

Цели создания и задачи
В рамках жизненного цикла промышленных изделий САПР решает задачи автоматизации работ на стадиях проектирования и подготовки производства. Основная цель создания САПР — повышение эффективности труда инженеров, включая:
сокращения трудоёмкости проектирования и планирования;
сокращения сроков проектирования;
сокращения себестоимости проектирования и изготовления, уменьшение затрат на эксплуатацию;
повышения качества и технико-экономического уровня результатов проектирования;
сокращения затрат на натурное моделирование и испытания. Достижение этих целей обеспечивается путем:
автоматизации оформления документации;
информационной поддержки и автоматизации процесса принятия решений;
использования технологий параллельного проектирования;
унификации проектных решений и процессов проектирования;
повторного использования проектных решений, данных и наработок;
стратегического проектирования;
замены натурных испытаний и макетирования математическим моделированием;
повышения качества управления проектированием;
применения методов вариантного проектирования и оптимизации.
3. Составить программу, которая формирует очередь, добавляя в неё произвольное количество компонент.
|
uses SysUtils, Windows;
//Program Zadanie_10; //Uses Crt; Type TPtr = ^TElem; TElem = record Inf :Integer; Link:TPtr; end; Var Z,Value:Integer; Top_O, End_O:TPtr; Procedure Add_Z(Val:Integer); Var P:TPtr; Begin New(P); P^.Inf:=Val; P^.Link:=nil; if Top_O = nil Then Top_O:=P else End_O^.Link:=P; End_O:=P; End; Procedure Del_Z(var Val:Integer); Var P:TPtr; Begin Val:=Top_O^.Inf; P:=Top_O; Top_O:=P^.Link; if Top_O=nil Then End_O:=nil; Dispose(P); End; Begin //ClrScr; Writeln('Create OCHERED...'); Top_O:=nil; End_O:=nil;
|
Writeln('Ukagite deistvie:'); Writeln(' 1. Zapis v Ochered'); Writeln(' 2. Izvlechenie iz Ochered'); Writeln(' 3. Ochistka Ochered and print'); Writeln(' 4. EXIT'); Repeat Readln(Z);
If Z=1 Then Begin Writeln('Vvedite VALUE == '); Readln(Value); Add_Z(Value); End; If Z = 2 Then Begin Del_Z(Value); Writeln('Izvlechennoe VALUE == ',Value); End; If Z = 3 Then Begin While Top_O <> nil do Begin Del_Z(Value); Writeln('Izvlechennoe VALUE == ',Value); End; End; Until (Z=4); End. //begin { TODO -oUser -cConsole Main : Insert code here } //end.
|
Билет 26.
1. Сравнительный анализ алгоритмов поиска: линейный, двоичный.
Само действие поиска элемента в наборе данных требует возможности отличать элементы друг от друга. Очевидно, сравнение числовых типов не вызывает трудности. В случае сравнения строк процедура усложняется. Можно выполнять сравнение чувствительное или нечувствительное к регистру, сравнение по локальным таблицам символов, когда оно выполняется на основе алгоритмов, специфичных для определенной страны или языка и т.д. При работе с объектами вообще не существует заранее определенной схемы сравнения за исключением сравнения указателей на эти объекты.
В таком случае лучше всего рассматривать процедуру сравнения в виде «черного ящика» – функции с четко определенным интерфейсом, которая в качестве входных параметров принимает указатели на два элемента и возвращает результат сравнения – первый элемент больше, меньше или равен второму.
Линейный поиск. Единственно возможным методом поиска элемента по значению ключа, находящегося в неупорядоченном наборе данных, является последовательный (линейный) просмотр каждого элемента, который продолжается до тех пор, пока не будет найден искомый элемент. Если просмотрен весь набор, но элемент не найден, искомый ключ отсутствует. Для последовательного поиска в среднем требуется (n+1)/2 сравнений и порядок алгоритма линейный O(n).
Программная иллюстрация линейного поиска в неупорядоченном массиве приведена ниже, где aList – исходный массив, aItem – искомый ключ; функция возвращает индекс найденного элемента или -1, если элемент отсутствует.
{ Линейный поиск в неотсортированном массивом }
function LineNonSortedSearch(aList: TList;
aItem: Pointer; aCompare: TCompareFunc): Integer;
var i: Integer;
begin
Result:=-1;
for i:=0 to aList.Count-1 do
if aCompare(aList.List[i],aItem) = 0 then
begin
Result:=i;
Break;
end;
end;
Последовательный поиск для отсортированного массива ничем не отличается от приведенного и имеет линейный порядок алгоритма O(n).
Бинарный поиск. Другим относительно простым методом доступа к элементу является бинарный (двоичный или дихотомичный) поиск, который выполняется в заведомо упорядоченной последовательности элементов. Элементы массива должны располагаться в лексикографическом (символьные ключи) или численно (числовые ключи) возрастающем порядке. Для достижения упорядоченности может быть использован один из методов сортировки.
В методе сначала приближенно определяется запись в середине массива и анализируется значение ее ключа. Если оно слишком велико, то анализируется значение ключа, соответствующего записи в середине первой половины массива, и указанная процедура повторяется в этой половине до тех пор, пока не будет найдена требуемая запись. Если значение ключа слишком мало, испытывается ключ, соответствующий записи в середине второй половины массива, и процедура повторяется в этой половине.
Процесс продолжается до тех пор, пока не найден требуемый ключ или не станет пустым интервал, в котором осуществляется поиск. Чтобы найти элемент, в худшем случае требуется log2(N) сравнений, что значительно лучше, чем при последовательном поиске. Программная иллюстрация бинарного поиска в упорядоченном массиве приведена ниже.
{ Двоичный поиск }
function BinarySearch(aList: TList;
aItem: Pointer; aCompare: TCompareFunc): Integer;
var L, R, M, CompareResult: Integer;
begin
{ Значения индексов первого и последнего элементов }
L:=0; R:=aList.Count-1;
while L <= R do
begin
{ Индекс среднего элемента }
M:=(L + R) div 2;
{ Сравнить значение среднего элемента с искомым }
CompareResult:=aCompare(aList.List[M], aItem);
{ Если значение среднего элемента меньше искомого -
переместить левый индекс на позицию до среднего индекса }
if CompareResult < 0 then
L:=M+1 else
{ Если значение среднего элемента больше искомого -
переместить правый индекс на позицию после среднего индекса }
if CompareResult > 0 then
R:=M-1 else
begin
Result:=M;
Exit;
end;
end;
Result:=-1;
end;
2. Факторы, определяющие развитие архитектуры вычислительных систем.
Совершенствование архитектуры вычислительных машин и систем началось с момента появления первых ВМ и не прекращается по сей день. Каждое изменение в архитектуре направлено на абсолютное повышение производительности или, по крайней мере, на более эффективное решение задач определенного класса. Эволюцию архитектур определяют самые различные факторы, главные из которых показаны на рис. 1.7. Не умаляя роли ни одного из них, следует признать, что наиболее очевидные успехи в области средств вычислительной техники все же связаны с технологическими достижениями.
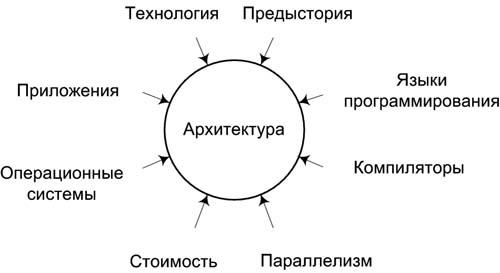 Рис.
1.7. Факторы, определяющие развитие
архитектуры вычислительных систем
Рис.
1.7. Факторы, определяющие развитие
архитектуры вычислительных систем
С каждым новым технологическим успехом многие из архитектурных идей переходят на уровень практической реализации. Очевидно, что процесс этот будет продолжаться и в дальнейшем, однако возникает вопрос: «Насколько быстро?» Косвенный ответ можно получить, проанализировав тенденции совершенствования технологий, главным образом полупроводниковых.
Основные тенденции:
Тенденции развития больших интегральных схем - Наиболее перспективным представляется увеличение размеров кристалла
Пока основные успехи в плане увеличения емкости СБИС связаны с уменьшением размеров элементарных транзисторов и плотности их размещения на кристалле
Тенденции развития элементной базы процессорных устройств - К увеличению числа логических элементов на кристалле ведут три пути: увеличение размеров кристалла; уменьшение размеров элементарных транзисторов; уменьшение ширины проводников, образующих внутренние шины или соединяющих логические элементы между собой.
Тенденции развития полупроводниковых запоминающих устройств - По мере повышения возможностей вычислительных средств растут и «аппетиты» программных приложений относительно емкости основной памяти. В целом можно предсказать, что число запоминающих элементов на кристалле будет возрастать в два раза каждые полтора года, запоминающих устройств основной памяти.
Перспективные направления исследований в области архитектуры - Основные направления исследований в области архитектуры ВМ и ВС можно условно разделить на две группы: эволюционные и революционные. К первой группе следует отнести исследования, целью которых является совершенствование методов реализации уже достаточно известных идей. Изыскания, условно названные революционными, направлены на создание совершенно новых архитектур, принципиально отличных от уже ставшей традиционной фон-неймановской архитектуры. Появление образцов с нетрадиционной архитектурой.
3. Составить программу, которая формирует очередь, добавляя в неё произвольное количество компонент.
|
uses SysUtils, Windows;
//Program Zadanie_10; //Uses Crt; Type TPtr = ^TElem; TElem = record Inf :Integer; Link:TPtr; end; Var Z,Value:Integer; Top_O, End_O:TPtr; Procedure Add_Z(Val:Integer); Var P:TPtr; Begin New(P); P^.Inf:=Val; P^.Link:=nil; if Top_O = nil Then Top_O:=P else End_O^.Link:=P; End_O:=P; End; Procedure Del_Z(var Val:Integer); Var P:TPtr; Begin Val:=Top_O^.Inf; P:=Top_O; Top_O:=P^.Link; if Top_O=nil Then End_O:=nil; Dispose(P); End; Begin //ClrScr; Writeln('Create OCHERED...'); Top_O:=nil; End_O:=nil;
|
Writeln('Ukagite deistvie:'); Writeln(' 1. Zapis v Ochered'); Writeln(' 2. Izvlechenie iz Ochered'); Writeln(' 3. Ochistka Ochered and print'); Writeln(' 4. EXIT'); Repeat Readln(Z);
If Z=1 Then Begin Writeln('Vvedite VALUE == '); Readln(Value); Add_Z(Value); End; If Z = 2 Then Begin Del_Z(Value); Writeln('Izvlechennoe VALUE == ',Value); End; If Z = 3 Then Begin While Top_O <> nil do Begin Del_Z(Value); Writeln('Izvlechennoe VALUE == ',Value); End; End; Until (Z=4); End. //begin { TODO -oUser -cConsole Main : Insert code here } //end.
|
Билет 27.
1. Рекурсивные функции. Лямбда- исчисление Черча.
Функция называется рекурсивной, если во время ее обработки возникает ее повторный вызов, либо непосредственно, либо косвенно, путем цепочки вызовов других функций.
Прямой (непосредственной) рекурсией является вызов функции внутри тела этой функции.
int a()
{.....a().....}
Косвенной рекурсией является рекурсия, осуществляющая рекурсивный вызов функции посредством цепочки вызова других функций. Все функции, входящие в цепочку, тоже считаются рекурсивными.
Например:
a(){.....b().....} b(){.....c().....} c(){.....a().....} .
Все функции a,b,c являются рекурсивными, так как при вызове одной из них, осуществляется вызов других и самой себя.
Другая известная модель вычислимости - рекурсивные функции Чёрча (лямбда-исчисление), которая является теоретическим фундаментом другой большой группы формальных языков, объединённых названием "функциональные". Согласно этой модели, алгоритм решения задачи можно представить в виде последовательности вложенных друг в друга функций. При этом пользуются математическим определением функции, определяющим функцию как некое правило, отображающее область аргументов функции в область её значений, причём значения определяются по значениям аргументов единственным образом.
Программа на языке, использующем концепцию лямбда-исчисления, выглядит как композиция конечного набора функций, каждая из которых, в свою очередь, может быть композицией ещё более элементарных функций, и т.д. При этом каждая функция может прямо или косвенно осуществлять рекурсию, т.е. вызов самой себя. Данная модель лишена недостатков машин Тьюринга, описанных выше, в силу своей структуры, изначально требующей определения функций, значения которых зависят исключительно от аргументов функции и не зависят от контекста вызова и выполнения.
Функциональное программирование представляет из себя одну из альтернатив императивному подходу. В императивном программировании алгоритмы - это описания последовательно исполняемых операций. Здесь существует понятие "текущего шага исполнения" (то есть, времени), и "текущего состояния", которое меняется с течением этого времени.
В функциональном программировании понятие времени отсутствует. Программы являются выражениями, исполнение программ заключается в вычислении этих выражений. Практически все математики, сами того не замечая, занимаются функциональным программированием, описывая, например, чему равно абсолютное значение произвольного вещественного числа.
Как правило, рассматривают так называемое "расширенное лямбда-исчисление". Его грамматику можно описать следующим образом:
Выражение ::= Простое выражение | Составное выражение
Простое выражение ::= Константа | Имя
Составное выражение ::= -абстракция | Применение | Квалифицирванное выражение | Ветвление
Лямбда-абстракция ::= lambda Имя -> Выражение end
Применение ::= ( Выражение Выражение )
Квалифицированное выражение ::= let ( Имя = Выражение ; )* in Выражение end
Ветвление ::= if Выражение then Выражение (elseif Выражение then Выражение)* else Выражение end
Константами в расширенном лямбда-исчислении могут быть числа, кортежи, списки, имена предопределенных функций, и так далее.
Результатом вычисление применения предопределенной функции к аргументам будет значение предопределенной функции в этой "точке".
Результатом применения лямбда-абстракции к аргументу будет подстановка аргумента в выражение - "тело" лямбда-абстракции. Сами лямбда-абстракции так же являются выражениями, и, следовательно, могут быть аргументами.
Чистое лямбда-исчисление Черча позволяет обходится исключительно именами, лямбда-абстракциями от одного аргумента и применениями выражений к выражениям. Оказывается, в этих терминах можно описать и "предопределенные" константы (числа и т.п.), структуры данных (списки, кортежи...), логические значения и ветвление. Более того, в чистом лямбда-исчислении можно обойтись без квалифицированных выражений, и, следовательно, выразить рекурсию, не используя для этого употребления имени функции в теле функции. Некоторые экспериментальные модели функционального программирования позволяют обходится без каких-либо имен вообще.
Функциональное программирование обладает следующими двумя примечательными свойствами:
1) Аппликативность: программа есть выражение, составленное из применения функций к аргументам. 2) Настраиваемость: так как не только программа, но и любой программный объект (в идеале) является выражением, можно легко порождать новые программные объекты по образцу, как значения соответствующих выражений (применение порождающей функции к параметрам образца).
2. Обеспечивающие системы САПР.
Система автоматизированного проектирования (САПР) – это совокупность средств и методов для осуществления автоматизированного проектирования.
В САПР вводятся следующие виды обеспечения объектов проектирования:
Техническое обеспечение представляет собой совокупность взаимосвязанных и взаимодействующих технических средств, предназначенных для выполнения автоматизированного проектирования. Техническое обеспечение делится на группы средств программной обработки данных, подготовки и ввода данных, средств отображения и документирования, архива проектных решений, средств передачи данных.
Средства программной обработки данных представлены процессорами и запоминающими устройствами, т.е. устройствами ЭВМ, в которых реализуются преобразования данных и программное управление вычислениями. Средства подготовки, ввода, отображения и документирования данных служат для общения человека с ЭВМ. Средства архива проектных решений представлены внешними запоминающими устройствами. Средства передачи данных используются для организации связей между территориально разнесенными ЭВМ и терминалами (оконечными пунктами).
Математическое обеспечение включает в себя математические модели (ММ) проектируемых объектов, методы и алгоритмы проектных процедур, используемые при автоматизированном проектировании. Элементы математического проектирования САПР чрезвычайно разнообразны. К ним относятся принципы построения функциональных моделей, методы численного решения алгебраических и дифференциальных уравнений, постановки экстремальных задач, поиска экстремума и т.д.
Программное обеспечение объединяет собственно программы для систем обработки данных на машинных носителях и программную документацию, необходимую для эксплуатации программы. Программное обеспечение (ПО) делится на общесистемное, базовое и прикладное (специальное). Общесистемное ПО предназначено для организации функционирования технических средств, т.е. для планирования и управления вычислительным процессом, распределения имеющихся ресурсов, и представлено операционными системами ЭВМ и ВС. Общесистемное ПО обычно создается для многих приложений и специфики САПР не отражает. Базовое и прикладное ПО создаются для нужд САПР. В базовое ПО входят программы, обеспечивающие правильное функционирование прикладных программ. В прикладном ПО реализуется математическое обеспечение для непосредственного выполнения проектных процедур. Прикладное ПО обычно имеет форму пакетов прикладных программ (ППП), каждый из которых обслуживает определенный этап процесса проектирования или группу однотипных задач внутри различных этапов. Программы, входящие в ПО, должны:
- обеспечивать экономичность использования ресурсов ЭВМ (памяти и времени процессора), т.е. быть эффективными;
- обладать надежностью;
- обладать структурностью и модульностью, которые заключаются в том, что сложная задача может быть разделена на более простые, каждой из которых соответствует определенный программный модуль;
- допускать модифицируемость, т.е. вносимые в программы изменения не должны ухудшать их качества;
- допускать переносимость на новые виды вычислительной техники и технологических задач;
- быть согласованными, т.е. данные, которые используются в двух и более программах, должны входить в числовые массивы, не требующие коррекций при переходе от одной программы к другой;
- быть "дружественными", т.е. удобными для пользования.
Информационное обеспечение объединяет всевозможные данные, необходимые для выполнения автоматизированного проектирования. Эти данные могут быть представлены в виде тех или иных документов на различных носителях, содержащих сведения справочного характера о материалах, комплектующих изделиях, типовых проектных решениях, параметрах элементов, сведения о состоянии текущих разработок в виде промежуточных и окончательных проектных решений, структур и параметров проектируемых объектов и т.п. Основная часть информационного обеспечения САПР − банк данных, представляющий собой совокупность средств для централизованного накопления и коллективного использования данных в САПР. Банк данных (БНД) состоит из базы данных и системы управления базой данных.
База данных (БД) − сами данные, находящиеся в запоминающих устройствах ЭВМ и структурированные в соответствии с принятыми в данной БД правилами.
Система управления базой данных (СУБД) − совокупность программных средств, обеспечивающих функционирование БД. С помощью СУБД производятся запись данных в БД, их выборка по запросам пользователей и прикладных программ, обеспечивается защита данных от искажений, несанкционированного доступа и т.п.
Лингвистическое обеспечение представлено совокупностью языков, применяемых для описания процедур автоматизированного проектирования и проектных решений. Языки, которые используются в вычислительной технике, являются алгоритмическими. Они служат для задания определенных алгоритмов переработки информации и построены посредством набора символов и системы правил соответствующего языка. В САПР применяют языки программирования и языки общения человека с ЭВМ. С помощью языков программирования составляются программы, входящие в состав общесистемного или прикладного ПО. Эти языки подразделяют на языки низкого и высокого уровней.
Методическое обеспечение составляют документы, характеризующие состав, правила выбора и эксплуатации средств автоматизированного проектирования.
Организационное обеспечение включает положения, инструкции, приказы, штатные расписания, квалификационные требования и другие документы, регламентирующие организационную структуру подразделений проектной организации и их взаимодействие с комплексом средств автоматизированного проектирования.
3. Написать программу на языке С++ для реверса списка. Например: [1,2,3] [3,2,1].
#include <iostream.h>
void main()
{
int X[10],Y[10],N,j=1,i;
cout<<"\n Vvedite N (<10) ==";
cin>>N;
for(i=1;i<=N;i++)
{
cout<<"\n X["<<i<<"] ==";
cin>>X[i];
}
for(i=N;i>0;i--)
{
Y[j]=X[i];
j++;
}
for(i=1;i<=N;i++)
{
cout<<"\n X["<<i<<"] == "<<Y[i];
}
_getch();
}
Билет 28.
1. Память. Типы адресов. Виды распределения памяти.
Память является важнейшим ресурсом, требующим тщательного управления со стороны мультипрограммной операционной системы. Распределению подлежит вся оперативная память, не занятая операционной системой. Обычно ОС располагается в самых младших адресах, однако может занимать и самые старшие адреса. Функциями ОС по управлению памятью являются: отслеживание свободной и занятой памяти, выделение памяти процессам и освобождение памяти при завершении процессов, вытеснение процессов из оперативной памяти на диск, когда размеры основной памяти не достаточны для размещения в ней всех процессов, и возвращение их в оперативную память, когда в ней освобождается место, а также настройка адресов программы на конкретную область физической памяти.
Типы адресов. Для идентификации переменных и команд используются символьные имена (метки), виртуальные адреса и физические адреса.
Символьные имена присваивает пользователь при написании программы на алгоритмическом языке или ассемблере. Виртуальные адреса вырабатывает транслятор, переводящий программу на машинный язык. Так как во время трансляции в общем случае не известно, в какое место оперативной памяти будет загружена программа, то транслятор присваивает переменным и командам виртуальные (условные) адреса, обычно считая по умолчанию, что программа будет размещена, начиная с нулевого адреса. Физические адреса соответствуют номерам ячеек оперативной памяти, где в действительности расположены или будут расположены переменные и команды. Переход от виртуальных адресов к физическим может осуществляться двумя способами. В первом случае замену виртуальных адресов на физические делает специальная системная программа - перемещающий загрузчик. Перемещающий загрузчик на основании имеющихся у него исходных данных о начальном адресе физической памяти, в которую предстоит загружать программу, и информации, предоставленной транслятором об адресно-зависимых константах программы, выполняет загрузку программы, совмещая ее с заменой виртуальных адресов физическими.
Второй способ заключается в том, что программа загружается в память в неизмененном виде в виртуальных адресах, при этом операционная система фиксирует смещение действительного расположения программного кода относительно виртуального адресного пространства. Во время выполнения программы при каждом обращении к оперативной памяти выполняется преобразование виртуального адреса в физический. Второй способ является более гибким, он допускает перемещение программы во время ее выполнения, в то время как перемещающий загрузчик жестко привязывает программу к первоначально выделенному ей участку памяти. Вместе с тем использование перемещающего загрузчика уменьшает накладные расходы, так как преобразование каждого виртуального адреса происходит только один раз во время загрузки, а во втором случае - каждый раз при обращении по данному адресу.
В некоторых случаях (обычно в специализированных системах), когда заранее точно известно, в какой области оперативной памяти будет выполняться программа, транслятор выдает исполняемый код сразу в физических адресах.
Все методы управления памятью могут быть разделены на два класса: методы, которые используют перемещение процессов между оперативной памятью и диском, и методы, которые не делают этого.
Методы распределения памяти без использования дискового пространства.
Распределение памяти фиксированными разделами
Самым простым способом управления оперативной памятью является разделение ее на несколько разделов фиксированной величины. Это может быть выполнено вручную оператором во время старта системы или во время ее генерации. Очередная задача, поступившая на выполнение, помещается либо в общую очередь, либо в очередь к некоторому разделу. Распределение памяти разделами переменной величины
В этом случае память машины не делится заранее на разделы. Сначала вся память свободна. Каждой вновь поступающей задаче выделяется необходимая ей память. Если достаточный объем памяти отсутствует, то задача не принимается на выполнение и стоит в очереди. После завершения задачи память освобождается, и на это место может быть загружена другая задача. Таким образом, в произвольный момент времени оперативная память представляет собой случайную последовательность занятых и свободных участков (разделов) произвольного размера. По сравнению с методом распределения памяти фиксированными разделами данный метод обладает гораздо большей гибкостью, но ему присущ очень серьезный недостаток - фрагментация памяти. Перемещаемые разделы
Одним из методов борьбы с фрагментацией является перемещение всех занятых участков в сторону старших либо в сторону младших адресов, так, чтобы вся свободная память образовывала единую свободную область. В дополнение к функциям, которые выполняет ОС при распределении памяти переменными разделами, в данном случае она должна еще время от времени копировать содержимое разделов из одного места памяти в другое, корректируя таблицы свободных и занятых областей. Эта процедура называется "сжатием".
Методы распределения памяти с использованием дискового пространства
Понятие виртуальной памяти
виртуальная память - это совокупность программно-аппаратных средств, позволяющих пользователям писать программы, размер которых превосходит имеющуюся оперативную память; для этого виртуальная память решает следующие задачи:
размещает данные в запоминающих устройствах разного типа, например, часть программы в оперативной памяти, а часть на диске;
перемещает по мере необходимости данные между запоминающими устройствами разного типа, например, подгружает нужную часть программы с диска в оперативную память;
преобразует виртуальные адреса в физические.
Все эти действия выполняются автоматически, без участия программиста, то есть механизм виртуальной памяти является прозрачным по отношению к пользователю.
Наиболее распространенными реализациями виртуальной памяти является страничное, сегментное и странично-сегментное распределение памяти, а также свопинг.
Страничное распределение
виртуальное адресное пространство каждого процесса делится на части одинакового, фиксированного для данной системы размера, называемые виртуальными страницами. В общем случае размер виртуального адресного пространства не является кратным размеру страницы, поэтому последняя страница каждого процесса дополняется фиктивной областью.
Вся оперативная память машины также делится на части такого же размера, называемые физическими страницами (или блоками).
Размер страницы обычно выбирается равным степени двойки: 512, 1024 и т.д., это позволяет упростить механизм преобразования адресов.
При загрузке процесса часть его виртуальных страниц помещается в оперативную память, а остальные - на диск.
Сегментное распределение
При страничной организации виртуальное адресное пространство процесса делится механически на равные части. Это не позволяет дифференцировать способы доступа к разным частям программы (сегментам), а это свойство часто бывает очень полезным. Например, можно запретить обращаться с операциями записи и чтения в кодовый сегмент программы, а для сегмента данных разрешить только чтение. Кроме того, разбиение программы на "осмысленные" части делает принципиально возможным разделение одного сегмента несколькими процессами. Например, если два процесса используют одну и ту же математическую подпрограмму, то в оперативную память может быть загружена только одна копия этой подпрограммы.
Рассмотрим, каким образом сегментное распределение памяти реализует эти возможности. Виртуальное адресное пространство процесса делится на сегменты, размер которых определяется программистом с учетом смыслового значения содержащейся в них информации. Отдельный сегмент может представлять собой подпрограмму, массив данных и т.п. Иногда сегментация программы выполняется по умолчанию компилятором.
При загрузке процесса часть сегментов помещается в оперативную память (при этом для каждого из этих сегментов операционная система подыскивает подходящий участок свободной памяти), а часть сегментов размещается в дисковой памяти. Сегменты одной программы могут занимать в оперативной памяти несмежные участки. Во время загрузки система создает таблицу сегментов процесса (аналогичную таблице страниц), в которой для каждого сегмента указывается начальный физический адрес сегмента в оперативной памяти, размер сегмента, правила доступа, признак модификации, признак обращения к данному сегменту за последний интервал времени и некоторая другая информация. Если виртуальные адресные пространства нескольких процессов включают один и тот же сегмент, то в таблицах сегментов этих процессов делаются ссылки на один и тот же участок оперативной памяти, в который данный сегмент загружается в единственном экземпляре.
Странично-сегментное распределение
Как видно из названия, данный метод представляет собой комбинацию страничного и сегментного распределения памяти и, вследствие этого, сочетает в себе достоинства обоих подходов. Виртуальное пространство процесса делится на сегменты, а каждый сегмент в свою очередь делится на виртуальные страницы, которые нумеруются в пределах сегмента. Оперативная память делится на физические страницы. Загрузка процесса выполняется операционной системой постранично, при этом часть страниц размещается в оперативной памяти, а часть на диске. Для каждого сегмента создается своя таблица страниц, структура которой полностью совпадает со структурой таблицы страниц, используемой при страничном распределении. Для каждого процесса создается таблица сегментов, в которой указываются адреса таблиц страниц для всех сегментов данного процесса. Адрес таблицы сегментов загружается в специальный регистр процессора, когда активизируется соответствующий процесс.
Свопинг
Разновидностью виртуальной памяти является свопинг. Существует метод организации вычислительного процесса, называемый свопингом. В соответствии с этим методом некоторые процессы (обычно находящиеся в состоянии ожидания) временно выгружаются на диск. Планировщик операционной системы не исключает их из своего рассмотрения, и при наступлении условий активизации некоторого процесса, находящегося в области свопинга на диске, этот процесс перемещается в оперативную память. Если свободного места в оперативной памяти не хватает, то выгружается другой процесс.
При свопинге, в отличие от рассмотренных ранее методов реализации виртуальной памяти, процесс перемещается между памятью и диском целиком, то есть в течение некоторого времени процесс может полностью отсутствовать в оперативной памяти. Существуют различные алгоритмы выбора процессов на загрузку и выгрузку, а также различные способы выделения оперативной и дисковой памяти загружаемому процессу.
Кэш-память
Память вычислительной машины представляет собой иерархию запоминающих устройств (внутренние регистры процессора, различные типы сверхоперативной и оперативной памяти, диски, ленты), отличающихся средним временем доступа и стоимостью хранения данных в расчете на один бит. Пользователю хотелось бы иметь и недорогую и быструю память. Кэш-память представляет некоторое компромиссное решение этой проблемы. Кэш-память - это способ организации совместного функционирования двух типов запоминающих устройств, отличающихся временем доступа и стоимостью хранения данных, который позволяет уменьшить среднее время доступа к данным за счет динамического копирования в "быстрое" ЗУ наиболее часто используемой информации из "медленного" ЗУ.
2. Архитектура системы команд.
Системой команд вычислительной машины называют полный перечень команд, которые способна выполнять данная ВМ. В свою очередь, под архитектурой системы команд (АСК) принято определять те средства вычислительной машины, которые видны и доступны программисту. АСК можно рассматривать как линию согласования нужд разработчиков программного обеспечения с возможностями создателей аппаратуры вычислительной машины.
В истории развития вычислительной техники как в зеркале отражаются изменения, происходившие во взглядах разработчиков на перспективность той или иной архитектуры системы команд. Сложившуюся на настоящий момент ситуацию в области АСК иллюстрирует рис. 2.3.
Среди мотивов, чаще всего предопределяющих переход к новому типу АСК, остановимся на двух наиболее существенных. Первый — это состав операций, выполняемых вычислительной машиной, и их сложность. Второй — место хранения операндов, что влияет на количество и длину адресов, указываемых в адресной части команд обработки данных. Именно эти моменты взяты в качестве критериев излагаемых ниже вариантов классификации архитектур системы команд.
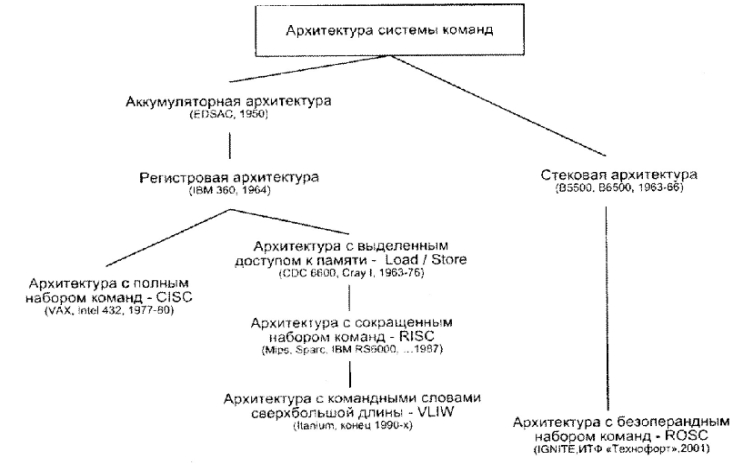
Рис. Хронология развития архитектур системы команд
Классификация по составу и сложности команд
Современная технология программирования ориентирована на языки высокого уровня (ЯВУ), главная цель которых — облегчить процесс программирования. Переход к ЯВУ, однако, породил серьезную проблему: сложные операторы, характерные для ЯВУ, существенно отличаются от простых машинных операций, реализуемых в большинстве вычислительных машин. Проблема получила название семантического разрыва, а ее следствием становится недостаточно эффективное выполнение программ на ВМ. Пытаясь преодолеть семантический разрыв, разработчики вычислительных машин в настоящее время выбирают один из трех подходов и, соответственно, один из трех типов АСК: архитектуру с полным набором команд: CISC (Complex Instruction Set Computer); архитектуру с сокращенным набором команд: RISC (Reduced Instruction Set Computer); архитектуру с командными словами сверхбольшой длины: VLIW (Very Long Instruction Word).
В вычислительных машинах типа CISC проблема семантического разрыва решается за счет расширения системы команд, дополнения ее сложными командами, семантически аналогичными операторам ЯВУ. Основоположником CISC-архитектуры считается компания IBM, которая начала применять данный подход с семейства машин IBM 360 и продолжает его в своих мощных современных универсальных ВМ, таких как IBM ES/9000. Аналогичный подход характерен и для компании Intel в ее микропроцессорах серии 8086 и Pentium.
Для CISC-архитектуры типичны: наличие в процессоре сравнительно небольшого числа регистров общего назначения; большое количество машинных команд, некоторые из них аппаратно реализуют сложные операторы ЯВУ; разнообразие способов адресации операндов;
множество форматов команд различной разрядности;
наличие команд, где обработка совмещается с обращением к памяти.
К типу CISC можно отнести практически все ВМ, выпускавшиеся до середины 1980-х годов, и значительную часть производящихся в настоящее время. Рассмотренный способ решения проблемы семантического разрыва вместе с тем ведет к усложнению аппаратуры ВМ, главным образом устройства управления, что, в свою очередь, негативно сказывается на производительности ВМ в целом. Это заставило более внимательно проанализировать программы, получаемые после компиляции с ЯВУ. Был предпринят комплекс исследований, в результате которых обнаружилось, что доля дополнительных команд, эквивалентных операторам ЯВУ, в общем объеме программ не превышает 10-20%, а для некоторых наиболее сложных команд даже 0,2%. В то же время объем аппаратных средств, требуемых для реализации дополнительных команд, возрастает весьма существенно. Так, емкость микропрограммной памяти при поддержании сложных команд может увеличиваться на 60%. Детальный анализ результатов упомянутых исследований привел к серьезному пересмотру традиционных решений, следствием чего стало появление RISC-архитектуры. Термин RISC впервые был использован Д. Паттерсоном и Д. Дитцелем в 1980 году. Идея заключается в ограничении списка команд ВМ наиболее часто используемыми простейшими командами, оперирующими данными, размещенными только в регистрах процессорах. Обращение к памяти допускается лишь с помощью специальных команд чтения и записи. Резко уменьшено количество форматов команд и способов указания адресов операндов. Сокращение числа форматов команд и их простота, использование ограниченного количества способов адресации, отделение операций обработки данных от операций обращения к памяти позволяет существенно упростить аппаратные средства ВМ и повысить их быстродействие. RISC-архитектура разрабатывалась таким образом, чтобы уменьшить TВИЧ за счет сокращения CPI и I/. Как следствие, реализация сложных команд за счет последовательности из простых, но быстрых RISC-команд оказывается не менее эффективной, чем аппаратный вариант сложных команд в CISC-архитектуре. Отметим, что в последних микропроцессорах фирмы Intel и AMD широко используются идеи, свойственные RISC-архитектуре, так что многие различия между CISC и RISC постепенно стираются.
Помимо CISC- и RISC-архитектур в общей классификации был упомянут еще один тип АСК — архитектура с командными словами сверхбольшой длины (VLIW). Концепция VLIW базируется на RISC-архитектуре, где несколько простых RISC-команд объединяются в одну сверхдлинную команду и выполняются параллельно. В плане АСК архитектура VLIW сравнительно мало отличается от RISC. Появился лишь дополнительный уровень параллелизма вычислений, в силу чего архитектуру VLIW логичнее адресовать не к вычислительным машинам, а к вычислительным системам. Таблица 2.1 позволяет оценить наиболее существенные различия в архитектурах типа CISC, RISC и VLIW.
Таблица 2.1. Сравнительная оценка CISC-, RISC- и VLIW-архитектур
|
Характеристика |
CISC |
RISC |
VLIW |
|
Длина команды |
Варьируется |
Единая |
Единая |
|
Расположение нолей и команде |
Варьируется |
Неизменное |
Неизменное |
|
Количество регистров |
Несколько (часто специализированных) |
Много регистров общего назначения |
Много регистров общего назначения |
|
Доступ к памяти |
Может выполняться как часть команд различных типов |
Выполняется только специальными командами |
Выполняется только специальными командами |
Классификация по месту хранения операндов
Количество команд и их сложность, безусловно, являются важнейшими факторами, однако не меньшую роль при выборе АСК играет ответ на вопрос о том, где могут храниться операнды и каким образом к ним осуществляется доступ. С этих позиций различают следующие виды архитектур системы команд: стековую; аккумуляторную; регистровую; с выделенным доступом к памяти.
Выбор той или иной архитектуры влияет на принципиальные моменты: сколько адресов будет содержать адресная часть команд, какова будет длина этих адресов, насколько просто будет происходить доступ к операндам и какой, в конечном итоге, будет общая длина команд.
Стековая архитектура Стеком называется память, по своей структурной организации отличная от основной памяти ВМ. Принципы построения стековой памяти детально рассматриваются позже, здесь же выделим только те аспекты, которые требуются для пояснения особенностей АСК на базе стека. Стек образует множество логически взаимосвязанных ячеек (рис. 2.4), взаимодействующих по принципу «последним вошел, первым вышел» (L1FO, Last In First Out).
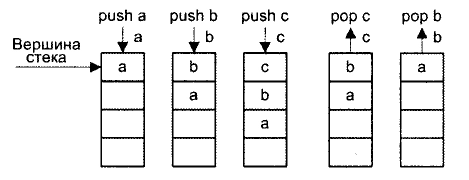
Рис. 2.4. Принцип действия стековой памяти
Верхнюю ячейку называют вершиной стека. Для работы со стеком предусмотрены две операции: push (проталкивание данных в стек) и pop (вытаякивание данных из стека). Запись возможна только в верхнюю ячейку стека, при этом вся хранящаяся в стеке информация предварительно проталкивается на одну позицию вниз. Чтение допустимо также только из вершины стека. Извлеченная информация удаляется из стека, а оставшееся его содержимое продвигается вверх. В вычислительных машинах, где реализована АСК на базе стека (их обычно называют стековыми), операнды перед обработкой помещаются в две верхних ячейки стековой памяти.
Аккумуляторная архитектура Архитектура на базе аккумулятора исторически возникла одной из первых. В ней для хранения одного из операндов арифметической или логической операции в процессоре имеется выделенный регистр — аккумулятор. В этот же регистр заносится и результат операции. Поскольку адрес одного из операндов предопределен, в командах обработки достаточно явно указать местоположение только второго операнда. Изначально оба операнда хранятся в основной памяти, и до выполнения операции один из них нужно загрузить в аккумулятор. После выполнения команды обработки результат находится в аккумуляторе и, если он не является операндом для последующей команды, его требуется сохранить в ячейке памяти.
Регистровая архитектура В машинах данного типа процессор включает в себя массив регистров (регистровый файл), известных как регистры общего назначения (РОН). Эти регистры, в каком-то смысле, можно рассматривать как явно управляемый кэш для хранения недавно использовавшихся данных. Размер регистров обычно фиксирован и совпадает с размером машинного слова. К любому регистру можно обратиться, указав его номер. Количество РОН в архитектурах типа CISC обычно невелико (от 8 до 32), и для представления номера конкретного регистра необходимо не более пяти разрядов, благодаря чему в адресной части команд обработки допустимо одновременно указать номера двух, а зачастую и трех регистров (двух регистров операндов и регистра результата). RISC-архитектура предполагает использование существенно большего числа РОН (до нескольких сотен), однако типичная для таких ВМ длина команды (обычно 32 разряда) позволяет определить в команде до трех регистров. Регистровая архитектура допускает расположение операндов в одной из двух запоминающих сред: основной памяти или регистрах. С учетом возможного размещения операндов в рамках регистровых АСК выделяют три подвида команд обработки: регистр-регистр; регистр-память; память-память.
В варианте «регистр-регистр» операнды могут находиться только в регистрах. В них же засылается и результат. Подтип «регистр-память» предполагает, что од и и из операндов размещается в регистре, а второй в основной памяти. Результат обычно замещает один из операндов. В командах типа «память-память» оба операнда хранятся в основной памяти. Результат заносится в память. Каждому из вариантов свойственны свои достоинства и недостатки (табл. 2.4).
В выражениях вида (т, п), приведенных в первом столбце таблицы, т означает количество операндов, хранящихся в основной памяти, а n — общее число операндов в команде арифметической или логической обработки.
Вариант «регистр-регистр» является основным в вычислительных машинах типа RISC. Команды типа «регистр-память» характерны для CISC-машин. Наконец, вариант «память-память» считается неэффективным, хотя и остается в наиболее сложных моделях машин класса CISC.
|
Вариант |
Достоинства |
Недостатки |
|
Регистр-регистр (0,3) |
Простота реализации, фиксированная длина команд, простая модель формирования объектного кода при компиляции программ, возможность выполнения всех команд за одинаковое количество тактов |
Большая длина объектного кода, из-за фиксированной длины команд часть разрядов в коротких командах не используется |
|
Регистр-память (1.2) |
Данные могут быть доступны без загрузки в регистры процессора, простота кодирования команд, объектный код получается достаточно компактным |
Потеря одного из операндов при записи результата, длинное поле адреса памяти в коде команды сокращает место под помер регистра, что ограничивает общее число РОН. СР1 зависит от места размещения операнда |
|
Память-память (3,3) |
Компактность объектного кода, малая потребность в регистрах для хранения промежуточных данных |
Разнообразие форматов команд и времени их исполнения, низкое быстродействие из-за обращения к памяти |
Архитектура с выделенным доступом к памяти В архитектуре с выделенным доступом к памяти обращение к основной памяти возможно только с помощью двух специальных команд: load и store. В английской транскрипции данную архитектуру называют Load/Store architecture. Команда load (загрузка) обеспечивает считывание значения из основной памяти и занесение его в регистр процессора (в команде обычно указывается адрес ячейки памяти и номер регистра). Пересылка информации в противоположном направлении производится командой store (сохранение). Операнды во всех командах обработки информации могут находиться только в регистрах процессора (чаще всего в регистрах общего назначения). Результат операции также заносится в регистр. В архитектуре отсутствуют команды обработки, допускающие прямое обращение к основной памяти. Допускается наличие в АСК ограниченного числа команд, где операнд является частью кода команды.
АСК с выделенным доступом к памяти характерна для всех вычислительных машин с RISC-архитектурой. Команды в таких ВМ, как правило, имеют длину 32 бита и трехадресный формат. В качестве примеров вычислительных машин с выделенным доступом к памяти можно отметить HP PA-RISC, IBM RS/6000, Sun SPARC, MIPS R4000, DEC Alpha и т. д. К достоинствам АСК следует отнести простоту декодирования и исполнения команды.
3. Найти в массиве максимальный элемент и его индекс. Вывести на печать.
Int num = 0;
Word arr[n];
Int max = arr[0];
For (int i = 0; i<n; i++)
{
if (arr[i]>max)
{
max = arr[i];
num = i;
}
}
printf(max, ‘/n’);
printf( num, ‘/n’);
Билет 29.
1. Аппаратура передачи данных (модемы).
Модем (акроним, составленный из слов модулятор и демодулятор) — устройство, применяющееся в системах связи для физического сопряжения информационного сигнала со средой его распространения, где он не может существовать без адаптации (то есть переносе его нанесущую с модуляцией), и выполняющее функцию модуляции и демодуляции этого сигнала (чаще всего в речевом диапазоне). Модулятор в модеме осуществляет модуляцию несущего сигнала, то есть изменяет его характеристики в соответствии с изменениями входного информационного сигнала, демодулятор — осуществляет обратный процесс. Модем выполняет функцию оконечного оборудования линии связи. Само формирование данных для передачи и обработки принимаемых данных осуществляет т. н. терминальное оборудование (в его роли может выступать и персональный компьютер). Модемы широко применяются для связи компьютеров (одно из их периферийных устройств), позволяющее одному из них связываться с другим (также оборудованным модемом) через телефонную сеть (телефонный модем) или кабельную сеть (кабельный модем). Также модемы ранее применялись в сотовых телефонах (пока не были вытеснены цифровыми способами передачи данных).
Типы компьютерных модемов
По исполнению:
внешние — подключаются через COM или LPT, USB порт или стандартный разъем в сетевой карте RJ-45, обычно имеют отдельный блок питания (существуют и USB-модемы с питанием от шины USB).
внутренние — дополнительно устанавливаются внутрь аппарата (в слот ISA, PCI, PCI-E, PCMCIA, AMR, CNR)
встроенные — являются частью аппарата, куда встроены (например ноутбука или док-станции).
По принципу работы:
аппаратные — все операции преобразования сигнала, поддержка физических протоколов обмена, производятся встроенным в модем вычислителем (например с использованием DSP, контроллера). Так же в аппаратном модеме присутствует ПЗУ, в котором записана микропрограмма, управляющая модемом.
программные (софт-модемы, Host based soft-modem) — все операции по кодированию сигнала, проверки на ошибки и управление протоколами реализованы программно и производятся центральным процессором компьютера. В модеме находятся только входные аналоговые цепи и преобразователи (ЦАП и АЦП), также контроллер интерфейса (например USB).
полупрограммные (Controller based soft-modem) — модемы, в которых часть функций модема выполняет компьютер, к которому подключён модем.
По виду соединения:
Модемы для коммутируемых телефонных линий — наиболее распространённый тип модемов
ISDN — модемы для цифровых коммутируемых телефонных линий
DSL — используются для организации выделенных (некоммутируемых) линий используя обычную телефонную сеть. Отличаются от коммутируемых модемов тем, что используют другой частотный диапазон, а также тем, что по телефонным линиям сигнал передается только до АТС. Обычно позволяют одновременно с обменом данными осуществлять использование телефонной линии в обычном порядке.
Кабельные — используются для обмена данными по специализированным кабелям — к примеру, через кабель коллективного телевидения по протоколу DOCSIS.
Радио — работают в радиодиапазоне, используют собственные наборы частот и протоколы.
Сотовые — работают по протоколам сотовой связи — GPRS, EDGE, и т. п. Часто имеют исполнения в виде USB-брелка. В качестве таких модемов также часто используют терминалы мобильной связи.
Спутниковые — используются для организации спутникового интернета.Принимают и обрабатывают сигнал полученный со спутника.
PLC — используют технологию передачи данных по проводам бытовой электрической сети.
Наиболее распространены в настоящее время:
внутренний программный модем
внешний аппаратный модем
встроенные в ноутбуки модемы.
2. Проектные процедуры в САПР.
Проектная процедура—часть проектирования, заканчивающаяся получением проектного решения. Примерами проектных процедур служат синтез функциональной схемы устройства, оптимизация параметров функционального узла, трассировка межсоединений на печатной плате и т. п.
Проектные процедуры делятся на процедуры синтеза и анализа.
Процедуры синтеза заключаются в создании описаний проектируемых объектов. В таких описаниях отображаются структура и параметры объекта и соответственно существуют процедуры структурного и параметрического синтеза. Под структурой объекта понимают состав его элементов и способы связи элементов друг с другом. Параметр объекта—величина, характеризующая некоторое свойство объекта или режим его функционирования. Примерами процедур структурного синтеза служат синтез структурной схемы с корректирующими устройствами (структура которой выражается перечнем входящих в нее звеньев и их соединений) или синтез алгоритма (его структура определяется составом и последовательностью операторов). Процедура параметрического синтеза заключается в расчете значений параметров элементов при заданной структуре объекта, например коэффициентов корректирующих устройств.
Процедуры анализа заключаются в исследовании проектируемого объекта или его описания, направленном на получение полезной информации о свойствах объекта. Цель анализа — проверка работоспособности объекта. Часто задача анализа формулируется как задача установления соответствия двух различных описаний одного и того же объекта. При этом одно из описаний считается первичным и его корректность предполагается установленной. Другое описание относится к более подробному уровню иерархии или к другому аспекту, и его правильность нужно установить сопоставлением с первичным описанием. Такое сопоставление называется верификацией.
По назначению подсистемы САПР разделяют на два вида: проектирующие и обслуживающие.
К проектирующим относятся подсистемы, выполняющие проектные процедуры и операции, например:
подсистема компоновки машины;
подсистема проектирования сборочных единиц;
подсистема проектирования деталей;
подсистема проектирования схемы управления;
подсистема технологического проектирования.
3. Рассчитать сетевую маску для IP адреса 192.168.0.37/28. Указать сколько компьютеров может входить в такую подсеть. Написать 2 зарезервированных адреса у которых в поле номер компьютера расположены все 0 или все 1.
Рассчитать сетевую маску для адреса 192.168.0.37/28
28 первых бит отдано для адреса сети (выделены более крупным шрифтом). Представляем предложенный адрес в битовом варианте по октетам, получаем
192
|
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
|
128 |
64 |
32 |
16 |
8 |
4 |
2 |
1 |
168
|
1 |
0 |
1 |
0 |
1 |
0 |
0 |
0 |
|
128 |
64 |
32 |
16 |
8 |
4 |
2 |
1 |
0
|
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
|
128 |
64 |
32 |
16 |
8 |
4 |
2 |
1 |
37
|
0 |
0 |
1 |
0 |
0 |
1 |
0 |
1 |
|
128 |
64 |
32 |
16 |
8 |
4 |
2 |
1 |
Если установить их в 1, тогда получится сетевая маска 255.255.255.240
Сколько компьютеров входит в данную сеть
Под адрес компьютеров в сети отдано 4 бита, получаем 24 – 2 = 16 – 2 = 14 компьютеров
Написать 2 зарезервированных адреса, у которых в поле номер компьютера все нули или все 1.
Первые 3 октета не изменятся, будем рассматривать только последний октет
Все биты номера компьютера в сети (4 последних бита) = 0
|
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
|
128 |
64 |
32 |
16 |
8 |
4 |
2 |
1 |
Ответ: Адрес 192.168.0.32
Все биты номеров компьютера в сети = 1
|
0 |
0 |
1 |
0 |
1 |
1 |
1 |
1 |
|
128 |
64 |
32 |
16 |
8 |
4 |
2 |
1 |
Ответ: 192.168.0.47
Билет 30.
1. Характеристика канального и сетевого уровней стека протоколов TCP/IP.
TCP/IP - аббревиатура термина Transmission Control Protocol/Internet Protocol (Протокол управления передачей/Интернет Протокол) - это согласованный заранее стандарт, служащий для обмена данных между двумя узлами(компьютерами в сети), причём неважно, на какой платформе эти компьютеры и какая между ними сеть. TCP/IP служит как мост, соединяющий все узлы сети воедино, за это он и завоевал свою популярность. TCP/IP зародился в результате исследований, профинансированных ARPA (Advanced Research Project Agency) - специальным отделением правительства США в 1970-х годах. Он был задуман, как общий стандарт, который объединит все сети в единую виртуальную "сеть сетей"(internetwork). Таким образом был создан Интернет, в результате преобразования существующего конгломерата вычислительных сетей, носивших название ARPAnet, с помощью TCP/IP. Название "TCP/IP" связано с двумя протоколами: TCP и IP. Но TCP/IP - это не только эти два протокола. Это целое семейство протоколов, объединенное под одним началом - IP-протоколом. В это семейство входят протоколы, которые взаимодействуют с протоколом IP и с его помощью строят свои каналы данных. Это сам TCP, а также UDP, ICMP, telnet, SMTP, FTP и многие другие.
Структура стека TCP/IP
|
Уровень I |
Прикладной уровень |
|
Уровень II |
Основной (транспортный) уровень |
|
Уровень III |
Уровень межсетевого взаимодействия |
|
Уровень IV |
Уровень сетевых интерфейсов |
Канальный уровень - Уровень сетевых интерфейсов. Идеологическим отличием архитектуры стека TCP/IP от многоуровневой организации других стеков является интерпретация функций самого нижнего уровня - уровня сетевых интерфейсов. Протоколы этого уровня должны обеспечивать интеграцию в составную сеть других сетей, причем задача ставится так: сеть TCP/IP должна иметь средства включения в себя любой другой сети, какую бы внутреннюю технологию передачи данных эта сеть не использовала. Отсюда следует, что этот уровень нельзя определить раз и навсегда. Для каждой технологии, включаемой в составную сеть подсети, должны быть разработаны собственные интерфейсные средства. К таким интерфейсным средствам относится протокол инкапсуляции IP-пакетов межсетевого взаимодействия в кадры локальных технологий.
Уровень сетевых интерфейсов в протоколах TCP/IP не регламентируется, но он поддерживает все популярные стандарты физического и канального уровней: для локальных сетей - это Ethernet, Token Ring, FDDI, Fast Ethernet, Gigabit Ethernet, 100VG-AnyLAN, для глобальных сетей - протоколы соединений "точка-точка" SLIP и PPP, протоколы территориальных сетей с коммутацией пакетов X.25, frame relay. Разработана также специальная спецификация, определяющая использование технологии ATM в качестве транспорта канального уровня.
Сетевой уровень. Стержнем всей архитектуры является уровень межсетевого взаимодействия, или сетевой уровень, который реализует концепцию передачи пакетов в режиме без установления соединений, то есть дейтаграммным способом. Именно этот уровень обеспечивает возможность перемещения пакетов по сети, используя тот маршрут, который в данный момент является наиболее рациональным. Этот уровень также называют уровнем internet, указывая, тем самым, на основную его функцию - передачу данных через составную сеть.
Основным протоколом уровня (в терминологии модели OSI) в стеке TCP/IP является протокол IP. Этот протокол изначально проектировался как протокол передачи пакетов в составных сетях, состоящих из большого количества локальных сетей, объединенных как локальными, так глобальными связями. Поэтому протокол IP хорошо работает в сетях со множеством топологий, рационально используя наличие в них подсистем и экономно расходуя пропускную способность низкоскоростных линий связи. Так как протокол IP является дейтаграммным протоколом, он не гарантирует доставку пакетов до узла назначения, но старается это сделать.
К уровню межсетевого взаимодействия относятся все протоколы, связанные с состоянием и модификацией таблиц маршрутизации, такие как протоколы сбора маршрутной информации RIP и OSPF, а также протокол межсетевых управляющих сообщений ICMP. Последний протокол предназначен для обмена информацией об ошибках между маршрутизаторами сети и удаленным источником пакета. С помощью специальных пакетов ICMP сообщает о невозможности доставки пакета, о превышении времени жизни или продолжительности сборки пакета из фрагментов, об аномальных величинах параметров, об изменении маршрута пересылки и типа обслуживания, о состоянии системы и т. п.
2. Стековая архитектура вычислительных машин.
Стеком называется память, по своей структурной организации отличная от основной памяти ВМ. Принципы построения стековой памяти детально рассматриваются позже, здесь же выделим только те аспекты, которые требуются для пояснения особенностей АСК на базе стека. Стек образует множество логически взаимосвязанных ячеек (рис. 2.4), взаимодействующих по принципу «последним вошел, первым вышел» (L1FO, Last In First Out).
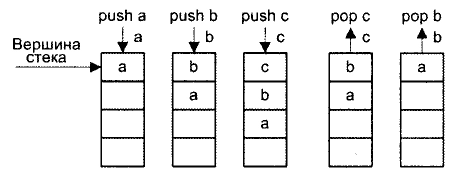
Рис.. Принцип действия стековой памяти. Верхнюю ячейку называют вершиной стека. Для работы со стеком предусмотрены две операции: push (проталкивание данных в стек) и pop (вытаякивание данных из стека). Запись возможна только в верхнюю ячейку стека, при этом вся хранящаяся в стеке информация предварительно проталкивается на одну позицию вниз. Чтение допустимо также только из вершины стека. Извлеченная информация удаляется из стека, а оставшееся его содержимое продвигается вверх. В вычислительных машинах, где реализована АСК на базе стека (их обычно называют стековыми), операнды перед обработкой помещаются в две верхних ячейки стековой памяти.
Особенностью вычислителей, построенных по стековой архитектуре является то, что входные, промежуточные и результирующие данные хранятся в памяти данных с последовательным доступом.
Для осуществления операции в стек необходимо записать данные на вершину стека (операция PUSH). Вершина и следующая за вершиной позиции стека подаются на вход АЛУ, выход АЛУ в свою очередь может управлять вершиной стека. ОТ – определяет выполняемую операцию.
PUSH A
PUSH B
ADD
POP C
//Где A, B, C – адреса в основной памяти.
Дочтоинства: Простота аппаратной реализации. Простота записи алгоритмов вычисления. Простота мнемонического описания микроопераций (с одним или без операндом).
Недостатки: Стек – запоминающее устройство с последовательным доступом обладающее медленной скоростью работы. Данная архитектура не позволяет производить расширения или дополнения для увеличения мощности.
3. Рассчитать сетевую маску для IP адреса 192.168.0.37/28. Указать сколько компьютеров может входить в такую подсеть. Написать 2 зарезервированных адреса у которых в поле номер компьютера расположены все 0 или все 1.
Рассчитать сетевую маску для адреса 192.168.0.37/28
28 первых бит отдано для адреса сети (выделены более крупным шрифтом). Представляем предложенный адрес в битовом варианте по октетам, получаем
192
|
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
|
128 |
64 |
32 |
16 |
8 |
4 |
2 |
1 |
168
|
1 |
0 |
1 |
0 |
1 |
0 |
0 |
0 |
|
128 |
64 |
32 |
16 |
8 |
4 |
2 |
1 |
0
|
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
|
128 |
64 |
32 |
16 |
8 |
4 |
2 |
1 |
37
|
0 |
0 |
1 |
0 |
0 |
1 |
0 |
1 |
|
128 |
64 |
32 |
16 |
8 |
4 |
2 |
1 |
Если установить их в 1, тогда получится сетевая маска 255.255.255.240
Сколько компьютеров входит в данную сеть
Под адрес компьютеров в сети отдано 4 бита, получаем 24 – 2 = 16 – 2 = 14 компьютеров
Написать 2 зарезервированных адреса, у которых в поле номер компьютера все нули или все 1.
Первые 3 октета не изменятся, будем рассматривать только последний октет
Все биты номера компьютера в сети (4 последних бита) = 0
|
0 |
0 |
1 |
0 |
0 |
0 |
0 |
0 |
|
128 |
64 |
32 |
16 |
8 |
4 |
2 |
1 |
Ответ: Адрес 192.168.0.32
Все биты номеров компьютера в сети = 1
|
0 |
0 |
1 |
0 |
1 |
1 |
1 |
1 |
|
128 |
64 |
32 |
16 |
8 |
4 |
2 |
1 |
Ответ: 192.168.0.47
Билет 31
1. Синтаксический разбор. Классификация методов синтаксического разбора.
Задачей синтаксического анализа считается проверка, принадлежит ли произвольная заданная цепочка T * языку L(G) для заданной грамматики G. На основе методов синтаксического анализа решаются задачи синтаксически управляемой обработки данных (например, текстов). Такой задачей является и задача трансляции. Регулярные языки и порождающие их А-грамматики используются, в основном, для лексического анализа распознавания в тексте его лексических единиц, лексем, т.е. слов, из которых по более сложным правилам строится текст.
Синтаксический разбор — это основная часть компилятора на этапе анализа. Она выполняет выделение синтаксических конструкций в тексте исходной программы, обработанном лексическим анализатором. На этой же фазе компиляции проверяется синтаксическая правильность программы Синтаксический разбор играет главную роль — роль распознавателя текста входного языка.
Методы (классификация) синтаксического разбора (в основном два способа):
Нисходящий разбор. Суть разбора состоит в том, что текст некоей программы, который с самого начала представлен в виде очень большой строки, постепенно разбивается на лексемы, к лексемам применяется синтаксический анализ для построения внутреннего представления программы.
Восходящий разбор. Суть этого типа разбора состоит в том, что программа представляется в виде последовательности лексем. которые далее "снизу вверх" склеиваются в более сложные предложения языка, после успешной склейки производится построение внутреннего представления программы.
Отдельно можно отметить ассемблеры, в которых разбор осуществляется построчно, часто без необходимости использования грамматик, и препроцессоры, которые просто производят замену строк с применением некоторых простых правил. С функциональностью "хорошего" препроцессора можно познакомится на примере m4 из среды Unix.
На самом деле в реальных компиляторах редко используются те или иные методы разбора в чистом виде. Обычно используются комбинации известных методов, или же несколько изменённые методы разбора, в основном с целью повышения скорости разбора. Однако, последнее десятилетие из-за повышения при компиляции программ удельной массы проходов оптимизации, время синтаксического разбора занимает небольшой процент общего времени компиляции, потому нет особого смысла заниматься оптимизацией разбора сверх меры. Частично в ряде случаев используются автоматизированные среды для постороения лексических и синтаксических анализаторов: lex, yacc, bison. Так, в версии GCC 3.3 для синтаксического разбора используется bison, но в последнее время разработки пытаются написать проход синтаксического анализа не использующий bison для повышения скорости синтаксического разбора.
2. Интеграция систем автоматизации проектирования и управления(CAD – CAM – CAPP – системы).
Проектирование – процесс, заключающийся в получении и преобразовании исходного описания объекта в окончательное описание на основе выполнения комплекса работ исследовательского, расчетного и конструкторского характера.
Одними из важнейших функций инженера являются проектирование изделий и технологических процессов их изготовления. В связи с этим САПР принято делить по крайней мере на два основных вида:
САПР изделий (САПР И);
САПР технологических процессов (САПР ТП) их изготовления.
САПР изделий. На Западе эти системы называют CAD (Computer Aided Design) – «проектирование с помощью компьютера» - фактически этот термин означает системы геометрического моделирования и САПР чертежно-конструкторских работ. Эти системы выполняют объемное и плоское геометрическое моделирование, инженерные расчеты и анализ, оценку проектных решений, изготовление чертежей.
САПР технологии изготовления. В России эти системы принято называть САПР ТП или АС ТППП (автоматизированные системы технологической подготовки производства). На Западе их называют CAPP (Computer Automated Process Planning). Здесь Automated – автоматический, Process – процесс, Planning – планировать, планирование, составление плана. С помощью этих систем разрабатывают технологические процессы и оформляют их в виде маршрутных, операционных, маршрутно-операционных карт, проектируют технологическую оснастку, разрабатывают управляющие программы (УП) для станков с ЧПУ (числовое программное управление).
Более конкретное описание технологии обработки на оборудовании с ЧПУ (в виде кадров управляющей программы) вводится в автоматизированную систему управления производственным оборудованием (АСУПР), которую на Западе принято называть CAM (Computer Aided Manufacturing) - “производство с помощью компьютера”. Техническими средствами, реализующими данную систему, могут быть системы ЧПУ станков, компьютеры, управляющие автоматизированными станочными системами.
С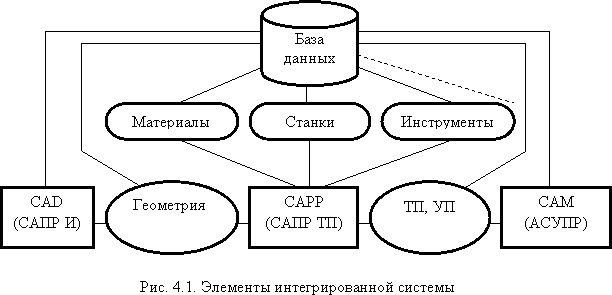 амостоятельное
использование систем CAD, CAM дает
экономический эффект. Но он может быть
существенно увеличен их интеграцией
посредством CAPP. Такаяинтегрированная
система CAD/CAM
на информационном уровне поддерживается
единой базой данных. В ней хранится
информация о структуре и геометрии
изделия (как результат проектирования
в системе CAD), о технологии изготовления
(как результат работы системы CAPP) и
управляющие программы для оборудования
с ЧПУ (как исходная информация для
обработки в системе CAM на оборудовании
с ЧПУ) – рис.4.1.
амостоятельное
использование систем CAD, CAM дает
экономический эффект. Но он может быть
существенно увеличен их интеграцией
посредством CAPP. Такаяинтегрированная
система CAD/CAM
на информационном уровне поддерживается
единой базой данных. В ней хранится
информация о структуре и геометрии
изделия (как результат проектирования
в системе CAD), о технологии изготовления
(как результат работы системы CAPP) и
управляющие программы для оборудования
с ЧПУ (как исходная информация для
обработки в системе CAM на оборудовании
с ЧПУ) – рис.4.1.
3. Написать программу на языке С++ для удаления из списка целых всех элементов, равных 0. Например: [1,0,2,0,3,0] [1,2,3].
|
#pragma hdrstop #include <iostream.h> void main() { int X[10],Y[10],N,j=0,i; cout<<"\n Vvedite N (<10) =="; cin>>N; for(i=1;i<=N;i++) { cout<<"\n X["<<i<<"] =="; cin>>X[i]; }
|
for(i=1;i<=N;i++) { if (X[i]!=0) { j++; Y[j]=X[i]; } }
|
for(i=1;i<=j;i++) { cout<<"\n X["<<i<<"] == "<<Y[i]; } }
|
Билет 32
1. Понятие алгоритма. Интуитивное понятие алгоритма.
Слово алгоритм возникло от algorithm- латинской транслитерации имени великого математика IX века Мохаммеда ибн Муссы аль-Хорезми, который сформулировал правила выполнения четырех арифметических действий над многозначными числами.
Алгоритм - это организованная последовательность действий, понятных для некоторого исполнителя, ведущая к решению поставленной задачи.
Алгоритм - это конечная последовательность однозначных предписаний, исполнение которых позволяет с помощью конечного числа шагов получить решение задачи, однозначно определяемое исходными данными.
Алгоритм – понятное и точное предписание исполнителю совершить последовательность действий, направленных на достижение цели.
Алгоритм – это набор однозначно определённых шагов, выполняемых для решения задачи определённого класса.
Интуитивное определение неформально, поскольку отсутствуют формальные определения используемых в нем базовых понятий: элементарного шага, задач, классов задач. Кроме того, даже интуитивное определение элементарного шага основано на понятии алгоритма.
В 30 годы ХХ века в противовес классическим представлениям Альхарезми, возникла гипотеза об алгоритмически неразрешимости нескольких задач.
А) С точки зрения Геделя, алгоритм есть последовательность построения сложных математических функций из более простых, с использованием правил сформулированных на языках математической логики.
Можно ввести математическую абстракцию:
Пусть Х – совокупность входных данных, Y – совокупность выходных данных.
Y=f(X)
В) Черча. λ – исчисление или ввел понятие систем рекурсивно-вычислимых (РВ) функций. В этой системе было выделено 3 базовых функции и 3 оператора, посредством которых мы из базовых РВ функций строим более сложные РВ функции.
Алгоритм – способ определения РВ функции.
С) Алaна Тьюринга. Он предложил модель гипотетического вычислительного устройства (исполнителя). Алгоритм – программа для этого исполнителя.
D) Маркова. Основан на том, что какие бы ни были входные данные, они описываются определённым языком.
ВХОД – строка
ВЫХОД – строка
Алгоритм – набор правил подстановки одних символов вместо других.
Был также обоснован тезис Черча – Тьюринга. Различные подходы к формализации понятия алгоритма эквивалентны между собой с точки зрения понятия алгоритмической неразрешимости. С этой точки зрения, любой компьютер с Фон-неймановской архитектурой или другой ныне известной архитектурой, позволяет реализовать только те алгоритмы, которые можно реализовать на машине Тьюринга.
Свойства алгоритма:
Массовость - алгоритм должен быть применим для класса подобных задач.
Дискретность - алгоритм состоит из ряда дискретных шагов.
Определенность - каждый следующий шаг алгоритма однозначно определяется предыдущими шагами.
Результативность - алгоритм должен приводить к решению поставленной задачи за конечное число шагов
Понятность – алгоритм рассчитан на исполнителя, и должен быть сформулирован на понятном ему языке (СКИ – система команд исполнителя).
Каждый исполнитель алгоритма имеет свою систему команд (набор действий) и свою среду (набор объектов, над которыми совершаются действия), в которой, и только в ней, он работает.
Виды алгоритма:
Линейный - алгоритм, в котором все предписания (шаги) выполняются так, как записаны, без изменения порядка следования, строго друг за другом.
Разветвляющийся - алгоритм, в котором выполнение того или иного действия (шага) зависит от выполнения или не выполнения какого-либо условия.
Циклический - алгоритм, в котором некоторая последовательность действий повторяется несколько раз.
Способы записи алгоритма:
Словесно-формульное описание (на естественном языке с использованием математических формул).
Графическое описание в виде блок-схемы (набор связанных между собой геометрических фигур).
алгоритмический язык – система обозначений и правил для единообразной и точной записи алгоритмов и исполнения их.
Разработка алгоритмов.
Существует два подхода к разработке алгоритмов: операциональный и структурный.
Операциональный:
· минимум памяти;
· минимум операций.
операции:
· присваивание;
· арифметические;
· сравнение;
· условный и безусловный переход;
· вызов подпрограммы.
Каждый алгоритм можно представить в виде суперпозиции трех базовых алгоритмических структур: следование, ветвление, цикл. Такой подход позволяет осуществлять разработку алгоритмов, последовательно их детализируя. Сначала выделяется несколько крупных логических блоков (модулей), затем каждый из них последовательно детализируется до отдельных команд конкретного языка программирования. Кроме того, при таком подходе каждый модуль может реализовываться отдельным программистом, если предварительно разработан способ взаимосвязи между модулями.
2. Объекты и отношения в программировании. Сущность объектного подхода к разработке программных средств. Особенности объектного подхода к разработке внешнего описания программного средства.
Окружающий нас мир состоит из объектов и отношений между ними. Объект воплощает некоторую сущность и имеет некоторое состояние, которое может изменяться со временем как следствие влияния других объектов, находящихся с данным в каком-либо отношении. Он может иметь внутреннюю структуру: состоять из других объектов, также находящихся между собой в некоторых отношениях. Исходя из этого, можно построить иерархическое строение мира из объектов. Однако при каждом конкретном рассмотрении окружающего нас мира некоторые объекты считаются неделимыми ("точечными"), причем в зависимости от целей рассмотрения такими (неделимыми) могут приниматься объекты разного уровня иерархии. Отношение связывает некоторые объекты: можно считать, что объединение этих объектов обладает некоторым свойством. Если отношение связывает n объектов, то такое отношение называется n-местным (n-арным). На каждом месте объединения объектов, которые могут быть связаны каким-либо конкретным отношением, могут находиться разные объекты, но вполне определенные (в этом случае говорят: объекты определенного класса). Одноместное отношение называется свойством объекта (соответствующего класса). Состояние объекта может быть изучено по значению свойств этого объекта или неявно по значению свойств объединений объектов, связываемых вместе с данным тем или иным отношением.
В процессе познания или изменения окружающего нас мира мы всегда принимаем в рассмотрение ту или иную упрощенную модель мира (модельный мир), в которую включаем некоторые из объектов и некоторые из отношений окружающего нас мира и, как правило, одного уровня иерархии. Каждый объект, имеющий внутреннюю структуру, может представлять свой модельный мир, включающий объекты этой структуры и отношения, которые их связывают. Таким образом, окружающий нас мир, можно рассматривать (в некотором приближении) как иерархическую структуру модельных миров.
В настоящее время в процессе познания или изменения окружающего нас мира широко используется компьютерная техника для обработки различного рода информации. В связи с этим применяется компьютерное (информационное) представление объектов и отношений. Каждый объект информационно может быть представлен некоторой структурой данных, отображающей его состояние. Свойства этого объекта могут задаваться непосредственно в виде отдельных компонент этой структуры, либо специальными функциями над этой структурой данных. N-местные отношения для N>1 можно представить либо в активной форме, либо в пассивной форме. В активной форме N-местное отношение представляется некоторым программным фрагментом, реализующим либо N-местную функцию (определяющую значение свойства соответствующего объединения объектов), либо процедуру, осуществляющую по состоянию представлений объектов, связываемых представляемым отношением, изменение состояний некоторых из них. В пассивной форме такое отношение может быть представлено некоторой структурой данных (в которую могут входить и представления объектов, связываемых этим отношением), интерпретируемую на основании принятых соглашений по общим процедурам, независящим от конкретных отношений (например, реляционная база данных). В любом случае представление отношения определяет некоторые действия по обработке данных.
При исследовании модельного мира пользователь может по-разному получать информацию от компьютера. При одном подходе его могут интересовать получение информации об отдельных свойствах интересующих его объектов или результатах какого-либо взаимодействия между некоторыми объектами. Для этого он заказывает разработку того или иного ПС, выполняющего интересующие его функции, или некоторую информационную систему, способной выдавать информацию об интересующих его отношениях, используя при этом соответствующую базу данных. В начальный период развития компьютерной техники (при не достаточно высокой мощности компьютеров) такой подход к использованию компьютеров был вполне естественным. Именно он и провоцировал функциональный (реляционный) подход к разработке ПС. Сущность этого подхода состоит в систематическом использовании декомпозиции функций (отношений) для построения структуры ПС и текстов программ, входящих в него. При этом сами объекты, к которым применялись заказываемые и реализуемые функции, представлялись фрагментарно (в том объеме, который необходим для выполнения этих функций) и в форме, удобной для реализации этих функций. Тем самым не обеспечивалось цельного и адекватного компьютерного представления модельного мира, интересующего пользователя: отображение его на используемые ПС могло оказаться для пользователя достаточно трудоемкой задачей, попытки незначительного расширения объема и характера информации об интересующем пользователя модельном мире, получаемой от таких ПС, могло привести к серьезной их модернизации. Такой подход к разработке ПС поддерживается большинством используемых языков программирования, начиная от языков ассемблеров и процедурных языков (ФОРТРАН, Паскаль) до функциональных языков (ЛИСП) и языков логического программирования (ПРОЛОГ).
При другом подходе к исследованию модельного мира с помощью компьютера пользователя может интересовать наблюдение за изменением состояний объектов в результате их взаимодействий. Это требует достаточно цельного представления в компьютере интересующего пользователя объекта, а программные компоненты, реализующие отношения, в которых участвует этот объект, явно связываются с ним. Для реализации такого подхода приходилось строить программные средства, моделирующих процессы взаимодействия объектов (модельного мира). С помощью традиционных средств разработки это оказалось довольно трудоемкой задачей. Правда, появились языки программирования, специально ориентированные на такое моделирование, но это лишь частично упростило задачу разработки требуемых ПС. Наиболее полно отвечает решению этой задачи объектный подход к разработке ПС. Сущность его состоит в систематическом использовании декомпозиции объектов при построении структуры ПС и текстов программ, входящих в него. При этом функции (отношения), выполняемые таким ПС, выражались через отношения объектов разных уровней, т. е. их декомпозиция существенно зависела от декомпозиции объектов.
Говоря об объектном подходе следует также четко понимать о какого рода объектах идет речь: объектах модельного мира пользователя, об их информационном представлении, об объектах программы, с помощью которых строится ПС. Кроме того, следует различать собственно объекты (объекты "пассивные") и субъекты (объекты "активные").
Особенности объектного подхода к разработке внешнего описания программного средства
Определение требований заключается в неформальном описании модельного мира, который пользователь собирается изучать или просто использовать с помощью требуемого ПС. При этом повышается роль прототипирования, которое при этом подходе часто окупается уменьшением объема работы на последующих этапах разработки ПС. Часто определение требование завершается разработкой диаграммы вариантов использования, в которой фиксируются, в каких случаях будет использоваться ПС. Это позволяет при разработке ПС ограничиться только такими ее функциональными возможностями, которые поддерживают эти случаи (варианты) использования.
Существенно изменяется содержание процесса спецификации требований: вместо разработки функциональной спецификации ПС создается формальное описание модельного мира, состоящее из трех частей:
• объектной модели,
• динамической модели,
• функциональной модели.
Назначение этих частей можно определить следующим образом: объектная модель определяет то, с чем что-то случается; динамическая модель определяет, когда это случается; функциональная модель определяет то, что случается.
Объектная модель показывает статическую объектную структуру модельного мира, который должно представлять разрабатываемое ПС (программная система). Она включает определения используемых классов объектов и отношений между этими классами, а также определение используемых объектов этих классов и отношения между этими объектами.
Обычно класс объектов в объектной модели представляется в виде тройки (Имя класса, Список атрибутов, Список операций).
Каждый атрибут представляется некоторым именем и может принимать значения определенного типа. По существу, атрибут класса выражает некоторое простое свойство объектов этого класса. Представление некоторых простых свойств объектов атрибутами весьма удобно, особенно когда по значениям этих атрибутов осуществляется классификация объектов. Операции, указываемые в представлении класса, отражают другие свойства объектов этого класса (как простые, так и ассоциативные). Они показывают, что можно делать с объектами этого класса (или что могут делать сами эти объекты).
В объектной модели отношение между объектами некоторых классов обобщаются в отношения между этими классами. При этом используются, как правило, только одноместные и двуместные отношения между объектами. Более сложные отношения приводит к неоправданному усложнению объектных моделей, а с другой стороны, такие отношения всегда могут быть сведены к двуместным за счет определения дополнительных классов. Одноместные отношения называют атрибутами, причем некоторые атрибуты объекта получаются из атрибутов класса присвоением им конкретных значений. Отношение между двумя (и более) объектами называют связями, а их обобщение (отношение между классами) обычно называют ассоциациями. Ассоциации определяют допустимые связи между объектами. Различают следующие виды ассоциаций:
• взаимодействия состояний объектов,
• агрегирования (структурирования) объектов,
• абстрагирования (порождения) классов.
Ассоциация «взаимодействие», по существу, означает, что объекты классов, находящихся в таком отношении, могут быть параметрами некоторых операций. Ассоциация «агрегирование» означает, что объект одного из классов, находящихся в таком отношении, включает (или может включать) в себя (как часть) объекты другого из этих классов. Ассоциация «абстрагирование» означает, что один из классов, находящихся в таком отношении, наследует свойства другого из этих классов и может обладать также и другими (дополнительными) свойствами.
Для представления объектной модели часто используются графические языки спецификации объектов (например, язык UML). На таких языках классы и объекты задаются прямоугольниками, в которых указывается специфицирующая их информация. Для задания отношений между двумя классами соответствующие им прямоугольники связываются линией, снабженной различными графическими значками и некоторыми надписями. Графические значки специфицируют характер (вид) отношения между этими классами, а надписи обеспечивают полную идентификацию этого отношения (делают его конкретным).
Следует заметить, что объектная модель полностью включает описание внешней информационной среды при реляционном подходе.
Динамическая модель показывает допустимые последовательности изменений состояний объектов из объектной модели модельного мира, который должно представлять разрабатываемое ПС (программная система). Она описывает последовательности операций в ответ на внешние сигналы (взаимодействия) без рассмотрения того, что эти операции делают. Динамическая модель необходима, если в соответствующей объектной модели имеются активные объекты.
Основные понятия динамической модели: события и состояния объектов. Под событием здесь понимается элементарное воздействие одного объекта на другой, происходящее в определенный момент времени. Одно событие может логически предшествовать другому или быть не связанным с другим. Другими словами, события в динамической модели частично упорядочены. Под состоянием объекта здесь понимается совокупность значений атрибутов объекта и представления текущих связей этого объекта с другими объектами. Состояние объекта связывается с интервалом времени между некоторыми двумя событиями, на которые реагирует этот объект. Объект переходит из одного состояния в другое в результате реакции на некоторое событие (в конце интервала, связанного с этим состоянием).
В связи с этим в динамической модели для каждого класса активных объектов строится своя диаграмма состояний. Она представляет собой граф, вершинами которого являются состояния, а дугами – переходы между этими состояниями (переходы часто обозначаются именами событий). Некоторые переходы могут быть связаны с условиями, разрешающими эти переходы. Условие – это предикат, зависящий от значений некоторых атрибутов объекта. Каждое условие указывается на дуге, переходом по которой управляет это условие. Существенно, что в диаграмме состояний с некоторыми состояниями или событиями связываются определенные операции. Операция, связываемая с событием, обозначает реакцию объекта на это событие и считается, что она выполняется мгновенно (в точке некоторого временного интервала). Такая операция называется действием. Операция, связываемая с состоянием, выполняется в рамках временного интервала, с которым связано это состояние (т.е. имеет продолжительность, ограниченную этим интервалом). Такая операция называется деятельностью. Диаграмма состояний определяет управление активизацией указанных операций. Таким образом, диаграмма состояний описывает поведение одного класса объектов.
Динамическая модель в целом объединяет все диаграммы состояний с помощью событий между классами.
Функциональная модель показывает, как вычисляются выходные значения из входных без указания порядка, в котором эти значения вычисляются. Она определяет все операции, условия и ограничения, используемые в объектной и динамической моделях (внешние операции). Функциональная модель соответствует определению внешних функций при реляционном подходе к разработке ПС.
Для определения крупных операций в функциональной модели используются потоковые диаграммы (диаграммы потоков данных), позволяющие выразить эти операции через более простые операции. Основными понятиями потоковых диаграмм являются процессы, объекты и потоки данных. Потоковая диаграмма – это граф, вершинами которого являются объекты или процессы, а дугами – потоки данных. Процессы преобразуют данные, поступающие от одних объектов и направляемые для хранения в другие объекты. Эти процессы представляют внутренние операции, через которые выражается операция, представляемая данной потоковой диаграммой. Объекты могут быть пассивными (хранилищами данных) и активными (агентами). Пассивные объекты используются только для хранения данных, а активные объекты используются как для хранения, так и для преобразования данных. Потоки данных определяют допустимые направления перемещения данных и типы перемещаемых данных.
Процессы могут выражаться терминальными операциями (определяемые непосредственно) или с помощью других потоковых диаграмм. Таким образом, потоковые диаграммы являются иерархическими.
Терминальные операции определяются так же, как и при реляционном подходе. Впрочем, и диаграммы потоков данных используются при реляционном подходе.
Таким образом, основным содержанием этапа внешнего описания при объектном подходе является объектное моделирование. При этом широко используются формальные языки спецификаций, в том числе и графические. Одним из наиболее употребительных в настоящее время таких языков является язык UML.
3. Указать к какому классу относится каждый из перечисленных IP адресов:
192.168.0.15
127.0.0.1
112.0.0.15
167.58.13.21
Определить к какому классу относится каждый IP-адрес
Старший октет адреса представляем в двоичном коде: если старший бит = 0 (класс А), = 10 (класс B), = 11 (класс С)
192.168.0.15
|
1 |
1 |
0 |
0 |
0 |
0 |
0 |
0 |
|
128 |
64 |
32 |
16 |
8 |
4 |
2 |
1 |
Ответ: Класс С
127.0.0.1
|
0 |
1 |
1 |
1 |
1 |
1 |
1 |
1 |
|
128 |
64 |
32 |
16 |
8 |
4 |
2 |
1 |
Ответ: Класс А
112.0.0.15
|
0 |
1 |
1 |
1 |
0 |
0 |
0 |
0 |
|
128 |
64 |
32 |
16 |
8 |
4 |
2 |
1 |
Ответ: Класс А
167.58.13.21
|
1 |
0 |
1 |
0 |
0 |
1 |
1 |
1 |
|
128 |
64 |
32 |
16 |
8 |
4 |
2 |
1 |
Ответ: Класс В
Билет 33.
1. Объявление и реализация классов на языке Паскаль.
Для объявления классов (объектных типов) используется зарезервированное слово class. Определим некоторый класс графических примитивов TFigure следующим образом:
TFigure = class
fColor: Byte;
fThickness: Byte;
fCanvas: TCanvas;
procedure SetColor(Value: Byte);
procedure SetThickness(Value: Byte);
procedure PrepareCanvas;
end;
По принятому соглашению имена классов начинаются с заглавной буквы «T», имена полей данных начинаются с буквы «F», и поля класса объявляются до методов. Класс объединяет данные, представленные атрибутами (полями) и алгоритмы (методы) по их обработке.
В примере к полям данных класса относятся: поле fColor, хранящее код цвета, поле fThickness, задающее толщину линий и поле fCanvas, представляющее полотно, на котором будет происходить отображение графических примитивов.
Методы класса определяют действия, выполняемые над данными. Их совокупность характеризует функциональный аспект поведения класса. Методы представляют собой процедуры и функции, принадлежащие классу. К методам класса относится метод PrepareCanvas, выполняющий подготовку полотна к работе и два метода задания значений полей данных – SetColor и SetThickness.
Таким образом, в одной информационной структуре TFigure оказались объединены как исходные параметры, так и необходимые средства по выполнению их реализации. Такое объединение (сокрытие) данных и методов в качестве собственных ресурсов класса получило название инкапсуляции.
Для окончательного оформления шаблона требуется поместить класс в интерфейсный раздел модуля и дать реализацию всех методов:
unit figures;