

Методы машинного обучения для анализа текстовой информации. Понятие эмбеддинга. Методы построения и использования эмбеддингов при работе с текстом.
Методы машинного обучения для анализа текстовой информации. Методы машинного обучения для анализа текстовой информации предполагают использование алгоритмов и моделей для извлечения значимых закономерностей и выводов из текстовых данных. Эти методы позволяют автоматизировать обработку, классификацию и понимание больших объемов текстовой информации. Ниже приведены некоторые конкретные методы машинного обучения, широко используемые для анализа текстовой информации:
Bag-of-Words (BoW) – это простая, но эффективная технология, которая представляет текстовые документы как набор отдельных слов, игнорируя грамматику и порядок слов. Он создает числовой вектор признаков для каждого документа путем подсчета частоты встречаемости слов в корпусе текстов. BoW часто используется в качестве базового подхода для задач классификации текстов.
Term Frequency-Inverse Document Frequency (TF-IDF) – это статистическая мера, используемая для оценки важности слова в документе в рамках большого корпуса. Она присваивает вес каждому слову в зависимости от его частоты в данном документе (TF) и обратно пропорционально его частоте во всех документах (IDF). TF-IDF помогает выявить ключевые термины и уменьшить влияние часто встречающихся слов.
Вложения слов (Embedding) представляют слова как векторы плотности в высокоразмерном пространстве, отражающие семантические связи между словами. Такие методы, как Word2Vec и GloVe, изучают эти вкрапления путем обучения на больших текстовых корпорациях. Вложения слов позволяют улавливать контекстное сходство и могут использоваться в различных задачах обработки естественного языка, таких как анализ настроения, распознавание именованных сущностей и системы ответа на вопросы.
Распознавание именованных сущностей (NER) – это метод, позволяющий идентифицировать и классифицировать именованные сущности (такие как имена, названия, местоположения, организации) в тексте. Для решения задач NER обычно используются модели машинного обучения, в частности модели маркировки последовательностей, такие как условные случайные поля (CRF) или рекуррентные нейронные сети (RNN). Эти модели учатся распознавать и классифицировать объекты, используя контекстную информацию.
Анализ настроений направлен на определение настроения или мнения, выраженного в тексте. Для анализа настроений могут использоваться такие методы машинного обучения, как машины опорных векторов (SVM), Naive Bayes или рекуррентные нейронные сети (RNN). Эти модели обучаются на помеченных данных, чтобы классифицировать текст на положительные, отрицательные или нейтральные настроения.
Топологическое моделирование – это метод, позволяющий автоматически определять основные темы в коллекции документов. Латентное распределение Дирихле (Latent Dirichlet Allocation, LDA) – популярный алгоритм тематического моделирования, который назначает вероятности словам и документам для выявления основных тем. Он помогает организовать и обобщить большие текстовые массивы данных.
Классификация текста предполагает присвоение текстовым документам заранее определенных категорий или меток на основе их содержания. Для задач классификации текстов могут использоваться такие методы, как машины опорных векторов (SVM), Naive Bayes или конволюционные нейронные сети (CNN). Эти модели обучаются на основе маркированных обучающих данных, чтобы классифицировать новые документы по заранее определенным категориям.
Понятие эмбеддинга. Как уже упоминалось ранее, вложения слов – это фундаментальная концепция обработки естественного языка (NLP), которая представляет слова в виде векторов плотности в высокоразмерном пространстве. Эти векторы отражают семантические связи и контекстуальное сходство между словами.
Методы построения и использования эмбеддингов при работе с текстом. Существует несколько методов построения и использования вкраплений слов при работе с текстом:
Word2Vec – популярный метод обучения вложенных слов. Он состоит из двух моделей: Continuous Bag-of-Words (CBOW) и Skip-gram. CBOW предсказывает целевое слово на основе контекстных слов, а Skip-gram предсказывает контекстные слова, заданные целевым словом. Обе модели учатся представлять слова в виде плотных векторов путем тренировки на больших текстовых массивах. Полученные вкрапления слов могут быть использованы для измерения сходства слов, проведения аналоговых рассуждений или в качестве входных признаков для последующих задач NLP.
GloVe (Global Vectors for Word Representation) – еще один широко распространенный метод построения вкраплений слов. Он использует статистику совпадений для обучения векторов слов. GloVe строит матрицу кокуррентности, которая фиксирует частоту встречаемости слов в корпусе. Затем эта матрица факторизуется для получения вкраплений слов, отражающих глобальные связи между словами.
Вместо того чтобы обучать вкрапления слов с нуля, можно использовать предварительно обученные вкрапления. Такие вкрапления обучаются на крупных корпоративных базах и доступны для непосредственного использования. К числу популярных предварительно обученных вкраплений относятся Word2Vec, GloVe и FastText. Их можно скачать и использовать в различных задачах NLP без необходимости длительного обучения на специальных наборах данных.
Контекстуальные вкрапления слов определяют значение слова на основе его контекста в предложении или документе. Такие модели, как ELMo (Embeddings from Language Models) и BERT (Bidirectional Encoder Representations from Transformers), обучаются контекстуальным вкраплениям путем тренировки на крупномасштабных задачах моделирования языка. Было показано, что такие вкрапления улучшают производительность в широком спектре задач NLP, поскольку они отражают нюансы значения слов в различных контекстах.
При использовании вкраплений слов в моделях NLP часто используется матрица вкраплений для сопоставления слов с соответствующими им векторами. Эта матрица инициализируется предварительно обученными вкраплениями или обучается в процессе обучения. Каждое слово в текстовой последовательности представлено своим вектором встраивания, и эти векторы поступают в модель в качестве входных признаков. Матрица вкраплений обновляется в процессе обучения для оптимизации работы последующей задачи NLP.
В некоторых случаях может быть полезно провести тонкую настройку предварительно обученных вкраплений слов на конкретной задаче или на наборе данных, специфичных для конкретной области. Тонкая настройка позволяет вкраплениям адаптироваться к специфическим характеристикам целевой задачи, повышая эффективность работы. Это может быть сделано путем обновления матрицы вкраплений в процессе обучения или путем обучения дополнительных слоев поверх предварительно обученных вкраплений.
Графовые вероятностные модели. Методы структурного обучения и обучения распределений в узлах графовых вероятностных моделей. Типы графовых вероятностных моделей. Меры качества и целевые функции, применяемые при обучении графовых вероятностных моделей.
Графовые вероятностные модели. Графовые модели, представляют собой тип статистической модели, в которой взаимосвязи между переменными представлены с помощью графовой структуры. В этих моделях узлы графа представляют собой случайные переменные, а ребра между узлами – вероятностные зависимости между этими переменными.
Методы структурного обучения и обучения распределений в узлах графовых вероятностных моделей. Существует несколько подходов к изучению структуры, включая методы, основанные на оценках (баллах), методы, основанные на ограничениях, и гибридные методы.
Балльные методы направлены на поиск оптимальной структуры графа путем оценки различных структур-кандидатов на основе балльного критерия. Критерий оценки часто подразумевает компромисс между сложностью модели (количеством параметров) и ее соответствием данным. Популярными критериями оценки являются Байесовский информационный критерий и информационный критерий Акаике.
Байесовский информационный критерий наказывает сложные модели. Оценка BIC для графовой структуры дается следующим образом:

где
– набор данных,
 и
и
 – отражают граф и его параметры,
– отражают граф и его параметры,
 – число параметров в модели,
– число точек данных.
– число параметров в модели,
– число точек данных.
В информационном критерии Акаике штрафной член в 2 раза больше числа параметров, что является менее строгим по сравнению с Байесовским критерием. Это означает, что критерий Акаике позволяет использовать более сложные модели.

Методы, основанные на ограничениях, используют статистические тесты для определения взаимосвязи между переменными. Эти методы проверяют, являются ли две переменные условно независимыми при наличии других переменных. Если они независимы, то между ними нет ребра в графе. К числу распространенных тестов относится χ-квадрат, который сравнивает наблюдаемые и ожидаемые частоты.
Гибридные методы сочетают в себе подходы к изучению структуры, основанные как на оценках, так и на ограничениях. Они начинают с исходной структуры графа и итеративно уточняют ее, добавляя или удаляя ребра на основе статистических тестов и критериев оценки. Одним из популярных гибридных методов является алгоритм PC, который сначала использует тесты условной независимости для определения скелета графа (т.е. набора неориентированных ребер). А затем для ориентации ребер и получения направленного ациклического графа используется подход, основанный на оценке.
После изучения структуры графа следующим шагом является оценка распределений вероятностей, связанных с каждым узлом графа. Для этого могут быть использованы различные подходы:
Оценка максимального правдоподобия – широко распространенный метод, позволяющий оценить параметры распределения вероятностей путем максимизации правдоподобия по наблюдаемым данным. Для дискретных переменных оценка максимального правдоподобия включает в себя подсчет встречаемости различных значений и их нормализацию для получения вероятностей. Для непрерывных переменных метод часто предполагает подгонку параметрического распределения с использованием таких методов, как максимальная энтропия или максимальная апостериорная оценка.
Байесовское оценивание включает в себя предварительные знания о параметрах распределения, что приводит к получению более надежных оценок. Оно использует теорему Байеса для обновления предварительных представлений с учетом наблюдаемых данных и получения апостериорных распределений. Для байесовского оценивания обычно используются методы Марковской цепи Монте-Карло, такие как выборка Гиббса или Метрополиса-Гастингса.
Типы графовых вероятностных моделей. Одним из распространенных типов графовых вероятностных моделей является байесовская сеть, представляющая собой направленный ациклический граф. В байесовской сети каждый узел представляет собой случайную переменную, а направленные ребра указывают на условные зависимости между переменными. Условное распределение вероятностей каждой переменной определяется на основе ее родителей в графе.
Другим типом вероятностной модели графа является марковское случайное поле. В отличие от байесовских сетей, марковские случайные поля являются неориентированными графами, то есть ребра не имеют определенного направления. Вместо этого ребра представляют собой парные зависимости между переменными. Совместное распределение вероятностей переменных факторизуется в виде произведения потенциальных функций, связанных с каждым кликом в графе.
Наконец, рассмотрим скрытые марковские модели – это тип графовой вероятностной модели, включающей как наблюдаемые, так и скрытые переменные. Скрытые марковские модели представляются в виде направленных графов, в которых скрытые переменные образуют цепь Маркова и порождают наблюдаемые переменные. Они широко используются для моделирования последовательных данных со скрытыми состояниями, например, в распознавании речи, обработке естественного языка и биоинформатике.
Меры качества и целевые функции, применяемые при обучении графовых вероятностных моделей. В процессе обучения графовых вероятностных моделей необходимо определить меры качества и целевые функции для оптимизации. К числу часто используемых относятся:
Логарифмическая функция правдоподобия измеряет степень соответствия модели наблюдаемым данным. Она определяет, насколько хорошо предсказанные моделью вероятности соответствуют фактическим данным. Максимизация функции логарифмического правдоподобия часто используется в качестве цели оптимизации в процессе обучения.

где
 – вероятность получить наблюдаемые
данные при заданных параметрах модели
;
– вероятность получить наблюдаемые
данные при заданных параметрах модели
;
Расхождение Куллбека-Лейблера определяет разницу между двумя распределениями вероятностей. Она часто используется в качестве меры несходства между истинным распределением и оцененным распределением модели. Минимизация расхождения Куллбека-Лейблера может быть использована в качестве целевой функции для обучения модели.

где
 – истинное распределение вероятностей;
– истинное распределение вероятностей;
 – оценка распределения вероятностей
согласно полученной модели.
– оценка распределения вероятностей
согласно полученной модели.
Информационный выигрыш измеряет уменьшение энтропии, достигаемое при включении в модель определенной переменной. Он широко используется в балльных методах для выбора наилучшей структуры среди графов-кандидатов. Максимизация информационного выигрыша позволяет направить процесс обучения в сторону более информативных моделей.

где
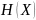 – энтропия параметра
;
– энтропия параметра
;
 – энтропия параметра
при заданном
.
– энтропия параметра
при заданном
.
Информационная энтропия Шеннона вычисляется как:
