

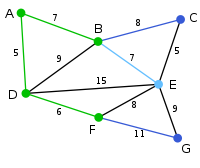
Алгоритмы на графах. Алгоритмы обхода (поиска на) графах. Обнаружение кратчайшего пути и минимального цикла в графе. Построение остовного дерева.
Алгоритмы на графах. Алгоритмы графов являются фундаментальной частью компьютерной науки и широко используются в различных приложениях, таких как маршрутизация сети, анализ социальных сетей и системы рекомендаций.
Алгоритмы обхода (поиска на) графах. Алгоритмы обхода графов используются для посещения всех вершин или ребер графа. Существуют два распространенных подхода к обходу графа: поиск в ширину (BFS) и поиск в глубину (DFS).
Поиск в ширину (BFS): BFS исследует вершины графа уровень за уровнем. Начиная с заданной исходной вершины, он исследует всех ее соседей перед переходом на следующий уровень. BFS использует структуру данных очередь для отслеживания вершин, которые нужно посетить.

Поиск в глубину (DFS): DFS исследует вершины графа, идя так глубоко, как это возможно, перед возвратом назад. Он использует структуру данных стек для отслеживания вершин, которые нужно посетить.
Обнаружение кратчайшего пути и минимального цикла в графе. Поиск кратчайшего пути между двумя вершинами в графе – это распространенная задача. Один из популярных алгоритмов для решения этой задачи – алгоритм Дейкстры.
Алгоритм Дейкстры находит кратчайший путь от исходной вершины до всех остальных вершин в графе с неотрицательными весами ребер. Он использует приоритетную очередь для выбора вершины с наименьшим расстоянием на каждом шаге.
На первом шаге инициализируется пустая приоритетная очередь и создается словарь расстояний с бесконечностями для всех вершин графа, кроме первой.


На первом шаге итерации происходит переоценка весов прямых соседей, как суммы веса текущей вершины и расстояния до экзаменуемой вершины. Если эта величина меньше текущей, она принимается как новое значение веса вершины.


Затем алгоримт переходит к тому соседу, чей вес оказался меньше и повторяет переоценку весов. В конце работы алгоритма обновленные веса графа представляют собой кратчайший путь полного обхода графа. Если же исследуется марштурт между точками, то алгоримт остановится раньше.
Поиск минимального цикла в графе – это еще одна важная задача. Цикл – это путь, который начинается и заканчивается в одной вершине. Один из алгоритмов для поиска минимального цикла - алгоритм Флойда-Уоршелла.
Алгоритм Флойда-Уоршелла находит кратчайшие пути между всеми парами вершин в графе, включая циклы. Он использует динамическое программирование для итеративного обновления кратчайших расстояний.

Построение остовного дерева. Остовное дерево – это подграф, который является деревом и соединяет все вершины графа. Один из алгоритмов для построения остовного дерева – алгоритм Прима.
Алгоритм Прима строит минимальное остовное дерево, начиная с произвольной вершины и добавляя соседние ребра с наименьшим весом, пока все вершины не будут соединены.





Основные понятия машинного обучения. Отличие машинного обучения от статистики. Методы на обучении с учителем. Методы на обучении без учителя. Метрики качества алгоритмов машинного обучения.
Основные понятия машинного обучения. Машинное обучение - это отрасль искусственного интеллекта, которая фокусируется на разработке алгоритмов и моделей, позволяющих компьютерам учиться и делать прогнозы или принимать решения без явного программирования. В машинном обучении существуют три ключевых концепции:
Обучающие данные. Алгоритмы машинного обучения требуют значительного количества размеченных данных для обучения находить закономерности и делать прогнозы. Обучающие данные состоят из входных переменных (признаков) и соответствующих им выходных переменных (меток) или целевых значений. Качество и количество обучающих данных играют решающую роль в точности и производительности моделей машинного обучения.
Построение модели. Модели машинного обучения создаются с использованием алгоритмов, которые анализируют обучающие данные для выявления закономерностей и взаимосвязей между входными признаками и выходными метками. Эти модели стремятся обобщить данные обучения для прогнозирования невидимых или будущих данных.
Оценка модели. После построения модели ее необходимо оценить, чтобы оценить ее производительность и способность к обобщению. Для измерения того, насколько хорошо модель работает на обучающих данных и невидимых данных, используются различные метрики.
Отличие машинного обучения от статистики. Хотя машинное обучение и статистика имеют некоторые общие принципы, у них есть существенные различия:
Статистика в основном фокусируется на выводах, проверке гипотез и понимании взаимосвязей между переменными в популяции. Машинное обучение, с другой стороны, концентрируется на предсказании и принятии решений с использованием алгоритмов, которые учатся на данных.
Машинное обучение подчеркивает подход, основанный на данных, где алгоритмы изучают закономерности напрямую из данных. Статистика часто полагается на предположения и модели, основанные на теоретических распределениях.
Машинное обучение в основном заботится о точном прогнозировании невидимых данных. Статистика, однако, стремится делать выводы о характеристиках популяции на основе выборочных данных и делать обобщения о популяции.
Методы на обучении с учителем. Обучение с учителем - это подход машинного обучения, при котором алгоритм учится на размеченных обучающих данных для прогнозирования невидимых данных. Существует два основных типа методов обучения с учителем:
Классификационные алгоритмы используются, когда выходная переменная является категориальной или дискретной. Цель состоит в том, чтобы научиться отображающей функции, которая присваивает входные признаки заранее определенным классам или категориям. Примеры включают логистическую регрессию, деревья решений и метод опорных векторов.
Регрессионные алгоритмы используются, когда выходная переменная является непрерывной или числовой. Цель состоит в том, чтобы научиться отображающей функции, которая предсказывает значение на основе входных признаков. Примеры включают линейную регрессию, случайные леса и нейронные сети.
Методы на обучении без учителя. Обучение без учителя - это подход машинного обучения, при котором алгоритм учится на неразмеченных данных для обнаружения закономерностей, взаимосвязей или структур в данных. Существует два основных типа методов обучения без учителя:
Алгоритмы кластеризации группируют похожие точки данных на основе их внутренних характеристик или близости. Цель состоит в том, чтобы выявить естественные кластеры в данных без каких-либо заранее определенных меток. Примеры включают кластеризацию k-средних, иерархическую кластеризацию и DBSCAN.
Алгоритмы снижения размерности стремятся уменьшить количество входных признаков, сохраняя при этом важную информацию. Это помогает визуализировать данные с высокой размерностью и удалить шум или избыточные признаки. Примеры включают анализ главных компонент (PCA) и t-распределенное стохастическое вложение соседей (t-SNE).
Метрики качества алгоритмов машинного обучения. Для оценки производительности алгоритмов машинного обучения используются различные метрики оценки:
Точность измеряет долю правильно предсказанных положительных экземпляров среди всех предсказанных положительных экземпляров. Она часто используется для задач классификации.
Полнота измеряет долю правильно предсказанных положительных экземпляров среди всех фактических положительных экземпляров.
F1-мера является гармоническим средним между точностью и полнотой, предоставляя сбалансированную меру между ними. Она особенно полезна, когда имеется неравномерное распределение между классами.
Средняя квадратическая ошибка (MSE) – это общепринятая метрика, используемая в задачах регрессии. Она измеряет среднеквадратичное отклонение между предсказанными и фактическими значениями.
Коэффициент детерминации (
 )
представляет долю дисперсии зависимой
переменной, которая может быть объяснена
независимыми переменными. Он варьируется
от 0 до 1, где 1 указывает на идеальную
соответствие.
)
представляет долю дисперсии зависимой
переменной, которая может быть объяснена
независимыми переменными. Он варьируется
от 0 до 1, где 1 указывает на идеальную
соответствие.