещения файлов имеет большое значение и требует много времени. Если таблица размещения файлов не обновляется регулярно, это может привести к потере данных. Длительность операции объясняется необходимостью перемещения читающих головок к логической нулевой дорожке диска при каждом обновлении таблицы FAT.
Каталог FAT не имеет определенной структуры, и файлы записываются в первом обнаруженном свободном месте на диске. Кроме того, файловая система FAT поддерживает только четыре файловых атрибута: «Системный», «Скрытый», «Только чтение» и «Архивный».
Имена файлов в FAT
В файловой системе FAT использован традиционный формат имен 8.3, имена файлов должны состоять из символов ASCII. Имя файла или каталога должно состоять не более чем из 8 символов, затем следует разделитель «.» (точка) и расширение длиной до 3 символов. Первым символом имени должна быть буква или цифра. При определении имени можно использовать все символы за исключением перечисленных ниже.
. " / \ [ ] : ; | = ,
Использование этих символов может привести к получению неожиданных результатов. Имя не должно содержать пробелов.
Указанные ниже имена зарезервированы.
CON, AUX, COM1, COM2, COM3, COM4, LPT1, LPT2, LPT3, PRN, NUL
Преимущества файловой системы FAT
На компьютере под управлением Windows NT в любой из поддерживаемых файловых систем нельзя отменить удаление. Программа отмены удаления пытается напрямую обратиться к оборудованию, что невозможно при использовании Windows NT. Однако если файл находился в FAT-разделе, то, запустив компьютер в режиме MS-DOS, удаление файла можно отменить. Файловая система FAT лучше всего подходит для использования на дисках и разделах размером до 200 МБ, потому что она запускается с минимальными накладными расходами.
Недостатки файловой системы FAT
Как правило, не стоит использовать файловую систему FAT для дисков и разделов, чей размер больше 200 МБ. Это объясняется тем, что по мере увеличения размера тома производительность файловой системы FAT быстро падает. Для файлов, расположенных в разделах FAT, невозможно установить разрешения. Разделы FAT имеют ограничение по размеру: 4 ГБ под Windows NT и 2 ГБ под MS-DOS.
2. Основные компоненты графических пользовательских интерфейсов.
Основными элементами графического пользовательского интерфейса (ГПИ) являются: окна, пиктограммы, компоненты ввода-вывода и мышь, которую используют в качестве указывающего устройства и устройства прямого манипулирования объектами на экране.
Окно – обычно прямоугольная, ограниченная рамкой область физического экрана. Окно может менять размеры и местоположение в пределах экрана. Все окна можно разделить на 5 категорий:
1) основные окна (окна приложений);
2) дочерние или подчиненные окна;
3) окна диалога;
4) информационные окна;
5) окна меню.
Окно приложения обычно содержит: рамку, ограничивающую рабочую область окна, строку заголовка с кнопкой системного меню и кнопками выбора представления окна и выхода, строку меню, пиктографическое меню (панель инструментов), горизонтальные и вертикальные прокрутки и строку состояния.
Дочернее окно используют в многодокументных программных интерфейсах (MDI), предполагающих, что ПО должно работать с несколькими документами одновременно. В отличие от окна приложения дочернее окно не содержит меню. В строке заголовка – специальное имя.
Пиктограмма представляет собой небольшое окно с графическим изображением, отражающим содержимое буфера, с которым она связана. Различают:
-программные пиктограммы;
-пиктограммы дочерних окон;
-пиктограммы панели инструментов;
-пиктограммы объектов.
Программными пиктограммами, которые связаны с соответствующей программой, управляет ОС. Так, можно «свернуть» окно приложения в пиктограмму на панели задач Windows или «развернуть» его обратно «на рабочий стол». Аналогично многодокументная программная система управляет пиктограммами дочерних окон, обеспечивающими доступ к различным документа, одновременно обрабатываемым программной системой. Пиктограммы панели инструментов обычно дублируют доступ к соответствующим функциям через меню, обеспечивая их быстрый вызов. Пиктограммы объектов используют для прямого манипулирования этими объектами. Как правило, все пиктограммы можно перемещать мышью. Для облегчения работы с пиктограммами обычно использую «всплывающие» подсказки, которые появляются, если пользователь в течение некоторого времени удерживает мышь над пиктограммой панели инструментов.
Прямое манипулирование изображением - это возможность замены команды воздействия на некоторый объект физическим действием в интерфейсе, осуществляемым с помощью мыши. При этом любая область экрана рассматривается как адресат, который может быть активизирован при подведении курсора и нажатии клавиши мыши. По реакции на воздействие различают следующие типы адресатов:
-указание и выбор (развертывание пиктограмм, определение активного окна и т.п.);
-буксировка и «резиновая нить» (перенос объекта или его границ);
-экранные кнопки и «скользящие» барьеры (выполнение дискретных или циклически повторяемых действий, например, выполнение некоторой операции или рисование, подразумеваемых при активизации определенной области экрана - кнопки).
Не последняя роль в графических интерфейсах отводится динамическим визуальным сигналам, которые представляют собой изменение изображения на экране. Основная цель этих сигналов заключается в предоставлении пользователям дополнительной информации. Простейшим примером такого сигнала является изменение изображения курсора мыши при выполнении конкретных операций, например, изображение его в форме песочных часов во время обработки. Другой пример - изменение изображения кнопки при нажатии на нее. Хотя в отличие от анимационных интерфейсов прямого манипулирования эти визуальные сигналы играют в ГПИ вспомогательную роль, обеспечивая более реалистическую картинку.
Компоненты ввода-вывода. Интерфейс практически любого современного ПО включает несколько меню: основное или «ниспадающее» иерархическое меню, пиктографические меню (панели инструментов) и контекстные меню для разных ситуаций. Любое из указанных меню представляет собой компонент ввода-вывода, реализующий диалог с пользователем, используя табличную форму.
Иерархические меню используют, чтобы организовать выполняемые ПО операции, программным обеспечением операции, если их число превышает 5-8 (6 в соответствии с рекомендациями фирмы IBM), и обеспечить пользователю их обзор. Панели инструментов и контекстные меню применяют, для обеспечения быстрого доступа к часто используемым командам, обеспечивая, пользователю возможность относительно свободной навигации.
Кроме меню в интерфейсе используют и другие компоненты ввода-вывода, которые можно разделить на три группы в соответствии с тем, какую форму диалога они реализуют: фразовую, табличную или смешанную. Директивная форма диалога обычно предполагает ввод комбинаций клавиш или перемещение пиктограмм, а потому не требует использования компонентов ввода-вывода.
К элементам графического интерфейса также относят:
Кнопки – элементы управления, позволяющие выбрать опцию или вызвать событие (например, запуск подпрограммы). Все взаимодействие пользователя с кнопкой ограничивается нажатием.
Командные кнопки (Push Buttons) – нажатие на такую кнопку запускает какое-либо явное действие (кнопки прямого действия). Изображаются в виде прямоугольника, в центре размещается короткое текстовое сообщение, поясняющее, какое именно событие инициирует нажатие кнопки. Командная кнопка имеет три состояния: нормальное (кнопка доступна, но еще не активирована пользователем), нажатое (активированное) и недоступное (неактивное) (если недоступна функция, закрепленная за кнопкой, или если кнопка расположена в фоновом окне).
Чекбоксы (Checkboxes) и радиокнопки (Radio buttons) – кнопки отложенного действия, т.е. их нажатие не инициирует какое-либо немедленное действие, с их помощью пользователи вводят некоторые параметры, которые скажутся после, когда действие будет запущено другими элементами управления. Главное отличие состоит в том, что радиокнопки являются кнопками единственного выбора, а чекбоксы – множественного. В группе радиокнопок как минимум одна кнопка должна быть проставлена по умолчанию.
Вариантом реализации радиокнопок и чекбоксов являются списки (list boxes) – специализированные средства управления, которые отображают раскрывающиеся перечни значений (часто с присоединенными слайдерами, чтобы перемещаться вверх или вниз по списку) и позволяют пользователю выбирать значение из списка или вводить другое значение в присоединенное текстовое поле.
Списки бывают пролистываемыми и раскрывающимися, причем пролистываемые могут обеспечивать как единственный (аналогично группе радиокнопок), так и множественный выбор (чекбокс); раскрывающиеся же работают исключительно как радиокнопки. Скорость доступа к отдельным элементам и наглядность в списках принесены в жертву компактности (они экономят экранное пространство, что актуально, если количество элементов велико) и расширяемости (простота загрузки в списки динамически изменяемых элементов делает их очень удобными при разработке интерфейса, поскольку позволяет не показывать пользователю заведомо неработающие элементы).
Список единственного выбора является промежуточным вариантом между группой радиокнопок и раскрывающимся списком. Он меньше группы радиокнопок с аналогичным числом элементов, но больше раскрывающегося списка. Соответственно, использовать его стоит только в условиях «ленивой экономии» пространства экрана.
Списки множественного выбора позволяют выбрать несколько вариантов из набора предложенных.
Комбобоксами (combo box), называются гибриды списка c полем ввода: пользователь может выбрать существующий элемент, либо ввести свой. Комбобоксы бывают двух видов: раскрывающиеся и расширенные.
Поля ввода (edit text fields) являются основой любого интерфейса.
Слайдеры (Sliders) или ползунки – элемент управления, состоящий из полосы прокрутки (slider bar), показывающей допустимо возможное значение изменяемого параметра (например, яркость или контрастность изображения), и индикатора (ползунка), показывающего текущее состояние. Слайдеры могут быть горизонтальными или вертикальными, перемещение индикатора может быть квантованным или нет.
Крутилка (spinner, little arrow) – элемент управления, который позволяет пользователю уменьшать или увеличивать значение некоторой величины. Крутилки также могут содержать поле ввода, не такое универсальное, как обычное, не позволяющее вводить текстовые данные, но зато обладающее двумя полезными возможностями. Во-первых, чтобы ввести значение в крутилку, пользователю не обязательно бросать мышь и переносить руку на клавиатуру. Во-вторых, при вводе значения мышью система может позволить пользователям вводить только корректные данные, причем в корректном формате. Это резко уменьшает вероятность человеческой ошибки.
Меню – это метод взаимодействия пользователя с системой, при котором пользователь выбирает из предложенных вариантов, а не предоставляет системе свою команду. Соответственно, диалоговое окно с несколькими кнопками (и без единого поля ввода) также является меню.
Существую несколько различных классификаций меню. Первая классификация делит меню на два типа:
Статические меню, т.е. меню, постоянно присутствующие на экране. Характерным примером такого типа меню является панель инструментов.
Динамические меню, в которых пользователь должен вызвать меню, чтобы выбрать какой либо элемент. Примером является обычное контекстное меню.
Статические меню, как правило, обеспечивают высокую скорость работы, лучше обучают пользователей, но зато занимают место на экране. Напротив, с динамическими меню ситуация обратная.
Вторая классификация также делит меню на два типа:
Меню, разворачивающиеся в пространстве (например, обычное выпадающее меню). Всякий раз, когда пользователь выбирает элемент нижнего уровня, верхние элементы остаются видимыми.
Меню, разворачивающееся во времени. При использовании таких меню элементы верхнего уровня по тем или иным причинам исчезают с экрана. Например, диалоговое окно с меню может перекрывать элемент управления, которым это меню было вызвано.
Изображения (Иконки)
В интерфейсе непосредственного манипулирования, пользователи выполняют действия непосредственно на видимых объектах. Этими объектами могут быть кнопки, метки, меню или изображения (иконки). Все иконки можно классифицировать согласно тому, насколько точно они отображают несущую функцию.
Иконки подобия - иконки похожи на объекты, которые они отображают (типа ножниц, чтобы отобразить операцию «вырезки»);
Иконки по образцу представляют пример типа объекта (например иконкой, показывающей линию, чтобы представить средство рисования);
Символические иконки - используются, чтобы представить действие или состояние в символической форме (например, разорванная линия между двумя компьютерами для того, чтобы показать разорванное сетевое соединение);
Произвольные иконки - не несут никакой информации по поводу их представления, поэтому их назначение должно быть описано (например, обратная круговая стрелка, чтобы представить действие «отмена последней команды»)
Курсоры – средство обеспечения обратной связи. Например, всякий раз, когда пользователь подводит курсор к углу окна, курсор изменяется, показывая пользователю, что форму окна можно увеличить.
3. Если элементы массивы D[1…5] равны соответственно 4, 1, 5, 3, 2, то значение выражение D[D[3]]-D[D[5]] равно?
D[D[3]] – D[D[5]] = D[5] – D[2] = 2 – 1 = 1
Ответ: 1.
Билет 7
1. Структуры распределенных вычислительных систем(топология, физические и логические элементы сетей ЭВМ)
Топология локальных сетей. Под топологией (компоновкой, конфигурацией, структурой) компьютерной сети обычно понимается физическое расположение компьютеров сети друг относительно друга и способ соединения их линиями связи. Важно отметить, что понятие топологии относится прежде всего к локальным сетям, в которых структуру связей можно легко проследить. В глобальных сетях структура связей обычно скрыта от пользователей не слишком важна, так как каждый сеанс связи может производиться по своему собственному пути. Топология определяет требования к оборудованию, тип используемого кабеля, возможные и наиболее удобные методы управления обменом, надежность работы, возможности расширения сети. И хотя выбирать топологию пользователю сети приходится нечасто, знать об особенностях основных топологий, их достоинствах и недостатках, наверное, надо всем. Существует три основных топологии сети: 1.шина (bus), при которой все компьютеры параллельно подключаются к одной линии связи и информация от каждого компьютера одновременно передается всем остальным компьютерам (рис. 1.1); 2.звезда (star), при которой к одному центральному компьютеру присоединяются остальные периферийные компьютеры, причем каждый из них использует свою отдельную линию связи (рис. 1.2); 3.кольцо (ring), при которой каждый компьютер передает информацию всегда только одному компьютеру, следующему в цепочке, а получает информацию только от предыдущего в цепочке компьютера, и эта цепочка замкнута в «кольцо» (рис. 1.3).
Многозначность понятия топологии. Топология сети определяет не только физическое расположение компьютеров, но, что гораздо важнее, характер связей между ними, особенности распространения сигналов по сети. Именно характер связей определяет степень отказоустойчивости сети, требуемую сложность сетевой аппаратуры, наиболее подходящий метод управления обменом, возможные типы сред передачи (каналов связи), допустимый размер сети (длина линий связи и количество абонентов), необходимость электрического согласования и многое другое. Когда в литературе упоминается о топологии сети, то могут подразумевать четыре совершенно разных понятия, относящихся к различным уровням сетевой архитектуры: Физическая топология (то есть схема расположения компьютеров и прокладки кабелей). Логическая топология (то есть структура связей, характер распространения сигналов по сети). Это, наверное, наиболее правильное определение топологии. Топология управления обменом (то есть принцип и последовательность передачи права на захват сети между отдельными компьютерами). Информационная топология (то есть направление потоков информации, передаваемой по сети).
Топология все-таки не является основным фактором при выборе типа сети. Гораздо важнее, например, уровень стандартизации сети, скорость обмена, количество абонентов, стоимость оборудования, выбранное программное обеспечение. Но, с другой стороны, некоторые сети позволяют использовать разные топологии на разных уровнях. Этот выбор уже целиком ложится на пользователя, который должен учитывать все перечисленные в данном разделе соображения.
Все компьютеры в локальной сети соединены линиями связи. Геометрическое расположение линий связи относительно узлов сети и физическое подключение узлов к сети называется физической топологией. В зависимости от топологии различают сети: шинной, кольцевой, звездной, иерархической и произвольной структуры.
Различают физическую и логическую топологию. Логическая и физическая топологии сети независимы друг от друга. Физическая топология - это геометрия построения сети, а логическая топология определяет направления потоков данных между узлами сети и способы передачи данных. В настоящее время в локальных сетях используются следующие физические топологии:
физическая "шина" (bus);
физическая “звезда” (star);
физическое “кольцо” (ring);
физическая "звезда" и логическое "кольцо" (Token Ring).
Шинная топология
Сети с шинной топологией используют линейный моноканал (коаксиальный кабель) передачи данных, на концах которого устанавливаются оконечные сопротивления (терминаторы). Каждый компьютер подключается к коаксиальному кабелю с помощью Т-разъема (Т - коннектор). Данные от передающего узла сети передаются по шине в обе стороны, отражаясь от оконечных терминаторов. Терминаторы предотвращают отражение сигналов, т.е. используются для гашения сигналов, которые достигают концов канала передачи данных. Таким образом, информация поступает на все узлы, но принимается только тем узлом, которому она предназначается. В топологии логическая шина среда передачи данных используются совместно и одновременно всеми ПК сети, а сигналы от ПК распространяются одновременно во все направления по среде передачи. Так как передача сигналов в топологии физическая шина является широковещательной, т.е. сигналы распространяются одновременно во все направления, то логическая топология данной локальной сети является логической шиной. Данная топология применяется в локальных сетях с архитектурой Ethernet (классы 10Base-5 и 10Base-2 для толстого и тонкого коаксиального кабеля соответственно).
Преимущества сетей шинной топологии:
отказ одного из узлов не влияет на работу сети в целом;
сеть легко настраивать и конфигурировать;
сеть устойчива к неисправностям отдельных узлов.
Недостатки сетей шинной топологии:
разрыв кабеля может повлиять на работу всей сети;
ограниченная длина кабеля и количество рабочих станций;
трудно определить дефекты соединений
Топология типа “звезда”
В сети построенной по топологии типа “звезда” каждая рабочая станция подсоединяется кабелем (витой парой) к концентратору или хабу (hub). Концентратор обеспечивает параллельное соединение ПК и, таким образом, все компьютеры, подключенные к сети, могут общаться друг с другом.
Данные от передающей станции сети передаются через хаб по всем линиям связи всем ПК. Информация поступает на все рабочие станции, но принимается только теми станциями, которым она предназначается. Так как передача сигналов в топологии физическая звезда является широковещательной, т.е. сигналы от ПК распространяются одновременно во все направления, то логическая топология данной локальной сети является логической шиной. Данная топология применяется в локальных сетях с архитектурой 10Base-T Ethernet.
Преимущества сетей топологии звезда:
легко подключить новый ПК;
имеется возможность централизованного управления;
сеть устойчива к неисправностям отдельных ПК и к разрывам соединения отдельных ПК.
Недостатки сетей топологии звезда:
отказ хаба влияет на работу всей сети;
большой расход кабеля;
Топология “кольцо”
В сети с топологией кольцо все узлы соединены каналами связи в неразрывное кольцо (необязательно окружность), по которому передаются данные. Выход одного ПК соединяется со входом другого ПК. Начав движение из одной точки, данные, в конечном счете, попадают на его начало. Данные в кольце всегда движутся в одном и том же направлении.
Принимающая рабочая станция распознает и получает только адресованное ей сообщение. В сети с топологией типа физическое кольцо используется маркерный доступ, который предоставляет станции право на использование кольца в определенном порядке. Логическая топология данной сети - логическое кольцо.
Данную сеть очень легко создавать и настраивать. К основному недостатку сетей топологии кольцо является то, что повреждение линии связи в одном месте или отказ ПК приводит к неработоспособности всей сети.
Как правило, в чистом виде топология “кольцо” не применяется из-за своей ненадёжности, поэтому на практике применяются различные модификации кольцевой топологии.
Топология
Token Ring - Эта топология основана на
топологии "физическое кольцо с
подключением типа звезда". В данной
топологии все рабочие станции подключаются
к центральному концентратору (Token Ring)
как в топологии физическая звезда.
Центральный концентратор - это
интеллектуальное устройство, которое
с помощью перемычек обеспечивает
последовательное соединение выхода
одной станции со входом другой станции.
Другими словами с помощью концентратора
каждая станция соединяется только с
двумя другими станциями (предыдущей и
последующей станциями). Таким образом,
рабочие станции связаны петлей кабеля,
по которой пакеты данных передаются от
одной станции к другой и каждая станция
ретранслирует эти посланные пакеты. В
каждой рабочей станции имеется для
этого приемо-передающее устройство,
которое позволяет управлять прохождением
данных в сети. Физически такая сеть
построена по типу топологии “звезда”.
Концентратор создаёт первичное (основное)
и резервное кольца. Если в основном
кольце произойдёт обрыв, то его можно
обойти, воспользовавшись резервным
кольцом, так как используется четырёхжильный
кабель. Отказ станции или обрыв линии
связи рабочей станции не вличет за собой
отказ сети как в топологии кольцо, потому
что концентратор отключет неисправную
станцию и замкнет кольцо передачи
данных. 
В архитектуре Token Ring маркер передаётся от узла к узлу по логическому кольцу, созданному центральным концентратором. Такая маркерная передача осуществляется в фиксированном направлении (направление движения маркера и пакетов данных представлено на рисунке стрелками синего цвета). Станция, обладающая маркером, может отправить данные другой станции. Для передачи данных рабочие станции должны сначала дождаться прихода свободного маркера. В маркере содержится адрес станции, пославшей этот маркер, а также адрес той станции, которой он предназначается. После этого отправитель передает маркер следующей в сети станции для того, чтобы и та могла отправить свои данные. Один из узлов сети (обычно для этого используется файл-сервер) создаёт маркер, который отправляется в кольцо сети. Такой узел выступает в качестве активного монитора, который следит за тем, чтобы маркер не был утерян или разрушен. Преимущества сетей топологии Token Ring:
топология обеспечивает равный доступ ко всем рабочим станциям;
высокая надежность, так как сеть устойчива к неисправностям отдельных станций и к разрывам соединения отдельных станций. Недостатки сетей топологии Token Ring: большой расход кабеля и соответственно дорогостоящая разводка линий связи.
Аппаратура локальных сетей
Аппаратура локальных сетей обеспечивает реальную связь между абонентами. Выбор аппаратуры имеет важнейшее значение на этапе проектирования сети, так как стоимость аппаратуры составляет наиболее существенную часть от стоимости сети в целом, а замена аппаратуры связана не только с дополнительными расходами, но зачастую и с трудоемкими работами. К аппаратуре локальных сетей относятся: кабели для передачи информации; разъемы для присоединения кабелей; согласующие терминаторы; сетевые адаптеры; репитеры; трансиверы; концентраторы; мосты; маршрутизаторы; шлюзы и т.д.
Эталонная модель OSI
При связи компьютеров по сети производится множество операций, обеспечивающих передачу данных от компьютера к компьютеру. Пользователю, работающему с каким-то приложением, в общем-то безразлично, что и как при этом происходит. Для него просто существует доступ к другому приложению или компьютерному ресурсу, расположенному на другом компьютере сети. В действительности же вся передаваемая информация проходит много этапов обработки. Прежде всего она разбивается на блоки, каждый из которых снабжается управляющей информацией. Полученные блоки оформляются в виде сетевых пакетов, эти пакеты кодируются, передаются с помощью электрических или световых сигналов по сети в соответствии с выбранным методом доступа, затем из принятых пакетов вновь восстанавливаются заключенные в них блоки данных, блоки соединяются в данные, которые и становятся доступны другому приложению. Это, конечно, очень упрощенное описание происходящих процессов. Часть из указанных процедур реализуется только программно, другая - аппаратно, а какие-то операции могут выполняться как программами, так и аппаратурой. Упорядочить все выполняемые процедуры, разделить их на уровни и подуровни, взаимодействующие между собой, как раз и призваны модели сетей. Эти модели позволяют правильно организовать взаимодействие как абонентам внутри одной сети, так и самым разным сетям на различных уровнях. Наибольшее распространение получила в настоящее время так называемая эталонная модель обмена информацией открытой системы OSI (Open System Interchange). Под термином «открытая система» в данном случае понимается незамкнутая в себе система, имеющая возможность взаимодействия с какими-то другими системами (в отличие от закрытой системы).
Модель OSI была предложена Международной организацией стандартов ISO (International Standards Organization) в 1984 году. С тех пор ее используют (более или менее строго) все производители сетевых продуктов. Как и любая универсальная модель, модель OSI довольно громоздка, избыточна и не слишком гибка, поэтому реальные сетевые средства, предлагаемые различными фирмами, не обязательно придерживаются принятого разделения функций. Однако знакомство с моделью OSI позволяет лучше понять, что же происходит в сети.

Рис. 4.1. Семь уровней модели OSI
Все сетевые функции в модели разделены на 7 уровней (рис. 4.1). При этом вышестоящие уровни выполняют более сложные, глобальные задачи, для чего используют в своих целях нижестоящие уровни, а также управляют ими. Цель нижестоящего уровня — предоставление услуг вышестоящему уровню, причем вышестоящему уровню не важны детали выполнения этих услуг. Нижестоящие уровни выполняют более простые, более конкретные функции. В идеале каждый уровень взаимодействует только с теми, которые находятся рядом с ним (выше него и ниже него). Верхний уровень соответствует прикладной задаче, работающему в данный момент приложению, нижний - непосредственной передаче сигналов по каналу связи.
Функции, входящие в показанные на рис 4.1 уровни, реализуются каждым абонентом сети. При этом каждый уровень на одном абоненте работает так, как будто он имеет прямую связь с соответствующим уровнем другого абонента, то есть между одноименными уровнями абонентов сети существует виртуальная связь. Реальную же связь абоненты одной сети имеют только на самом нижнем, первом, физическом уровне. В передающем абоненте информация проходит все уровни, начиная с верхнего и заканчивая нижним. В принимающем абоненте полученная информация совершает обратный путь: от нижнего уровня к верхнему (рис. 4.2).
Р ис.
4.2. Путь информации от абонента к абоненту
Рассмотрим подробнее функции разных
уровней.
ис.
4.2. Путь информации от абонента к абоненту
Рассмотрим подробнее функции разных
уровней.
Прикладной уровень (Application), или уровень приложений, обеспечивает услуги, непосредственно поддерживающие приложения пользователя, например программные средства передачи файлов, доступа к базам данных, средства электронной почты, службу регистрации на сервере. Этот уровень управляет остальными шестью уровнями.
Представительский уровень (Presentation), или уровень представления данных, определяет и преобразует форматы данных и их синтаксис в форму, удобную для сети, то есть выполняет функцию переводчика. Здесь же выполняется шифрование и дешифрирование данных, а при необходимости - их сжатие.
Сеансовый уровень (Session) управляет проведением сеансов связи (то есть устанавливает, поддерживает и прекращает связь). Этот же уровень распознает логические имена абонентов, контролирует предоставленные им права доступа.
Транспортный уровень (Transport) обеспечивает доставку пакетов без ошибок и потерь, в нужной последовательности. Здесь же производится разбивка передаваемых данных на блоки, помещаемые в пакеты, и восстановление принимаемых данных.
Сетевой уровень (Network) отвечает за адресацию пакетов и перевод логических имен в физические сетевые адреса (и обратно), а также за выбор маршрута, по которому пакет доставляется по назначению (если в сети имеется несколько маршрутов).
Канальный уровень, или уровень управления линией передачи (Data link), отвечает за формирование пакетов стандартного вида, включающих начальное и конечное управляющие поля. Здесь же производится управление доступом к сети, обнаруживаются ошибки передачи" и производится повторная пересылка приемнику ошибочных пакетов.
Физический уровень (Physical) - это самый нижний уровень модели, который отвечает за кодирование передаваемой информации в уровни сигналов, принятые в среде передачи, и обратное декодирование. Здесь же определяются требования к соединителям, разъемам, электрическому согласованию, заземлению, защите от помех и т.д.
Большинство функций двух нижних уровней модели (1 и 2) обычно реализуются аппаратно (часть функций уровня 2 - программным драйвером сетевого адаптера). Именно на этих уровнях определяется скорость передачи и топология сети, метод управления обменом и формат пакета, то есть то, что имеет непосредственное отношение к типу сети (Ethernet, Token-Ring, FDDI). Более высокие уровни не работают напрямую с конкретной аппаратурой, хотя уровни 3,4 и 5 еще могут учитывать ее особенности. Уровни 6 и 7 вообще не имеют к аппаратуре никакого отношения. Замены аппаратуры сети на другую они просто не заметят.
В уровне 2 (канальном) нередко выделяют два подуровня.
Верхний подуровень (LLC - Logical Link Control) осуществляет управление логической связью, то есть устанавливает виртуальный канал связи (часть его функций выполняется программой драйвера сетевого адаптера).
Нижний подуровень (MAC - Media Access Control) осуществляет непосредственный доступ к среде передачи информации (каналу связи). Он напрямую связан с аппаратурой сети.
Назначение протоколов
Протоколы (protocols) — это набор правил и процедур, регулирующих порядок осуществления некоторой связи. Например, дипломаты какой-либо страны четко придерживаются протокола при общении с дипломатами других стран. В компьютерной среде правила связи служат тем же целям. Протоколы — это правила и технические процедуры, позволяющие нескольким компьютерам при объединении в сеть общаться друг с другом. Запомните три основных момента, касающихся протоколов.
Существует множество протоколов. И хотя все они участвуют в реализации связи, каждый протокол имеет различные цели, выполняет различные задачи, обладает своими преимуществами и ограничениями.
Протоколы работают на разных уровнях модели OSI. Функции протокола определяются уровнем, на котором он работает. Если, например, какой-то протокол работает на Физическом уровне, то это означает, что он обеспечивает прохождение пакетов через плату сетевого адаптера и их поступление в сетевой кабель.
Несколько протоколов могут работать совместно. Это так называемый стек, или набор, протоколов. Как сетевые функции распределены по всем уровням модели OSI, так и протоколы совместно работают на различных уровнях стека протоколов. Уровни в стеке протоколов соответствуют уровням модели OSI. В совокупности протоколы дают полную характеристику функциям и возможностям стека.
Работа протоколов
Передача данных по сети, с технической точки зрения, должна быть разбита на ряд последовательных шагов, каждому из которых соответствуют свои правила и процедуры, или протокол. Таким образом, сохраняется строгая очередность в выполнении определенных действий.
Кроме того, эти действия (шаги) должны быть выполнены в одной и той же последовательности на каждом сетевом компьютере. На компьютере-отправителе эти действия выполняются в направлении сверху вниз, а на компьютере-получателе -снизу вверх.
Компьютер - отправитель
Компьютер-отправитель в соответствии с протоколом выполняет следующие действия:
разбивает данные на небольшие блоки, называемые пакетами, с которыми может работать протокол;
добавляет к пакетам адресную информацию, чтобы компьютер-получатель мог определить, что эти данные предназначены именно ему;
подготавливает данные к передаче через плату сетевого адаптера и далее — по сетевому кабелю.
Компьютер - получатель
Компьютер-получатель в соответствии с протоколом выполняет те же действия, но только в обратном порядке:
принимает пакеты данных из сетевого кабеля;
через плату сетевого адаптера передает пакеты в компьютер;
удаляет из пакета всю служебную информацию, добавленную компьютером-отправителем;
копирует данные из пакетов в буфер — для их объединения в исходный блок данных;
передает приложению этот блок данных в том формате, который оно использует.
И компьютеру-отправителю, и компьютеру-получателю необходимо выполнять каждое действие одинаковым способом, с тем чтобы пришедшие по сети данные совпадали с отправленными.
Если, например, два протокола будут по-разному разбивать данные на пакеты и добавлять информацию (о последовательности пакетов, синхронизации и для проверки ошибок), тогда компьютер, использующий один из этих протоколов, не сможет успешно связаться с компьютером, на котором работает другой протокол.
Маршрутизируемые и немаршрутизируемые протоколы
До середины 80-х годов большинство локальных сетей были изолированными. Они обслуживали один отдел или одну компанию и редко объединялись в крупные системы. Однако, когда локальные сети достигли высокого уровня развития и объем передаваемой ими коммерческой информации возрос, ЛВС стали компонентами больших сетей.
Данные, передаваемые из одной локальной сети в другую по одному из возможных маршрутов, называются маршрутизированными. Протоколы, которые поддерживают передачу данных между сетями по нескольким маршрутам, называются маршрутизируемыми (routable) протоколами. Так как маршрутизируемые протоколы могут использоваться для объединения нескольких локальных сетей в глобальную сеть, их роль постоянно возрастает.
Протоколы в многоуровневой архитектуре
Несколько протоколов, которые работают в сети одновременно, обеспечивают следующие операции с данными:
подготовку;
передачу;
прием;
последующие действия.
Работа различных протоколов должна быть скоординирована так, чтобы исключить конфликты или незаконченные операции. Этого можно достичь с помощью разбиения на уровни.
Стеки протоколов
Стек протоколов (protocol stack) — это комбинация протоколов. Каждый уровень определяет различные протоколы для управления функциями связи или ее подсистемами. Каждому уровню присущ свой набор правил.
|
Так же как и уровни в модели OSI, нижние уровни стека описывают правила взаимодействия оборудования, изготовленного разными производителями. А верхние уровни описывают правила для проведения сеансов связи и интерпретации приложений. Чем выше уровень, тем сложнее становятся решаемые им задачи и связанные с этими задачами протоколы.
Привязка
Процесс, который называется привязка, позволяет с достаточной гибкостью настраивать сеть, т.е. сочетать протоколы и платы сетевых адаптеров, как того требует ситуация. Например, два стека протоколов, IPX/SPX и TCP/IP, могут быть привязаны к одной плате сетевого адаптера. Если на компьютере более одной платы сетевого адаптера, то стек протоколов может быть привязан как к одной, так и к нескольким платам сетевого адаптера.
Порядок привязки определяет очередность, с которой операционная система выполняет протоколы. Если с одной платой сетевого адаптера связано несколько протоколов, то порядок привязки определяет очередность, с которой будут использоваться протоколы при попытках установить соединение. Обычно привязку выполняют при установке операционной системы или протокола. Например, если TCP/IP — первый протокол в списке привязки, то именно он будет использоваться при попытке установить связь. Если попытка неудачна, компьютер попытается установить соединение, используя следующий по порядку протокол в списке привязки.
Привязка (binding) не ограничивается установкой соответствия стека протоколов плате сетевого адаптера. Стек протоколов должен быть привязан (или ассоциирован) к компонентам, уровни которых и выше, и ниже его уровня. Так, TCP/IP наверху может быть привязан к Сеансовому уровню NetBIOS, а внизу — к драйверу платы сетевого адаптера. Драйвер, в свою очередь, привязан к плате сетевого адаптера.
Стандартные стеки
В компьютерной промышленности в качестве стандартных моделей протоколов разработано несколько стеков. Вот наиболее важные из них:
набор протоколов ISO/OSI;
IBM System Network Architecture (SNA);
Digital DECnet™;
Novell NetWare;
Apple AppleTalk®;
набор протоколов Интернета, TCP/IP.
Протоколы этих стеков выполняют работу, специфичную для своего уровня. Однако коммуникационные задачи, которые возложены на сеть, приводят к разделению протоколов на три типа:
прикладной;
транспортный;
сетевой.
|
Прикладной |
Добавление информации о трафике с указанием момента отправки пакета |
|
Представительский | |
|
Сеансовый | |
|
Транспортный |
Добавление информации для обработки ошибок |
|
Сетевой |
Передача пакета как потока битов |
|
Канальный | |
|
Физический |
Прикладные протоколы
Прикладные протоколы работают на верхнем уровне модели OSI. Они обеспечивают взаимодействие ирулож^лмй vi обмен данными между ними. К наиболее популярным прикладным протоколам относятся:
APPC(Advanced Program-to-Program Communication) — одноранговый SNA-протокол фирмы IBM, используемый в основном на AS/400®;
FTAM (File Transfer Access and Management) — протокол OSI доступа к файлам;
Х.400 — протокол CCITT для международного обмена электронной почтой;
Х.500 — протокол CCITT служб файлов и каталогов на нескольких системах;
SMTP (Simple Mail Transfer Protocol) — протокол Интернета для обмена электронной почтой;
FTP (File Transfer Protocol) — протокол Интернета для передачи файлов;
SNMP (Simple Network Management Protocol) — протокол Интернета для мониторинга сети и сетевых компонентов;
Telnet — протокол Интернета для регистрации на удаленных хостах и обработки данных на них;
Microsoft SMBs (Server Message Blocks, блоки сообщений сервера) и клиентские оболочки или редиректоры;
NCP (Novell NetWare Core Protocol) и клиентские оболочки или редиректоры фирмы Novell;
Apple Talk и Apple Share® — набор сетевых протоколов фирмы Apple;
AFP (AppleTalk Filling Protocol) — протокол удаленного доступа к файлам фирмы Apple;
DAP (Data Access Protocol) — протокол доступа к файлам сетей DECnet.
Транспортные протоколы
Транспортные протоколы поддерживают сеансы связи между компьютерами и гарантируют надежный обмен данных между ними. К популярным транспортным протоколам относятся:
TCP (Transmission Control Protocol) — TCP/IР-протокол для гарантированной доставки данных, разбитых на последовательность фрагментов;
SPX— часть набора протоколов IPX/SPX (Internetwork Packet Exchange/Sequential Packet Exchange) для данных, разбитых на последовательность фрагментов, фирмы Novell; NWLink — реализация протокола IPX/SPX от фирмы Microsoft;
NetBEUI [NetBIOS (Network Basic Input/Output System) Extended User Interface — расширенный интерфейс пользователя] — устанавливает сеансы связи между компьютерами (NetBIOS) и предоставляет верхним уровням транспортные услуги (NetBEUI);
ATP (AppleTalk Transaction Protocol), NBP (Name Binding Protocol) — протоколы сеансов связи и транспортировки данных фирмы Apple.
Сетевые протоколы
Сетевые протоколы обеспечивают услуги связи. Эти протоколы управляют несколькими типами данных: адресацией, маршрутизацией, проверкой ошибок и запросами на повторную передачу. Сетевые протоколы, кроме того, определяют правила для осуществления связи в конкретных сетевых средах, например Ethernet или Token Ring. К наиболее популярным сетевым протоколам относятся:
IP (Internet Protocol) — TCP/IР-протокол для передачи пакетов;
IPX (Internetwork Packet Exchange) — протокол фирмы NetWare для передачи и маршрутизации пакетов;
NWLink — реализация протокола IPX/SPX фирмой Microsoft;
NetBEUI — транспортный протокол, обеспечивающий услуги транспортировки данных для сеансов и приложений NetBIOS;
DDP (Datagram Delivery Protocol) — AppleTalk-протокол транспортировки данных.
Стандарты протоколов
Модель OSI помогает определить, какие протоколы нужно использовать на каждом уровне. Продукты от разных производителей, которые соответствуют этой модели, могут вполне корректно взаимодействовать друг с другом.
ISO, IEEE, ANSI (American National Standards Institute), CCITT (Comite Consultatif Internationale de Telegraphie et Telephonie), сейчас называемый ITU (International Telecommunications Union), и другие организации по стандартизации разработали протоколы, соответствующие некоторым уровням модели OSI.
IEEE-протоколы Физического уровня:
802.3 (Ethernet). Это сеть «логическая шина», скорость передачи данных — 10 Мбит/с. Данные передаются по кабелю каждому компьютеру, но принимают их только те, кому они адресованы. Протокол CSMA/CD регулирует трафик сети, разрешая передачу только тогда, когда кабель не занят и другой компьютер не передает информацию.
802.4 (передача маркера). Это сеть топологии «шина», использующая схему передачи маркера. Каждый компьютер принимает данные, но реагируют на них только те, кому они адресованы. Маркер, передаваемый от компьютера к компьютеру, определяет тот компьютер, которому разрешена передача.
802.5 (Token Ring). Это сеть «логическое кольцо», скорость передачи данных — 4 или 16 Мбит/с. Хотя эта сеть и называется кольцом, выглядит она как звезда, поскольку все сетевые компьютеры подключены к концентратору (MAU). Впрочем, кольцо реализуется внутри концентратора. Маркер, передаваемый по кольцу, определяет тот компьютер, которому разрешена передача.
IEEE-протоколы Канального уровня поддерживают связь на подуровне Управления доступом к среде.
Прикладной уровень
Представительский уровень
Сеансовый уровень
Транспортный уровень
Сетевой уровень
Канальный уровень
Управление логической связью (LLC)
Управление доступом к среде (MAC)
Физический уровень
Драйвер управления доступом к среде — это драйвер устройства, расположенный на подуровне Управления доступом к среде. Этот драйвер называют также драйвером платы сетевого адаптера. Он предоставляет низкоуровневый доступ к сетевым адаптерам, обеспечивая поддержку передачи данных и некоторые основные функции по управлению адаптером.
Протокол управления доступом к среде определяет, какой именно компьютер может использовать сетевой кабель, если несколько компьютеров одновременно пытаются получить к нему доступ. CSMA/CD, протокол 802.3, разрешает компьютеру начинать передачу лишь тогда, когда на данный момент нет других передающих компьютеров. Если два компьютера начинают передачу одновременно, происходит своего рода столкновение — коллизия (collision). Протокол обнаруживает коллизию и запрещает передачу до тех пор, пока кабель не освободится. Затем, через случайный интервал времени, каждый компьютер вновь пытается начать передачу.
Распространенные протоколы
Среди множества протоколов наиболее популярны следующие:
TCP/IP; NetBEUI; Х.25;
Xerox Network System (XNS™);
IPX/SPXHNWLink;
APPC;
AplleTalk;
набор протоколов OSI;
DECnet.
TCP/IP
Transmission Control Protocol/Internet Protocol (TCP/IP) — промышленный стандартный набор протоколов, которые обеспечивают связь в гетерогенной (неоднородной) среде, т.е. обеспечивают совместимость между компьютерами разных типов. Совместимость — одно из основных преимуществ TCP/IP, поэтому большинство ЛВС поддерживает его. Кроме того, TCP/IP предоставляет доступ к ресурсам Интернета, а также маршрутизируемый протокол для сетей масштаба предприятия. Поскольку TCP/IP поддерживает маршрутизацию, он обычно используется в качестве межсетевого протокола. Благодаря своей популярности TCP/IP стал стандартом де-факто для межсетевого взаимодействия. К другим специально созданным для набора TCP/IP протоколам относятся:
SMTP (Simple Mail Transfer Protocol) — электронная почта;
FTP (File Transfer Protocol) — обмен файлами между компьютерами, поддерживающими TCP/IP;
SNMP (Simple Network Management Protocol) — управление сетью.
TCP/IP имеет два главных недостатка: размер и недостаточная скорость работы. TCP/IP — относительно большой стек протоколов, который может вызвать проблемы у MS-DOS-клиентов. Однако для таких операционных систем, как Windows NT или Windows 95, размер не является проблемой, а скорость работы сравнима со скоростью протокола IPX.
NetBEUI
NetBEUI — расширенный интерфейс NetBIOS. Первоначально NetBIOS и NetBEUI были тесно связаны и рассматривались как один протокол. Затем некоторые производители ЛВС так обособили NetBIOS, протокол Сеансового уровня, что он уже не мог использоваться наряду с другими маршрутизируемыми транспортными протоколами. NetBIOS (Network Basic Input/Output System — сетевая базовая система ввода/вывода) -это IBM-интерфейс Сеансового уровня с ЛВС, который выступает в качестве прикладного интерфейса с сетью. Этот протокол предоставляет программам средства для осуществления сеансов связи с другими сетевыми программами. Он очень популярен, так как поддерживается многими приложениями.
NetBEUI — небольшой, быстрый и эффективный протокол Транспортного уровня, который поставляется со всеми сетевыми продуктами фирмы Microsoft. Он появился в середине 80-х годов в первом сетевом продукте Microsoft — MS®-NET.
К преимуществам NetBEUI относятся небольшой размер стека (важно для MS-DOS-компьютеров), высокая скорость передачи данных по сети и совместимость со всеми сетями Microsoft. Основной недостаток NetBEUI — он не поддерживает маршрутизацию. Это ограничение относится ко всем сетям Microsoft.
Х.25
Х.25 — набор протоколов для сетей с коммутацией пакетов. Его использовали службы коммутации, которые должны были соединять удаленные терминалы с мэйнфреймами.
XNS
Xerox Network System (XNS) был разработан фирмой Xerox для своих сетей Ethernet. Его широкое использование началось с 80-х годов, но постепенно он был вытеснен протоколом TCP/IP. XNS — большой и медленный протокол, к тому же он применяет значительное количество широковещательных сообщений, что увеличивает трафик сети. IPX/SPX и NWLink
Internetwork Packet Exchange/Sequenced Packet Exchange (IPX/SPX) — стек протоколов, используемый в сетях Novell. Как и NetBEUI, относительно небольшой и быстрый протокол. Но, в отличие от NetBEUI, он поддерживает маршрутизацию. IPX/SPX -«наследник» XNS. NWLink — реализация IPX/SPX фирмой Microsoft. Это транспортный маршрутизируемый протокол.
АРРС
АРРС (Advanced Program-to-Program Communication) — транспортный протокол фирмы IBM, часть Systems Network Architecture (SNA). Он позволяет приложениям, работающим на разных компьютерах, непосредственно взаимодействовать и обмениваться данными.
AppleTalk
AppleTalk — собственный стек протоколов фирмы Apple Computer, позволяющий компьютерам Apple Macintosh совместно использовать файлы и принтеры в сетевой среде.
Набор протоколов OSI
Набор протоколов OSI — полный стек протоколов, где каждый протокол соответствует конкретному уровню модели OSI. Набор содержит маршрутизируемые и транспортные протоколы, серии протоколов IEEE Project 802, протокол Сеансового уровня, Представительского уровня и несколько протоколов Прикладного уровня. Они обеспечивают полнофункциональность сети, включая доступ к файлам, печать и эмуляцию терминала.
DECnet
DECnet — собственный стек протоколов фирмы Digital Equipment Corporation. Этот набор аппаратных и программных продуктов реализует архитектуру Digital Network Architecture (DNA). Указанная архитектура определяет сети на базе локальных вычислительных сетей Ethernet, сетей FDDI MAN (Fiber Distributed Data Interface Metropolitan Area Network) и глобальных вычислительных сетей, которые используют средства передачи конфиденциальных и общедоступных данных. DECnet может использовать как протоколы TCP/IP и OSI, так и свои собственные. Данный протокол принадлежит к числу маршрутизируемых.
2. Встроенные средства контроля доступа в современных ОС.
Операцио́нная систе́ма, ОС (англ.operating system) — базовый комплекскомпьютерных программ, обеспечивающий интерфейс с пользователем, управление аппаратными средствамикомпьютера, работу сфайлами, ввод и вывод данных, а также выполнениеприкладных программиутилит. ОС позволяет абстрагироваться от деталей реализации аппаратного обеспечения, предоставляя разработчикам программного обеспечения минимально необходимый набор функций. С точки зрения обычных пользователей компьютерной техники ОС включает в себя и программы пользовательского интерфейса.
Одна из функций - Разграничение прав доступа и многопользовательский режим работы (файловая система, аутентификация,авторизация).
Аутентификация - процедура проверки подлинности данных и субъектов информационного взаимодействия исключительно на основе внутренней структура самих данных.
АВТОРИЗАЦИЯ - 1. Элемент информационной безопасности, предусматривающий идентификацию заявителя в форме запроса и последующего подтверждения законности операции.
Фа́йловая систе́ма (англ.file system) — регламент, определяющий способ организации, хранения и именования данных наносителях информации. Она определяетформатфизического хранения информации, которую принято группировать в видефайлов. Конкретная файловая система определяет размер имени файла (папки), максимальный возможный размер файла и раздела, набор атрибутов файла. Некоторые файловые системы предоставляют сервисные возможности, например,разграничение доступаилишифрованиефайлов
3. Указать к какому классу относится каждый из перечисленных IP адресов:
192.168.0.15
127.0.0.1
112.0.0.15
167.58.13.21
Определить к какому классу относится каждый IP-адрес
Старший октет адреса представляем в двоичном коде: если старший бит = 0 (класс А), = 10 (класс B), = 11 (класс С)
192.168.0.15
|
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
|
128 |
64 |
32 |
16 |
8 |
4 |
2 |
1 |
Ответ: Класс С
127.0.0.1
|
0 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
|
128 |
64 |
32 |
16 |
8 |
4 |
2 |
1 |
Ответ: Класс А
112.0.0.15
|
0 |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
|
128 |
64 |
32 |
16 |
8 |
4 |
2 |
1 |
Ответ: Класс А
167.58.13.21
|
1 |
0 |
1 |
0 |
0 |
1 |
1 |
1 |
|
128 |
64 |
32 |
16 |
8 |
4 |
2 |
1 |
Ответ: Класс В
Билет 8
1.Трансляторы, компиляторы и интерпретаторы: определение, общая схема работы. Варианты взаимодействия блоков транслятора.
Транслятор - обслуживающая программа, преобразующая исходную программу, предоставленную на входном языке программирования, в рабочую программу, представленную на объектном языке.
Приведенное определение относится ко всем разновидностям транслирующих программ. Однако у каждой из таких программ могут иметься свои особенности по организации процесса трансляции. В настоящее время трансляторы разделяются на три основные группы: ассемблеры, компиляторы и интерпретаторы.
Ассемблер - системная обслуживающая программа, которая преобразует символические конструкции в команды машинного языка. Специфической чертой ассемблеров является то, что они осуществляют дословную трансляцию одной символической команды в одну машинную. Таким образом, язык ассемблера (еще называется автокодом) предназначен для облегчения восприятия системы команд компьютера и ускорения программирования в этой системе команд. Программисту гораздо легче запомнить мнемоническое обозначение машинных команд, чем их двоичный код. Поэтому, основной выигрыш достигается не за счет увеличения мощности отдельных команд, а за счет повышения эффективности их восприятия.Вместе с тем, язык ассемблера, кроме аналогов машинных команд, содержит множество дополнительных директив, облегчающих, в частности, управление ресурсами компьютера, написание повторяющихся фрагментов, построение многомодульных программ. Поэтому выразительность языка намного богаче, чем просто языка символического кодирования, что значительно повышает эффективность программирования.
Компилятор - это обслуживающая программа, выполняющая трансляцию на машинный язык программы, записанной на исходном языке программирования. Также как и ассемблер, компилятор обеспечивает преобразование программы с одного языка на другой (чаще всего, в язык конкретного компьютера). Вместе с тем, команды исходного языка значительно отличаются по организации и мощности от команд машинного языка. Существуют языки, в которых одна команда исходного языка транслируется в 7-10 машинных команд. Однако есть и такие языки, в которых каждой команде может соответствовать 100 и более машинных команд (например, Пролог). Кроме того, в исходных языках достаточно часто используется строгая типизация данных, осуществляемая через их предварительное описание. Программирование может опираться не на кодирование алгоритма, а на тщательное обдумывание структур данных или классов. Процесс трансляции с таких языков обычно называется компиляцией, а исходные языки обычно относятся к языкам программирования высокого уровня (или высокоуровневым языкам). Абстрагирование языка программирования от системы команд компьютера привело к независимому созданию самых разнообразных языков, ориентированных на решение конкретных задач. Появились языки для научных расчетов, экономических расчетов, доступа к базам данных и другие
Интерпретатор - программа или устройство, осуществляющее пооператорную трансляцию и выполнение исходной программы. В отличие от компилятора, интерпретатор не порождает на выходе программу на машинном языке. Распознав команду исходного языка, он тут же выполняет ее. Как в компиляторах, так и в интерпретаторах используются одинаковые методы анализа исходного текста программы. Но интерпретатор позволяет начать обработку данных после написания даже одной команды. Это делает процесс разработки и отладки программ более гибким. Кроме того, отсутствие выходного машинного кода позволяет не "захламлять" внешние устройства дополнительными файлами, а сам интерпретатор можно достаточно легко адаптировать к любым машинным архитектурам, разработав его только один раз на широко распространенном языке программирования. Поэтому, интерпретируемые языки, типа Java Script, VB Script, получили широкое распространение. Недостатком интерпретаторов является низкая скорость выполнения программ. Обычно интерпретируемые программы выполняются в 50-100 раз медленнее программ, написанных в машинных кодах.
Трансля́тор — программа, которая принимает на вход программу на одном языке (он в этом случае называется исходный язык, а программа — исходный код), и преобразует её в программу, написанную на другом языке (соответственно, целевой язык и объектный код).
Наиболее часто встречаются две разновидности трансляторов:
Компиляторы — выдают результат в виде исполняемого файла (в данном случае считаем, что компоновка входит в компиляцию). Этот файл:
транслируется один раз — может быть запущен самостоятельно
не требует для работы наличия на машине создавшего его транслятора
Интерпретаторы — исполняют программу после разбора (в этом случае в роли объектного кода выступает внутреннее представление программы интерпретатором). Исполняется она построчно. В данном случае программа
транслируется (интерпретируется) при каждом запуске (если объектный код кешируется, возможны варианты)
требует для исполнения наличия на машине интерпретатора и исходного кода
Рис. 1. Функциональные блоки транслятора
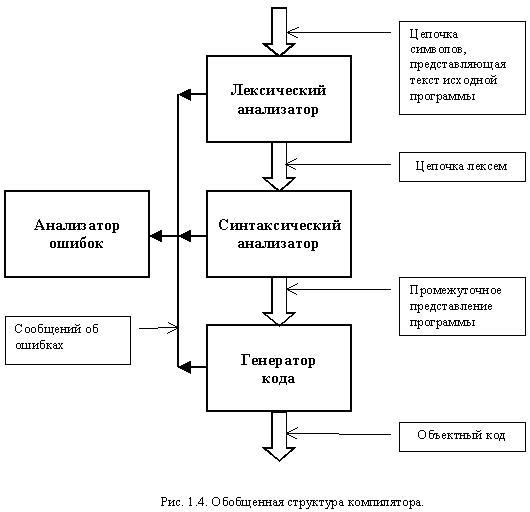
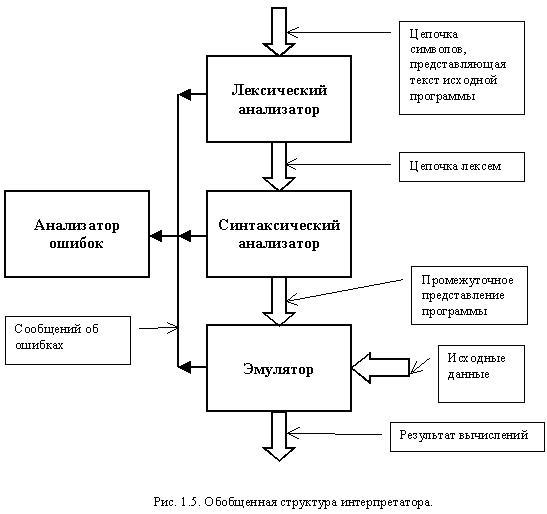
2. Эргономические требования, предъявляемые к дизайну пользовательских интерфейсов.