

Обучение с подкреплением. Модели агентов и отклика среды. Задачи, решаемые обучением с подкреплением.
Обучение с подкреплением. Это область искусственного интеллекта (ИИ), которая изучает, как агент может учиться принимать решения и совершать действия в окружающей среде методом проб и ошибок, получая обратную связь в виде вознаграждений или наказаний, с целью максимизации своего кумулятивного вознаграждения в проекции на будущее.
Чтобы формализовать эту концепцию введем понятие Марковских Процессов Принятия Решений (MDP), основными компонентами которого являются:
Агент, взаимодействующий с окружающей средой и принимающий решения.
Пространство состояний
 или, иначе говоря, внешняя система в
которой действует агент.
или, иначе говоря, внешняя система в
которой действует агент.Доступные агенту варианты воздействия на окружающую среду, также называемые пространством действий .
Функции переходов задают изменение среды после того, как в некотором состоянии
 было выбрано некоторое действие
было выбрано некоторое действие
 .
В общем случае функция переходов может
быть подчиняться некоторому распределению
вероятностей
.
В общем случае функция переходов может
быть подчиняться некоторому распределению
вероятностей
 ,
т.е. с какой вероятностью и в какое
состояние перейдет среда после выбора
действия
в состоянии
,
т.е. с какой вероятностью и в какое
состояние перейдет среда после выбора
действия
в состоянии
 .
.Сигналы обратной связи, функции вознаграждения за правильно предпринятые действия
 .
.Стратегия, которую использует агент для определения своих действий. В общем случае стратегия принятия решений тоже может быть стохастической и моделироваться распределением
 .
.
Стратегия принятия решений – есть
искомая функция и цель обучения с
подкреплением. Взаимодействие со средой
агента со стратегией
моделируется так. Изначально среда
находится в некотором состоянии
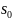 .
Агент выбирает действие из своей
стратегии
.
Агент выбирает действие из своей
стратегии
 .
Среда отвечает на это, выбирая своё
следующее состояние
.
Среда отвечает на это, выбирая своё
следующее состояние
 из функции переходов, а также выдаёт
агенту награду в размере
из функции переходов, а также выдаёт
агенту награду в размере
 .
Процесс повторяется: агент снова выбирает
,
а среда отвечает генерацией
.
Процесс повторяется: агент снова выбирает
,
а среда отвечает генерацией
 и скалярной наградой
и скалярной наградой
 .
.

Так продолжается до бесконечности или
пока среда не перейдёт в терминальное
состояние, после попадания в которое
взаимодействие прерывается, и сбор
агентом награды заканчивается. Если в
среде есть терминальные состояния, одна
итерация взаимодействия от начального
состояния до попадания в терминальное
состояние называется эпизодом. Цепочка
генерируемых в ходе взаимодействия
случайных величин называется траекторией
 .
Каждая стратегия задаёт распределение
в пространстве траекторий, т.е. с какой
вероятностью нам может встретится
траектория:
.
Каждая стратегия задаёт распределение
в пространстве траекторий, т.е. с какой
вероятностью нам может встретится
траектория:
![]()
Итак, фактически среда для нас — это управляемая марковская цепь: на каждом шаге мы выбором определяем то распределение, из которого будет генерироваться следующее состояние. Мы предполагаем, во-первых, марковское свойство: что переход в следующее состояние определяется лишь текущим состоянием и не зависит от всей предыдущей истории:
![]()
Во-вторых, мы предполагаем стационарность: функция переходов не зависит ни от времени, ни от того, сколько шагов прошло с начала взаимодействия.
Как уже упоминалось ранее, конечная цель обучения алгоритма – найти наиболее удачную стратегию и соответствующее ей распределение в пространстве траекторий, при котором достигался бы максимум функции вознаграждения. Математически это записывается как:

Методы динамического программирования разбивают задачу оптимизации стратегии на подзадачи и рекурсивно решают их, используя принцип оптимальности Беллмана. Уравнение оптимальности Беллмана для Q-функции формулирует оптимальное значение оценочной функции в каждом состоянии через значения оценочной функции в следующих состояниях.
![]()
В данном выражении второе слагаемое является оценочной функций, которая сообщает нам как много выгоды (награды) в будущем мы получим, если выберем соответствующее действие на текущем шаге.

где
 – штрафной коэффициент (дисконтирование),
который сообщает модели, что решения,
которую приносят выгоду в настоящий
момент более ценны, чем решения, которую
принесут ту же выгоду, но далеко в
будущем.
– штрафной коэффициент (дисконтирование),
который сообщает модели, что решения,
которую приносят выгоду в настоящий
момент более ценны, чем решения, которую
принесут ту же выгоду, но далеко в
будущем.
Решить уравнение оптимальности можно аналитически, если пространство решений невелико, но чаще используют итеративные методы или метод Монте-Карло. В последнем случае уравнение оптимальности заменяется его оценкой – Беллмановским таргетом.
![]()
Модели агентов и отклика среды. Агенты, основанные на моделях, поддерживают внутреннюю модель среды, включая ее динамику и возможные состояния. Они используют эту модель для планирования своих действий и принятия соответствующих решению. Агенты без модели не поддерживают явную модель среды, а обучаются непосредственно в процессе взаимодействия с ней. Они используют метод проб и ошибок для обновления своей стратегии на основе наблюдаемых вознаграждений.
В детерминированных средах следующее состояние полностью определяется текущим состоянием и действиями агента. В стохастических средах переход из одного состояния в другое, даже при выполнении одного и того же действия, является элементом случайности.
Эпизодические задачи имеют четкое начало и конец, в то время как непрерывные задачи не имеют естественной границы между эпизодами.
Проблемы, решаемые методом обучения с подкреплением. Одной из основных проблем, решаемых методом обучения с подкреплением, является задача управления. Агент должен научиться выбирать оптимальные действия в каждом состоянии среды, чтобы максимизировать суммарную награду или минимизировать затраты. Примерами задач управления являются управление роботом, управление процессами в промышленности или управление трафиком.
Другой проблемой, решаемой методом обучения с подкреплением, является задача обучения с подкреплением с частично наблюдаемыми состояниями. В этом случае агент не имеет полной информации о текущем состоянии среды и должен на основе неполной информации принимать решения. Примерами таких задач являются игры на основе текста или задачи планирования в неизвестной среде.
Еще одной проблемой, решаемой методом обучения с подкреплением, является задача обучения с подкреплением с функцией ценности. В этом случае агент должен научиться оценивать состояния и действия с помощью функции ценности, которая может быть определена как ожидаемая награда или вероятность успеха. Примерами таких задач являются задачи планирования маршрутов или задачи принятия решений в условиях неопределенности.