

Interface
type
TFigure = class
fColor: Byte;
fThickness: Byte;
fCanvas: TCanvas;
procedure SetColor(Value: Byte);
procedure SetThickness(Value: Byte);
procedure PrepareCanvas;
end;
Implementation
procedure TFigure.SetColor(Value: Byte);
begin
if fColor <> Value then
fColor:=Color;
end;
procedure TFigure.SetThickness(Value: Byte);
begin
if fThickness <> Value then
fThickness:=Value;
end;
procedure TFigure.PrepareCanvas;
begin
{ Подготовка полотна для рисования }
end;
end.
Методы SetColor и SetThickness выполняют присвоение внутреннему полю fColor и fThickness значения в том случае, если текущее значение отличается от передаваемого. К полям класса никогда не следует обращаться напрямую, а только посредством специальных методов, обеспечивающих корректность выполнения операции присваивания.
Теперь объявим переменную f класса TFigure:
var
f: TFigure;
Переменную f называют экземпляром класса, объектной ссылкой или просто объектом. Через объект f возможен доступ к методам и полям класса. Однако для начала необходимо создать сам объект. Для этого необходимо вызвать специальную процедуру Create, называемую конструктором:
f:=TFigure.Create;
Конструктор не объявлен в классе TFigure, однако присутствует в нем благодаря наследованию от класса TObject. В результате будет выделена область памяти в размере, необходимом для хранения объекта f. Обратите внимание, конструктор вызывается с помощью ссылки на тип, а не на экземпляр типа, в отличие от методов, которые всегда вызываются с помощью ссылки на экземпляр. Связано это с тем, что объект f на момент вызова конструктора еще не создан.
После создания объекта с ним можно работать:
uses figures;
var
f: TCircle;
begin
f:=TCircle.Create;
f.SetColor($FF);
f.SetThickness(1);
f.PrepareCanvas;
f.Free;
end.
После выполнения методов объект f следует удалить, чтобы он не занимал места в памяти. Удаление выполняет метод Destroy, определенный в классе TObject, но лучше использовать Free, т.к. он инкапсулирует вызов Destroy: в начале определяется, существует ли объект и только затем выполняется вызов Destroy. В противном случае метод Free ничего не делает.
Класс Figure можно несколько модифицировать. Например, можно явно добавить к методам конструктор Create с помощью зарезервированного слова constructor и деструктор Destroy с помощью зарезервированного слова destructor:
TFigure = class
...
constructor Create; virtual;
destructor Destroy; override;
end;
В конструкторе присваиваются полям начальные значения и создается объект полотна:
constructor TFigure.Create;
begin
fColor:=$FF;
fThickness:=1;
fCanvas:=TCanvas.Create;
end;
В деструкторе обычно выполняются действия, связанные с освобождением задействованных в течение работы объекта ресурсов:
destructor TFigure.Destroy;
begin
{ Освобождение ресурсов, используемых в работе объекта }
fCanvas.Free;
end;
2. Архитектура клиент-сервер. Распределенные базы данных.
Архитектура клиент-сервер - архитектура распределенной вычислительной системы, в которой приложение делится на клиентский и серверный процессы.
Модель "сервер базы данных" - архитектура вычислительной сети типа "клиент-сервер", в которой пользовательский интерфейс и логика приложений сосредоточены на машине-клиенте, а информационные функции (функции СУБД) - на сервере. Обычно клиентский процесс посылает запрос серверу на языке SQL.
Распределенная база данных - совокупность баз данных, физически распределенная по взаимосвязанным ресурсам вычислительной сети и доступная для совместного использования.
Распределенная база данных - территориально распределенная совокупность локальных баз данных, объединенных согласованными принципами организации, комплектования и эксплуатации, а также каналами связи, и доступная для совместного использования.
(Чтоб понятнее был принцип: Распределенная система - система из нескольких взаимосвязанных компьютеров, способная решать единую прикладную задачу.
Н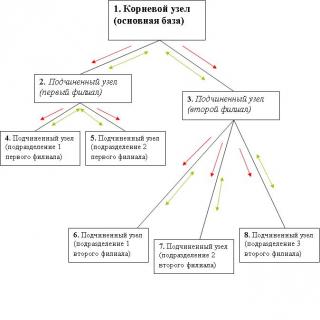 азначение
и принцип работы распределенной базы
данных
азначение
и принцип работы распределенной базы
данных
Когда у предприятия есть удаленные филиалы, возникает необходимость в синхронизации данных между ними и главным офисом. Естественно, что в основной базе предприятия должны отображаться любые изменения касательно филиалов. Такую синхронизацию можно осуществлять при помощи механизмов распределенной базы данных.
В главном офисе создаются начальные образы базы (для каждого филиала - свой образ) и передаются в филиалы, где их загружают. При этом задаются настройки обмена, по которым будет происходить синхронизация между каждой из периферийных (подчиненных) баз и главной базой.
Структура предприятия может быть такова, что у филиалов, подчиненных главному офису, могут быть свои удаленные подразделения. Тогда для них производят процедуру аналогичную той, что была совершена при настройке филиалов, подчиненных напрямую главной базе.
Таким образом, можно подытожить, что в распределенной базе формируются древообразные связи. Например, на предприятии главному офису подчинено два филиала, причем у первого филиала есть два удаленных подразделения, а у второго - три подразделения. Получается, что основной базе подчинено две периферийных базы. Первой периферийной базе, в свою очередь, подчинено еще две базы, а второй периферийной - три. То есть можно представить связи в такой распределенной базе следующим образом:
Схема распределенной базы для нашего примера
Узел 1 является корневым для всей распределенной базы и главным узлом для подчиненных ему второму и третьему. Второй узел является главным узлом для подчиненных ему четвертому и пятому. Третий узел будет главным для подчиненных ему шестому, седьмому и восьмому.
• Любой узел распределенной базы данных (УРБД) "видит" только узлы, напрямую связанные с ним. С такими узлами он и осуществляет обмен данными.
• Внесение изменений в данные информационной базы возможно в любом узле УРБД, причем изменения данных передаются между любыми связанными узлами. На схеме направления, по которым передаются изменения данных, обозначены зелеными стрелочками (по ним из любого узла УРБД за определенное количество шагов можно попасть в любой другой узел, отсюда следует, что при внесении изменений в данные любого узла эти изменения постепенно перенесутся во все остальные).
• Внесение изменений в конфигурацию информационной базы возможно только в одном (корневом) узле УРБД, причем изменения конфигурации передаются от главного узла к подчиненным. На схеме направления, по которым передаются изменения конфигурации, обозначены красными стрелочками.
3. Занести в BL наименьшее число из отрезка от 2 до К на которое не делится число N , при условии что 2K<N.
program Project1;
{$APPTYPE CONSOLE}
uses
SysUtils,
Windows;
//Program Zadanie_1;
//Uses Crt;
Var K:Byte;
Function Otrezok (X:Integer):Integer;
Begin
asm
{находим значение N и сохраняем его в AX}
MOV CX,2
MOV AX,5
MUL CX
{сохраняем в BX значение N}
MOV BX,AX
{задаем начальное значение делителя}
MOV CX,1
@1:
INC CX
MOV AX,BX
{проверка, не вышли ли за границы отрезка 2..K}
CMP CX,x
JG @2
{делим регистр AX на CX}
DIV CX
{проверяем остаток от DX}
CMP DX,0
{если поделено нацело, отправляемся по метке 1}
JZ @1
{нацело не поделилось, нашли значение на отрезке = CX и выход из процедуры}
// MOV @Result,CX
JMP @3
@2:
MOV CX,0
// MOV @Result,CX
@3:
end;
End;
Begin
//ClrScr;
Write('Vvedite K == ');
Readln(K);
Writeln('RESULT => ',Otrezok(K));
Readln;
end.
//begin
{ TODO -oUser -cConsole Main : Insert code here }
//end.
Билет 34.
1. Характеристики транспортного и прикладного уровней стека протоколов TCP/IP.
TCP/IP - аббревиатура термина Transmission Control Protocol/Internet Protocol (Протокол управления передачей/Интернет Протокол) - это согласованный заранее стандарт, служащий для обмена данных между двумя узлами(компьютерами в сети), причём неважно, на какой платформе эти компьютеры и какая между ними сеть. TCP/IP служит как мост, соединяющий все узлы сети воедино, за это он и завоевал свою популярность. TCP/IP зародился в результате исследований, профинансированных ARPA (Advanced Research Project Agency) - специальным отделением правительства США в 1970-х годах. Он был задуман, как общий стандарт, который объединит все сети в единую виртуальную "сеть сетей"(internetwork). Таким образом был создан Интернет, в результате преобразования существующего конгломерата вычислительных сетей, носивших название ARPAnet, с помощью TCP/IP. Название "TCP/IP" связано с двумя протоколами: TCP и IP. Но TCP/IP - это не только эти два протокола. Это целое семейство протоколов, объединенное под одним началом - IP-протоколом. В это семейство входят протоколы, которые взаимодействуют с протоколом IP и с его помощью строят свои каналы данных. Это сам TCP, а также UDP, ICMP, telnet, SMTP, FTP и многие другие.
Структура стека TCP/IP
|
Уровень I |
Прикладной уровень |
|
Уровень II |
Основной (транспортный) уровень |
|
Уровень III |
Уровень межсетевого взаимодействия |
|
Уровень IV |
Уровень сетевых интерфейсов |
Транспортный уровень – Основной
Поскольку на сетевом уровне не устанавливается соединение, то нет никаких гарантий того, что все пакеты будут доставлены в место назначения целыми и невредимыми или придут в том же порядке, в котором они были отправлены. Эту задачу - обеспечение надежности информационной связи между двумя конечными узлами - решает основной уровень стека TCP/IP, называемый также транспортным. На этом уровне функционируют протокол управления передачей TCP и протокол дейтаграмм пользователя UDP. Протокол TCP обеспечивает надежную передачу сообщений между удаленными прикладными процессами за счет образования логических соединений. Этот протокол позволяет равноранговым объектам на компьютере-отправителе и на компьютере-получателе поддерживать обмен данными в дуплексном режиме. TCP позволяет без ошибок доставлять сформированный на одном из компьютеров поток байт в любой другой компьютер, входящий в составную сеть. TCP делит поток байт на части - сегменты и передает их нижележащему уровню межсетевого взаимодействия. После того, как эти сегменты будут доставлены в пункт назначения, протокол TCP снова соберет их в непрерывный поток байт. Протокол UDP обеспечивает передачу прикладных пакетов дейтаграммным способом, как и главный протокол уровня межсетевого взаимодействия IP, и выполняет только функции связующего звена (мультиплексора) между сетевым протоколом и многочисленными системами прикладного уровня, или пользовательскими процессами.
Прикладной уровень
Прикладной уровень объединяет все службы, представляемые системой пользовательским приложениям. За долгие годы использования в сетях различных стран и организаций стек TCP/IP накопил большое число протоколов и служб прикладного уровня. Прикладной уровень реализуется программными системами, построенными в архитектуре клиент-сервер, базирующейся на протоколах нижних уровней. В отличие от протоколов остальных трех уровней, протоколы прикладного уровня занимаются деталями конкретного приложения и "не интересуются" способами передачи данных по сети. Этот уровень постоянно расширяется за счет присоединения к старым, прошедшим многолетнюю эксплуатацию сетевым службам типа Telnet, FTP, TFTP, DNS, SNMP, сравнительно новых служб, таких, например, как протокол передачи гипертекстовой информации HTTP.
2. Вычислительные методы решения задач на ЭВМ. Приближения функций. Интерполяция и Метод наименьших квадратов.
Под вычислительными методами будем понимать методы, которые используются в вычислительной математике для преобразования задач к виду, удобному для реализации на ЭВМ.
Задача приближения (аппроксимации) функций заключается в том, чтобы для данной функции построить другую, отличную от нее функцию, значения которой достаточно близки к значениям данной функции.
Приближение и интерполирование функций, раздел теории функций, посвященный изучению вопросов приближённого представления функций.
Приближение функций — нахождение для данной функции f функции g из некоторого определённого класса (например, среди алгебраических многочленов заданной степени), в том или ином смысле близкой к f, дающей её приближённое представление. Существует много разных вариантов задачи о приближении функций в зависимости от того, какие функции используются для приближения, как ищется приближающая функция g, как понимается близость функций f и g. Интерполирование функций — частный случай задачи приближения, когда требуется, чтобы в определённых точках (узлах интерполирования) совпадали значения функции f и приближающей её функции g, а в более общем случае — и значения некоторых их производных.
Метод наименьших квадратов — один из методов регрессионного анализа для оценки неизвестных величин по результатам измерений, содержащих случайные ошибки.
Метод наименьших квадратов применяется также для приближённого представления заданной функции другими (более простыми) функциями и часто оказывается полезным при обработке наблюдений.
Когда искомая величина может быть измерена непосредственно, как, например, длина отрезка или угол, то, для увеличения точности, измерение производится много раз, и за окончательный результат берут арифметическое среднее из всех отдельных измерений. Это правило арифметической середины основывается на соображениях теории вероятностей; легко показать, что сумма квадратов уклонений отдельных измерений от арифметической середины будет меньше, чем сумма квадратов уклонений отдельных измерений от какой бы то ни было другой величины. Само правило арифметической середины представляет, следовательно, простейший случай метода наименьших квадратов.
3. Построить программу на языке С++ для работы со структурами – строками. Структура должна включать следующие поля: массив для хранения строки, его длину, время создания строки. Программа должна обеспечивать простейшие функции для работы с данными структуры: изменение строки, вывод строки, нахождение подстроки в строке.
|
unit Str_Stroka;
interface uses SysUtils; type TUserStr=class private fStroka:String; public fLen:Word; fDateCreate:String; Procedure InitStr(AStr:String); Function PrintStr:String; Function FindStr(AStr:String):Boolean; end; implementation
Procedure TUserStr.InitStr; Begin if AStr<>'' Then Begin fStroka:=AStr; fLen:=Length(AStr); fDateCreate:=DateToStr(Date); end; End;
Function TUserStr.PrintStr; Begin Result:=fStroka; End;
Function TUserStr.FindStr; Begin if Pos(AStr,fStroka)<> 0 Then Result:=True else Result:=False; End;
end.
|
program Zad_18;
{$APPTYPE CONSOLE}
uses SysUtils, Str_Stroka;
var UsStr:TUserStr; begin UsStr:=TUserStr.Create; UsStr.InitStr('Hello, WORLD!!!'); Writeln('Vvedena stroka =>> ',UsStr.PrintStr,' dlinoj =>> ',UsStr.fLen,' date: ',UsStr.fDateCreate); if UsStr.FindStr('WORLD') Then Writeln('Find podstroka <WORLD>') else writeln('Not Find podstroka <world>'); Readln; { TODO -oUser -cConsole Main : Insert code here } end. |
Билет 35.
1. Компоненты и интерфейсы. Диаграммы физического уровня.
Компонента реализуют некоторый набор действий, и служит для общего обозначения элементов физического представления модели. Изображение в UML позволяет визуализировать компоненту без привязки к операционной системе или алгоритмическому языку с помощью специального символа (рис. 1.29 а).
Поскольку конкретная реализация логического представления зависит от используемых инструментальных средств, то и имена компонентов будут определяться особенностями синтаксиса соответствующего языка. В отдельных случаях к простому имени компонента может быть добавлено имя объемлющего пакета и версии реализации данного компонента (рис. 1.29 б).
Компоненты зачастую воспринимаются как двоичные исполняемые EXE-файлы, но могут быть частью системы, которая не является непосредственно исполняемым модулем (например, файлом исходного текста программы, файлом данных, динамически компонуемой библиотекой DLL или хранимой процедурой базы данных). Механизмы расширения, принятые в UML, расширяют как свойства компонент, так и определяют новые стереотипы. Базовый набор включает несколько элементов (табл. 1.1), общепринятая нотация их представлена на рис. 1.30. Все виды компонент именуют артефактами, подчеркивая их законченное информационное содержание.
Табл. 1.1. Разновидности компонент.
|
Разновидность компонента |
Описание |
|
исполнимый (executable) |
программный модуль, исполняющийся в узле |
|
библиотека (library) |
динамическая или статическая библиотека |
|
таблица (table) |
таблицы базы данных |
|
файл (file) |
файлы с исходными текстами |
|
документ (document) |
текстовый документ |
Рис. 1.30. Условное изображение базовых стереотипов компонента в UML.
Наличие интерфейсов у компоненты означает, что компонента реализует соответствующий набор интерфейсов. Если компонента реализует некоторый интерфейс, то такой интерфейс называют экспортируемым, поскольку компонента предоставляет его в качестве сервиса другим компонентам. Если компонента использует некоторый интерфейс, который реализуется другим компонентом, то такой интерфейс для первой компоненты называется импортируемым.
Приведем основные характеристики компонент:
компонента представляет независимо развертываемый программный блок (компонента никогда не развертывается частично);
компонента может служить строительным блоком для стороннего разработчика (компонента в достаточной мере документирована и самодостаточна, чтобы сторонний разработчик мог встроить ее в другие компоненты);
компонента – заменяемая часть системы, т.е. ее можно заменить другой компонентой, которая согласуется с тем же интерфейсом;
компонента выполняет четко определенную функцию и с логической и с физической точки зрения образует единое целое;
компонента может быть вложена в другие компоненты.
Сравним компоненту с пакетами и классами. Пакет – логическая часть системы. На логическом уровне каждый класс принадлежит одному пакету. На физическом уровне каждый класс реализуется, по крайней мере, одной компонентой, а компонента, возможно, реализует только один класс. Пакеты группируют классы по горизонтали за счет статической близости классов, принадлежащих одной проблемной области. Компоненты – вертикальные группы классов с близким поведением. Они могут принадлежать разным проблемным областям. Свойство ортогональности пакетов и компонент затрудняет установление зависимостей между ними. Зачастую один логический пакет зависит от нескольких физических компонент.
Подобно классам компоненты реализуют интерфейсы. Однако существует разница. Во-первых, компонента – физическая абстракция, развертываемая на некотором компьютерном узле. Класс представляет логическую сущность, которая для того чтобы действовать в качестве физической абстракции, должна быть реализована с помощью компоненты. Во-вторых, компонента делает доступным только некоторые интерфейсы содержащихся в ней классов. Другие инкапсулированные интерфейсы используются только внутри компонента другими классами.
Диаграмма компонентов
Диаграмма компонентов позволяет установить зависимости между компонентами, в роли которых может выступать исходный, объектный и исполняемый код. Основными элементами диаграммы являются компоненты, интерфейсы, отношения зависимости и реализации. Зависимости отражают наличие в независимом компоненте описаний классов, которые используются в зависимом компоненте для создания соответствующих объектов. Зависимости связывают различные виды компонентов, а также компоненты и импортируемые компонентом интерфейсы между собой.
Другим вариантом зависимости является отношение между различными видами компонент. Наличие подобной зависимости означает, что внесение изменений в исходные тексты программ или динамические библиотеки приводит к изменениям самого компонента
Диаграмма развертывания
Диаграмма развертывания применяется для представления общей конфигурации и топологии распределенной системы и содержит распределение компонентов по отдельным узлам. Все элементы, предназначенные для визуализации на диаграмме, существуют только на этапе исполнения, поэтому представляют компоненты-экземпляры, являющиеся исполняемыми файлами или динамическими библиотеками.
Диаграмма содержит графические изображения процессоров, периферийных устройств и связей между ними. В отличие от диаграмм логического представления, диаграмма развертывания является единой для системы в целом, поскольку всецело отражает особенности ее реализации и фактически завершает процесс объектно-ориентированного анализа и проектирования.
Диаграмма развертывания позволяет:
определить распределение компонентов системы по ее физическим узлам;
показать физические связи между всеми узлами реализации системы на этапе ее исполнения;
выявить узкие места системы и сконфигурировать ее топологию для достижения требуемой производительности.
Разработка диаграммы развертывания начинается с идентификации всех аппаратных устройств, которые необходимы для выполнения системой своих функций. В первую очередь определяются вычислительные узлы системы, обладающие памятью и процессором. Дальнейшее построение диаграммы развертывания связано с размещением всех исполняемых компонентов диаграммы по узлам системы.
Диаграмма развертывания представляет граф с узлами в вершинах и соединениями между ними. Узел является физически существующим элементом, обладающим некоторым вычислительным ресурсом (например, процессор с электронной или магнитооптической памятью). Начиная с версии UML 1.3, понятие узла расширено и может включать в себя не только вычислительные, но и механические и электронные устройства – датчики, манипуляторы, принтеры, модемы, и др.
Диаграмма вариантов использования
Информационные системы не работают в изоляции. Они взаимодействуют с внешними системами и пользователями. В UML прецедент (Use case) определяет поведение и представляет описание множества действий, выполняемых системой для получения определенного результата внешней системой. Прецеденты описываются отдельно от реализации и формируются на этапе анализа функциональных требований к системе. Они могут быть применимы ко всей системе или ее части.
Моделирование прецедентов основано на составлении диаграммы вариантов использования. Для этого используются два приема: моделирование требований, списка того, что система должна делать, и моделирование контекста системы, идентификации деятелей, внешних по отношению к системе. Деятель представляет любую внешнюю по отношению к моделируемой системе сущность, которая взаимодействует с системой и использует ее функциональные возможности для достижения целей в решении конкретных задач
2. Правовые вопросы организации Интернет-сайта.
Сайт сети Интернет представляет собой сетевой информационный ресурс, на котором может быть размещена информация различной природы, в том числе персональные данные, коммерческая тайна, произведения, охраняемые авторским правом.
Изначально сеть Интернет была задумана как средство общения и объединения людей, как большая распределенная библиотека, не предназначенная для коммерческого использования. Однако расширение услуг сети Интернет привело к росту числа пользователей и новым горизонтам коммерческого использования. Благодаря стремительному развитию рыночных отношений, Интернет сегодня требует определенного правового регулирования. Среди всего спектра правовых проблем особое место занимает проблема регулирования порядка использования информационных ресурсов сайта сети Интернет.
Информационные ресурсы сайта сети Интернет имеют различное правовое регулирование, сложный субъектный состав лиц, имеющих определенные права и обязанности в отношении размещаемой на сайте информации, включая следующие категории лиц: собственник информационного ресурса, владелец информационного ресурса, потребитель (пользователь) информации, автор произведения (созданного изначально или переведенного позже в электронную форму), обладатель имущественных авторских прав на произведение на основе авторского договора, наследники.
Вследствие того, что информационные ресурсы сайта сети Интернет доступны для пользователей других стран, где относительно определенных видов информации может быть установлено иное, отличное от страны размещения сайта сети Интернет правовое регулирование, владельцы таких сайтов могут нарушать законодательство других стран.
Информационные ресурсы сайтов сети Интернет обычно размещаются на серверах организаций, предоставляющих услуги хостинга и имеющих выделенные широкополосные каналы доступа в сеть Интернет. В этой связи возникает закономерный вопрос о степени ответственности подобных организаций за информационные ресурсы, размещаемые на их серверах. Как правило, в договорах, заключаемых между организацией, представляющей услуги хостинга (хостинг-провайдер), и клиентом содержатся отдельные положения о недопустимости нарушения действующего законодательства, однако полный отказ от деликтоспособности (способности лица самостоятельно нести ответственность за вред, причиненный его противоправными действиями) в данном случае со стороны хостинг-провайдера представляется не достаточно обоснованным.
Пользователи сети Интернет осуществляют доступ к информационным ресурсам сайтов через целый ряд информационных посредников, представляющих услуги доступа или осуществляющих информационный обмен с другими открытыми сетями. В ходе использования информационных ресурсов сайтов сети Интернет осуществляется сбор информации, позволяющей в конечном счете идентифицировать личность пользователя (персональные данные). Нарушение норм о сборе и порядке использования персональных данных может произойти на различных этапах доступа пользователя к сайту сети Интернет. В этой связи особый интерес представляет не только ответственность организации, представляющей доступ к сети Интернет, но и промежуточных звеньев в цепи между такой организацией и хостинг-провайдером.
Отдельного рассмотрения заслуживает также деятельность самих пользователей в сети Интернет. Наличие широкополосного доступа к сети Интернет в настоящее время не является отличительной чертой лишь организаций, представляющих услуги хостинга или доступа к сети, так что пользователь, в том числе физическое лицо, может самостоятельно установить соответствующее программное обеспечение, и тогда информационные ресурсы на его компьютере будут представлены в виде соответствующего сайта сети Интернет. Однако, выставляя для обмена новый фильм, пусть даже в виде правомерно изготовленной резервной копии приобретенного за собственные средства лицензионного диска DVD, пользователь тем самым нарушает права правообладателей, в частности, право на распространение произведения.
Все большее число сайтов содержат указания относительно порядка использования их информационных ресурсов. Однако подобные указания могут не соответствовать действующему законодательству, искажать отдельные положения и нормы законов, а также намеренно вводить в заблуждение пользователей сети Интернет. Известны случаи, когда создаются сайты-двойники Интернет-магазинов и Интернет-аукционов, где в соответствии с предлагаемым порядком использования информационных ресурсов сайта требуется ввести персональные данные, в том числе номер кредитной карточки и секретный PIN-код, известный только владельцу карты, чем намеренно вводят в заблуждение пользователя относительно действительного предназначения вводимых данных.
Правовые проблемы могут возникать как на стадии подготовки сайта и определения его содержания, так и при последующем поддержании его функционирования. Пренебрежение тем или иным правовым аспектам при создании сайта может привести к парализации его функционирования, а при неблагоприятных условиях – к необходимости выплачивать значительные суммы компенсаций лицам, интересы которых были затронуты функционированием сайта.
Владелец сайта может разместить на нем различные объекты, исключительные права на которые принадлежит иным лицам. В этом случае он должен позаботиться о том, чтобы своевременно получить права, дающие ему возможность использовать эти объекты на сайте. Учет прав на объекты, размещенные на сайте, важен и с точки зрения возможности использования этих объектов посетителями сайта. Во избежание ненужных конфликтов лучше заранее описать на сайте условия использования материалов, размещенных на нем (разрешается ли их копирование без согласия владельца сайта, каковы возможные формы из последующего использования и т.д.). Это поможет облегчить защиту от недобросовестных действий посетителей сайта в отношении размещенных на нем материалов и предупредить конфликты с обладателями прав на размещенные материалы (если владелец сайта получал ограниченное право на их использование). При предоставлении посетителям сайта возможности загрузить определенные объекты, например программы, целесообразно разместить на сайте текст договора с пользователем таким образом, чтобы пользователь, не выразив своего согласия с этим документом (например, не щелкнув по кнопке с надписью «согласен»), не смог загрузить соответствующий объект. Особенно важно разместить такие договоры на сайте в случае оказания каких-либо услуг через Интернет или продажи товаров. При этом, конечно, нельзя не сознавать, что полноценные контрактные отношения могут быть реализованы через Интернет только после того, как начнется широкое применение электронных цифровых подписей.
3. На языке С++ вычислить сумму ряда целых чисел от 1 до n.
#pragma hdrstop
//---------------------------------------------------------------------------
#include <iostream.h>
void main()
{
int N,S=0,i;
cout<<"\n Vvedite N ==";
cin>>N;
for(i=1;i<=N;i++) S=S+i;
cout<<"\n Summa =="<<S;
}
Билет 36.
1. Структуры данных типа очередь. Логическая структура очереди. Машинное представление очереди FIFO и реализация операций. Очереди с приоритетами.
Очередью FIFO (First - In - First- Out - "первым пришел - первым исключается"). называется такой последовательный список с переменной длиной, в котором включение элементов выполняется только с одной стороны списка (эту сторону часто называют концом или хвостом очереди), а исключение - с другой стороны (называемой началом или головой очереди). Те самые очереди к прилавкам и к кассам, которые мы так не любим, являются типичным бытовым примером очереди FIFO.
Основные операции над очередью - те же, что и над стеком - включение, исключение, определение размера, очистка, неразрушающее чтение.
Машинное представление очереди FIFO и реализация операций
При представлении очереди вектором в статической памяти в дополнение к обычным для дескриптора вектора параметрам в нем должны находиться два указателя: на начало очереди (на первый элемент в очереди) и на ее конец (первый свободный элемент в очереди). При включении элемента в очередь элемент записывается по адресу, определяемому указателем на конец, после чего этот указатель увеличивается на единицу. При исключении элемента из очереди выбирается элемент, адресуемый указателем на начало, после чего этот указатель уменьшается на единицу.
Очевидно, что со временем указатель на конец при очередном включении элемента достигнет верхней границы той области памяти, которая выделена для очереди. Однако, если операции включения чередовались с операциями исключения элементов, то в начальной части отведенной под очередь памяти имеется свободное место. Для того, чтобы места, занимаемые исключенными элементами, могли быть повторно использованы, очередь замыкается в кольцо: указатели (на начало и на конец), достигнув конца выделенной области памяти, переключаются на ее начало. Такая организация очереди в памяти называется кольцевой очередью. Возможны, конечно, и другие варианты организации: например, всякий раз, когда указатель конца достигнет верхней границы памяти, сдвигать все непустые элементы очереди к началу области памяти, но как этот, так и другие варианты требуют перемещения в памяти элементов очереди и менее эффективны, чем кольцевая очередь.
В исходном состоянии указатели на начало и на конец указывают на начало области памяти. Равенство этих двух указателей (при любом их значении) является признаком пустой очереди. Если в процессе работы с кольцевой очередью число операций включения превышает число операций исключения, то может возникнуть ситуация, в которой указатель конца "догонит" указатель начала. Это ситуация заполненной очереди, но если в этой ситуации указатели сравняются, эта ситуация будет неотличима от ситуации пустой очереди. Для различения этих двух ситуаций к кольцевой очереди предъявляется требование, чтобы между указателем конца и указателем начала оставался "зазор" из свободных элементов. Когда этот "зазор" сокращается до одного элемента, очередь считается заполненной и дальнейшие попытки записи в нее блокируются. Очистка очереди сводится к записи одного и того же (не обязательно начального) значения в оба указателя. Определение размера состоит в вычислении разности указателей с учетом кольцевой природы очереди.
{==== Программный пример 4.3 ====}
unit Queue; { Очередь FIFO - кольцевая }
Interface
const SIZE=...; { предельный размер очереди }
type data = ...; { эл-ты могут иметь любой тип }
Procesure QInit;
Procedure Qclr;
Function QWrite(a: data) : boolean;
Function QRead(var a: data) : boolean;
Function Qsize : integer;
Implementation { Очередь на кольце }
var QueueA : array[1..SIZE] of data; { данные очереди }
top, bottom : integer; { начало и конец }
Procedure QInit; {** инициализация - начало=конец=1 }
begin top:=1; bottom:=1; end;
Procedure Qclr; {**очистка - начало=конец }
begin top:=bottom; end;
Function QWrite(a : data) : boolean; {** запись в конец }
begin
if bottom mod SIZE+1=top then { очередь полна } QWrite:=false
else begin
{ запись, модификация указ.конца с переходом по кольцу }
Queue[bottom]:=a; bottom:=bottom mod SIZE+1; QWrite:=true;
end; end; { QWrite }
Function QRead(var a: data) : boolean; {** выборка из начала }
begin
if top=bottom then QRead:=false else
{ запись, модификация указ.начала с переходом по кольцу }
begin a:=Queue[top]; top:=top mod SIZE + 1; QRead:=true;
end; end; { QRead }
Function QSize : integer; {** определение размера }
begin
if top <= bottom then QSize:=bottom-top
else QSize:=bottom+SIZE-top;
end; { QSize }
END.
Очереди с приоритетами
В реальных задачах иногда возникает необходимость в формировании очередей, отличных от FIFO или LIFO. Порядок выборки элементов из таких очередей определяется приоритетами элементов. Приоритет в общем случае может быть представлен числовым значением, которое вычисляется либо на основании значений каких-либо полей элемента, либо на основании внешних факторов. Так, и FIFO, и LIFO-очереди могут трактоваться как приоритетные очереди, в которых приоритет элемента зависит от времени его включения в очередь. При выборке элемента всякий раз выбирается элемент с наибольшим приоритетом.
Очереди с приоритетами могут быть реализованы на линейных списковых структурах - в смежном или связном представлении. Возможны очереди с приоритетным включением - в которых последовательность элементов очереди все время поддерживается упорядоченной, т.е. каждый новый элемент включается на то место в последовательности, которое определяется его приоритетом, а при исключении всегда выбирается элемент из начала. Возможны и очереди с приоритетным исключением - новый элемент включается всегда в конец очереди, а при исключении в очереди ищется (этот поиск может быть только линейным) элемент с максимальным приоритетом и после выборки удаляется из последовательности. И в том, и в другом варианте требуется поиск, а если очередь размещается в статической памяти - еще и перемещение элементов.
Наиболее удобной формой для организации больших очередей с приоритетами является сортировка элементов по убыванию приоритетов частично упорядоченным деревом.
2. Моделирование как процесс познания. Математическая модель, понятие вычислительного эксперимента и его структура.
Моделирование – метод познания. Модель – неполное описание объекта относительно поставленной задачи.
Математическая модель – модель описанная на математическом языке.
Вычислительный эксперимент – технология в итерационном процессе моделирования. Вычислительный эксперимент – средство решения сложных задач. В каждом случае имеет свою особенность (область исследования, применения и т.д)
Вычислительный эксперимент можно разделить на этапы:
1)Постановка задачи
2)Разработка математической модели
3)Разработка алгоритма
4)Программная реализация
5)Проведение расчетов
6)Анализ результата
7)Обработка результата
Последний этап: этап принятия решения
3. Составить программу, которая формирует стек, добавляя в него произвольное количество компонент.
|
program Project11;
{$APPTYPE CONSOLE}
uses SysUtils, Windows;
//Program Zadanie_11; //Uses Crt; Type TPtr = ^TElem; TElem = record Inf :Integer; Link:TPtr; end; Var Z,Value:Integer; Top:TPtr; Procedure Push(Val:Integer); Var P:TPtr; Begin New(P); P^.Inf:=Val; P^.Link:=Top; Top:=P; End; Procedure Pop(var Val:Integer); Var P:TPtr; Begin Val:=Top^.Inf; P:=Top; Top:=P^.Link; Dispose(P); End;
|
Begin //ClrScr; Writeln('Create STACK...'); Top:=nil; Writeln('Ukagite deistvie:'); Writeln(' 1. Zapis v STACK'); Writeln(' 2. Izvlechenie iz STACK'); Writeln(' 3. Ochistka STACK and print'); Writeln(' 4. EXIT'); Repeat Readln(Z); If Z=1 Then Begin Writeln('Vvedite VALUE == '); Readln(Value); Push(Value); End; If Z = 2 Then Begin Pop(Value); Writeln('Izvlechennoe VALUE == ',Value); End; If Z = 3 Then Begin While Top <> nil do Begin Pop(Value); Writeln('Izvlechennoe VALUE == ',Value); End; End; Until (Z=4); End. //begin { TODO -oUser -cConsole Main : Insert code here } //end.
|
Билет 37
1. Улучшенные методы сортировки. Сортировка Шелла, Хоара, улучшенная сортировка выбором. Сортировка с помощью дерева.
Сортировка – упорядочение элементов множества по возрастанию или убыванию.
Сортировку можно разбить на 2 вида:
1. Простые методы сортировки – выбором, пузырьковая, вставками.
2. Улучшенные методы сортировки – Шелла, Хоара.
Сортировка Шелла - общая идея заимствована из сортировки вставками и основывается на уменьшении шагов(расстояние между сортируемыми элементами на конкретном этапе сортировки). Сначала сортируются все элементы, отстоящие друг от друга на три позиции. Затем сортируются элементы, расположенные на расстоянии двух позиций. Наконец, сортируются все соседние элементы.
Проход 1 f d a c b e
\___\___\___/ / /
\___\_____/ / /
\_______/
Проход 2 c b a f d e
\___\___|___|___/ /
\______|______/
Проход 3 a b c d e f
|___|___|___|___|___|
Результат a b c d e f
Конкретная последовательность шагов может быть и другой. Единственное правило состоит в том, чтобы последний шаг был равен 1. Например, такая последовательность: 9, 5, 3, 2, 1
/* Сортировка Шелла. */
void shell(char *items, int count)
{
register int i, j, gap, k;
char x, a[5];
a[0]=9; a[1]=5; a[2]=3; a[3]=2; a[4]=1;
for(k=0; k < 5; k++) {
gap = a[k];
for(i=gap; i < count; ++i) {
x = items[i];
for(j=i-gap; (x < items[j]) && (j >= 0); j=j-gap)
items[j+gap] = items[j];
items[j+gap] = x;
}
}
}
Внутренний цикл for имеет два условия проверки. Очевидно, что сравнение x<items[j] необходимо для процесса сортировки. Выражение j>=0 предотвращает выход за границу массива items. Эти дополнительные проверки в некоторой степени понижают производительность сортировки Шелла.
В слегка модифицированных версиях данного метода сортировки применяются специальные элементы массива, называемые сигнальными метками. Они не принадлежат к собственно сортируемому массиву, а содержат специальные значения, соответствующие наименьшему возможному и наибольшему возможному элементам. Это устраняет необходимость проверки выхода за границы массива. Однако применение сигнальных меток элементов требует конкретной информации о сортируемых данных, что уменьшает универсальность функции сортировки.
Быстрая сортировка Хоара – в ее основе лежит сортировка обменами.
Быстрая сортировка построена на идее деления. Общая процедура заключается в том, чтобы выбрать некоторое значение, называемое компарандом(операнд в операции сравнения. Иногда называется также основой и критерием разбиения) ,а затем разбить массив на две части. Все элементы, большие или равные компаранду, перемещаются на одну сторону, а меньшие — на другую. Потом этот процесс повторяется для каждой части до тех пор, пока массив не будет отсортирован. Например, если исходный массив состоит из символов f e d a c b, а в качестве компаранда используется символ d, первый проход быстрой сортировки переупорядочит массив следующим образом:
Начало f e d a c b
Проход 1 b c a d e f
Затем сортировка повторяется для обеих половин массива, то есть b с а и d e f. Как вы видите, этот процесс по своей сути рекурсивный, и, действительно, в чистом виде быстрая сортировка реализуется как рекурсивная функция.
Значение компаранда можно выбирать двумя способами — случайным образом либо усреднив небольшое количество значений из массива. Для оптимальной сортировки необходимо выбирать значение, которое расположено точно в середине диапазона всех значений. Однако для большинства наборов данных это сделать непросто. В худшем случае выбранное значение оказывается одним из крайних. Тем не менее, даже в этом случае быстрая сортировка работает правильно. В приведенной ниже версии быстрой сортировки в качестве компаранда выбирается средний элемент массива.
/* Функция, фызывающая функцию быстрой сортировки. */
void quick(char *items, int count)
{
qs(items, 0, count-1);
}
/* Быстрая сортировка. */
void qs(char *items, int left, int right)
{
register int i, j;
char x, y;
i = left; j = right;
x = items[(left+right)/2]; /* выбор компаранда */
do {
while((items[i] < x) && (i < right)) i++;
while((x < items[j]) && (j > left)) j--;
if(i <= j) {
y = items[i];
items[i] = items[j];
items[j] = y;
i++; j--;
}
} while(i <= j);
if(left < j) qs(items, left, j);
if(i < right) qs(items, i, right);
}
В этой версии функция quick() готовит вызов главной сортирующей функции qs(). Это обеспечивает общий интерфейс с параметрами items и count, но несущественно, так как можно вызывать непосредственно функцию qs() с тремя аргументами.
Необходимо упомянуть об одном особенно проблематичном аспекте быстрой сортировки. Если значение компаранда в каждом делении равно наибольшему значению, быстрая сортировка становится "медленной сортировкой" со временем выполнения порядка n2. Поэтому внимательно выбирайте метод определения компаранда. Этот метод часто определяется природой сортируемых данных. Например, в очень больших списках почтовой рассылки, в которых сортировка происходит по почтовому индексу, выбор прост, потому что почтовые индексы довольно равномерно распределены — компаранд можно определить с помощью простой алгебраической функции. Однако в других базах данных зачастую лучшим выбором является случайное значение. Популярный и довольно эффективный метод — выбрать три элемента из сортируемой части массива и взять в качестве компаранда значение, расположенное между двумя другими.
Сортировка выбором
Отыскивается максимальный (минимальный) элемент и переносится в конец массива. Затем этот метод применяется ко всем элементам, кроме последнего (он уже находится на своем месте).
Другой вариант метода - перенос найденного элемента в начало массива и последующее применение метода ко всем элементам, кроме первого.
Сортировка двоичным деревом
Двоичным(бинарным) деревом назовем упорядоченную структуру данных, в которой каждому элементу - предшественнику или корню (под)дерева - поставлены в соответствие по крайней мере два других элемента (преемника). Причем для каждого предшественника выполнено следующее правило: левый преемник всегда меньше, а правый преемник всегда больше или равен предшественнику.
Вместо 'предшественник' и 'преемник' также употребляют термины 'родитель' и 'сын'. Все элементы дерева также называют 'узлами'. При добавлении в дерево нового элемента его последовательно сравнивают с нижестоящими узлами, таким образом вставляя на место. Если элемент >= корня - он идет в правое поддерево, сравниваем его уже с правым сыном, иначе - он идет в левое поддерево, сравниваем с левым, и так далее, пока есть сыновья, с которыми можно сравнить. Процесс построения дерева из последовательности 44 55 12 42 94 18 06 67:
44 44 44 44 44
\ / \ / \ / \
55 12 55 12 55 12 55
\ \ \
42 42 94
(**) 44 44 (*) 44
/ \ / \ / \
12 55 12 55 12 55
\ \ / \ \ / \ \
42 94 06 42 94 06 42 94
/ / / /
18 18 18 67
2. Правовые вопросы, возникающие при использовании электронной почты.
Электронная почта – один из самых популярных сервисов Интернет, использование которого предполагает высокоскоростную передачу информации по телекоммуникационным сетям связи на любые расстояния. Основным отличием от прочих систем передачи сообщений (например, служб мгновенных сообщений) является возможность отложенной доставки и развитая система взаимодействия между независимыми почтовыми серверами.
Правовое регулирование электронной почты включает в себя следующие элементы:
– использование электронной почты для ведения деловой деятельности;
– использование электронной почты для официальных контактов с органами государственной власти;
– использование электронной почты для ведения личных дел;
– обеспечение безопасности, управление доступом и сохранение конфиденциальности сообщений;
– администрирование и хранение электронных писем.
Характеризуя электронную почту в целом, важно отметить, что электронная форма писем не должна вводить в заблуждение: на бумаге или в виде последовательности электронных импульсов письмо все равно будет выполнять одни и те же функции. Письмо может быть средством общения и инструментом в коммерческих отношениях. Использование электронной формы письма вместо обычной, на бумажном носителе, не меняет принципиально характер взаимоотношений отправителя и адресата, и соответственно, правовые последствия использования такой формы коммуникации, как правило, существенно не отличаются от правовых последствий общения с помощью традиционных писем. Это означает, что электронная почта не находится в правовом вакууме, а к отправке электронного письма следует подходить не менее осмотрительно, чем к отправке обычного письма.
Прежде всего, необходимо обратить внимание на возможность перехода электронного письма из одной юрисдикции в другую. В случае открытия отправителем и адресатом почтовых ящиков на сайтах, находящихся под разными юрисдикциями, ситуация правового регулирования еще больше осложняется. Так лицо, проживающее в России и открывшее свой почтовый ящик на сайте hotmail.com или yahoo.com, хранит всю свою почту на сервере, находящимся на территории США. Это обстоятельство делает обязательным для отправителя электронного сообщения учет возможности нарушения содержанием электронного письма законодательства другого государства. Письмо может включать в себя объекты, исключительные права на которые в данной стране принадлежат иным лицам (например, произведения литературы, науки и искусства, товарные знаки и т.д.), информацию, распространение которой на территории данной страны запрещено, и т.д. Как минимум, в расчет должно приниматься законодательство страны проживания отправителя и адресата, а также стран нахождения их почтовых ящиков.
В свою очередь, возможность нахождения письма под разными юрисдикциями резко увеличивает значимость проблемы конфиденциальности электронного сообщения. Незашифрованное электронное письмо становится доступным многим лицам во время прохождения от отправителя к адресату. В ряде случаев целесообразным может оказаться использование механизмов шифрования, однако во многих странах применение определенных средств шифрования частными лицами ограничено или запрещено. Наконец, есть риск, что письмо будет доставлено не по адресу в результате ошибки в работе ПО. Все это делает электронную почту не слишком надежным (с т.з. конфиденциальности) способом передачи информации.
Еще одна серьезная проблема связана с ответственностью провайдера за сохранность почты и обеспечение ее конфиденциальности. Прежде чем открыть почтовый ящик, следует внимательно изучить предлагаемый договор, чтобы определить, каковы обязанности провайдера по обеспечению сохранности почты, предполагается ли проверка входящей почты на вирусы, в каких случаях провайдер может удалять письма, может ли он осуществлять их цензуру и т.д. Договор должен подробно определять перечень предоставляемых услуг, который может быть различным у разных провайдеров, а также тарифы на эти услуги. При этом надо учитывать, что выбор страны размещения почтового ящика решающим образом влияет на возможность защиты интересов пользователя электронной почты.
Другим аспектом обеспечения конфиденциальности электронной почты является обеспечение сохранности электронного письма. Получатель электронного письма должен осознавать, что содержание этого письма могло быть изменено третьим лицом. Легкость копирования электронной почты, теоретическая доступность содержания письма посторонним лицам делает вопрос подлинности электронного письма очень важным. С другой стороны, очевидна и проблема идентификации отправителя письма. Например, сайты, предоставляющие бесплатные почтовые ящики, и Интернет-провайдеры, оказывающие такие услуги, никак не проверяют соответствие выбранного имени реальному имени пользователя. Ничто не мешает зарегистрировать бесплатный почтовый ящик, включив в состав выбранного имени имя другого человека и рассылать почту в дальнейшем, притворяясь другим лицом.
Электронное письмо является одной из форм корреспонденции. Перехват чужого сообщения, внесение в него изменений, его разглашение будут затрагивать право лица на неприкосновенность переписки.
Довольно частыми являются попытки работодателей осуществлять мониторинг содержания электронной почты, отправляемой работниками, так же как и другого использования Интернета. Безусловно, что работодатели имеют существенные причины для организации такого контроля. Заинтересованность работодателя в возможности контроля за перепиской своих работников была принята во внимание законодательно в ряде стран. При этом конечно, администратор системы должен предпринять все меры для того, чтобы довести правила использования электронной почты до сведения пользователей системы. Учитывая, что Конституция РФ признает право на тайну переписки, телефонных переговоров, почтовых, телеграфных и иных сообщений (ч.2 ст. 23) работодателям в России следует избегать использования определенных форм мониторинга электронной почты. В случаях, непосредственно связанных с вопросами трудовых отношений, работодатель вправе получать и обрабатывать данные о частной жизни работника только с его письменного согласия.
Естественно, что электронная почта, так же как и обычная почта, может быть использована для совершения ряда запрещенных действий, например шантажа. Но появляются и новые формы совершения противоправных действий. Так, большую опасность представляются электронные письма, инфицированные компьютерными вирусами. В соответствии со ст. 272 УК РФ распространение вредоносных программ для ЭВМ является уголовным преступлением.
Другой формой недобросовестного использования электронной почты является массовая рассылка «непрошенных» писем, в основном носящих рекламный характер, обычно называемых спамом. К сожалению, российскому законодательству понятие «спам» не известно, однако за рубежом судебные процессы в связи с рассылкой спама стали обыденными явлением. Спам признается вторжением в личную жизнь. Негативное отношение к спаму важно учитывать при использовании электронной почты в качестве рекламного средства. Важно помнить, что почтовый ящик отправителя или адресата может находиться под юрисдикцией страны, законодательством которой предусмотрены серьезные санкции за рассылку спама.
Важно принять во внимание и то, что очень часто лица, рассылающие спам, используют бесплатные почтовые ящики, которые легко можно открыть на многих крупных Интернет-сайтах (поскольку закрытие такого сайта ничем не грозят лицу, рассылающему спам, а открыть новый можно без труда). В связи с этим при рассылке рекламных сообщений, да и вообще при ведении коммерческой деятельности стоит избегать использования таких бесплатных ящиков, поскольку это может негативно сказаться на репутации отправителя. Это важно учитывать лицам, занимающимся серьезной коммерческой деятельностью. Как бы не серьезны их намерения, их письма не будут восприниматься всерьез, если они посланы с одного из бесплатных сайтов.
Наконец, стоит осторожно относиться и к указанию своего адреса в общедоступных местах – на конференциях, в чатах и т.д. Возможно использование нескольких почтовых адресов – например, один для личной переписки, другой – для указания при общении с интернет-магазинами, при регистрации на различных интернет-сайтах и т.д.
Использование сервиса электронной почты в сфере государственного управления пока только формируется. Однако в связи с вступлением в силу Федерального закона «Об электронной цифровой подписи» от 10 января 2001 г. № 1-ФЗ, а также введением новелл о возможности предоставления бухгалтерской и налоговой отчетности в электронной форме можно ожидать принятия новых правовых норм, касающихся электронной почты.
3. Составить программу, которая формирует стек, добавляя в него произвольное количество компонент.
program Project11;
{$APPTYPE CONSOLE}
uses
SysUtils,
Windows;
//Program Zadanie_11;
//Uses Crt;
Type
TPtr = ^TElem;
TElem = record
Inf :Integer;
Link:TPtr;
end;
Var
Z,Value:Integer;
Top:TPtr;
Procedure Push(Val:Integer);
Var P:TPtr;
Begin
New(P);
P^.Inf:=Val;
P^.Link:=Top;
Top:=P;
End;
Procedure Pop(var Val:Integer);
Var P:TPtr;
Begin
Val:=Top^.Inf;
P:=Top;
Top:=P^.Link;
Dispose(P);
End;
Begin
//ClrScr;
Writeln('Create STACK...');
Top:=nil;
Writeln('Ukagite deistvie:');
Writeln(' 1. Zapis v STACK');
Writeln(' 2. Izvlechenie iz STACK');
Writeln(' 3. Ochistka STACK and print');
Writeln(' 4. EXIT');
Repeat
Readln(Z);
If Z=1 Then Begin
Writeln('Vvedite VALUE == ');
Readln(Value);
Push(Value);
End;
If Z = 2 Then
Begin
Pop(Value);
Writeln('Izvlechennoe VALUE == ',Value);
End;
If Z = 3 Then Begin
While Top <> nil do
Begin
Pop(Value);
Writeln('Izvlechennoe VALUE == ',Value);
End;
End;
Until (Z=4);
End.
//begin
{ TODO -oUser -cConsole Main : Insert code here }
//end.
Билет 38.
1. Классификация ОС. Требования, предъявляемые к ОС.
Вариантов классификации ОС может быт очень много, они зависят от признака, по которому одна ОС отличается от другой:
- по назначению;
- по режиму обработки;
- по способу взаимодействия с системой;
- по способу построения.
Основным предназначением ОС является:
- организация эффективных и надежных вычислений;
- создание различных интерфейсов для взаимодействия с этими вычислениями и самой вычислительной системой.
ОС разделяют по назначению:
- ОС общего назначения;
- ОС специально назначения.
ОС специального назначения подразделяются на следующие:
- для переносимых компьютеров и встроенных систем;
- для организации и ведения баз данных;
- для решения задач реального времени и т.д.
ОС разделяют по режиму обработки задач:
- однопрограммный режим;
- мультипрограммный режим.
Мультипрограммирование – способ организации вычислений, когда на однопроцессной вычислительной системе создается видимость одновременного выполнения нескольких задач. Любая задержка в выполнении одной программы используется для выполнения других программ.Мультипрограммный и многозадачный режимы близки по смыслу, но синонимами не являются.
Мультипрограммный режим обеспечивает параллельное выполнение нескольких приложений, а программисты, создающие эти приложения, не должны заботиться о механизме организации их параллельной работы. Эти функции выполняет ОС, которая распределяет между выполняющимися приложениями ресурсы вычислительной системы, обеспечивает необходимую синхронизацию вычислений и взаимодействие.
Мультизадачный режим предполагает, что забота о параллельном выполнении и взаимодействии приложений ложится на прикладных программистов.
Современные ОС для ПК реализуют и мультипрограммный, и многозадачный режимы.
По организации работы в диалоговом режиме ОС делятся на следующие:
- однопользовательские (однотерминальные);
- мультитерминальные.
В мультитерминальных ОС с одной вычислительной системой одновременно могут работать несколько пользователей, каждый со своего терминала, при этом у пользователей возникает иллюзия, что у него имеется своя собственная вычислительная система. Для организации мультитерминального доступа необходим мультипрограммный режим работы вычислительной системы.
Основная особенность операционных систем реального времени (ОСРВ) – обеспечение обработки поступающих заданий в течение заданных интервалов времени, которые нельзя превышать. Поток заданий не является планомерным и не регулируется оператором, т.е. задания поступают в непредсказуемые моменты времени и без всякой очередности. В ОСРВ в общем случае отсутствуют накладные расходы процессорного времени на этап инициирования (загрузку программы, выделение ресурсов), так как набор задач обычно фиксирован и вся информация о задаче известна до поступления запроса. Для реализации режима реального времени необходим режим мультипрограммирования, который является основным средством повышения производительности вычислительной системы, а для задач реального времени производительность – решающий фактор. Лучшие по производительности характеристики для систем реального времени обеспечивают однотерминальные ОСРВ.
По способам построения (архитектуре) ОС подразделяются на следующие:
- микроядерные;
- монолитные.
Это деление условно. К микроядерным ОС относится ОСРВ QNX, а к монолитным – Windows 9x и Linux. Для ОС Windows 9x пользователь не может изменить ядро, так как не располагает исходными кодами и программой сборки ядра. Для ОС Linux такая возможность предоставлена, пользователь может сам собрать ядро, включив в него необходимые программные модули и драйверы.
Очевидно, что главным требованием, предъявляемым к операционной системе, является способность выполнения основных функций: эффективного управления ресурсами и обеспечения удобного интерфейса для пользователя и прикладных программ. Современная ОС, как правило, должна реализовывать мультипрограммную обработку, виртуальную память, свопинг(виртуальная память), поддерживать многооконный интерфейс, а также выполнять многие другие, совершенно необходимые функции. Кроме этих функциональных требований к операционным системам предъявляются не менее важные рыночные требования. К этим требованиям относятся:
Расширяемость. Код должен быть написан таким образом, чтобы можно было легко внести дополнения и изменения, если это потребуется, и не нарушить целостность системы.
Переносимость. Код должен легко переноситься с процессора одного типа на процессор другого типа и с аппаратной платформы (которая включает наряду с типом процессора и способ организации всей аппаратуры компьютера) одного типа на аппаратную платформу другого типа.
Надежность и отказоустойчивость. Система должна быть защищена как от внутренних, так и от внешних ошибок, сбоев и отказов. Ее действия должны быть всегда предсказуемыми, а приложения не должны быть в состоянии наносить вред ОС.
Совместимость. ОС должна иметь средства для выполнения прикладных программ, написанных для других операционных систем. Кроме того, пользовательский интерфейс должен быть совместим с существующими системами и стандартами.
Безопасность. ОС должна обладать средствами защиты ресурсов одних пользователей от других.
Производительность. Система должна обладать настолько хорошим быстродействием и временем реакции, насколько это позволяет аппаратная платформа.
Основные требования к операционной системе реального времени:
1) мультипрограммность и многозадачность (многопоточность). ОС должна активно использовать прерывания для диспетчеризации. Максимальное время выполнения того или иного действия должно быть известно заранее и соответствовать требованиям приложения;
2) приоритеты задач (потоков). Проблема, какой задаче ресурс требуется больше всего. В идеальной ситуации ОСРВ отдает ресурс потоку или драйверу с ближайшим крайнем сроком завершения. Чтобы реализовать этот принцип ОС должна знать, сколько времени требуется каждому процессу для его завершения. Таких ОС нет, так как их очень сложно реализовать, поэтому вводится понятие уровня приоритета для задачи и временные ограничения сводятся к приоритетам;
3) наследование приоритетов. ОСРВ должна допускать наследование приоритета, то есть повышение уровня приоритета потока до уровня приоритета потока, который его вызывает. Наследование означает, что блокирующий ресурс поток наследует приоритет потока, который он блокирует;
4) синхронизация процессов и задач. Так как задачи разделяют данные (ресурсы) и должны сообщаться друг с другом, то должны существовать механизмы блокирования и коммуникации. Эти системные механизмы должны быть всегда доступны процессам, требующим реального времени;
5) предсказуемость. Времена выполнения системных вызовов и временные характеристики поведения системы в различных обстоятельствах должны быть известны разработчику.
Разработчик ОСРВ должен привести следующие характеристики:
- задержку прерывания, время от момента прерывания до момента запуска задачи;
- максимальное время выполнения каждого системного вызова;
- максимальное время маскирования прерываний драйверами и ОС.
2. Понятие системы. Математическое определение системы. Классификация систем.
Система – объект исследования. Она существует в среде или в системе более высокого порядка. Любую систему можно разбить на подсистемы. Система функционирует во времени и это значит, что она меняется.
Система может делать:
1)Преобразовывать
2)Носить информацию
Математическое отображение
<T, X, Y, Q, F, G>
T – время существования
X – входные воздействия
Y – выходные воздействия
Q – множество всех состояний системы
F – чтобы связать описанную систему
G
F: это отображение дэкартового произведения T*X*Q -> Y
Или
y(t,x,q) , где x принадлежит X
,где t принадлежит T
,где q принадлежит Q
Функция выхода
y(t,x,q) = F(t,x(t),q(t))
Пред. момент
q(t,x,q-1) = G(t,x(t),q-1)
G: T*X*Q -> Q
Клас. систем можно по виду множеств и функции:
Если они детерминированы (определены –конечный автомат описываются виде логических отношений и как правило не имеет выхода)
Если они недетерминированные (случайные – будет не известно, что будет на выходе и что выпадет)
3. Занести в BL наименьшее число из отрезка от 2 до К на которое не делится число N , при условии что 2K<N.
|
program Project1;
{$APPTYPE CONSOLE}
uses SysUtils, Windows;
//Program Zadanie_1; //Uses Crt; Var K:Byte; Function Otrezok (X:Integer):Integer; Begin asm {находим значение N и сохраняем его в AX} MOV CX,2 MOV AX,5 MUL CX {сохраняем в BX значение N} MOV BX,AX {задаем начальное значение делителя} MOV CX,1 @1: INC CX MOV AX,BX {проверка, не вышли ли за границы отрезка 2..K} CMP CX,x JG @2 {делим регистр AX на CX} DIV CX {проверяем остаток от DX} CMP DX,0 {если поделено нацело, отправляемся по метке 1} JZ @1
|
{нацело не поделилось, нашли значение на отрезке = CX и выход из процедуры} // MOV @Result,CX JMP @3 @2: MOV CX,0 // MOV @Result,CX @3: end; End; Begin //ClrScr; Write('Vvedite K == '); Readln(K); Writeln('RESULT => ',Otrezok(K)); Readln; end. //begin { TODO -oUser -cConsole Main : Insert code here } //end.
|
Билет 39.
1. Понятия файла. Структура файла. Реализация файлов
понятие файла. Имена файлов. Полное имя файла. Понятие каталога. Атрибуты файлов
Что такое файл.
Информация на дисках (жестких дисках, дискетах, магнитооптических дисках, компьютерных компакт-дисках и т.д.) хранится в файлах.
Файл — это поименованная область на диске или другом носителе информации. В файлах могут храниться тексты программ, документы, готовые к выполнению программы и любые другие данные.
Текстовые и двоичные файлы. Часто файлы разделяют на две категории — текстовые и двоичные. Текстовые файлы предназначены для чтения человеком. Они состоят из строк символов, причем каждая строка оканчивается двумя специальными символами «возврат каретки» (СR) и «новая строка» (LF). При редактировании и просмотре текстовых файлов эти специальные символы, как правило, не видны, В
текстовых файлах хранятся тексты программ, командных файлов и т.д. Файлы, не являющиеся текстовыми, по традиции называются двоичными.
Исполнимые файлы. Каждая программа (кроме операционной системы, которая запускается при включении компьютера) содержит в своем составе файл, который запускает эту программу. Такой файл называется исполнимым файлом. Иначе говоря, исполнимый файл —это головной файл программы, запускающий ее на выполнение. Если программа состоит из одного файла, то этот файл и является исполнимым файлом. По традиции исполнимые файлы обычно имеют расширение имени .СОМ или .ЕХЕ.
Файлы документов. Кроме файлов программ, на Ваших дисках всегда будут файлы, содержащие данные, с которыми Вы работаете. Чаще всего данные, соответствующие одному документу, с которым Вы работаете, содержатся в одном файле. Такие файлы обычно называют файлами документов. Например, большинство редакторов текстов, электронных таблиц, сохраняют любой обрабатываемый документ (таблиц; рисунок и т.д.) в одном файле. Для работы с такими документами надо запустить соответствующую программу и считать (часто говорят — открыть) документа в этой программе.
Имена файлов
Чтобы операционная система и другие программы могли обращаться к файлам, файлы должны иметь обозначения. Это обозначения обычно называют именем файла.
Имена файлов. В операционной системе DOS, обозначения файлов состоят из двух частей: имени и расширения. Часто имя и расширение вместе также {они}называются именем{файлов}, как правило, это не приводит к путанице. В имени файла может быть от 1 до 8 символов. Расширение начинается с точки, за которой следуют от 1 до 3 символов. Например,
Command.com
имя .расширение
Допустимые символы. Имя и расширение могут состоять из прописных и строчных латинских букв, цифр и символов
Прописные и строчные буквы. В имени и расширении имени файла прописные и строчные латинские буквы являются эквивалентными, так как DOS переводит все строчные буквы в соответствующие прописные буквы. На диске имя файла хранится в версии, записанной прописными (то есть большими) буквами.
Русские буквы. Некоторые «русифицированные» версии DOS позволяют употреблять в именах файлов русские буквы. Однако эту возможность следует использовать с осторожностью: многие программы не «понимают» имен с русскими буквами.
Примеры: недопустимы:
ШЧУРКЕВИЧ.ООС — более 8 символов до точки;
Аf ghv.doc —пробелы недопустимы;
Ж+Коля — символ «+» недопустим;
1>4.txt —символы «<» и «>» недопустимы;
мАО.ТЕХТ —более 3 символов в расширении.
расширение имени. Расширение имени файла является необязательным. Оно, как правило, описывает содержание файла, поэтому использование расширения весьма удобно. Многие программы устанавливают расширение имени файла, и по нему Вы можете узнать, какая программа создала файл. Кроме того, многие программы (Norton commander, Диспетчер Файлов Windows и т.д.) позволяют по расширению имени файла вызвать соответствующую программу и сразу загрузить в нее данный файл — это весьма полезно, так как экономит время.
Примеры:
.com,.exe-исполнимые файлы (готовые к выполнению программы);
.bat-командные файлы;
.pas-программы на Паскале;
.bak- копия файла, создаваемая перед его изменением.
.sys-системный или драйверный файл;
.txt –текстовый файл;
.tmp-рабочий временный файл;
.pcx-файл изображения в формате Paintbrash;
.rar, .arj, .zip-архивные;
.dbf-файлы баз данных foxpro
Замечание. Многие программы используют расширение .ВАК для копий файла, создаваемых перед его изменением. Наличие такой копии позволяет восстановить содержимое файла в случае его ошибочного изменения или удаления. После окончания работы с файлом, когда пользователь убедился в том, что правильно внес все изменения в файлы, он может уничтожить созданные файлы с расширением .ВАК.
Зарезервированные имена файлов. Некоторые сочетания символов нельзя использовать в качестве имен файлов, так как операционная система DOS использует их для обозначения устройств DOS. Имена устройств позволяют при задании команд DOS осуществлять ввод и вывод информации с различными устройствами компьютера, что иногда бывает очень удобно. Например, имя PRN обозначает принтер, поэтому если в команде DOS вместо имени файла указать PRN, то соответствующие данные будут выведены на принтер. Вот список имен устройств DOS:
PRN— принтер;
LPT1-LPT4— устройства, присоединяемые к параллельным портам (обычно это принтеры);
COM1-СОМ4 — устройства, присоединяемые к последовательным портам 1-4;
NUL-“пустое устройство”;Все операции ввода-вывода для этого устройства игнорируются(при чтении с него программе сообщается о конце файла, а при выводе на него информация на самом деле никуда не выводится, но программе, которая делает вывод, сообщается, что вывод прошел успешно)
CON-консоль, при вводе -клавиатура при выводе –экран;
AUX-асинхронный интерфейс(вспомогательный выход). Устройство подсоединяемое к последовательному порту.AUX-синоним COM1.
Нельзя использовать следующие символы, которые зарезервированы для специальных функций:
? . , ; : = + * / \ “ | < > [ ] ПРОБЕЛ
В длинных именах нельзя использовать следующие символы:
? : * / \ “ > < |
Каталоги.
Имена файлов регистрируются на дисках в каталогах(или директориях).
Каталог-это специальное место на диске, в котором хранятся имена файлов, сведения о размере файлов, времени их последнего обновления, атрибуты (свойства) файлов и т.д. Если в каталоге хранится имя файла, то говорят, что этот файл находится в данном каталоге. На каждом диске может быть несколько каталогов. В каждом каталоге может быть много файлов, но каждый файл всегда регистрируется только в одном каталоге.
Все каталоги на самом деле являются файлами специального вида. Каждый каталог имеет имя, и он может быть зарегистрирован в другом каталоге. Требования к именам каталогов те же, что к именам файлов. Как правило расширение имени для каталогов не используются.
На каждом диске имеется один главный или корневой каталог. В нем регистрируются файлы и подкаталоги (каталоги 1го уровня). В каталогах 1го уровня регистрируются файлы и каталоги 2-го уровня и т.д. Получается иерархическая древообразная структура каталогов на диске.
Каталог, с которым в настоящий момент работает пользователь называется текущим. Если в команде DOC указать имя файла, то этот файл будет создаваться или отыскиваться в текущем каталоге.
Директорий - это область памяти на диске, выделяемая в процессе его форматирования. Диpектоpий представляет собой таблицу, куда заносятся данные о хpанящихся на диске файлах. Каждому файлу в диpектоpии соответствует одна запись.Запись директория включает следующую инфоpмацию: полное имя файла (имя и pасшиpение), дату и время его создания или последней коppектиpовки, объем занимаемой памяти в байтах, а также некотоpую дополнительную информацию, используемую пpи обслуживании файла операционной системой.
Когда вы используете файл не из текущего каталога, необходимо указать, в каком каталоге этот файл находится т.е. указать путь к файлу. Путь- это последовательность из имен каталогов или символов «..», разделенных символом «/». Этот путь задает маршрут от текущего каталога или от корневого каталога диска к тому каталогу, в котором находится нужный файл.
Если путь начинается с символа «/», то маршрут вычисляется от корневого каталога диска, иначе –от текущего каталога. Каждое имя каталога в пути соответствует входу в подкаталог с таким именем, «..» соответствует входу в надкаталог.
Корневой
каталог
Текущий каталог - DOC
..\CHI - путь к каталогу 1-го уровня
LETTERS – путь к подкаталогу LETTERS каталога dos
..\exe\CHI –путь к подкаталогу CHI каталога EXE .
Имена дисков.
В компьютере имеется несколько дисководов-накопителей на жестких дисках, дискетах, компакт-дисках и т.д. На каждом из них могут находиться файлы и каталоги. Для того, чтобы указать, какой диск Вам необходим надо обратиться к дисководу по имени.
По традиции дисководы именуются А:, В:, С: и т .д. Например, в компьютере могут быть два накопителя на гибком магнитном диске А: и В: и один накопитель на жестком магнитном диске С:.
Текущий дисковод-это тот дисковод, с которым вы работаете в настоящее время.
Говоря, что обозначения А:, В:, С: и т.д. соответствуют дисководам, мы были не совсем точны. На самом деле эти обозначения соответствуют не дисководам, а логическим дискам. Дело в том, что любой жесткий диск можно разделить на несколько частей и работать с ними как с отдельными дисками. Эти части называются логическими дисками, или разделами диска. Каждый логический диск имеет имя, по которому к нему можно обращаться.
Полное имя файла.
Полное имя файла имеет следующий вид ( []-необязательные элементы).
[дисковод:][путь\]имя-файла
т.е состоит из пути к каталогу, в котором находится файл и имени файла, разделенных символом «\», перед которым может стоять имя дисковода. Если дисковод не указан, то подразумевается текущий дисковод. Если путь не указан, то подразумевается текущий каталог.
A:mouse.com –в текущем каталоге
A:\mouse.com –в корневом каталоге
ST\mouse.com-в подкаталоге ST текущего каталога
Символы * и ?. Во многих командах и именах файлов можно употреблять символы * и ? для указания группы файлов из одного каталога.
Символ *- обозначает любое число любых символов в имени файла или в расширении имени файла.
Символ ?- обозначает один произвольный символ или отсутствие символа в имени файла или в расширении имени файла.
В имени файлов, содержащих указание на каталог или дисковод, символы * и ? обычно употреблять нельзя в той части имени, которая содержит указания на каталог или дисковод.
C:\dos\*.doc-допустимо
C:\*\f.doc- недопустимо
*:\dos\f.doc- -“-
*.bak -все файлы с расширением bak из текущего дисковода.
C*.d* -все файлы начинающиеся с С, и расширением, начинающимся с D из текущего каталога.
В:\doc\as???.* -все файлы из каталога В:\doc с именем, начинающимся AS и состоящим не более чем из 5 символов.
Размещение файлов на жестком диске.
При использовании дискет не приходится особо задумываться каким образом следует размещать на них файлы. Чаще всего все файлы записывают в корневой каталог, иногда создается несколько каталогов для хранения отдельных групп файлов. Сложные структуры каталогов на дискете используются редко т.к. для такого количества файлов, которое помещается на дискете, простейшей структуры дерева каталогов вполне хватает.
При работе с жестким диском ситуация совсем другая. На жестком диске можно поместить тысячи файлов, и без продуманной схемы размещения файлов по каталогам разбираться в этих файлах было бы крайне трудно.
В корневом каталоге, при работе с жестким диском, не должно быть большого количества файлов и подкаталогов, поскольку поиск программ и файлов начинается часто с корневого каталога, это ускорит работу и облегчит ориентировку в файловой системе.
Рекомендации размещения:
1)Все файлы, относящиеся к одному комплексу, размещают в одном каталоге и его подкаталогах;
2)Все исполнимые и командные файлы общего назначения желательно размещать в одном каталоге и нескольких его подкаталогах (их описывают в Path);
3)Не следует помещать в одном каталоге файлы, которые не изменяете и файлы, которые можете изменить. Для текстов создают отдельный каталог.
Атрибуты файлов.
Для каждого файла соответствующая ему запись в каталоге содержит следующие атрибуты:
“только для чтения”-предохраняет файл от изменений;(для изменения и удаления необходимо снять данный атрибут)
“скрытый”-или “системный”
“архивный”-устанавливается при создании файла.
2. Виды объектов авторского права. Виды авторских прав. Программы для ЭВМ и базы данных, как объектов авторского права.
Интеллектуальные права на произведения науки, литературы и искусства являются авторскими правами.
Статья 1259. Объекты авторских прав
1. Объектами авторских прав являются произведения науки, литературы и искусства независимо от достоинств и назначения произведения, а также от способа его выражения:
литературные произведения;
драматические и музыкально-драматические произведения, сценарные произведения;
хореографические произведения и пантомимы;
музыкальные произведения с текстом или без текста;
аудиовизуальные произведения;
произведения живописи, скульптуры, графики, дизайна, графические рассказы, комиксы и другие произведения изобразительного искусства;
произведения декоративно-прикладного и сценографического искусства;
произведения архитектуры, градостроительства и садово-паркового искусства, в том числе в виде проектов, чертежей, изображений и макетов;
фотографические произведения и произведения, полученные способами, аналогичными фотографии;
географические, геологические и другие карты, планы, эскизы и пластические произведения, относящиеся к географии, топографии и к другим наукам;
другие произведения.
К объектам авторских прав также относятся программы для ЭВМ, которые охраняются как литературные произведения.
2. К объектам авторских прав относятся:
1) производные произведения, то есть произведения, представляющие собой переработку другого произведения;
2) составные произведения, то есть произведения, представляющие собой по подбору или расположению материалов результат творческого труда.
3. Авторские права распространяются как на обнародованные, так и на необнародованные произведения, выраженные в какой-либо объективной форме, в том числе в письменной, устной форме (в виде публичного произнесения, публичного исполнения и иной подобной форме), в форме изображения, в форме звуко- или видеозаписи, в объемно-пространственной форме.
4. Для возникновения, осуществления и защиты авторских прав не требуется регистрация произведения или соблюдение каких-либо иных формальностей.
В отношении программ для ЭВМ и баз данных возможна регистрация, осуществляемая по желанию правообладателя в соответствии с правилами статьи 1262 настоящего Кодекса.
5. Авторские права не распространяются на идеи, концепции, принципы, методы, процессы, системы, способы, решения технических, организационных или иных задач, открытия, факты, языки программирования.
6. Не являются объектами авторских прав:
1) официальные документы государственных органов и органов местного самоуправления муниципальных образований, в том числе законы, другие нормативные акты, судебные решения, иные материалы законодательного, административного и судебного характера, официальные документы международных организаций, а также их официальные переводы;
2) государственные символы и знаки (флаги, гербы, ордена, денежные знаки и тому подобное), а также символы и знаки муниципальных образований;
3) произведения народного творчества (фольклор), не имеющие конкретных авторов;
4) сообщения о событиях и фактах, имеющие исключительно информационный характер (сообщения о новостях дня, программы телепередач, расписания движения транспортных средств и тому подобное).
7. Авторские права распространяются на часть произведения, на его название, на персонаж произведения, если по своему характеру они могут быть признаны самостоятельным результатом творческого труда автора и отвечают требованиям, установленным пунктом 3 настоящей статьи.