

Основные принципы создания интерфейса
1. Естественность (интуитивность). Работа с системой не должна вызывать у пользователя сложностей в поиске необходимых директив (элементов интерфейса) для управления процессом решения поставленной задачи.
2. Непротиворечивость. Если в процессе работы с системой пользователем были использованы некоторые приемы работы с некоторой частью системы, то в другой части системы приемы работы должны быть идентичны. Также работа с системой через интерфейс должна соответствовать установленным, привычным нормам (например, использование клавиши Enter).
3. Неизбыточность. Это означает, что пользователь должен вводить только минимальную информацию для работы или управления системой. Например, пользователь не должен вводить незначимые цифры (00010 вместо 10). Аналогично, нельзя требовать от пользователя ввести информацию, которая была предварительно введена или которая может быть автоматически получена из системы. Желательно использовать значения по умолчанию где только возможно, чтобы минимизировать процесс ввода информации.
4. Непосредственный доступ к системе помощи. В процессе работы необходимо, чтобы система обеспечивала пользователя необходимыми инструкциями. Система помощи отвечает трем основным аспектам - качество и количество обеспечиваемых команд; характер сообщений об ошибках и подтверждения того, что система делает. Сообщения об ошибках должны быть полезны и понятны пользователю. Идеальное сообщение об ошибке должно отвечать всего на три вопроса:
в чем заключается проблема?
как исправить эту проблему сейчас?
как сделать так, чтобы проблема не повторилась?
При этом отвечать на эти вопросы нужно возможно более вежливым и понятным пользователям языком.
5. Гибкость. Интерфейс системы должен обслуживать пользователя с различными уровнями подготовки. Для неопытных пользователей интерфейс может быть организован как иерархическая структура меню, а для опытных пользователей как команды, комбинации нажатий клавиш и параметры.
Качество интерфейса – эргономический аспект
Качество определяется в ГОСТ Р ИСО/МЭК 9126-93 как «объем признаков и характеристик продукции или услуги, который относится к их способности удовлетворять установленным или предполагаемым потребностям». При комплексной оценке показателей качества программного продукта качество пользовательского интерфейса вносит определяющий вклад в такую субхарактеристику качества, как практичность (usability).
В качестве пользовательского интерфейса можно выделить два аспекта интерфейса: функциональный и эргономический. О качестве функциональности интерфейса трудно говорить безотносительно предметной области, например, сформулировать «руководящие принципы функциональности» пользовательского интерфейса. Формально его можно связать со степенью «соответствия задаче».
Поскольку интерфейс является физическим динамическим устройством, взаимодействующим с пользователем, то наряду с абстрактно-синтаксическим возникает и дополняющий его независимый эргономический аспект, который, в зачаточной форме и соответствует обычному текстовому объекту (размер шрифта, цветовое оформление, размер и толщина книги, защита от старения и разрушения, навигация по страницам и т.д.). В случае компьютерного интерфейса появляются новые особенности, связанные с комфортностью экранного представления, достаточной оперативностью реакции программного средства на действия пользователя, удобством манипулирования мышью и клавиатурой (и их скоростными показателями).
Нормативные требования по эргономике пользовательского интерфейса отличаются по своей природе от синтаксических и манипуляционных правил — они относятся к психофизиологическим свойствам конкретной реализации уже выбранного типа (стиля) пользовательского интерфейса (и соответствующего стандарта) в конкретном приложении. Эргономические аспекты пользовательского интерфейса приложения являются естественным расширением эргономики технических средств и рабочего места. Сегодня существует два подхода к оценке эргономического качества, которые можно отнести к методам «черного» и «белого ящика».
В первом подходе оценку производит конечный пользователь (или тестер), суммируя результаты работы с программой в рамках следующих показателей:
эффективности (effectiveness) - влияния интерфейса на полноту и точность достижения пользователем целевых результатов;
продуктивности (efficiency) или влияния интерфейса на производительность пользователя;
степени (субъективной) удовлетворенности (satisfaction) конечного пользователя этим интерфейсом.
Эффективность является критерием функциональности интерфейса, а степень удовлетворенности и, косвенно, продуктивность — критерием эргономичности. Вводимые здесь меры соответствуют общей прагматической концепции оценки качества по соотношению «цели/затраты».
Во втором подходе пытаются установить, каким (руководящим эргономическим) принципам должен удовлетворять пользовательский интерфейс с точки зрения оптимальности человеко-машинного взаимодействия. Развитие этого аналитического подхода было вызвано потребностями проектирования и разработки ПО, поскольку позволяет сформулировать руководящие указания по организации и характеристикам оптимального пользовательского интерфейса. Этот подход может быть использован и при оценке качества разработанного пользовательского интерфейса. В этом случае показатель качества оценивается экспертом по степени реализации руководящих принципов или вытекающих из них более конкретных графических и операционных особенностей оптимального «человеко-ориентированного» пользовательского интерфейса.
Таблица - Стандарты, затрагивающие эргономические принципы
|
Документ ISO |
Эргономические принципы |
|
ISO 9241-10-1996 Ergonomic requirements for office work with visual display terminals (VDTs). P. 10. Dialogue principles |
Обсуждение руководящих эргономических принципов: соответствие задаче, самоописательность, контролируемость, соответствие ожиданиям пользователя, толерантность к ошибкам, настраиваемость, изучаемость |
|
ISO/IEC 13407-1999 Designing user interfaces with humans in mind |
Обоснование, принципы, проектирование и реализация ориентированного на пользователя программного проекта |
|
ГОСТ Р ИСО/МЭК 12119-2000 Информационная технология. Пакеты программ. Требования к уровню качества и тестирование. |
Требования к практичности: понятность, обозримость, удобство использования |
|
ГОСТ Р ИСО/МЭК 9126-93 Информационная технология. Оценка программной продукции. Характеристики качества и руководства по их применению. |
Субхарактеристика практичность: понятность, обучаемость, простота, простота использования |
3. Указать к какому классу относится каждый из перечисленных IP
адресов:
192.168.0.15
127.0.0.1
112.0.0.15
167.58.13.21
Билет 9
1. Сети Петри. Моделирование процессов на основе сетей Петри.
Для моделирования производственных процессов широко применяют имитационные модели. Имитационные модели применяют, когда необходимо обеспечить наблюдение за ходом процесса в течение определенного временного периода (или когда невозможно применить аналитические модели математического программирования к решению задач управления). При построении имитационных моделей выбирают некоторые базовые единицы модели – объекты, или сущности. Это могу различные физические объекты, например, производственный участок, единица оборудования, деталь, узел и т.д. Объектам присваивают атрибуты. Фиксированные атрибуты описывают природу и характеристики объекта, переменные – состояние объекта. Состояние моделируемой системы описывается состояниями всех характеризующих ее объектов. Связи между объектами задаются атрибутами. Фиксированные атрибуты описывают статические, переменные – динамические связи. В зависимости от характера изменения атрибутов различают непрерывные и дискретные модели. В моделях дискретных событий выделяют набор работ. Такими работами, например, могут быть технологические операции по обработке деталей. Построение модели в этом случае состоит в логико-математическом описании соответствующих работ, событий и процессов.
Абстрактные автоматы
Абстрактные автоматы используют для описания объектов АСУ, для которых характерно наличие дискретных состояний и дискретный характер работы во времени. К числу таких объектов относятся элементы и узлы ЭВМ, устройства контроля и регулирования, системы коммутации, программы и операционные системы.
Абстрактный автомат можно представить видом:
, где
- конечное множество входных сигналов (входной алфавит автомата);
- конечное множество выходных сигналов (выходной алфавит автомата);
- выходное множество состояний автомата;
- начальное состояние автомата;
- функция переходов автомата,
- функция выходов или сдвинутая функция выходов.
Функции и задают однозначное отображение множества , где и в множества X и Y. Автомат, заданный функцией выходов, называется автоматом первого рода, автомат, заданный сдвинутой функцией выходов, - автоматом второго рода.
Абстрактный автомат функционирует в дискретном времени, принимающем целые неотрицательные значения В каждый момент времени автомат имеет определенное состояние из множества Z состояний автомата, причём в начальный момент времени автомат всегда находится в начальном состоянии , т.е. . В каждый момент времени , отличный от начального, автомат способен воспринимать входной сигнал - и выдавать соответствующий выходной сигнал. Закон функционирования абстрактного автомата первого рода задаётся уравнениями ;
Сети Петри
В абстрактном автомате рассматриваются последовательные переходы состояния. Поэтому такая модель неприменима для объектов, способных выполнять свои функции параллельно. Для моделирования таких объектов используют сети Петри. Сети Петри – это инструмент описания и исследования мультипрограммных, асинхронных, распределенных, параллельных, недетерминированных и/или стохастических систем обработки информации.
В качестве графического средства сети Петри могут использоваться для наглядного представления моделируемой системы, подобно блок-схемам, структурным схемам и сетевым графикам. Вводимое в этих сетях понятие фишек позволяет моделировать динамику функционирования систем и параллельные процессы. В качестве математического средства аналитическое представление сети Петри позволяет составлять уравнения состояния, алгебраические уравнения и другие математические соотношения, описывающие динамику систем.
Моделирование в сетях Петри осуществляется на событийном уровне. Определяются, какие действия происходят в системе, какие состояние предшествовали этим действиям и какие состояния примет система после выполнения действия. Выполнения событийной модели в сетях Петри описывает поведение системы. Анализ результатов выполнения может сказать о том, в каких состояниях пребывала или не пребывала система, какие состояния в принципе не достижимы. Однако такой анализ не дает числовых характеристик, определяющих состояние системы.
Простая Сеть Петри из трех элементов: множество мест, множество переходов и отношение инцидентности. Сети Петри имеют удобную графическую форму представления в виде графа, в котором места изображаются кружками, а переходы прямоугольниками. Места и переходы соединяются направленными дугами, каждой дуге сопоставляется некоторое натуральное число. Это число называется кратностью дуги, которое графически изображается рядом с дугой. Дуги, имеющие единичную кратность, обозначаются без приписывания единицы.
Само по себе понятие сети имеет статическую природу. Для задания динамических характеристик используется понятие маркировки сети. Графически маркировка изображается в виде точек, называемых метками (tokens), и располагающихся в кружках, соответствующих местам сети. Отсутствие меток в некотором месте говорит о нулевой маркировке этого места.
Сети Петри могут применяться:
1) Для моделирования бизнес-процессов. Функциональные диаграммы в нотации IDEF3 могут быть преобразованы в сеть Петри. Каждой работе на диаграмме соответствует переход сети Петри. Позиции соответствуют стрелкам, соединяющим работы напрямую и перекресткам. Метки соответствуют продукции, документов и т.д. Причем в зависимости от перехода интерпретация метки может отличаться.
2) Для моделирования параллельных вычислений и устройств. Если представить себе переход как процедуру, то она корректно выполняется при наличии значений всех своих аргументов и вырабатывает значения всех выходных переменных. В таком случае входные позиции перехода соответствуют аргументам, выходные – возвращаемым значениям. В другой интерпретации переход может представлять некоторое устройство. Устройство может (но не должно) сработать, если выполнились все входные условия.
3) Для моделирования процесса обучения. Тогда позиция соответствует некоторому состоянию процесса обучения, метка сопоставляется обучаемому, переход ассоциируется с изучением какой-либо темы обучаемым.
Сети Петри — математический аппарат для моделирования динамических дискретных систем. Впервые описаны Карлом Петри в 1962 году.
Сеть Петри представляет собой двудольный ориентированный граф, состоящий из вершин двух типов — позиций и переходов, соединённых между собой дугами, вершины одного типа не могут быть соединены непосредственно. В позициях могут размещаться метки (маркеры), способные перемещаться по сети.
Событием называют срабатывание перехода, при котором метки из входных позиций этого перехода перемещаются в выходные позиции. События происходят мгновенно, разновременно при выполнении некоторых условий.
Виды сетей Петри
Некоторые виды сетей Петри:
Временная сеть Петри — переходы обладают весом, определяющим продолжительность срабатывания (задержку).
Стохастическая сеть Петри — задержки являются случайными величинами.
Функциональная сеть Петри — задержки определяются как функции некоторых аргументов, например, количества меток в каких-либо позициях, состояния некоторых переходов.
Цветная сеть Петри — метки могут быть различных типов, обозначаемых цветами, тип метки может быть использован как аргумент в функциональных сетях.
Ингибиторная сети Петри — возможны ингибиторные дуги, запрещающие срабатывания перехода, если во входной позиции, связанной с переходом ингибиторной дугой находится метка.
Анализ сетей Петри
Основными свойствами сети Петри являются:
Ограниченность — число меток в любой позиции сети не может превысить некоторого значения K.
Безопасность — частный случай ограниченности, K=1.
Сохраняемость — постоянство загрузки ресурсов, постоянна. Где Ni — число маркеров в i-той позиции, Ai — весовой коэффициент.
Достижимость — возможность перехода сети из одного заданного состояния (характеризуемого распределением меток) в другое.
Живость — возможностью срабатывания любого перехода при функционировании моделируемого объекта.
В основе исследования перечисленных свойств лежит анализ достижимости.
Моделирование в сетях Петри осуществляется на событийном уровне. Определяются, какие действия происходят в системе, какие состояние предшествовали этим действиям и какие состояния примет система после выполнения действия. Выполнения событийной модели в сетях Петри описывает поведение системы. Анализ результатов выполнения может сказать о том, в каких состояниях пребывала или не пребывала система, какие состояния в принципе не достижимы. Однако, такой анализ не дает числовых характеристик, определяющих состояние системы. Развитие теории сетей Петри привело к появлению, так называемых, “цветных” сетей Петри. Понятие цветности в них тесно связано с понятиями переменных, типов данных, условий и других конструкций, более приближенных к языкам программирования. Несмотря на некоторые сходства между цветными сетями Петри и программами, они еще не применялись в качестве языка программирования.
Не смотря на описанные выше достоинства сетей Петри, неудобства применения сетей Петри в качестве языка программирования заключены в процессе их выполнения в вычислительной системе. В сетях Петри нет строго понятия процесса, который можно было бы выполнять на указанном процессоре. Нет также однозначной последовательности исполнения сети Петри, так как исходная теория представляет нам язык для описания параллельных процессов.
2. Нормализация таблиц при проектировании баз данных. Нормальные формы (1НФ, 2НФ, 3НФ, НФБК).
Реляционная база данных содержит как структурную, так и семантическую информацию. Структура базы данных определяется числом и видом включенных в нее отношений, и связями типа "один ко многим", существующими между кортежами этих отношений. Семантическая часть описывает множество функциональных зависимостей, существующих между атрибутами этих отношений. Дадим определение функциональной зависимости - Если даны два атрибута X и Y некоторого отношения, то говорят, что Y функционально зависит от X, если в любой момент времени каждому значению X соответствует ровно одно значение Y.
Функциональная зависимость обозначается X -> Y. Отметим, что X и Y могут представлять собой не только единичные атрибуты, но и группы, составленные из нескольких атрибутов одного отношения.
Можно сказать, что функциональные зависимости представляют собой связи типа "один ко многим", существующие внутри отношения.
Некоторые функциональные зависимости могут быть нежелательны.
Избыточная функциональная зависимость - зависимость, заключающая в себе такую информацию, которая может быть получена на основе других зависимостей, имеющихся в базе данных.
Корректной считается такая схема базы данных, в которой отсутствуют избыточные функциональные зависимости. В противном случае приходится прибегать к процедуре декомпозиции (разложения) имеющегося множества отношений. При этом порождаемое множество содержит большее число отношений, которые являются проекциями отношений исходного множества. Обратимый пошаговый процесс замены данной совокупности отношений другой схемой с устранением избыточных функциональных зависимостей называется нормализацией.
Условие обратимости требует, чтобы декомпозиция сохраняла эквивалентность схем при замене одной схемы на другую, т.е. в результирующих отношениях:
• не должны появляться ранее отсутствовавшие кортежи;
• на отношениях новой схемы должно выполняться исходное множество функциональных зависимостей.
1NF - первая нормальная форма.
Для обсуждения первой нормальной формы необходимо дать два определения:
Простой атрибут - атрибут, значения которого атомарны (неделимы).
Сложный атрибут - получается соединением нескольких атомарных атрибутов, которые могут быть определены на одном или разных доменах. (его также называют вектор или агрегат данных).
Теперь можно дать
Определение первой нормальной формы: отношение находится в 1NF если значения всех его атрибутов атомарны.
В базе данных отдела кадров предприятия необходимо хранить сведения о служащих, которые можно попытаться представить в отношении
СЛУЖАЩИЙ(НОМЕР_СЛУЖАЩЕГО, ИМЯ, ДАТА_РОЖДЕНИЯ, ИСТОРИЯ_РАБОТЫ, ДЕТИ).
Из внимательного рассмотрения этого отношения следует, что атрибуты "история_работы" и "дети" являются сложными, более того, атрибут "история_работы" включает еще один сложный атрибут "история_зарплаты".
Данные агрегаты выглядят следующим образом:
• ИСТОРИЯ_РАБОТЫ (ДАТА_ПРИЕМА, НАЗВАНИЕ, ИСТОРИЯ_ЗАРПЛАТЫ),
• ИСТОРИЯ_ЗАРПЛАТЫ (ДАТА_НАЗНАЧЕНИЯ, ЗАРПЛАТА),
• ДЕТИ (ИМЯ_РЕБЕНКА, ГОД_РОЖДЕНИЯ).
Их связь представлена на рис. 1.
Рис.1. Исходное отношение.
Для приведения исходного отношения СЛУЖАЩИЙ к первой нормальной форме необходимо декомпозировать его на четыре отношения, так как это показано на следующем рисунке:
Рис.2. Нормализованное множество отношений.
Здесь первичный ключ каждого отношения выделен синей рамкой, названия внешних ключей набраны шрифтом синего цвета. Напомним, что именно внешние ключи служат для представления функциональных зависимостей, существующих в исходном отношении. Эти функциональные зависимости обозначены линиями со стрелками.
Алгоритм нормализации описан Е.Ф.Коддом следующим образом:
• Начиная с отношения, находящегося на верху дерева (рис. 1.), берется его первичный ключ, и каждое непосредственно подчиненное отношение расширяется путем вставки домена или комбинации доменов этого первичного ключа.
• Первичный Ключ каждого расширенного таким образом отношения состоит из Первичного Ключа, который был у этого отношения до расширения и добавленного Первичного Ключа родительского отношения.
• После этого из родительского отношения вычеркиваются все непростые домены, удаляется верхний узел дерева, и эта же процедура повторяется для каждого из оставшихся поддеревьев.
2NF - вторая нормальная форма.
Очень часто первичный ключ отношения включает несколько атрибутов (в таком случае его называют составным) - см., например, отношение ДЕТИ, показанное на рис. 2. При этом вводится понятие полной функциональной зависимости.
Определение: неключевой атрибут функционально полно зависит от составного ключа если он функционально зависит от всего ключа в целом, но не находится в функциональной зависимости от какого-либо из входящих в него атрибутов.
Пример:
Пусть имеется отношение ПОСТАВКИ (N_ПОСТАВЩИКА, ТОВАР, ЦЕНА).
Поставщик может поставлять различные товары, а один и тот же товар может поставляться разными поставщиками. Тогда ключ отношения - "N_поставщика + товар". Пусть все поставщики поставляют товар по одной и той же цене. Тогда имеем следующие функциональные зависимости:
• N_поставщика, товар -> цена
• товар -> цена
Неполная функциональная зависимость атрибута "цена" от ключа приводит к следующей аномалии: при изменении цены товара необходим полный просмотр отношения для того, чтобы изменить все записи о его поставщиках. Данная аномалия является следствием того факта, что в одной структуре данных объединены два семантических факта. Следующее разложение дает отношения во 2НФ:
• ПОСТАВКИ (N_ПОСТАВЩИКА, ТОВАР)
• ЦЕНА_ТОВАРА (ТОВАР, ЦЕНА)
Определение второй нормальной формы:
Отношение находится во 2НФ, если оно находится в 1НФ и каждый неключевой атрибут функционально полно зависит от ключа.
3NF - третья нормальная форма.
Перед обсуждением третьей нормальной формы необходимо ввести понятие транзитивной функциональной зависимости.
Пусть X, Y, Z - три атрибута некоторого отношения. При этом X --> Y и Y --> Z, но обратное соответствие отсутствует, т.е. Z -/-> Y и Y -/-> X. Тогда Z транзитивно зависит от X.
Пусть имеется отношение ХРАНЕНИЕ (ФИРМА, СКЛАД, ОБЪЕМ), которое содержит информацию о фирмах, получающих товары со складов, и объемах этих складов. Ключевой атрибут - "фирма". Если каждая фирма может получать товар только с одного склада, то в данном отношении имеются следующие функциональные зависимости:
• фирма -> склад
• склад -> объем
При этом возникают аномалии:
• если в данный момент ни одна фирма не получает товар со склада, то в базу данных нельзя ввести данные о его объеме (т.к. не определен ключевой атрибут)
• если объем склада изменяется, необходим просмотр всего отношения и изменение кортежей для всех фирм, связанных с данным складом.
Для устранения этих аномалий необходимо декомпозировать исходное отношение на два:
• ХРАНЕНИЕ (ФИРМА, СКЛАД)
• ОБЪЕМ_СКЛАДА (СКЛАД, ОБЪЕМ)
Определение третьей нормальной формы:
Отношение находится в 3НФ, если оно находится во 2НФ и каждый неключевой атрибут нетранзитивно зависит от первичного ключа.
BCNF - нормальная форма Бойса-Кодда.
Эта нормальная форма вводит дополнительное ограничение по сравнению с 3НФ. Определение нормальной формы Бойса-Кодда:
Отношение находится в BCNF, если оно находится во 3НФ и в ней отсутствуют зависимости атрибутов первичного ключа от неключевых атрибутов.
Ситуация, когда отношение будет находится в 3NF, но не в BCNF, возникает при условии, что отношение имеет два (или более) возможных ключа, которые являются составными и имеют общий атрибут. Заметим, что на практике такая ситуация встречается достаточно редко, для всех прочих отношений 3NF и BCNF эквивалентны.
3. Составить программу, которая формирует очередь, добавляя в неё произвольное количество компонент.
|
uses SysUtils, Windows;
//Program Zadanie_10; //Uses Crt; Type TPtr = ^TElem; TElem = record Inf :Integer; Link:TPtr; end; Var Z,Value:Integer; Top_O, End_O:TPtr; Procedure Add_Z(Val:Integer); Var P:TPtr; Begin New(P); P^.Inf:=Val; P^.Link:=nil; if Top_O = nil Then Top_O:=P else End_O^.Link:=P; End_O:=P; End; Procedure Del_Z(var Val:Integer); Var P:TPtr; Begin Val:=Top_O^.Inf; P:=Top_O; Top_O:=P^.Link; if Top_O=nil Then End_O:=nil; Dispose(P); End; Begin //ClrScr; Writeln('Create OCHERED...'); Top_O:=nil; End_O:=nil;
|
Writeln('Ukagite deistvie:'); Writeln(' 1. Zapis v Ochered'); Writeln(' 2. Izvlechenie iz Ochered'); Writeln(' 3. Ochistka Ochered and print'); Writeln(' 4. EXIT'); Repeat Readln(Z);
If Z=1 Then Begin Writeln('Vvedite VALUE == '); Readln(Value); Add_Z(Value); End; If Z = 2 Then Begin Del_Z(Value); Writeln('Izvlechennoe VALUE == ',Value); End; If Z = 3 Then Begin While Top_O <> nil do Begin Del_Z(Value); Writeln('Izvlechennoe VALUE == ',Value); End; End; Until (Z=4); End. //begin { TODO -oUser -cConsole Main : Insert code here } //end.
|
Билет 10.
1. Понятие алгоритма. Интуитивное понятие алгоритма.
Слово алгоритм возникло от algorithm- латинской транслитерации имени великого математика IX века Мохаммеда ибн Муссы аль-Хорезми, который сформулировал правила выполнения четырех арифметических действий над многозначными числами.
Алгоритм - это организованная последовательность действий, понятных для некоторого исполнителя, ведущая к решению поставленной задачи.
Алгоритм - это конечная последовательность однозначных предписаний, исполнение которых позволяет с помощью конечного числа шагов получить решение задачи, однозначно определяемое исходными данными.
Алгоритм – понятное и точное предписание исполнителю совершить последовательность действий, направленных на достижение цели.
Алгоритм – это набор однозначно определённых шагов, выполняемых для решения задачи определённого класса.
Интуитивное определение неформально, поскольку отсутствуют формальные определения используемых в нем базовых понятий: элементарного шага, задач, классов задач. Кроме того, даже интуитивное определение элементарного шага основано на понятии алгоритма.
В 30 годы ХХ века в противовес классическим представлениям Альхарезми, возникла гипотеза об алгоритмически неразрешимости нескольких задач.
А) С точки зрения Геделя, алгоритм есть последовательность построения сложных математических функций из более простых, с использованием правил сформулированных на языках математической логики.
Можно ввести математическую абстракцию:
Пусть Х – совокупность входных данных, Y – совокупность выходных данных.
Y=f(X)
В) Черча. λ – исчисление или ввел понятие систем рекурсивно-вычислимых (РВ) функций. В этой системе было выделено 3 базовых функции и 3 оператора, посредством которых мы из базовых РВ функций строим более сложные РВ функции.
Алгоритм – способ определения РВ функции.
С) Алaна Тьюринга. Он предложил модель гипотетического вычислительного устройства (исполнителя). Алгоритм – программа для этого исполнителя.
D) Маркова. Основан на том, что какие бы ни были входные данные, они описываются определённым языком.
ВХОД – строка
ВЫХОД – строка
Алгоритм – набор правил подстановки одних символов вместо других.
Был также обоснован тезис Черча – Тьюринга. Различные подходы к формализации понятия алгоритма эквивалентны между собой с точки зрения понятия алгоритмической неразрешимости. С этой точки зрения, любой компьютер с Фон-неймановской архитектурой или другой ныне известной архитектурой, позволяет реализовать только те алгоритмы, которые можно реализовать на машине Тьюринга.
Свойства алгоритма:
Массовость - алгоритм должен быть применим для класса подобных задач.
Дискретность - алгоритм состоит из ряда дискретных шагов.
Определенность - каждый следующий шаг алгоритма однозначно определяется предыдущими шагами.
Результативность - алгоритм должен приводить к решению поставленной задачи за конечное число шагов
Понятность – алгоритм рассчитан на исполнителя, и должен быть сформулирован на понятном ему языке (СКИ – система команд исполнителя).
Каждый исполнитель алгоритма имеет свою систему команд (набор действий) и свою среду (набор объектов, над которыми совершаются действия), в которой, и только в ней, он работает.
Виды алгоритма:
Линейный - алгоритм, в котором все предписания (шаги) выполняются так, как записаны, без изменения порядка следования, строго друг за другом.
Разветвляющийся - алгоритм, в котором выполнение того или иного действия (шага) зависит от выполнения или не выполнения какого-либо условия.
Циклический - алгоритм, в котором некоторая последовательность действий повторяется несколько раз.
Способы записи алгоритма:
Словесно-формульное описание (на естественном языке с использованием математических формул).
Графическое описание в виде блок-схемы (набор связанных между собой геометрических фигур).
алгоритмический язык – система обозначений и правил для единообразной и точной записи алгоритмов и исполнения их.
Разработка алгоритмов.
Существует два подхода к разработке алгоритмов: операциональный и структурный.
Операциональный:
· минимум памяти;
· минимум операций.
операции:
· присваивание;
· арифметические;
· сравнение;
· условный и безусловный переход;
· вызов подпрограммы.
Каждый алгоритм можно представить в виде суперпозиции трех базовых алгоритмических структур: следование, ветвление, цикл. Такой подход позволяет осуществлять разработку алгоритмов, последовательно их детализируя. Сначала выделяется несколько крупных логических блоков (модулей), затем каждый из них последовательно детализируется до отдельных команд конкретного языка программирования. Кроме того, при таком подходе каждый модуль может реализовываться отдельным программистом, если предварительно разработан способ взаимосвязи между модулями.
2. Функции СУБД.
Более точно, к числу функций СУБД принято относить следующие:
2.1.1. Непосредственное управление данными во внешней памяти
Эта функция включает обеспечение необходимых структур внешней памяти как для хранения данных, непосредственно входящих в БД, так и для служебных целей, например, для убыстрения доступа к данным в некоторых случаях (обычно для этого используются индексы).
2.1.2. Управление буферами оперативной памяти
СУБД обычно работают с БД значительного размера; по крайней мере этот размер обычно существенно больше доступного объема оперативной памяти. Понятно, что если при обращении к любому элементу данных будет производиться обмен с внешней памятью, то вся система будет работать со скоростью устройства внешней памяти. Практически единственным способом реального увеличения этой скорости является буферизация данных в оперативной памяти.
2.1.3. Управление транзакциями
Транзакция - это последовательность операций над БД, рассматриваемых СУБД как единое целое. Либо транзакция успешно выполняется, и СУБД фиксирует (COMMIT) изменения БД, произведенные этой транзакцией, во внешней памяти, либо ни одно из этих изменений никак не отражается на состоянии БД. Понятие транзакции необходимо для поддержания логической целостности БД. Поддержание механизма транзакций является обязательным условием даже однопользовательских СУБД. Но понятие транзакции гораздо более важно в многопользовательских СУБД.
То свойство, что каждая транзакция начинается при целостном состоянии БД и оставляет это состояние целостным после своего завершения, делает очень удобным использование понятия транзакции как единицы активности пользователя по отношению к БД.
2.1.4. Журнализация
Одним из основных требований к СУБД является надежность хранения данных во внешней памяти. Под надежностью хранения понимается то, что СУБД должна быть в состоянии восстановить последнее согласованное состояние БД после любого аппаратного или программного сбоя. Обычно рассматриваются два возможных вида аппаратных сбоев: так называемые мягкие сбои, которые можно трактовать как внезапную остановку работы компьютера (например, аварийное выключение питания), и жесткие сбои, характеризуемые потерей информации на носителях внешней памяти. Примерами программных сбоев могут быть: аварийное завершение работы СУБД (по причине ошибки в программе или в результате некоторого аппаратного сбоя) или аварийное завершение пользовательской программы, в результате чего некоторая транзакция остается незавершенной. Первую ситуацию можно рассматривать как особый вид мягкого аппаратного сбоя; при возникновении последней требуется ликвидировать последствия только одной транзакции.
Понятно, что в любом случае для восстановления БД нужно располагать некоторой дополнительной информацией. Другими словами, поддержание надежности хранения данных в БД требует избыточности хранения данных, причем та часть данных, которая используется для восстановления, должна храниться особо надежно. Наиболее распространенным методом поддержания такой избыточной информации является ведение журнала изменений БД.
Журнал - это особая часть БД, недоступная пользователям СУБД и поддерживаемая с особой тщательностью (иногда поддерживаются две копии журнала, располагаемые на разных физических дисках), в которую поступают записи обо всех изменениях основной части БД. В разных СУБД изменения БД журнализуются на разных уровнях: иногда запись в журнале соответствует некоторой логической операции изменения БД (например, операции удаления строки из таблицы реляционной БД), иногда - минимальной внутренней операции модификации страницы внешней памяти; в некоторых системах одновременно используются оба подхода.
Во всех случаях придерживаются стратегии "упреждающей" записи в журнал (так называемого протокола Write Ahead Log - WAL). Грубо говоря, эта стратегия заключается в том, что запись об изменении любого объекта БД должна попасть во внешнюю память журнала раньше, чем измененный объект попадет во внешнюю память основной части БД. Известно, что если в СУБД корректно соблюдается протокол WAL, то с помощью журнала можно решить все проблемы восстановления БД после любого сбоя.
2.1.5. Поддержка языков БД
Для работы с базами данных используются специальные языки, в целом называемые языками баз данных. В ранних СУБД поддерживалось несколько специализированных по своим функциям языков. Чаще всего выделялись два языка - язык определения схемы БД (SDL - Schema Definition Language) и язык манипулирования данными (DML - Data Manipulation Language). SDL служил главным образом для определения логической структуры БД, т.е. той структуры БД, какой она представляется пользователям. DML содержал набор операторов манипулирования данными, т.е. операторов, позволяющих заносить данные в БД, удалять, модифицировать или выбирать существующие данные. Мы рассмотрим более подробно языки ранних СУБД в следующей лекции.
В современных СУБД обычно поддерживается единый интегрированный язык, содержащий все необходимые средства для работы с БД, начиная от ее создания, и обеспечивающий базовый пользовательский интерфейс с базами данных. Стандартным языком наиболее распространенных в настоящее время реляционных СУБД является язык SQL (Structured Query Language). Прежде всего, язык SQL сочетает средства SDL и DML, т.е. позволяет определять схему реляционной БД и манипулировать данными. При этом именование объектов БД (для реляционной БД - именование таблиц и их столбцов) поддерживается на языковом уровне в том смысле, что компилятор языка SQL производит преобразование имен объектов в их внутренние идентификаторы на основании специально поддерживаемых служебных таблиц-каталогов. Внутренняя часть СУБД (ядро) вообще не работает с именами таблиц и их столбцов.
Язык SQL содержит специальные средства определения ограничений целостности БД. Специальные операторы языка SQL позволяют определять так называемые представления БД, фактически являющиеся хранимыми в БД запросами (результатом любого запроса к реляционной БД является таблица) с именованными столбцами. Для пользователя представление является такой же таблицей, как любая базовая таблица, хранимая в БД, но с помощью представлений можно ограничить или наоборот расширить видимость БД для конкретного пользователя. Поддержание представлений производится также на языковом уровне.
3. Написать программу на языке С++ для реверса списка. Например: [1,2,3] [3,2,1].
#include <iostream.h>
void main()
{
int X[10],Y[10],N,j=1,i;
cout<<"\n Vvedite N (<10) ==";
cin>>N;
for(i=1;i<=N;i++)
{
cout<<"\n X["<<i<<"] ==";
cin>>X[i];
}
for(i=N;i>0;i--)
{
Y[j]=X[i];
j++;
}
for(i=1;i<=N;i++)
{
cout<<"\n X["<<i<<"] == "<<Y[i];
}
_getch();
}
Билет 11.
1. Структура данных типа СТЕК. Логическая структура стека. Машинное представление стека и реализация операций.
Стек - такой последовательный список с переменной длиной, включение и исключение элементов из которого выполняются только с одной стороны списка, называемого вершиной стека. Применяются и другие названия стека - магазин и очередь, функционирующая по принципу LIFO (Last - In - First- Out - "последним пришел - первым исключается"). Примеры стека: винтовочный патронный магазин, тупиковый железнодорожный разъезд для сортировки вагонов.
Основные операции над стеком - включение нового элемента (английское название push - заталкивать) и исключение элемента из стека (англ. pop - выскакивать).
Полезными могут быть также вспомогательные операции:
определение текущего числа элементов в стеке;
очистка стека;
неразрушающее чтение элемента из вершины стека, которое может быть реализовано, как комбинация основных операций:
x:=pop(stack); push(stack,x).
Некоторые авторы рассматривают также операции включения/исключения элементов для середины стека, однако структура, для которой возможны такие операции, не соответствует стеку по определению.
Для наглядности рассмотрим небольшой пример, демонстрирующий принцип включения элементов в стек и исключения элементов из стека. На рис. 4.1 (а,б,с) изображены состояния стека:
а). пустого;
б-г). после последовательного включения в него элементов с именами 'A', 'B', 'C';
д, е). после последовательного удаления из стека элементов 'C' и 'B';
ж). после включения в стек элемента 'D'.
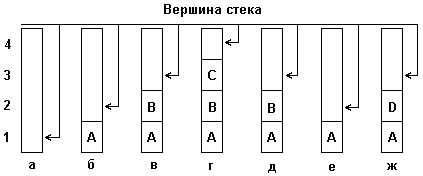
Машинное представление стека и реализация операций
При представлении стека в статической памяти для стека выделяется память, как для вектора. В дескрипторе этого вектора кроме обычных для вектора параметров должен находиться также указатель стека - адрес вершины стека. Указатель стека может указывать либо на первый свободный элемент стека, либо на последний записанный в стек элемент. (Все равно, какой из этих двух вариантов выбрать, важно в последствии строго придерживаться его при обработке стека.) В дальнейшем мы будем всегда считать, что указатель стека адресует первый свободный элемент и стек растет в сторону увеличения адресов.
При занесении элемента в стек элемент записывается на место, определяемое указателем стека, затем указатель модифицируется таким образом, чтобы он указывал на следующий свободный элемент (если указатель указывает на последний записанный элемент, то сначала модифицируется указатель, а затем производится запись элемента). Модификация указателя состоит в прибавлении к нему или в вычитании из него единицы (помните, что наш стек растет в сторону увеличения адресов.
Операция исключения элемента состоит в модификации указателя стека (в направлении, обратном модификации при включении) и выборке значения, на которое указывает указатель стека. После выборки слот, в котором размещался выбранный элемент, считается свободным.
Операция очистки стека сводится к записи в указатель стека начального значения - адреса начала выделенной области памяти.
Определение размера стека сводится к вычислению разности указателей: указателя стека и адреса начала области.
Программный модуль, представленный в примере 4.1, иллюстрирует операции над стеком, расширяющимся в сторону уменьшения адресов. Указатель стека всегда указывает на первый свободный элемент.
const SIZE = ...;
type data = ...;
{==== Программный пример 4.1 ====}
{ Стек }
unit Stack;
Interface
const SIZE=...; { предельный размер стека }
type data = ...; { эл-ты могут иметь любой тип }
Procedure StackInit;
Procedure StackClr;
Function StackPush(a : data) : boolean;
Function StackPop(Var a : data) : boolean;
Function StackSize : integer;
Implementation
Var StA : array[1..SIZE] of data; { Стек - данные }
{ Указатель на вершину стека, работает на префиксное вычитание }
top : integer;
Procedure StackInit; {** инициализация - на начало }
begin top:=SIZE; end; {** очистка = инициализация }
Procedure StackClr;
begin top:=SIZE; end;
{ ** занесение элемента в стек }
Function StackPush(a: data) : boolean;
begin
if top=0 then StackPush:=false
else begin { занесение, затем - увеличение указателя }
StA[top]:=a; top:=top-1; StackPush:=true;
end; end; { StackPush }
{ ** выборка элемента из стека }
Function StackPop(var a: data) : boolean;
begin
if top=SIZE then StackPop:=false
else begin { указатель увеличивается, затем - выборка }
top:=top+1; a:=StA[top]; StackPop:=true;
end; end; { StackPop }
Function StackSize : integer; {** определение размера }
begin StackSize:=SIZE-top; end;
END.
2. Принципы и виды отладки программного средства. Автономная отладка программного средства. Комплексная отладка программного средства.
Отладка ПС - это деятельность, направленная на обнаружение и исправление ошибок в ПС. Тестирование ПС - это процесс выполнения программ ПС на некотором наборе данных, для которого заранее известен результат применения или известны правила поведения этих программ. Указанный набор данных называется тестовым или просто тестом. Таким образом, отладку можно представить в виде многократного повторения трех процессов: тестирования, в результате которого может быть констатировано наличие в ПС ошибки, поиска места ошибки в программах и документации ПС и редактирования программ и документации с целью устранения обнаруженной ошибки. Другими словами:
Отладка = Тестирование + Поиск ошибок + Редактирование.
Принципы и виды отладки программного средства
Успех отладки ПС в значительной степени предопределяет рациональная организация тестирования. Тестирование не может доказать правильность ПС, в лучшем случае оно может продемонстрировать наличие в нем ошибки. Поэтому возникает две задачи. Первая задача: подготовить такой набор тестов, чтобы обнаружить в ПС по возможности большее число ошибок. Однако чем дольше продолжается процесс тестирования (и отладки в целом), тем большей становится стоимость ПС. Отсюда вторая задача: определить момент окончания отладки ПС (или отдельной его компоненты). Признаком возможности окончания отладки является полнота охвата пропущенными через ПС тестами (т.е. тестами, к которым применено ПС) множества различных ситуаций, возникающих при выполнении программ ПС, и относительно редкое проявление ошибок в ПС на последнем отрезке процесса тестирования. Последнее определяется в соответствии с требуемой степенью надежности ПС, указанной в спецификации его качества.
Для оптимизации набора тестов, т.е. для подготовки такого набора тестов, который позволял бы при заданном их числе (или при заданном интервале времени, отведенном на тестирование) обнаруживать большее число ошибок в ПС, необходимо, во-первых, заранее планировать этот набор и, во-вторых, использовать рациональную стратегию планирования (проектирования) тестов. Возможны разные подходы к выработке стратегии проектирования тестов, которые можно условно графически разместить между следующими двумя крайними подходами. Левый крайний подход заключается в том, что тесты проектируются только на основании изучения спецификаций ПС (внешнего описания, описания архитектуры и спецификации модулей). Строение модулей при этом никак не учитывается, т.е. они рассматриваются как черные ящики. Фактически такой подход требует полного перебора всех наборов входных данных, так как в противном случае некоторые участки программ ПС могут не работать при пропуске любого теста, а это значит, что содержащиеся в них ошибки не будут проявляться. Однако тестирование ПС полным множеством наборов входных данных практически неосуществимо. Правый крайний подход заключается в том, что тесты проектируются на основании изучения текстов программ с целью протестировать все пути выполнения каждой программ ПС. Если принять во внимание наличие в программах циклов с переменным числом повторений, то различных путей выполнения программ ПС может оказаться также чрезвычайно много, так что их тестирование также будет практически неосуществимо.
Оптимальная стратегия проектирования тестов расположена внутри интервала между этими крайними подходами, но ближе к левому краю. Она включает проектирование значительной части тестов по спецификациям, но она требует также проектирования некоторых тестов и по текстам программ. При этом в первом случае эта стратегия базируется на принципах:
• на каждую используемую функцию или возможность - хотя бы один тест,
• на каждую область и на каждую границу изменения какой-либо входной величины - хотя бы один тест,
• на каждую особую (исключительную) ситуацию, указанную в спецификациях, - хотя бы один тест.
Во втором случае эта стратегия базируется на принципе: каждая команда каждой программы ПС должна проработать хотя бы на одном тесте.
В нашей стране различаются два основных вида отладки (включая тестирование): автономную и комплексную отладку ПС.
Автономная отладка ПС означает последовательное раздельное тестирование различных частей программ, входящих в ПС, с поиском и исправлением в них фиксируемых при тестировании ошибок. Она фактически включает отладку каждого программного модуля и отладку сопряжения модулей. В процессе автономной отладки ПС производится наращивание тестируемой программы отлаженными модулями: при переходе к отладке следующего модуля в его программное окружение добавляется последний отлаженный модуль. Такой процесс наращивания программного окружения отлаженными модулями называется интеграцией программы.
При восходящем тестировании это окружение будет содержать только один отладочный модуль (кроме случая, когда отлаживается последний модуль отлаживаемой программы), который будет головным в тестируемой программе. Такой отладочный модуль называют ведущим (или драйвером). Ведущий отладочный модуль подготавливает информационную среду для тестирования отлаживаемого модуля (т. е. формирует ее состояние, требуемое для тестирования этого модуля, в частности, путем ввода некоторых тестовых данных), осуществляет обращение к отлаживаемому модулю и после окончания его работы выдает необходимые сообщения.
При нисходящем тестировании окружение отлаживаемого модуля в качестве отладочных модулей содержит отладочные имитаторы (заглушки) некоторых еще не отлаженных модулей. К таким модулям относятся, прежде всего, все модули, к которым может обращаться отлаживаемый модуль, а также еще не отлаженные модули, к которым могут обращаться уже отлаженные модули (включенные в это окружение). Некоторые из этих имитаторов при отладке одного модуля могут изменяться для разных тестов.
На практике в окружении отлаживаемого модуля могут содержаться отладочные модули обоих типов, если используется смешанная стратегия тестирования. Это связано с тем, что как восходящее, так и нисходящее тестирование имеет свои достоинства и свои недостатки.
К достоинствам восходящего тестирования относятся:
• простота подготовки тестов,
• возможность полной реализации плана тестирования модуля.
Это связано с тем, что тестовое состояние информационной среды готовится непосредственно перед обращением к отлаживаемому модулю (ведущим отладочным модулем).
Недостатками восходящего тестирования являются следующие его особенности:
• тестовые данные готовятся, как правило, не в той форме, которая рассчитана на пользователя (кроме случая, когда отлаживается последний, головной, модуль отлаживаемой программ);
• большой объем отладочного программирования (при отладке одного модуля приходится составлять много ведущих отладочных модулей, формирующих подходящее состояние информационной среды для разных тестов);
• необходимость специального тестирования сопряжения модулей.
• К достоинствам нисходящего тестирования относятся следующие его особенности:
• большинство тестов готовится в форме, рассчитанной на пользователя;
• во многих случаях относительно небольшой объем отладочного программирования (имитаторы модулей, как правило, весьма просты и каждый пригоден для большого числа, нередко - для всех, тестов);
• отпадает необходимость тестирования сопряжения модулей.
Недостатком нисходящего тестирования является то, что тестовое состояние информационной среды перед обращением к отлаживаемому модулю готовится косвенно - оно является результатом применения уже отлаженных модулей к тестовым данным или данным, выдаваемым имитаторами. Это, во-первых, затрудняет подготовку тестов и требует высокой квалификации тестовика (разработчика тестов), а во-вторых, делает затруднительным или даже невозможным реализацию полного плана тестирования отлаживаемого модуля. Указанный недостаток иногда вынуждает разработчиков применять восходящее тестирование даже в случае нисходящей разработки. Однако чаще применяют некоторые модификации нисходящего тестирования, либо некоторую комбинацию нисходящего и восходящего тестирования.
Часто применяют также комбинацию восходящего и нисходящего тестирования, которую называют методом сандвича. Сущность этого метода заключается в одновременном осуществлении как восходящего, так и нисходящего тестирования, пока эти два процесса тестирования не встретятся на каком-либо модуле где-то в середине структуры отлаживаемой программы. Этот метод при разумном порядке тестирования позволяет воспользоваться достоинствами как восходящего, так и нисходящего тестирования, а также в значительной степени нейтрализовать их недостатки.
Автономное тестирование модуля целесообразно осуществлять в четыре последовательно выполняемых шага.
• На основании спецификации отлаживаемого модуля подготовьте тесты для каждой возможности и каждой ситуации, для каждой границы областей допустимых значений всех входных данных, для каждой области изменения данных, для каждой области недопустимых значений всех входных данных и каждого недопустимого условия.
• Проверьте текст модуля, чтобы убедиться, что каждое направление любого разветвления будет пройдено хотя бы на одном тесте. Добавьте недостающие тесты.
• Проверьте текст модуля, чтобы убедиться, что для каждого цикла существуют тесты, обеспечивающие, по крайней мере, три следующие ситуации: тело цикла не выполняется ни разу, тело цикла выполняется один раз и тело цикла выполняется максимальное число раз. Добавьте недостающие тесты.
• Проверьте текст модуля, чтобы убедиться, что существуют тесты, проверяющие чувствительность к отдельным особым значениям входных данных. Добавьте недостающие тесты.
Комплексная отладка означает тестирование ПС в целом с поиском и исправлением фиксируемых при тестировании ошибок во всех документах (включая тексты программ ПС), относящихся к ПС в целом. К таким документам относятся определение требований к ПС, спецификация качества ПС, функциональная спецификация ПС, описание архитектуры ПС и тексты программ ПС. Тестирование этих документов производится, как правило, в порядке, обратном их разработке. Исключение составляет лишь тестирование документации по применению, которая разрабатывается по внешнему описанию параллельно с разработкой текстов программ - это тестирование лучше производить после завершения тестирования внешнего описания. Тестирование при комплексной отладке представляет собой применение ПС к конкретным данным, которые в принципе могут возникнуть у пользователя (в частности, все тесты готовятся в форме, рассчитанной на пользователя), но, возможно, в моделируемой (а не в реальной) среде. Например, некоторые недоступные при комплексной отладке устройства ввода и вывода могут быть заменены их программными имитаторами.
Тестирование архитектуры ПС. Целью тестирования является поиск несоответствия между описанием архитектуры и совокупностью программ ПС. К моменту начала тестирования архитектуры ПС должна быть уже закончена автономная отладка каждой подсистемы. Ошибки реализации архитектуры могут быть связаны, прежде всего, с взаимодействием этих подсистем, в частности, с реализацией архитектурных функций (если они есть). Поэтому хотелось бы проверить все пути взаимодействия между подсистемами ПС. При этом желательно хотя бы протестировать все цепочки выполнения подсистем без повторного вхождения последних. Если заданная архитектура представляет ПС в качестве малой системы из выделенных подсистем, то число таких цепочек будет вполне обозримо.
Тестирование внешних функций. Целью тестирования является поиск расхождений между функциональной спецификацией и совокупностью программ ПС. Несмотря на то, что все эти программы автономно уже отлажены, указанные расхождения могут быть, например, из-за несоответствия внутренних спецификаций программ и их модулей (на основании которых производилось автономное тестирование) функциональной спецификации ПС. Как правило, тестирование внешних функций производится так же, как и тестирование модулей на первом шаге, т.е. как черного ящика.
Тестирование качества ПС. Целью тестирования является поиск нарушений требований качества, сформулированных в спецификации качества ПС. Это наиболее трудный и наименее изученный вид тестирования. Ясно лишь, что далеко не каждый примитив качества ПС может быть испытан тестированием. Завершенность ПС проверяется уже при тестировании внешних функций. На данном этапе тестирование этого примитива качества может быть продолжено, если требуется получить какую-либо вероятностную оценку степени надежности ПС. Однако, методика такого тестирования еще требует своей разработки. Могут тестироваться такие примитивы качества, как точность, устойчивость, защищенность, временная эффективность, в какой-то мере - эффективность по памяти, эффективность по устройствам, расширяемость и, частично, независимость от устройств. Каждый из этих видов тестирования имеет свою специфику и заслуживает отдельного рассмотрения. Мы здесь ограничимся лишь их перечислением. Легкость применения ПС (критерий качества, включающий несколько примитивов качества) оценивается при тестировании документации по применению ПС.
Тестирование документации по применению ПС. Целью тестирования является поиск несогласованности документации по применению и совокупностью программ ПС, а также выявление неудобств, возникающих при применении ПС. Этот этап непосредственно предшествует подключению пользователя к завершению разработки ПС (тестированию определения требований к ПС и аттестации ПС), поэтому весьма важно разработчикам сначала самим воспользоваться ПС так, как это будет делать пользователь. Все тесты на этом этапе готовятся исключительно на основании только документации по применению ПС. Прежде всего, должны тестироваться возможности ПС как это делалось при тестировании внешних функций, но только на основании документации по применению. Должны быть протестированы все неясные места в документации, а также все примеры, использованные в документации. Далее тестируются наиболее трудные случаи применения ПС с целью обнаружить нарушение требований относительности легкости применения ПС.
Тестирование определения требований к ПС. Целью тестирования является выяснение, в какой мере ПС не соответствует предъявленному определению требований к нему. Особенность этого вида тестирования заключается в том, что его осуществляет организация-покупатель или организация-пользователь ПС как один из путей преодоления барьера между разработчиком и пользователем. Обычно это тестирование производится с помощью контрольных задач - типовых задач, для которых известен результат решения. В тех случаях, когда разрабатываемое ПС должно придти на смену другой версии ПС, которая решает хотя бы часть задач разрабатываемого ПС, тестирование производится путем решения общих задач с помощью как старого, так и нового ПС (с последующим сопоставлением полученных результатов). Иногда в качестве формы такого тестирования используют опытную эксплуатацию ПС - ограниченное применение нового ПС с анализом использования результатов в практической деятельности. По существу, этот вид тестирования во многом перекликается с испытанием ПС при его аттестации, но выполняется до аттестации, а иногда и вместо аттестации.
3. Дан массив типа word размерностью n. Найти сумму всех элементов, не прерывающих заданного m, далее вывести на экран.
|
program Project3; {$APPTYPE CONSOLE} uses SysUtils, Windows; //Program Zadanie_3; //Uses Crt; Const K = 100; Var N,i,M,S:Word; A:Array[1..K] of Word; Begin //ClrScr; Write('Number of elements array = '); Readln(N); If (N>0) and (N<100) Then Begin Writeln('Elements of array...');
|
For i:=1 To N Do Begin Write('A[',i,'] = '); Readln(a[i]); End; Write('Number M = '); Readln(M); S:=0; For i:=1 To N Do If (A[i]<=M) Then S:=S+A[i]; Writeln; Writeln('Summa of elements <= M == ',S); End Else Writeln('Uncorrectly number N'); Writeln('For exit press any key'); Readln; end.
|
Билет 12.
1. Сети Петри. Моделирование процессов на основе сетей Петри.
Для моделирования производственных процессов широко применяют имитационные модели. Имитационные модели применяют, когда необходимо обеспечить наблюдение за ходом процесса в течение определенного временного периода (или когда невозможно применить аналитические модели математического программирования к решению задач управления). При построении имитационных моделей выбирают некоторые базовые единицы модели – объекты, или сущности. Это могу различные физические объекты, например, производственный участок, единица оборудования, деталь, узел и т.д. Объектам присваивают атрибуты. Фиксированные атрибуты описывают природу и характеристики объекта, переменные – состояние объекта. Состояние моделируемой системы описывается состояниями всех характеризующих ее объектов. Связи между объектами задаются атрибутами. Фиксированные атрибуты описывают статические, переменные – динамические связи. В зависимости от характера изменения атрибутов различают непрерывные и дискретные модели. В моделях дискретных событий выделяют набор работ. Такими работами, например, могут быть технологические операции по обработке деталей. Построение модели в этом случае состоит в логико-математическом описании соответствующих работ, событий и процессов.
Абстрактные автоматы
Абстрактные автоматы используют для описания объектов АСУ, для которых характерно наличие дискретных состояний и дискретный характер работы во времени. К числу таких объектов относятся элементы и узлы ЭВМ, устройства контроля и регулирования, системы коммутации, программы и операционные системы.
Абстрактный автомат можно представить видом:
, где
- конечное множество входных сигналов (входной алфавит автомата);
- конечное множество выходных сигналов (выходной алфавит автомата);
- выходное множество состояний автомата;
- начальное состояние автомата;
- функция переходов автомата,
- функция выходов или сдвинутая функция выходов.
Функции и задают однозначное отображение множества , где и в множества X и Y. Автомат, заданный функцией выходов, называется автоматом первого рода, автомат, заданный сдвинутой функцией выходов, - автоматом второго рода.
Абстрактный автомат функционирует в дискретном времени, принимающем целые неотрицательные значения В каждый момент времени автомат имеет определенное состояние из множества Z состояний автомата, причём в начальный момент времени автомат всегда находится в начальном состоянии , т.е. . В каждый момент времени , отличный от начального, автомат способен воспринимать входной сигнал - и выдавать соответствующий выходной сигнал. Закон функционирования абстрактного автомата первого рода задаётся уравнениями ;
Сети Петри
В абстрактном автомате рассматриваются последовательные переходы состояния. Поэтому такая модель неприменима для объектов, способных выполнять свои функции параллельно. Для моделирования таких объектов используют сети Петри. Сети Петри – это инструмент описания и исследования мультипрограммных, асинхронных, распределенных, параллельных, недетерминированных и/или стохастических систем обработки информации.
В качестве графического средства сети Петри могут использоваться для наглядного представления моделируемой системы, подобно блок-схемам, структурным схемам и сетевым графикам. Вводимое в этих сетях понятие фишек позволяет моделировать динамику функционирования систем и параллельные процессы. В качестве математического средства аналитическое представление сети Петри позволяет составлять уравнения состояния, алгебраические уравнения и другие математические соотношения, описывающие динамику систем.
Моделирование в сетях Петри осуществляется на событийном уровне. Определяются, какие действия происходят в системе, какие состояние предшествовали этим действиям и какие состояния примет система после выполнения действия. Выполнения событийной модели в сетях Петри описывает поведение системы. Анализ результатов выполнения может сказать о том, в каких состояниях пребывала или не пребывала система, какие состояния в принципе не достижимы. Однако такой анализ не дает числовых характеристик, определяющих состояние системы.
Простая Сеть Петри из трех элементов: множество мест, множество переходов и отношение инцидентности. Сети Петри имеют удобную графическую форму представления в виде графа, в котором места изображаются кружками, а переходы прямоугольниками. Места и переходы соединяются направленными дугами, каждой дуге сопоставляется некоторое натуральное число. Это число называется кратностью дуги, которое графически изображается рядом с дугой. Дуги, имеющие единичную кратность, обозначаются без приписывания единицы.
Само по себе понятие сети имеет статическую природу. Для задания динамических характеристик используется понятие маркировки сети. Графически маркировка изображается в виде точек, называемых метками (tokens), и располагающихся в кружках, соответствующих местам сети. Отсутствие меток в некотором месте говорит о нулевой маркировке этого места.
Сети Петри могут применяться:
1) Для моделирования бизнес-процессов. Функциональные диаграммы в нотации IDEF3 могут быть преобразованы в сеть Петри. Каждой работе на диаграмме соответствует переход сети Петри. Позиции соответствуют стрелкам, соединяющим работы напрямую и перекресткам. Метки соответствуют продукции, документов и т.д. Причем в зависимости от перехода интерпретация метки может отличаться.
2) Для моделирования параллельных вычислений и устройств. Если представить себе переход как процедуру, то она корректно выполняется при наличии значений всех своих аргументов и вырабатывает значения всех выходных переменных. В таком случае входные позиции перехода соответствуют аргументам, выходные – возвращаемым значениям. В другой интерпретации переход может представлять некоторое устройство. Устройство может (но не должно) сработать, если выполнились все входные условия.
3) Для моделирования процесса обучения. Тогда позиция соответствует некоторому состоянию процесса обучения, метка сопоставляется обучаемому, переход ассоциируется с изучением какой-либо темы обучаемым.
Сети Петри — математический аппарат для моделирования динамических дискретных систем. Впервые описаны Карлом Петри в 1962 году.
Сеть Петри представляет собой двудольный ориентированный граф, состоящий из вершин двух типов — позиций и переходов, соединённых между собой дугами, вершины одного типа не могут быть соединены непосредственно. В позициях могут размещаться метки (маркеры), способные перемещаться по сети.
Событием называют срабатывание перехода, при котором метки из входных позиций этого перехода перемещаются в выходные позиции. События происходят мгновенно, разновременно при выполнении некоторых условий.
Виды сетей Петри
Некоторые виды сетей Петри:
Временная сеть Петри — переходы обладают весом, определяющим продолжительность срабатывания (задержку).
Стохастическая сеть Петри — задержки являются случайными величинами.
Функциональная сеть Петри — задержки определяются как функции некоторых аргументов, например, количества меток в каких-либо позициях, состояния некоторых переходов.
Цветная сеть Петри — метки могут быть различных типов, обозначаемых цветами, тип метки может быть использован как аргумент в функциональных сетях.
Ингибиторная сети Петри — возможны ингибиторные дуги, запрещающие срабатывания перехода, если во входной позиции, связанной с переходом ингибиторной дугой находится метка.
Анализ сетей Петри
Основными свойствами сети Петри являются:
Ограниченность — число меток в любой позиции сети не может превысить некоторого значения K.
Безопасность — частный случай ограниченности, K=1.
Сохраняемость — постоянство загрузки ресурсов, постоянна. Где Ni — число маркеров в i-той позиции, Ai — весовой коэффициент.
Достижимость — возможность перехода сети из одного заданного состояния (характеризуемого распределением меток) в другое.
Живость — возможностью срабатывания любого перехода при функционировании моделируемого объекта.
В основе исследования перечисленных свойств лежит анализ достижимости.
Моделирование в сетях Петри осуществляется на событийном уровне. Определяются, какие действия происходят в системе, какие состояние предшествовали этим действиям и какие состояния примет система после выполнения действия. Выполнения событийной модели в сетях Петри описывает поведение системы. Анализ результатов выполнения может сказать о том, в каких состояниях пребывала или не пребывала система, какие состояния в принципе не достижимы. Однако, такой анализ не дает числовых характеристик, определяющих состояние системы. Развитие теории сетей Петри привело к появлению, так называемых, “цветных” сетей Петри. Понятие цветности в них тесно связано с понятиями переменных, типов данных, условий и других конструкций, более приближенных к языкам программирования. Несмотря на некоторые сходства между цветными сетями Петри и программами, они еще не применялись в качестве языка программирования.
Не смотря на описанные выше достоинства сетей Петри, неудобства применения сетей Петри в качестве языка программирования заключены в процессе их выполнения в вычислительной системе. В сетях Петри нет строго понятия процесса, который можно было бы выполнять на указанном процессоре. Нет также однозначной последовательности исполнения сети Петри, так как исходная теория представляет нам язык для описания параллельных процессов.
2. Модели объектов проектирования .
ОБЪЕКТ инженерного проектирования - материальный объект искусственной природы, который должен быть создан для разрешения определенной проблемы, возникающей или выделенной в одном из фрагментов действительности. В машиностроении в качестве объекта инженерного проектирования выступают технологические операции определенных классов. Совокупность СВОЙСТВ объекта проектирования делится на внешние Y и внутренние Х свойства.
ВНЕШНИЕ свойства объекта проектирования разделяются на два подмножества:
- существенные (функциональные или свойства назначения) Yн, которые
подлежат непосредственной реализации при использовании объекта по прямому
назначению,
- утилитарные (нефункциональные) - Yу, присущие любому реальному
объекту (объем, масса, стоимость и др.).
Справедливо соотношение: Y = Yн U Yу.
ВНУТРЕННИЕ свойства проектирования характеризуют физический, химический и др.
процессы, а также техническую форму его реализации как принцип действия
данного объекта проектирования.
МОДЕЛЬ ОБЪЕКТА M(О) - приближенное описание какого-либо класса явлений,
выраженное с помощью математической символики.
Модели объектов проектирования классифицируют по ряду признаков:
-
3.
На языке С++ вычислить сумму ряда целых
чисел от 1 до n. #pragma
hdrstop //-------------------------------------------- #include
<iostream.h> void
main() { int
N,S=0,i; cout<<"\n
Vvedite N =="; cin>>N; for(i=1;i<=N;i++)
S=S+i; cout<<"\n
Summa =="<<S; }
- степени полноты отображения рассматриваемых сторон объекта,
- степени общности в отношении к объекту,
- пригодности для целей прогнозирования,
- назначению.
Кратко рассмотрим каждую из групп моделей.
А. По способу построения различают модели семиотические (знаковые) и
материальные (предметные ).
Семиотические модели предназначены для отображения с помощью знаков объектов
различной природы, свойств этих объектов, а также различных отношений между
объектами свойствами и значениями свойств.
Материальные (предметные) модели включают натурные (экспериментальные,
лабораторные, опытные образцы объектов); геометрически подобные
(пространственные макеты); физически подобные (модели, обладающие
механическим, кинематическим, динамическим и другими видами физического
подобия с объектом); предметно-математические (созданными с помощью ЭВМ).
Б. По степени полноты отображения (представления) объекта модели могут
быть полными - M(O); неполными (различной степени неполноты по содержанию или
объему) - M'(O), M"(O),..., Mn (O).
B. По степени общности в отношении к оригиналу выделяют модели описания M
o(O) (отображают характерные стороны объектов); модели-интерпретаторы M
i(O) (представляют отдельные объекты, входящие в состав некоторого класса
и учитывают особенности их частной реализации); модели - аналоги Ma
(O) (различные по форме представления, но равные между собой степени общности в
отношении оригинала).
Г. По характеру воспроизводимых сторон объекта проектирования выделяют
субстанциональные модели SbM(O) (характеризуют пространство возможных
состояний объекта, примеры: справочники, описания типовых проектных решений,
технологических операций); функциональные модели FnM(O) (в отличие от моделей
SbM(O) характеризуют объект только в аспекте определенных его отношений со
средой или другими объектами. Отображают поведение объекта, его
приспособленность к определенным воздействиям); структурные модели StrM(O)
(характеризуют внутреннюю организацию объектов); смешанные модели.
Д. По пригодности для целей прогнозирования модели относятся к пригодным
и непригодным.
Е. По назначению модели могут быть целевыми и продуктивными.
Целевые модели Mц(O) призваны в явной форме отображать цель создания,
назначение объекта проектирования.
Продуктивные модели Mпр(O), под ними понимается совокупность
технической документации на объект.
Билет 13.
1. Концепции информационного моделирования. Создание моделей на языке UML.
Моделирование имеет богатую историю во всех инженерных дисциплинах. Длительный опыт его использования позволил сформулировать четыре основных принципа.
Во-первых, выбор модели оказывает определяющее влияние на подход к решению проблемы и на то, как будет выглядеть это решение. Иначе говоря, подходите к выбору модели вдумчиво. Правильно выбранная модель высветит самые коварные проблемы разработки и позволит проникнуть в самую суть задачи, что при ином подходе было бы попросту невозможно. Неправильная модель заведет вас в тупик, поскольку внимание будет заостряться на несущественных вопросах.
Второй принцип формулируется так: каждая модель может быть воплощена с разной степенью абстракции
То же происходит и при моделировании программного обеспечения. Иногда простая и быстро созданная модель пользовательского интерфейса - самый подходящий вариант. В других случаях приходится работать на уровне битов, например когда вы специфицируете межсистемные интерфейсы или боретесь с узкими местами в сети. В любом случае лучшей моделью будет та, которая позволяет выбрать уровень детализации в зависимости от того, кто и с какой целью на нее смотрит. Для аналитика или конечного пользователя наибольший интерес представляет вопрос "что", а для разработчика - вопрос "как". В обоих случаях необходима возможность рассматривать систему на разных уровнях детализации в разное время.
Третий принцип: лучшие модели - те, что ближе к реальности
Возвращаясь к программному обеспечению, можно сказать, что "ахиллесова пята" структурного анализа - несоответствие принятой в нем модели и модели системного проекта. Если этот разрыв не будет устранен, то поведение созданной системы с течением времени начнет все больше отличаться от задуманного. При объектно-ориентированном подходе можно объединить все почти независимые представления системы в единое семантическое целое.
Четвертый принцип заключается в том, что нельзя ограничиваться созданием только одной модели. Наилучший подход при разработке любой нетривиальной системы - использовать совокупность нескольких моделей, почти независимых друг от друга.
Такой подход верен и в отношении объектно-ориентированных программных систем. Для понимания архитектуры подобной системы требуется несколько взаимодополняющих видов: вид с точки зрения прецедентов, или вариантов использования (чтобы выявить требования к системе), с точки зрения проектирования (чтобы построить словарь предметной области и области решения), с точки зрения процессов (чтобы смоделировать распределение процессов и потоков в системе), вид с точки зрения реализации, позволяющий рассмотреть физическую реализацию системы, и вид с точки зрения развертывания, помогающий сосредоточиться на вопросах системного проектирования. Каждый из перечисленных видов имеет множество структурных и поведенческих аспектов, которые в своей совокупности составляют детальный чертеж программной системы
Унифицированный язык моделирования (UML) является стандартным инструментом для создания "чертежей" программного обеспечения. С помощью UML можно визуализировать, специфицировать, конструировать и документировать артефакты программных систем.
UML пригоден для моделирования любых систем: от информационных систем масштаба предприятия до распределенных Web-приложений и даже встроенных систем реального времени. Это очень выразительный язык, позволяющий рассмотреть систему со всех точек зрения, имеющих отношение к ее разработке и последующему развертыванию. Несмотря на обилие выразительных возможностей, этот язык прост для понимания и использования. Изучение UML удобнее всего начать с его концептуальной модели, которая включает в себя три основных элемента: базовые строительные блоки, правила, определяющие, как эти блоки могут сочетаться между собой, и некоторые общие механизмы языка.
Несмотря на свои достоинства, UML - это всего лишь язык; он является одной из составляющих процесса разработки программного обеспечения, и не более того. Хотя UML не зависит от моделируемой реальности, лучше всего применять его, когда процесс моделирования основан на рассмотрении прецедентов использования, является итеративным и пошаговым, а сама система имеет четко выраженную архитектуру.
UML - это язык для визуализации, специфицирования, конструирования и документирования артефактов программных систем
Основные концепции.
Значение – это конечное обозначение, которое мы можем рассматривать как ответ или результат вычисления. Каждое значение имеет соответствующий тип. Мы можем рассматривать типы как наборы подобных значений.
Переменная – это сущность, имеющая имя, ячейка памяти, которая имеет специфическое значение и хранит его неизменным во время выполнения программы, пока она не получит другое значение.
Обычные программы состояли из переменных и инструкций для компьютера, чтобы ими управлять.
Реальный объект – это специфическая сущность, которую мы можем видеть, чувствовать или воспринимать любым другим образом и отличать от других объектов.
Моделируя реальный мир с помощью компьютерной программы, мы приходим к понятию компьютерного объекта (или просто объекта). Объект – это специфическая компьютерная сущность, которая существует в компьютерной памяти и может описывать реальный объект.
Моделирование – процесс создания модели чего-то; означает выделение важных значащих свойств, характеристик и отбрасывание всех неважных. Это отбрасывание называется абстрагированием.
Для формального описания качества свойства, мы должны ввести его обозначение. Каждый объект может быть охарактеризован его свойствами. Каждое из них имеет значение конкретного типа.
Некоторые свойства объекта могут никогда не изменять своего значения. Когда свойство объекта меняет значение, мы говорим, что объект меняет свое состояние.
Если и свойства, и их значения двух объектов одинаковы, то эти объекты неразличимы.
Так же, как каждое значение принадлежит к конкретному типу, каждый объект принадлежит к конкретному классу, который группирует схожие объекты. Класс – это абстрактное обозначение, на самом деле он не существует. Классы описывают свойства, которые должны иметь принадлежащие к ним объекты.
Объекты одного и того же класса имеют одинаковые свойства. Когда объект принадлежит конкретному классу, мы говорим, что объект – экземпляр этого класса. Для создания объекта необходимо точно определить класс и заполнить все свойства объекта, описанные в классе, значениями.
Объекты могут действовать, изменяя свое состояние или побуждая другие объекты к действию. Действия, совершаемые объектом, формализуются методом (функцией). Функции определяются для классов так же, как свойства, хотя они одинаковы для каждого объекта класса.
Объекты могут изменять свое состояние и влиять на другие объекты, вызывая их функции. Этот процесс можно рассматривать так: один объект отправляет сообщение другому, который его принимает и действует соответствующим образом.
2. Модели систем управления данными: сетевая, иерархическая, реляционная модель.
Организация структуры БД формируется исходя из следующих соображений:
1. Адекватность описываемому объекту/системе — на уровне концептуальной и логической модели.
2. Удобство использования для ведения учёта и анализа данных - на уровне так называемой физической модели.
Виды концептуальных и логических моделей БД — сетевая модель, иерархическая модель, реляционная модель (ER-модель), многомерная модель, объектная модель.
Таким образом, по виду модели БД разделяются на:
Иерархическая модель базы данных состоит из объектов с указателями от родительских объектов к потомкам, соединяя вместе связанную информацию.
Иерархические базы данных могут быть представлены как дерево, состоящее из объектов различных уровней. Верхний уровень занимает один объект, второй — объекты второго уровня и т. д.
Между объектами существуют связи, каждый объект может включать в себя несколько объектов более низкого уровня. Такие объекты находятся в отношении предка (объект более близкий к корню) к потомку (объект более низкого уровня), при этом возможно, когда объект-предок не имеет потомков или имеет их несколько, тогда как у объекта-потомка обязательно только один предок. Объекты, имеющие общего предка, называются близнецами.
Например, если иерархическая база данных содержала информацию о покупателях и их заказах, то будет существовать объект «покупатель» (родитель) и объект «заказ» (дочерний). Объект «покупатель» будет иметь указатели от каждого заказчика к физическому расположению заказов покупателя в объект «заказ».
В этой модели запрос, направленный вниз по иерархии, прост (например: какие заказы принадлежат этому покупателю); однако запрос, направленный вверх по иерархии, более сложен (например, какой покупатель поместил этот заказ). Также, трудно представить не-иерархические данные при использовании этой модели.
Иерархической базой данных является файловая система, состоящая из корневой директории, в которой имеется иерархия поддиректорий и файлов.
Реляционная база данных — база данных, основанная на реляционной модели. Слово «реляционный» происходит от английского «relation» (отношение[1]). Для работы с реляционными БД применяют Реляционные СУБД.
Теория реляционных баз данных была разработана доктором Коддом из компании IBM в 1970 году. В реляционных базах данных все данные представлены в виде простых таблиц, разбитых на строки и столбцы, на пересечении которых расположены данные. Запросы к таким таблицам возвращают таблицы, которые сами могут становиться предметом дальнейших запросов. Каждая база данных может включать несколько таблиц. Кратко особенности реляционной базы данных можно сформулировать следующим образом:
• Данные хранятся в таблицах, состоящих из столбцов ("атрибутов") и строк ("записей");
• На пересечении каждого столбца и строчки стоит в точности одно значение;
• У каждого столбца есть своё имя, которое служит его названием, и все значения в одном столбце имеют один тип.
• Запросы к базе данных возвращают результат в виде таблиц, которые тоже могут выступать как объект запросов.
Строки в реляционной базе данных неупорядочены - упорядочивание производится в момент формирования ответа на запрос.
Общепринятым стандартом языка работы с реляционными базами данных является язык SQL.
К основным понятиям сетевой модели базы данных относятся: уровень, элемент (узел), связь.
Узел — это совокупность атрибутов данных, описывающих некоторый объект. На схеме иерархического дерева узлы представляются вершинами графа. В сетевой структуре каждый элемент может быть связан с любым другим элементом.
Сетевые базы данных подобны иерархическим, за исключением того, что в них имеются указатели в обоих направлениях, которые соединяют родственную информацию.
Несмотря на то, что эта модель решает некоторые проблемы, связанные с иерархической моделью, выполнение простых запросов остается достаточно сложным процессом.
Также, поскольку логика процедуры выборки данных зависит от физической организации этих данных, то эта модель не является полностью независимой от приложения. Другими словами если необходимо изменить структуру данных, то нужно изменить и приложение.
3. Построить программу на языке С++ для работы со структурами – строками. Структура должна включать следующие поля: массив для хранения строки, его длину, время создания строки. Программа должна обеспечивать простейшие функции для работы с данными структуры: изменение строки, вывод строки, нахождение подстроки в строке.
|
unit Str_Stroka;
interface uses SysUtils; type TUserStr=class private fStroka:String; public fLen:Word; fDateCreate:String; Procedure InitStr(AStr:String); Function PrintStr:String; Function FindStr(AStr:String):Boolean; end; implementation
Procedure TUserStr.InitStr; Begin if AStr<>'' Then Begin fStroka:=AStr; fLen:=Length(AStr); fDateCreate:=DateToStr(Date); end; End;
Function TUserStr.PrintStr; Begin Result:=fStroka; End;
Function TUserStr.FindStr; Begin if Pos(AStr,fStroka)<> 0 Then Result:=True else Result:=False; End;
end.
|
program Zad_18;
{$APPTYPE CONSOLE}
uses SysUtils, Str_Stroka;
var UsStr:TUserStr; begin UsStr:=TUserStr.Create; UsStr.InitStr('Hello, WORLD!!!'); Writeln('Vvedena stroka =>> ',UsStr.PrintStr,' dlinoj =>> ',UsStr.fLen,' date: ',UsStr.fDateCreate); if UsStr.FindStr('WORLD') Then Writeln('Find podstroka <WORLD>') else writeln('Not Find podstroka <world>'); Readln; { TODO -oUser -cConsole Main : Insert code here } end. |
Билет 14.
1. Принципы создания компонент в визуальных средах разработки.
В настоящее время методы визуального компонентного проектирования находят очень широкое применение. Обусловлено это как значительным упрощением разработки программного обеспечения по сравнению с традиционным процедурным и объектно-ориентированным подходом, так и возможностью создавать функциональные завершенные, проблемно-ориентированные, многократно используемые компоненты и манипулировать ими в процессе проектирования. В данной главе будут рассмотрены возможности, которые открывает объектный подход для компонентной сборки программных систем в интегрированной среде Borland Delphi.
Создание компоненты начинается с формирования словаря задачи, т.е. выбора объектов предметной области, а также понятий и терминов, которыми они будут описываться, т.е. фактически всего того, с чем впоследствии придется работать. Результатом первого этапа является набор классов – абстракций предметной области, инкапсулирующих определенные черты и характеристики поведения реальных объектов. Чем выше уровень абстракции, тем для более широкого круга задач они могут быть применимы. Затем необходимо определить степень соседства созданных классов и с помощью обобщения сформировать иерархию классов наследования.
Эти две задачи относятся к невизуальным этапам проектирования. Для получения функционирующих программных объектов необходимо перейти от классов к их экземплярам. Внутреннее состояние объектов будет определяться изменением их атрибутов. Фактически в течение своей жизни объекты последовательно проходят через множество состояний, выполняя полезную для пользователя работу.
Благодаря принадлежности к одной иерархической системе, объекты полиморфны, и могут, в случае необходимости, подменять своих предков при выполнении тех или иных операций. Такие случаи мы уже рассматривали на примерах работы с иерархией классов наследования.
Собственно этим и заканчиваются возможности объектно-ориентированного подхода. Однако средства, предоставляемые интегрированной средой Borland Delphi, позволяют продвинуться значительные дальше – визуализировать классы и работать с объектами (называемыми теперь компонентами) в двух различных режимах – на этапе проектирования и на этапе исполнения. Для этого путем незначительной модификации созданных на первом этапе классов их можно зарегистрировать на палитре компонент.
3.1.1. Логическая организация и представление компонент
Откроем среду разработки Borland Delphi и посмотрим на доступные компоненты (рис. 3.1). Все компоненты логически сгруппированы по страницам. Например, на странице «Standard» расположены стандартные графические компоненты для создания элементов интерфейса пользователя, на странице «System» – общесистемные компоненты, на странице «Data Access» –компоненты доступа к базам данных. Для быстрого перехода с одной страницы палитры компонент на другую при большом их количестве откройте всплывающее меню на палитре с помощью неактивной клавише мыши и выберите нужную страницу.
Каждый компонент, находящийся на палитре компонент, по-прежнему является объектно-ориентированным классом. Однако для создания объектов данного класса нет необходимости в вызове конструкторов и инициализации полей данных. Среда разработки предоставляет чрезвычайно удобную возможность создания объектов путем простого перемещения выбранного компонента с палитры на форму проектирования.
В задачу инспектора объектов (Object Inspector) входит представление состояния выделенного на форме компонента. При переходе к другому компоненту содержимое инспектора автоматически обновляется. Такое поведение оказывается возможным благодаря механизму, предоставляющего информацию о типе времени выполнения (RTTI, Run-time Type Information). Информация RTTI обеспечивает предоставление сведений об объектах непосредственно во время их исполнения, а также необходима для обмена информацией между компонентами и графической средой разработки. Информацию о типе можно получить для любого исполняемого объекта. Она содержится в памяти и при необходимости может быть получена с помощью библиотеки времени выполнения (RTL, Run-time Library). Базовый класс TObject содержит методы для извлечения этой информации.
Все публикуемые свойства компонента (объявленные в разделе Published) доступны в инспекторе объектов для изменения на его первой вкладке «Properties». Второй составляющей любого класса являются его методы, т.е. действия, которые служат для изменения внутреннего состояния объектов. Конечно, доступ возможен только к методам, объявленным в разделе Public.
Компоненты обладают еще одной возможностью – способностью реагировать на внешние воздействия, например, системные события или действия пользователя. Для этого используются события компонент, которые также являются свойствами, но иного, процедурного типа данных. Для назначения событий компонент служит вторая вкладка «Events» инспектора объектов. На рис. 3.3 показаны обе странице инспектора объектов для компонента Button1.
При работе в режиме проектирования среда постоянно обеспечивает обратную связь с исходным текстом программы. При помещении компонент на форму, соответствующие объявления автоматически формируются в редакторе, и, наоборот, при удалении компонент эти объявления также удаляются.
2. Жизненный цикл программного обеспечения. Модели жизненного цикла ПО: каскадная, спиральная. Стадии, фазы работы жизненного цикла.
Жизненный цикл ИС можно представить как ряд событий, происходящих с системой в процессе ее создания и использования.
Модель ЖЦ отражает различные состояния системы, начиная с момента возникновения необходимости в данной ИС и заканчивая моментом ее полного выхода из употребления. Модель жизненного цикла - структура, содержащая процессы, действия и задачи, которые осуществляются в ходе разработки, функционирования и сопровождения программного продукта в течение всей жизни системы, от определения требований до завершения ее использования.
В настоящее время известны и используются следующие модели жизненного цикла:
• Каскадная модель предусматривает последовательное выполнение всех этапов проекта в строго фиксированном порядке. Переход на следующий этап означает полное завершение работ на предыдущем этапе.
Рис. Каскадная схема разработки ПО
• Поэтапная модель с промежуточным контролем. Разработка ИС ведется итерациями с циклами обратной связи между этапами. Межэтапные корректировки позволяют учитывать реально существующее взаимовлияние результатов разработки на различных этапах; время жизни каждого из этапов растягивается на весь период разработки.
• Спиральная модель. На каждом витке спирали выполняется создание очередной версии продукта, уточняются требования проекта, определяется его качество и планируются работы следующего витка. Особое внимание уделяется начальным этапам разработки - анализу и проектированию, где реализуемость тех или иных технических решений проверяется и обосновывается посредством создания прототипов (макетирования).
Рис. Спиральная модель ЖЦ
На практике наибольшее распространение получили две основные модели ЖЦ: каскадная и спиральная. Можно выделить следующие положительные стороны применения каскадного подхода:
• на каждом этапе формируется законченный набор проектной документации, отвечающий критериям полноты и согласованности;
• выполняемые в логической последовательности этапы работ позволяют планировать сроки завершения всех работ и соответствующие затраты.
Каскадный подход хорошо зарекомендовал себя при построении относительно простых ИС, когда в самом начале разработки можно достаточно точно и полно сформулировать все требования к системе. Основным недостатком этого подхода является то, что реальный процесс создания системы никогда полностью не укладывается в такую жесткую схему, постоянно возникает потребность в возврате к предыдущим этапам и уточнении или пересмотре ранее принятых решений.
Спиральная модель ЖЦ была предложена для преодоления перечисленных проблем. На этапах анализа и проектирования реализуемость технических решений и степень удовлетворения потребностей заказчика проверяется путем создания прототипов. Каждый виток спирали соответствует созданию работоспособного фрагмента или версии системы. Это позволяет уточнить требования, цели и характеристики проекта, определить качество разработки, спланировать работы следующего витка спирали. Таким образом, последовательно конкретизируются детали проекта и в результате выбирается обоснованный вариант, который удовлетворяет действительным требованиям заказчика и доводится до реализации.
Итеративная разработка отражает объективно существующий спиральный цикл создания сложных систем. Она позволяет переходить на следующий этап, не дожидаясь полного завершения работы на текущем и решить главную задачу - как можно быстрее показать пользователям системы работоспособный продукт, тем самым, активизируя процесс уточнения и дополнения требований. Основная проблема спирального цикла - определение момента перехода на следующий этап. Для ее решения вводятся временные ограничения на каждый из этапов жизненного цикла, и переход осуществляется в соответствии с планом, даже если не вся запланированная работа закончена. Планирование производится на основе статистических данных, полученных в предыдущих проектах, и личного опыта разработчиков.
В соответствии с базовым международным стандартом ISO/IEC 12207 все процессы ЖЦ ПО делятся на три группы:
• Основные процессы: приобретение, поставка, разработка, эксплуатация и сопровождение;
• Вспомогательные процессы: документирование, управление конфигурацией, обеспечение качества, разрешение проблем, аудит, аттестация, совместная оценка, верификация;
• Организационные процессы: создание инфраструктуры, управление, обучение, усовершенствование.
Традиционные этапы разработки программ.
Фаза разработки в жизненном цикле программы традиционно включает следующие этапы: анализ, проектирование, реализацию и тестирование.
Анализ
Фаза разработки в ЖЦ программы начинается с анализа, основная задача которого состоит в определении нужд пользователей предлагаемой системы. Если система должна быть продуктом общего назначения, продаваемым на рынке в условиях свободной конкуренции, анализ, вероятно, будет включать широкомасштабные исследования в целях определения потребностей потенциальных пользователей. Однако если система разрабатывается для нужд конкретного пользователя, исследования будут носить более целенаправленный характер.
По мере того как выясняются потребности потенциального пользователя, они преобразуются в ряд требований, которым должна удовлетворять новая система. Эти требования формулируются в терминах, принятых в сфере приложения, без использования специальной терминологии, принятой среди специалистов по обработке данных. После того как требования к создаваемой системе будут определены, их преобразуют в систему спецификаций, имеющих технически организованный вид.
Проектирование
В то время как анализ определяет, что должна делать предлагаемая система, проектирование определяет, как она будет выполнять эти задачи. Именно на этом этапе определяется структура системы программного обеспечения.
Наилучшей структурой для крупной системы ПО является модульная. Именно благодаря разбиению больших систем на модули становится возможной их практическая реализация. Без этого разбиения технические детали, необходимые при реализации большой системы, превысили бы возможности человеческого восприятия. При использовании модульной конструкции разработчик может ограничиться изучением только тех деталей, которые относятся к рассматриваемому модулю. Модульная конструкция также удобна при дальнейшем сопровождении программы, поскольку позволяет вносить изменения на модульной основе.
Реализация включает собственно написание программ, создание файлов данных и разработку баз данных.
Тестирование тесно связано с реализацией, так как каждый модуль системы, как правило, должен подвергаться тестированию как только он будет написан. В правильно сконструированной системе каждый модуль должен быть проверен либо независимо от других модулей, либо с использованием упрощенных версий других модулей, называемых заглушками. Назначение заглушек состоит в том, чтобы имитировать взаимодействие тестируемых модулей и остальной части системы. Аналогичным образом можно тестировать и систему в целом, по мере завершения создания отдельных модулей и их объединения в единое целое. К сожалению, этап тестирования и устранения обнаруженных в системе неполадок чрезвычайно сложно довести до успешного завершения. Опыт показывает, что большие системы ПО могут содержать множество ошибок даже после продолжительного тестирования.
ЖЦ ПО - это непрерывный процесс, который начинается с момента принятия решения о необходимости его создания и заканчивается в момент его полного изъятия из эксплуатации.
3. На языке С++ вычислить сумму ряда целых чисел от 1 до n.
#pragma hdrstop
//---------------------------------------------------------------------------
#include <iostream.h>
void main()
{
int N,S=0,i;
cout<<"\n Vvedite N ==";
cin>>N;
for(i=1;i<=N;i++) S=S+i;
cout<<"\n Summa =="<<S;
}
Билет 15.
1. Деревья. Основные определения. Логическое представление и изображение деревьев. Бинарные деревья. Машинное представление деревьев в памяти ЭВМ. Алгоритмы прохождения деревьев.
Дерево - это граф, который характеризуется следующими свойствами:
1. Cуществует единственный элемент (узел или вершина), на который не ссылается никакой другой элемент - и который называется КОРНЕМ (рис. 6.8, 6.9 - A,G,M - корни).
2. Начиная с корня и следуя по определенной цепочке указателей, содержащихся в элементах, можно осуществить доступ к любому элементу структуры.
3. На каждый элемент, кроме корня, имеется единственная ссылка, т.е. каждый элемент адресуется единственным указателем.
Название "дерево" проистекает из логической эквивалентности древовидной структуры абстрактному дереву в теории графов. Линия связи между парой узлов дерева называется обычно ВЕТВЬЮ. Те узлы, которые не ссылаются ни на какие другие узлы дерева, называются ЛИСТЬЯМИ (или терминальными вершинами)(рис. 6.8, 6.9 - b,k,l,h - листья). Узел, не являющийся листом или корнем, считается промежуточным или узлом ветвления (нетерминальной или внутренней вершиной).
Для ориентированного графа число ребер, исходящих из некоторой начальной вершины V, называется ПОЛУСТЕПЕНЬЮ ИСХОДА этой вершины. Число ребер, для которых вершина V является конечной, называется ПОЛУСТЕПЕНЬЮ ЗАХОДА вершины V, а сумма полустепеней исхода и захода вершины V называется ПОЛНОЙ СТЕПЕНЬЮ этой вершины.
рис. 6.8. Дерево
рис. 6.9. Лес
Ниже будет представлен важный класс орграфов - ориентированные деревья - и соответствующая им терминология. Деревья нужны для описания любой структуры с иерархией. Традиционные примеры таких структур: генеалогические деревья, десятичная классификация книг в библиотеках, иерархия должностей в организации, алгебраическое выражение, включающее операции, для которых предписаны определенные правила приоритета.
Ориентированное дерево - это такой ациклический орграф (ориентированный граф), у которого одна вершина, называемая корнем, имеет полустепень захода, равную 0, а остальные - полустепени захода, равные 1. Ориентированное дерево должно иметь по крайней мере одну вершину. Изолированная вершина также представляет собой ориентированное дерево.
Вершина ориентированного дерева, полустепень исхода которой равна нулю, называется КОНЦЕВОЙ (ВИСЯЧЕЙ) вершиной или ЛИСТОМ; все остальные вершины дерева называют вершинами ветвления. Длина пути от корня до некоторой вершины называется УРОВНЕМ (НОМЕРОМ ЯРУСА) этой вершины. Уровень корня ориентированного дерева равен нулю, а уровень любой другой вершины равен расстоянию (т.е. модулю разности номеров уровней вершин) между этой вершиной и корнем. Ориентированное дерево является ациклическим графом, все пути в нем элементарны.
Во многих приложениях относительный порядок следования вершин на каждом отдельном ярусе имеет определенное значение. При представлении дерева в ЭВМ такой порядок вводится автоматически, даже если он сам по себе произволен. Порядок следования вершин на некотором ярусе можно легко ввести, помечая одну вершину как первую, другую - как вторую и т.д. Вместо упорядочивания вершин можно задавать порядок на ребрах. Если в ориентированном дереве на каждом ярусе задан порядок следования вершин, то такое дерево называется УПОРЯДОЧЕННЫМ ДЕРЕВОМ.
Введем еще некоторые понятия, связанные с деревьями. На рис.6.10 показано дерево:
Узел X называется ПРЕДКОМ (или ОТЦОМ), а узлы Y и Z называются НАСЛЕДНИКАМИ (или СЫНОВЬЯМИ) их соответственно между собой называют БРАТЬЯМИ. Причем левый сын является старшим сыном, а правый - младшим. Число поддеревьев данной вершины называется СТЕПЕНЬЮ этой вершины. ( В данном примере X имеет 2 поддерева, следовательно СТЕПЕНЬ вершины X равна 2).
рис.6.10. Дерево
Если из дерева убрать корень и ребра, соединяющие корень с вершинами первого яруса, то получится некоторое множество несвязанных деревьев. Множество несвязанных деревьев называется ЛЕСОМ (рис. 6.9).
Логическое представление и изображение деревьев.
Имеется ряд способов графического изображения деревьев. Первый способ заключается в использовании для изображения поддеревьев известного метода диаграмм Венна, второй - метода вкладывающихся друг в друга скобок, третий способ - это способ, применяемый при составлении оглавлений книг. Последний способ, базирующийся на формате с нумерацией уровней, сходен с методами, используемыми в языках программирования. При применении этого формата каждой вершине приписывается числовой номер, который должен быть меньше номеров, приписанных корневым вершинам присоединенных к ней поддеревьев. Отметим, что корневые вершины всех поддереьев данной вершины должны иметь один и тот же номер.
МЕТОД ВЛОЖЕННЫХ СКОБОК
(V0(V1(V2(V5)(V6))(V3)(V4))(V7(V8)(V9(V10))))
Рис.6.11. Представление дерева : а)- исходное дерево, б)- оглавление книг, в)- граф, г)- диаграмма Венна
Все эти представления демонстрируют одну и ту же структуру и поэтому эквивалентны. С помощью графа можно наглядно представить разветвляющиеся связи, которые по понятным причинам привели к общеупотребительному термину "дерево".
Бинарные деревья.
Существуют m-арные деревья, т.е. такие деревья у которых полустепень исхода каждой вершины меньше или равна m (где m может быть равно 0,1,2,3 и т.д.). Если полустепень исхода каждой вершины в точности равна либо m, либо нулю, то такое дерево называется ПОЛНЫМ m-АРНЫМ ДЕРЕВОМ.
При m=2 такие деревья называются соответственно БИНАРНЫМИ, или ПОЛНЫМИ БИНАРНЫМИ.
На рисунке 6.12(a) изображено бинарное дерево, 6.12(b)- полное бинарное дерево, а на 6.12(c) показаны все четыре возможных расположения сыновей некоторой вершины бинарного дерева.

Рис. 6.13. Изображения бинарных деревьев
Машинное представление деревьев в памяти ЭВМ.
Деревья можно представлять с помощью связных списков и массивов (или последовательных списков).
Чаще всего используется связное представление деревьев, т.к. оно очень сильно напоминает логическое. Связное хранение состоит в том, что задается связь от отца к сыновьям. В бинарном дереве имеется два указателя, поэтому удобно узел представить в виде структуры:
LPTR DATA RPTR
где LPTR - указатель на левое поддерево, RPTR - указатель на правое поддерево, DATA - содержит информацию, связанную с вершиной.
Рассмотрим машинное представление бинарного дерева
 Логическое
представление дерева
Логическое
представление дерева
 Машинное связное
представление дерева
Машинное связное
представление дерева