

Распределение случайной величины х
|
Х |
0 |
1 |
2 |
3 |
4 |
|
Р |
0,0053 |
0,0575 |
0,2331 |
0,4201 |
0,2840 |
Определим числовые характеристики этого распределения. Математическое ожидание дискретной случайной величины Х находим по формуле
![]() ,
,
Где хi – возможные значения Х; рi– соответствующие вероятности.
M(X) = 0 ∙ 0,0053 + 1 ∙ 0,0575 + 2 ∙ 0,2331 + 3 ∙ 0,4201 + 4 ∙ 0,2840 = 2,92
Дисперсию случайной величины Х находим по формуле
D(X) =M(X²) – (M(X))².
Так как
M(X²) = 0 ∙ 0,0053 + 1 ∙ 0,0575 + 4 ∙ 0,2840 + 9 ∙ 0,4201 + 16 ∙ 0,2840 = 9,3148
то D(X) = 9,3148 – 2,92² = 0,7884.
Среднее квадратическое отклонение случайной величины Х равно:
![]()
Найдем функцию распределения вероятностей F(x).
Если х ≤ 0, то F(x) = 0.
Если 0 < х ≤ 1, то F(x) = 0,0053.
Если 2 < х ≤ 3, то F(x) = 0,0053 + 0,0575 = 0,0628.
Если 3 < х ≤ 4, то F(x) = 0,2959 + 0,4201 = 0,7160.
Если х > 4, то F(x) = 0,7160 + 0,2840 = 1.
График функции F(x) изображен на рис. 1.
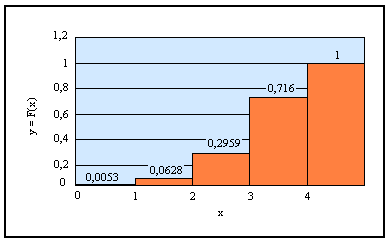
Рис.1. График функции распределения
Событие А, состоящее в том, что хотя бы один счет будет с ошибкой, является противоположным к событию, что все счета будут правильными, следовательно,
Р(А) = 1 – Р(Х = 4) = 1 – 0,2840 = 0,7160.
Вероятность того, что хотя бы один счет будет с ошибкой, равна 0,7160.
Задача 4. Годовой выпуск продукции
мебельной фабрики приблизительно
распределен по нормальному закону со
средним значением, равнымmтыс.ед. продукции, и стандартным
отклонением![]() тыс.ед. Найти вероятность того, что
годовой выпуск продукции: а) окажется
нижеbтыс.ед.; б)
превыситaтыс.ед.
тыс.ед. Найти вероятность того, что
годовой выпуск продукции: а) окажется
нижеbтыс.ед.; б)
превыситaтыс.ед.
Пример. Решить задачу для следующих
данных:m= 134,![]() = 13,b= 100,a= 150.
= 13,b= 100,a= 150.
Решение. Обозначим через Х – годовой
выпуск продукции мебельной фабрики.
Это непрерывная случайная величина,
имеющая нормальное распределение с
параметрамиmи![]() .
Поэтому вероятность попадания случайной
величины в промежуток [a,b] вычисляется по формуле
.
Поэтому вероятность попадания случайной
величины в промежуток [a,b] вычисляется по формуле
![]() ,
,
Где
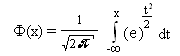 - функция Лапласа, которую можно вычислить
как по таблицам, так и с помощью программыMicrosoftExcel.
Если в ячейку А1 записано значение х, то
формула В1=НОРМРАСП(А1;0;1;ИСТИНА) запишет
в ячейку В1 соответствующее значение
функции Лапласа Ф(х).
- функция Лапласа, которую можно вычислить
как по таблицам, так и с помощью программыMicrosoftExcel.
Если в ячейку А1 записано значение х, то
формула В1=НОРМРАСП(А1;0;1;ИСТИНА) запишет
в ячейку В1 соответствующее значение
функции Лапласа Ф(х).
Вероятность того, что годовой выпуск продукции окажется ниже b= 100 тыс.ед.:
![]()
Вероятность того, что годовой выпуск продукции превысит b= 150 тыс.ед.:
![]()
Таким образом, с большой вероятностью, годовой выпуск продукции будет находиться между 100 и 150 тыс.ед.
5.2. Математическая статистика
Имеются статистические данные об объемах лесных грузов, в тыс.куб.м., перевозимых еженедельно от лесозаготовительных к деревообрабатывающим предприятиям: {хi}i=l¯n
Требуется произвести первичную обработку данных методами математической статистики. Для этого необходимо:
Составить статистический ряд,
Для каждого частичного интервала определить частоты, относительные частоты, накопленные частоты, накопленные относительные частоты,
Построить полигоны, кумуляты и кистограмму,
Определить выборочные характеристики статистического распределения.
Метод решения задачи рассмотрены в [1], [8], [15].
Пример. Решить задачу для следующих статистических данных:
38, 43, 54, 84, 32, 53, 59, 39, 72, 56, 93, 55, 48, 56, 26, 43, 37, 64, 42, 37, 34, 43, 46, 45, 86, 32, 96, 36, 28, 69, 42, 34, 50, 75, 59, 59, 44, 87, 61, 34, 49, 42, 64, 47, 46, 64, 42, 57, 54, 79, 51, 67.
Решение. Имеем выборку объемовn= 52 из генеральной совокупности Х, представляющей собой еженедельный объем лесных грузов.
Среди элементов выборки определим минимальное и максимальное значения: хmin = 26,хmax = 96. Уменьшимхmin и увеличимхmax до «хороших» чисел, и возьмем несколько больший промежуток от 20 до 100. Вычислим размах выборки
R= 100 – 20 = 80.
Количество групп (частичных интервалов) kопределим по формуле
K= [5 ∙lng] = [5 ∙lg52] = [5 ∙ 1,716] = 8. Длину интервала найдем по формуле
![]() .
.
Определим границы частичных интервалов:
a0 = 20,
a1 = a0 + h = 20 + 10 = 30, a5 = a4 + h = 60 + 10 = 70,
a2 = a1 + h = 30 + 10 = 40, a6 = a5 + h = 70 + 10 = 80,
a3 = a2 + h = 40 + 10 = 50, a7 = a6 + h = 80 + 10 = 90,
a4 = a3 + h = 50 + 10 = 60, a8 = a7 + h = 90 + 10 = 100.
Для каждого i-го интервала найдем число выборочных значений (частоту), попавших в данный интервал. В графе штрих-лист (табл.2) для каждого выборочного значения проставляется «черта». Их количество и равно соответствующей частотеni. Если некоторый элемент выборки попадает на границу интервала, то «черта» ставится в левый интервал.
Относительные частоты равны отношениям ni / n, накопленные частоты определяются по формуламwi=n1+n2 + ... +ni, а накопленные относительные частоты равныwi / n. Полученные данные заносятся в табл. 2.
Таблица 2
Таблица распределения частот
|
Группа |
Левая граница |
Правая граница |
Штрих- лист |
Середина |
Частота |
Относительная частота |
Накопленная частота |
Накопленная относительная частота |
|
1 |
20 |
30 |
// |
25 |
2 |
0,0385 |
2 |
0,0385 |
|
2 |
30 |
40 |
////////// |
35 |
10 |
0,1923 |
12 |
0,2308 |
|
3 |
40 |
50 |
/////////////// |
45 |
15 |
0,2885 |
27 |
0,5192 |
|
4 |
50 |
60 |
/////////// |
55 |
11 |
0,2115 |
38 |
0,7308 |
|
5 |
60 |
70 |
////// |
65 |
6 |
0,1154 |
44 |
0,8462 |
|
6 |
70 |
80 |
/// |
75 |
3 |
0,0577 |
47 |
0,9038 |
|
7 |
80 |
90 |
/// |
85 |
3 |
0,0577 |
50 |
0,9615 |
|
8 |
90 |
100 |
// |
95 |
2 |
0,0385 |
52 |
1,0000 |
В таблицу включен еще столбец со средними
значениями каждого интервала
![]() .
.
Полигоны представляют собой графическую зависимость частот (относительных частот) от середин интервалов (рис.2).
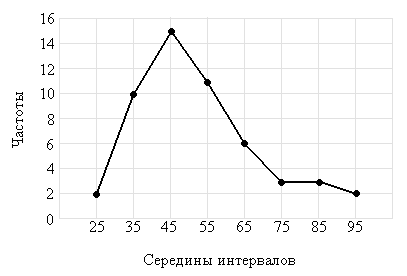
Рис.2. Полигон частот
Кумуляты представляют собой графическую зависимость накопленных частот (накопленных относительных частот) от середин интервалов (рис.3).
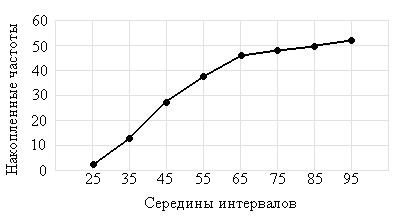
Рис.3. Кумулята частот
Гистограмма есть графическое изображение зависимости плотности относительных частот ni / nhот соответствующего интервала группировки (рис.4).
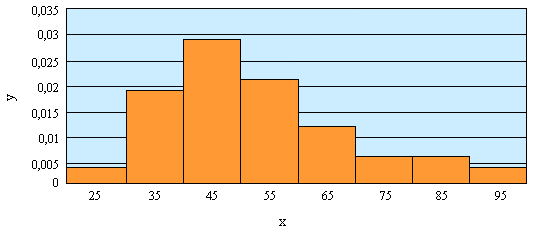
Рис.4. Гистограмма выборки
Определим выборочные характеристики статистического распределения. Выборочное среднее, выборочную дисперсию и выборочное среднее квадратическое отклонение определим по формулам
 (1)
(1)
Подставляя числовые значения, получим
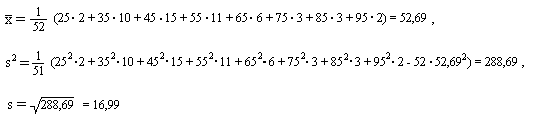
Таким образом, средний еженедельный
объем перевозок лесных грузов составляет
![]() = 52,69 тыс.куб.м. Выборочная дисперсияs²
= 288,69 тыс.куб.м². Выборочное среднее
квадратическое отклонениеs
= 16,99 тыс.куб.м.
= 52,69 тыс.куб.м. Выборочная дисперсияs²
= 288,69 тыс.куб.м². Выборочное среднее
квадратическое отклонениеs
= 16,99 тыс.куб.м.
Рассмотрим решение задачи в среде MicrosoftExcel. Статистические данные помещаются в ячейках А2:Н7; А8:D8, как показано в табл.3.
В ячейке А12 содержится объем выборки, равный 52. В ячейках В11 и С11 рассчитываются максимальное и минимальное значения статистических данных в соответствии с формулами.
= МАКС(А2:Н7; А8:D8) и =МИН(А2:Н7; А8:D8).
Округленные значения записываются в ячейке В12 и С12 соответственно. В ячейке D12 рассчитывается размах выборки по формуле =В12-С12.
Количество групп k= 8 записывается в ячейку Е12. В ячейкеF12 длина интервала рассчитывается по формуле
=D12/E12.
Далее производится заполнение таблицы распределения частот. После заполнения ячеек А15:D22 следует выделить ячейкиE15:Е22 и обратиться к функции «Частота», указав прямоугольный массив данный А2:Н8 и массив правых границ интервалов:
{= ЧАСТОТА(А2:Н8; С15:С22)}.
Таблица 3
|
|
А |
B |
C |
D |
E |
F |
G |
H |
|
1 |
Статистические данные |
|
|
|
|
| ||
|
2 |
38 |
43 |
54 |
84 |
32 |
53 |
59 |
39 |
|
3 |
72 |
56 |
93 |
55 |
48 |
56 |
26 |
43 |
|
4 |
37 |
64 |
42 |
37 |
34 |
43 |
46 |
45 |
|
5 |
86 |
32 |
96 |
36 |
28 |
69 |
42 |
34 |
|
6 |
50 |
75 |
59 |
59 |
44 |
87 |
61 |
34 |
|
7 |
49 |
42 |
64 |
47 |
46 |
64 |
42 |
57 |
|
8 |
54 |
79 |
51 |
67 |
|
|
|
|
|
9 |
|
|
|
|
|
|
|
|
|
10 |
n |
Макс |
Мин |
R |
k |
h |
|
|
|
11 |
|
96 |
26 |
|
|
|
|
|
|
12 |
52 |
100 |
20 |
80 |
8 |
10 |
|
|
|
13 |
|
|
|
|
|
|
|
|
|
14 |
Группа |
Лев.гран. |
Прав.гран. |
Середина |
Частота |
Отн.част. |
Нак.част. |
Н.о.част |
|
15 |
1 |
20 |
30 |
25 |
2 |
0,038 |
2,000 |
0,038 |
|
16 |
2 |
30 |
40 |
35 |
10 |
0,192 |
12,000 |
0,231 |
|
17 |
3 |
40 |
50 |
45 |
15 |
0,288 |
27,000 |
0,519 |
|
18 |
4 |
50 |
60 |
55 |
11 |
0,212 |
38,000 |
0,731 |
|
19 |
5 |
60 |
70 |
65 |
6 |
0,115 |
44,000 |
0,846 |
|
20 |
6 |
70 |
80 |
75 |
3 |
0,058 |
47,000 |
0,904 |
|
21 |
7 |
80 |
90 |
85 |
3 |
0,058 |
50,000 |
0,962 |
|
22 |
8 |
90 |
100 |
95 |
2 |
0,038 |
52,000 |
1,000 |
|
23 |
Сумма |
|
|
|
52 |
1 |
|
|
|
24 |
|
|
|
|
|
|
|
|
|
25 |
Среднее |
Дисп. |
Ср.кв.отк. |
|
|
|
|
|
|
26 |
52,94 |
291,39 |
17,07 |
|
|
|
|
|
Одновременное нажатие клавиш Ctrl+Shift+Enterприведет к заполнению выделенных ячеек Е15:Е22. Содержимое ячеекF15:Н22 рассчитывается в соответствии с формулами, приведенными выше.
С помощью мастера диаграмм строятся необходимые графики: полигон частот, кумулята частот и гистограмма (рис. 2-4).
Далее в ячейках А26:С26 рассчитываются значения статистических характеристик, которые определяются по выборке в соответствии с формулами:
Выборочное среднее = СРЗНАЧ(А2:Н7; А8:D8),
Выборочная дисперсия = ДИСП(А2:Н7; А8:D8),
Выборочное среднее квадратическое отклонение = КОРЕНЬ(В26).
Заметим, что характеристики, полученные ранее по формулам (1) с использованием группировки данных, лишь приближенно равны характеристикам, рассчитанным по программе без группировки данных.